猫头虎AI分享|腾讯新开源了一个轻量级、即插即用的身份保留视频生成框架:Stand-In,也支持换头像视频
猫头虎AI分享|腾讯新开源了一个轻量级、即插即用的身份保留视频生成框架:Stand-In,也支持换头像视频
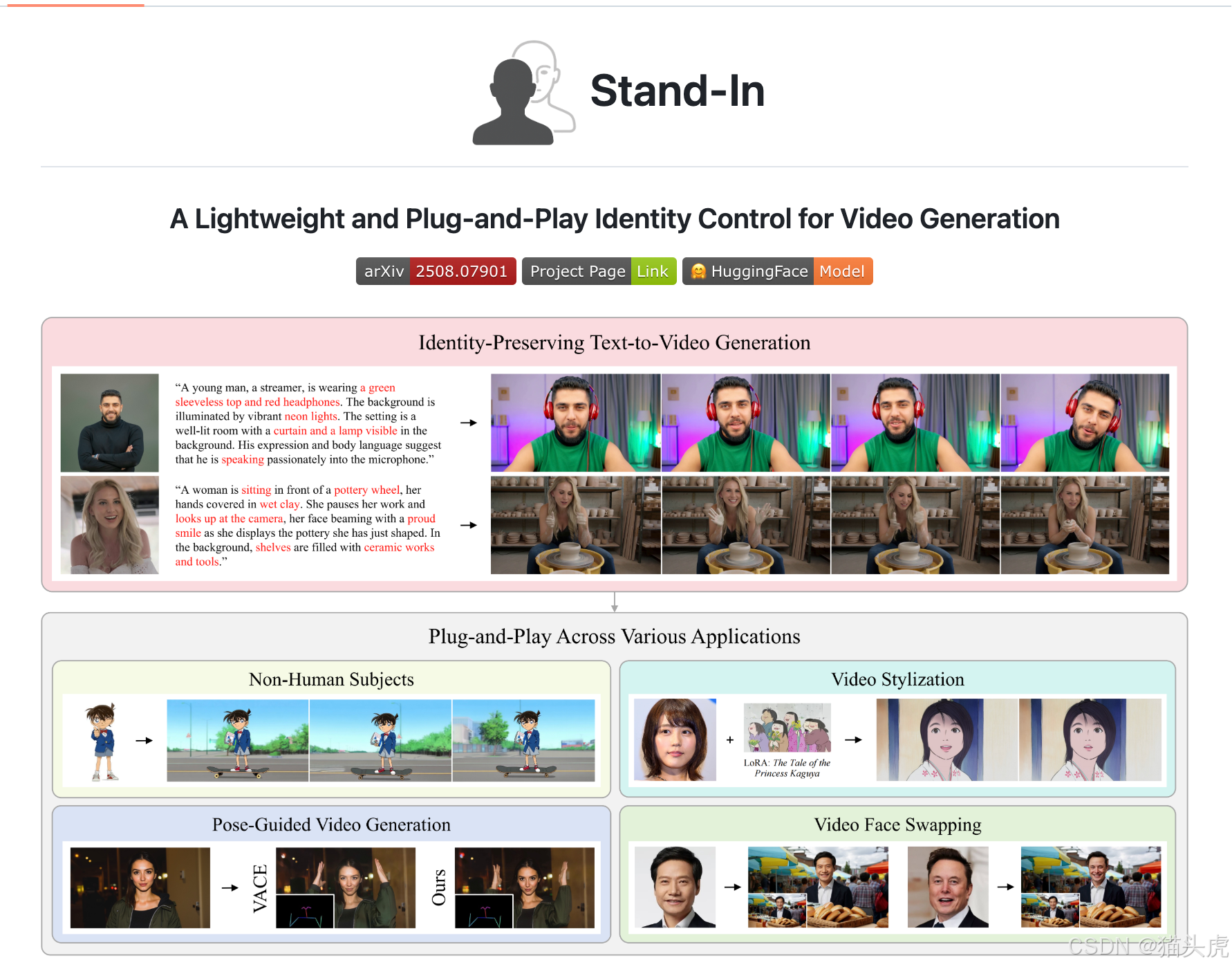
在人工智能和计算机视觉领域,视频生成技术一直是一个备受关注的话题。随着生成对抗网络(GAN)和深度学习技术的飞速发展,越来越多的创新性工具被推出,旨在提升视频内容的生成质量和控制能力。最近,腾讯发布了一个全新的开源项目——Stand-In,它是一个轻量级、即插即用的身份保留视频生成框架,不仅支持生成具有高保真度的文本到视频(Text-to-Video,T2V)内容,还能进行换头像、姿态控制等视频生成任务。
猫头虎开源项目fork仓库:https://github.com/MaoTouHU/Stand-In

Stand-In概述
Stand-In 是一个专注于身份保留的文本到视频生成框架。该框架采用了极其高效的训练方式,仅需比基础视频生成模型多训练1%的参数,就能够在面部相似度和自然度上实现先进的效果,超越了多种全参数训练的方法。Stand-In 不仅在保证身份一致性的同时,还能生成出高质量的视频。它还可以无缝集成到其他视频生成任务中,如:主题驱动的视频生成、姿态控制视频生成、视频风格化、以及人头像交换等。

核心特点
- 高效的训练方式:只需比基础模型多训练1%的参数。
- 高保真度:在不牺牲视频生成质量的情况下,出色地保持了身份一致性。
- 即插即用:可以轻松集成到现有的T2V(文本到视频)模型中。
- 高度可扩展:兼容社区模型,如LoRA,并支持多种下游视频任务。
Stand-In的优势
- 轻量化:相比传统的全参数模型,Stand-In只需增加1%的参数量,极大降低了计算资源消耗。
- 灵活的应用场景:除了基本的文本生成视频,Stand-In还支持换头像、姿态控制以及风格化等复杂任务。
- 易于集成:即使是现有的T2V模型,也可以通过简单的插件方式集成Stand-In。
主要功能展示
1. 身份保留的文本到视频生成
Stand-In支持根据用户提供的文本提示生成视频,并保留人物的面部特征和身份一致性。以下是一个生成示例:
 “一位男士舒适地坐在桌子前,面向镜头,好像在和朋友或家人交谈。他的目光专注而温柔,带着自然的微笑。背景是他精心装饰的个人空间,墙上挂着照片和世界地图,传达出一种亲密而现代的交流氛围。”
“一位男士舒适地坐在桌子前,面向镜头,好像在和朋友或家人交谈。他的目光专注而温柔,带着自然的微笑。背景是他精心装饰的个人空间,墙上挂着照片和世界地图,传达出一种亲密而现代的交流氛围。”
2. 非人类主体的身份保留视频生成
除了人类主体,Stand-In还支持非人类主体的视频生成,并能有效保留主体的身份特征。

3. 身份保留的风格化视频生成
Stand-In支持根据特定的风格(例如动漫风格)生成视频,同时保持主体的身份特征。

4. 视频换头像
Stand-In还支持高质量的人头像替换,能够精准地将一个视频中的人头像替换为另一个人的面孔,同时保持视频的自然感。

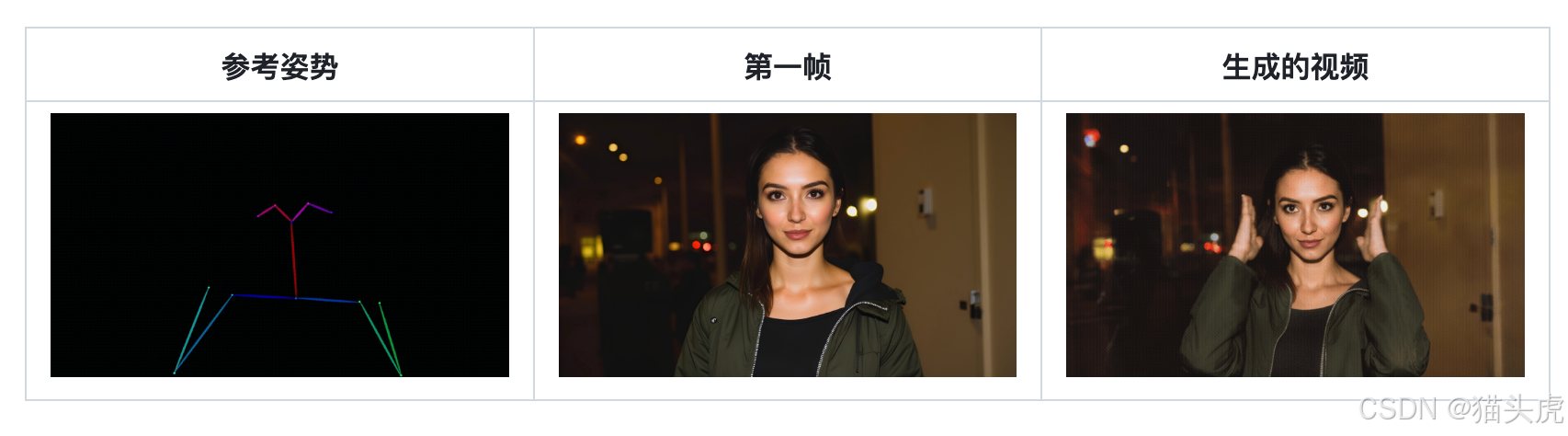
5. 姿态驱动的视频生成(结合VACE模型)
Stand-In结合VACE模型(Pose-Guided Video Generation),支持基于姿态生成动态视频,用户可以调整人物的姿态,并生成对应的视频内容。
如何快速开始
1. 环境搭建
# 克隆项目仓库
git clone https://github.com/WeChatCV/Stand-In.git
cd Stand-In# 创建并激活Conda环境
conda create -n Stand-In python=3.11 -y
conda activate Stand-In# 安装依赖
pip install -r requirements.txt# (可选)安装Flash Attention以加速推理
pip install flash-attn --no-build-isolation
2. 模型下载
可以通过以下脚本自动下载所有所需的模型权重:
python download_models.py
下载的模型包括:
wan2.1-T2V-14B(基础文本到视频生成模型)antelopev2(人头像识别模型)Stand-In(Stand-In模型)
3. 标准推理
使用infer.py脚本进行标准的身份保留文本到视频生成。
python infer.py \--prompt "描述视频中的场景..." \--ip_image "test/input/lecun.jpg" \--output "test/output/lecun.mp4"
4. 使用社区LoRA进行推理
python infer_with_lora.py \--prompt "描述视频中的场景..." \--ip_image "test/input/lecun.jpg" \--output "test/output/lecun.mp4" \--lora_path "path/to/your/lora.safetensors" \--lora_scale 1.0
致谢
此项目基于以下开源项目构建:
- DiffSynth-Studio(训练/推理框架)
- Wan2.1(基础视频生成模型)
结语
随着人工智能技术的不断进步,视频生成领域也在迎来一波全新的变革。腾讯推出的Stand-In框架,不仅为身份保留视频生成提供了一种创新解决方案,还通过其轻量化设计和高度可扩展的特性,为开发者提供了强大的工具支持。无论是文本到视频生成,还是换头像、姿态控制和风格化任务,Stand-In都能实现高质量的视频生成,并保持人物身份的自然一致性。
作为开源项目,Stand-In为AI领域的研究者、开发者及创作者提供了一个可扩展的平台,它不仅减少了模型训练的资源消耗,还提供了丰富的应用场景。从个人创作到商业应用,Stand-In都展现出了强大的潜力和价值。如果你也对视频生成技术充满兴趣,或者正在寻找一种更加高效、灵活的解决方案,Stand-In无疑是一个值得尝试的优秀框架。
猫头虎 相信,在未来,随着更多创新技术的加入,像Stand-In这样的工具将进一步推动AI创作的边界,释放出无限的创意和潜力。如果你对这个项目感兴趣,欢迎访问我们的GitHub仓库,探索更多的功能和应用。期待与全球开发者共同进步,为AI视频生成领域贡献更多的智慧与力量。
猫头虎开源项目fork仓库:https://github.com/MaoTouHU/Stand-In