网络编程及原理(八)网络层 IP 协议
目录
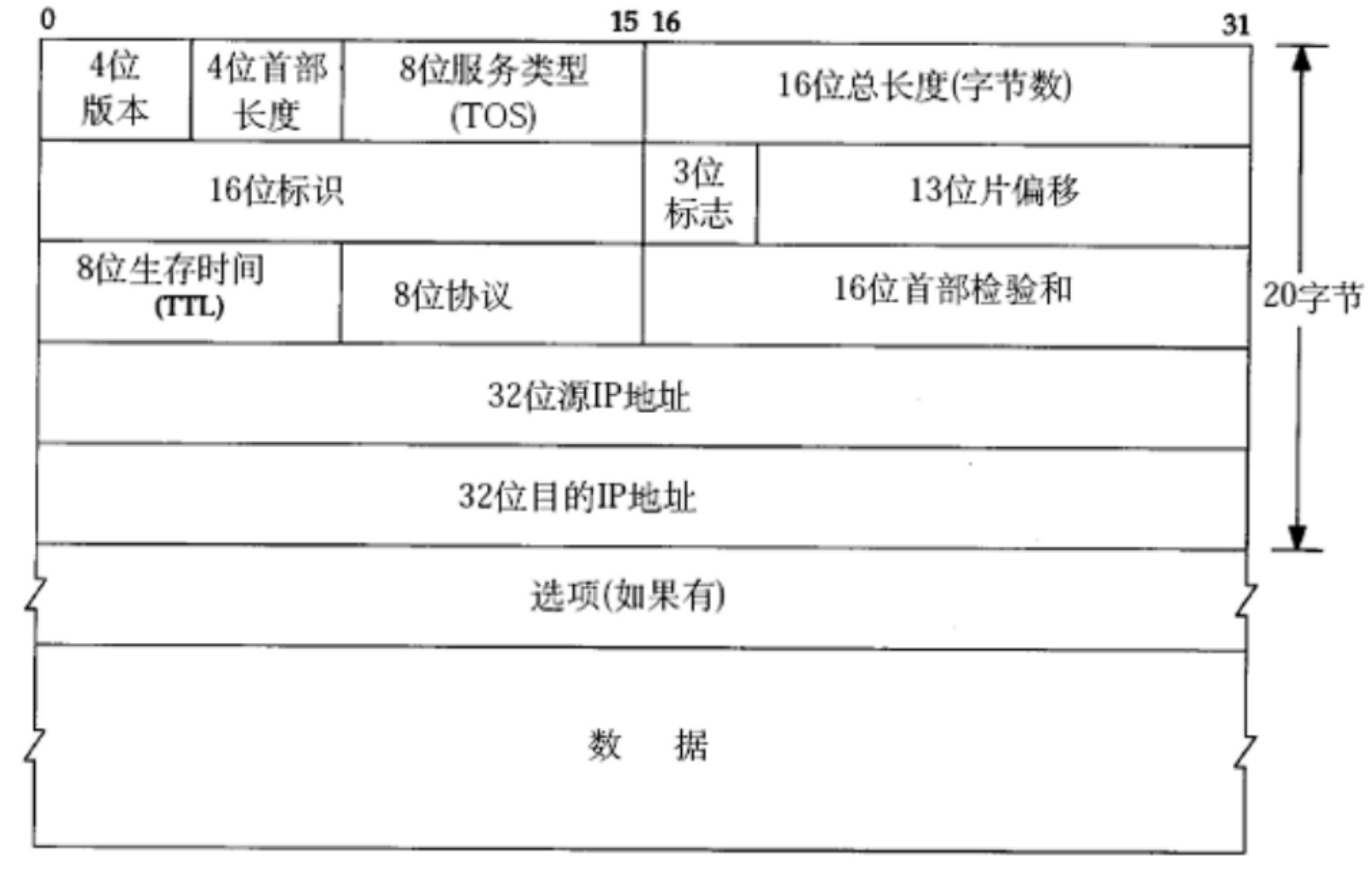
一 . IP 协议的报头结构
(1)“ 4位版本 ”
(2)“ 4位首部长度 ”
(3)“ 8位服务类型(TOS(type of service))”
(4)“ 16位总长度(字节数) ” 和 “ 13 位片偏移 ”
(5)“ 3位标志位 ”
(6)“ 8位生存时间(TTL) ”
(7)“ 8位协议 ”
(8)“ 16位首部校验和 ”
(9)“ 32 位源 IP 地址 ” 和 “ 32 位目的 IP 地址 ”
解决 IP 地址不够用的问题:
1 . 动态分配 IP 地址
2 . NAT 网络地址转换
3 . IPv6
(8)“ IP 地址中的网段划分 ”(组建网络)
二 . 特殊的 IP 地址
(1)主机号为全 0(二进制)
(2)主机号为全 1(二进制)
(3)环回 IP(loopback)
三 . 路由选择
四 . 数据链路层
(1)认识以太网
(2)以太网帧格式
五 . DNS 应用层协议
一 . IP 协议的报头结构
(1)“ 4位版本 ”
实际上只有两个取值:4 —> IPv4(默认为主流的IPv4),6 —> IPv6
(2)“ 4位首部长度 ”
IP 协议报头也是变长的,0 ~ 15,也就是说,当我们这里为 15 的时候,报头长度就是 60 。
(3)“ 8位服务类型(TOS(type of service))”
说的是 8 位,实际上 3 位已经弃用,1 位是保留字段(必须置为 0 ),真正有用的是 4 位 TOS 字段。
这四位分别表示:最小延时(数据从 A 到 B 传输的时间最短)、最大吞吐量(数据从 A 到 B 单位之间内,传输的数量最多)、最高可靠性(IP 协议并不像 TCP 那样有严格的可靠性,但是 IP 协议的一些机制也是会影响到丢包概率的)、最小成本(设备上消耗的资源较少)
这四者相互冲突,只能选择一个,对于 ssh / telnet 这样的应用程序,最小延时比较重要,而对于 ftp 这样的程序,最大吞吐量比较重要,对于不同的情形咱们需要选择不同的 TOS 。
(4)“ 16位总长度(字节数) ” 和 “ 13 位片偏移 ”
描述的是 IP 数据报的长度,16 位也就是 2 个字节,64 kb ,这跟 UDP 一样,并非是最多只能是 64 kb,因为我们 IP 协议中内置了拆包组包机制。单个的 IP 数据报确实没法超过 64 kb,但是不代表 IP 协议就不能传输超过 64 kb 的数据,因为 IP 协议会自动把大的数据报拆分成多个 IP 数据报携带传输,然后在接收方再进行拼装。
例如大家可能还没有买过家具,但是应该多多少少听过见过那种大型家具的搬运吧,像我们的沙发,床还有类的大型家具,都是很难进楼梯和电梯的,这个时候我们怎么将家具运上楼搬进家里呢?就是采用的这种先拆分再组装的方法。
怎么拆包的呢:同一个载荷的数据会被拆成多份,交给多个 IP 数据报来携带。多个 IP 数据报,16 位标识是相同数值,接受方就根据这个数值,将相同的拼接在一起。但是我们拼的时候,怎么判断谁在前谁在后呢?
我们不能靠接收数据的前后顺序来组装,因为我们之前就提到过,在网络数据传输中有很多不确定因素,很有可能会出现 “ 后发先至 ” 的情况,所以这就得靠我们的 13 位片偏移决定在组包的时候数据报的位置(谁的片偏移小谁就在前面,以此顺序组装)
(5)“ 3位标志位 ”
说着是 3 位标志位,只有 2 个有效,另外一个是保留位。有效的 2 位中,其中一位表示这个包是否需要组包(是否是拆包的一部分),另一位表示当前包是否是组包中的最后一个单位。
(6)“ 8位生存时间(TTL) ”
描述了一个数据包在网络中最多能存活多长时间。假如我们现在构造一个 IP 数据报,但是出于某种原因,我们的目的 IP 写错了,写成了不存在的 IP ,这就会导致我们的数据包就一直在路线上传输,找不到目的。
如果让这样的无效数据包无限传输,就会消耗很多的网络资源。此处的 TTL 约定了传输数据的上限,达到约定传输时间的上限之后,该数据包还没有找到目的 IP ,就会被自动丢弃掉。
注意:TTL 的单位不是 “ 秒 - s ” 也不是 “ 分钟 - min ” ,而是 “ 次数 ” 。这里的次数指的是数据报经过路由器转发的次数。
在发送一个 IP 数据报的时候,会有一个初始的 TTL 的值(32 / 64 / 128 ......),这个数据报每经过一个路由器转发,TTL 就会减一(经过交换机不减),一旦 TTL 减到了 0 ,此时这个数据报就被会当前的路由器直接丢弃掉。
(7)“ 8位协议 ”
区分在 IP 协议中,携带的载荷是哪种传输层协议的数据报。通过这 8 位协议里不同的数值,感知到接下来把数据交给 TCP 解析还是 UDP 解析还是交由其他协议解析。(类似于 TCP 、UDP 报头中的端口号)
(8)“ 16位首部校验和 ”
验证数据在传输中是否出错,只是针对首部,也就是 IP 报头,因为载荷部分 TCP / UDP 都有自己的校验和。
(9)“ 32 位源 IP 地址 ” 和 “ 32 位目的 IP 地址 ”
这是 IP 数据报中最关键的信息,关注数据报从哪里来到哪里去。
IP 地址,用来标识网络上的一个设备,并且期望 IP 地址是唯一的,但是我们 32 位标识的数据范围大概是 “ 2 ^ 32 - 1 ”(0 ~ 42 亿 9 千万),这个数字看起来很大,但是放在今天,这个全球光人口都有 80 多亿的世界,在这个移动互联网时代,电子设备只会有 42 亿多吗?显然这个数字放在现在肯定是不够用的,那么怎么解决呢?如下:
解决 IP 地址不够用的问题:
1 . 动态分配 IP 地址
一个设备,上网就分配 IP ,不上网就先不分配。但是很明显,这一方案只是权宜之计,或许能解燃眉之急,但是并不能从根本上解决问题,所以我们就有了进一步的方案二:
2 . NAT 网络地址转换
其核心思想就是 “ 以一当千 ”:使用一个 IP 代表一大波的设备。一个设备在进行上网的时候,IP 数据报中的 IP 地址就会被 NAT 设备(通常就是路由器)进行自动修改。
1 . 在同一个局域网内,主机 A 访问主机 B ,不会涉及到 NAT 机制。
2 . 公网上的设备 A 访问公网上的设备 B ,也不会涉及到 NAT 机制。
3 . 一个局域网中的主机 A 访问另一个局域网中的主机 B ,这种情况再 NAT 机制中是不允许的!
4 . 局域网内部的设备 A 访问公网上的设备 B ,NAT 机制主要就是针对这个情况进行生效的。
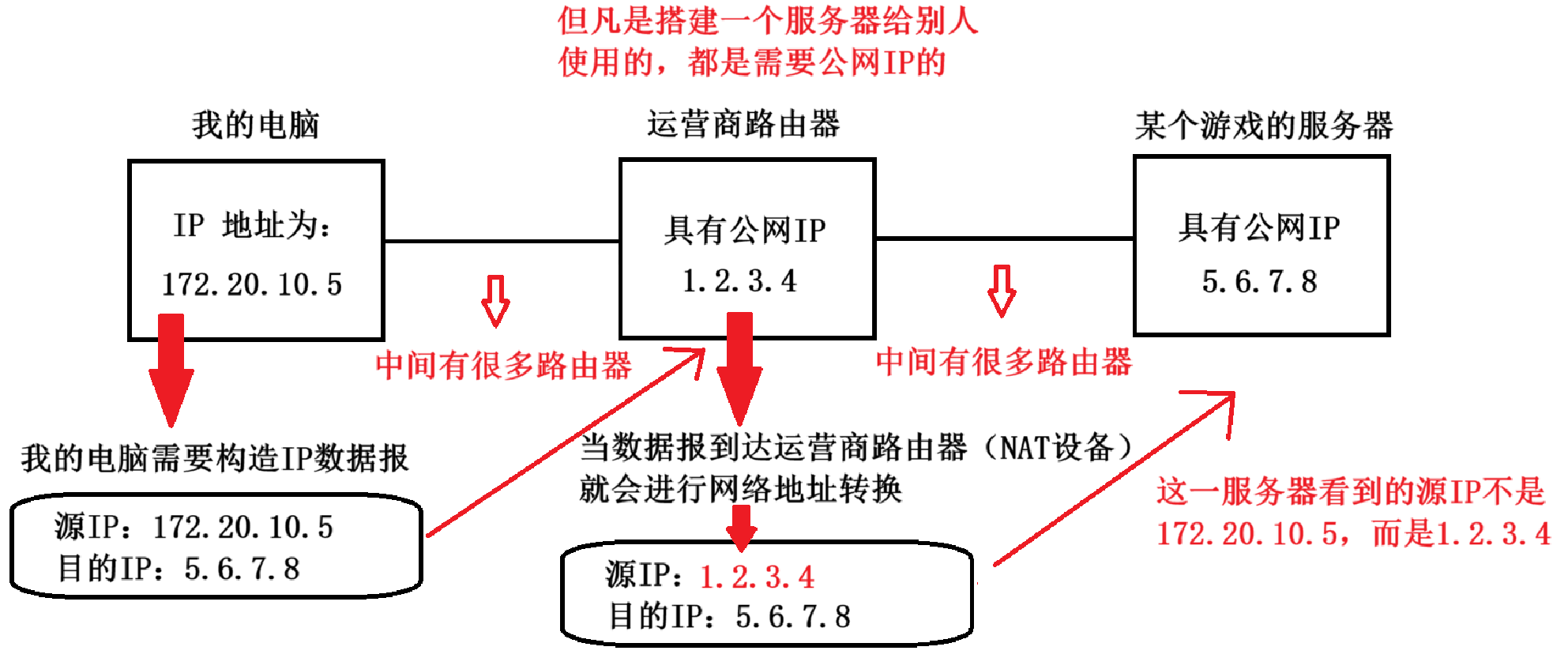
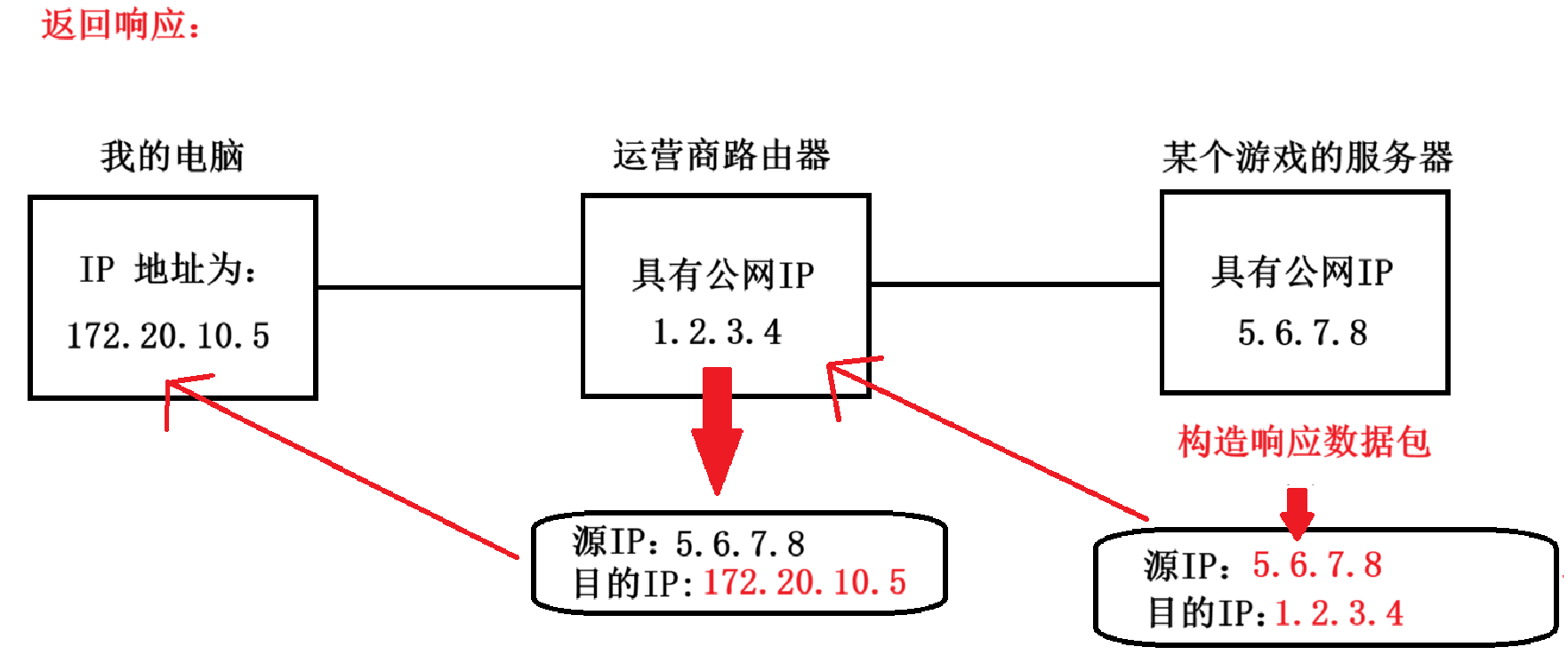
这只是针对单设备访问服务器,那么我们多设备访问同一个服务器呢?
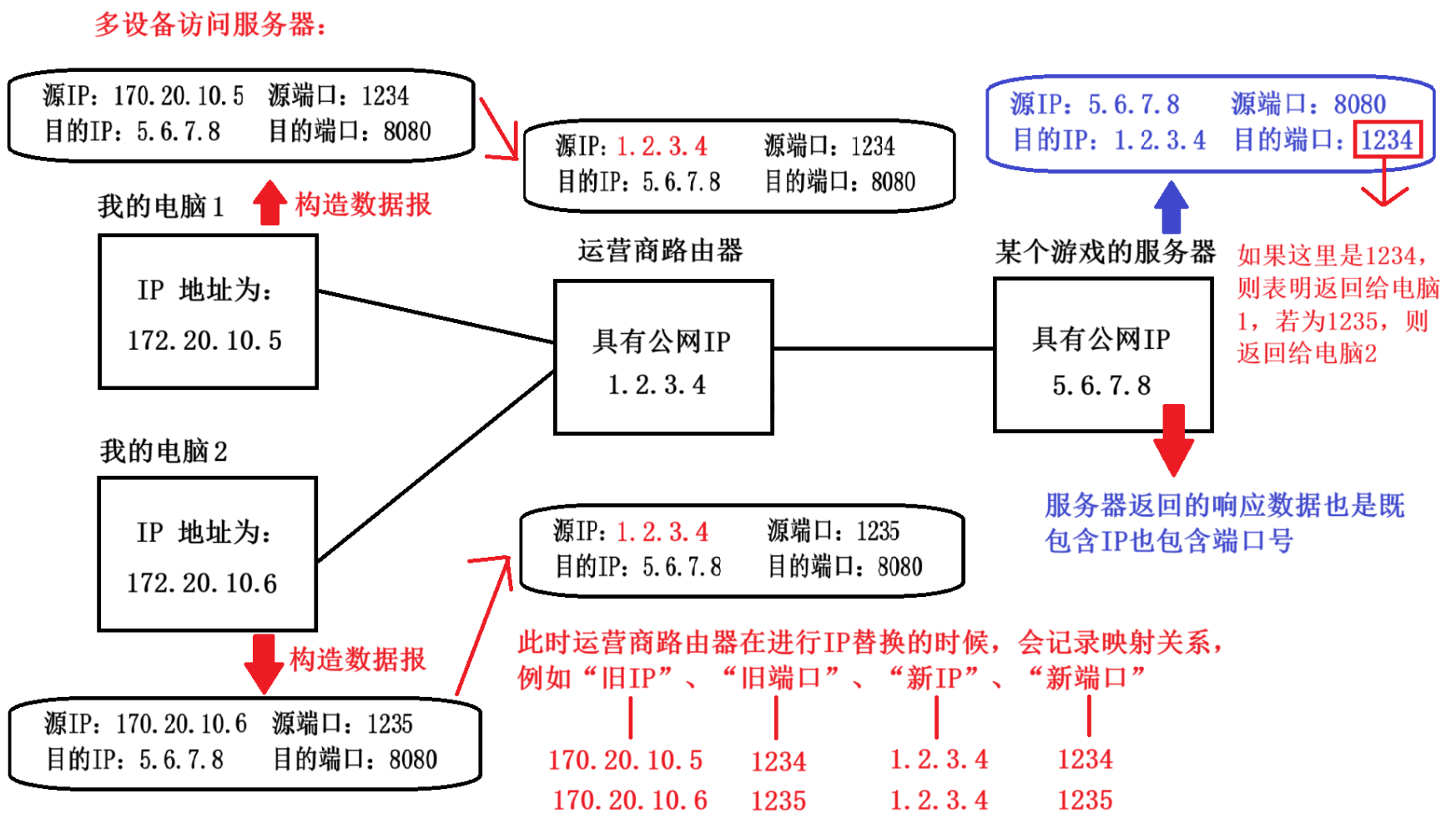
在网络通信中,不仅仅只有 IP 信息,还有一个关键的信息是 “ 端口号 ” ,端口号本来是区分同一个主机上不同的应用程序的,但是在 NAT 中,就可以用于区分不同主机上不同的应用程序。
还有一种情况是,客户端这里的源端口是由操作系统随机分配的,如果两台电脑的端口号相同,这种情况概率非常小(大概1/60000),但不代表不可能,此时我们又该怎么办呢?
此时不用担心,虽然两台电脑的源端口号一样,但是我们的路由器在打表分配端口号的时候,完全可以给这两台电脑分配到两个不同的端口号上加以区分。只需要保证服务器这边的映射关系是唯一的就行了。这一机制我们叫做 “ NAPT ” 。
NAT 机制的缺点:网络环境太复杂了,在替换的过程中,每一层的路由器都需要维护映射关系,每次转发数据,都要查询映射关系,而这类的维护、查询都是需要一定开销的。
其实在我们的日常生活中,手机、电脑、电视、冰箱、空调等等绝大部分设备都是在不同的局域网当中的,这就相当于一个公网 IP 就可以代表一大批设别,这样子就大幅减少了我们 IP 地址的使用,从而很好的解决了这一问题。
这就相当于,我们网购收快递,我填的地址是四川省成都市某某大学,在这个大学里可能有几万人,但我只需要填这一个地址就行了,不可能细分到将快递送到寝室送到我手上。
我们将 IP 地址分为了两大类:
1 : “ 内网 IP(也就是我们的私网 IP )”,“ 10. ”、“ 172.16~172.31 ”、“ 192.168. ” 开头的。
2 :“ 外网 IP(也就是我们的公网 IP)” ,上面那些 IP 之外,剩下的就是公网 IP 了。
对于这两种 IP ,我们只是要求公网 IP 必须是唯一的,但是私网 IP 是允许重复的(在不同的局域网中是允许重复的)。
(在 cmd 中输入 ipconfig 查看 IP )
3 . IPv6
IPv4:使用 32 位 4 个字节表示 IP 地址。
IPv6:使用 128 位 16 个字节表示 IP 地址。这一个数量级非常巨大,非常庞大,甚至多到可以给地球上的每一粒沙子都分配一个唯一的 IPv6 地址。这样子从根本上解决了 IP 地址不够用的问题。
注意:IPv6 和 IPv4 不兼容,这也就是我们 IPv6 不能完全普及的关键原因。要更换 IPv6 就得换设备,换设备就得花钱,而且对于我们用户体验上来说,在网速的体现上其实没差,而 NAT 机制只需要给路由器设备更新升级软件即可,不需要改变任何硬件设备,这就非常节约成本了。
IPv6 在我们国内的普及率是非常非常高的,大概在 80% 左右,这是因为国家在大力推进,属于国家战略,为什么呢?因为网络技术与我们的军事政治密切相关,在 2018 年左右,中美贸易战导致中美关系急转直下,而美丽国就采取了各种方式针对我们国家,其中就包括对中国大企业的制裁。
那时候我们网络通信普遍都是 IPv4 ,而 IPv4 的公网 IP 的分配权是由一个 “ 第三方的组织 ” 负责分配,讲道理这种组织不应该有任何政治因素,但是当时该组织背后有一个投资人是美国军方,所以大家懂的都懂,一旦美丽国想要制裁我们,不给我们分配公网 IP ,这就会对我们国内互联网行业的发展带来毁灭性的打击。
因为在 IPv4 的时代,咱们的计算机技术还不够格,所以咱们没有主导的发言权,被美国佬卡脖子,当咱们大力推进发展 IPv6 的时候,我们的技术水平已经不可同日而语了,咱们也有发言权了,所以 IPv6 并不是美丽国一家独大了,也就不能对我们做出什么制裁,所以咱们虽然能够普及 IPv6 了,但是并不常用,上网的时候基本还是用的 IPv4 ,这是为什么呀?有些东西可以不用,但是不能没有是吧,不然某些人看到了,那张嘴脸又要明晃晃地摆上台面威胁人了。
(8)“ IP 地址中的网段划分 ”(组建网络)
在组网的时候,就需要我们针对每个上网的设备的 IP 地址(包括路由器地址的 IP )进行设置。
IP 地址是 32 位整数,将其一分为二,左半部分为 “ 网络号 ” ,右半部分为 “ 主机号 ” ,这具体怎么分呢?一般我们是看不出来的,需要通过 “ 子网掩码 ” 区分出哪里是网络号,哪里是主机号。
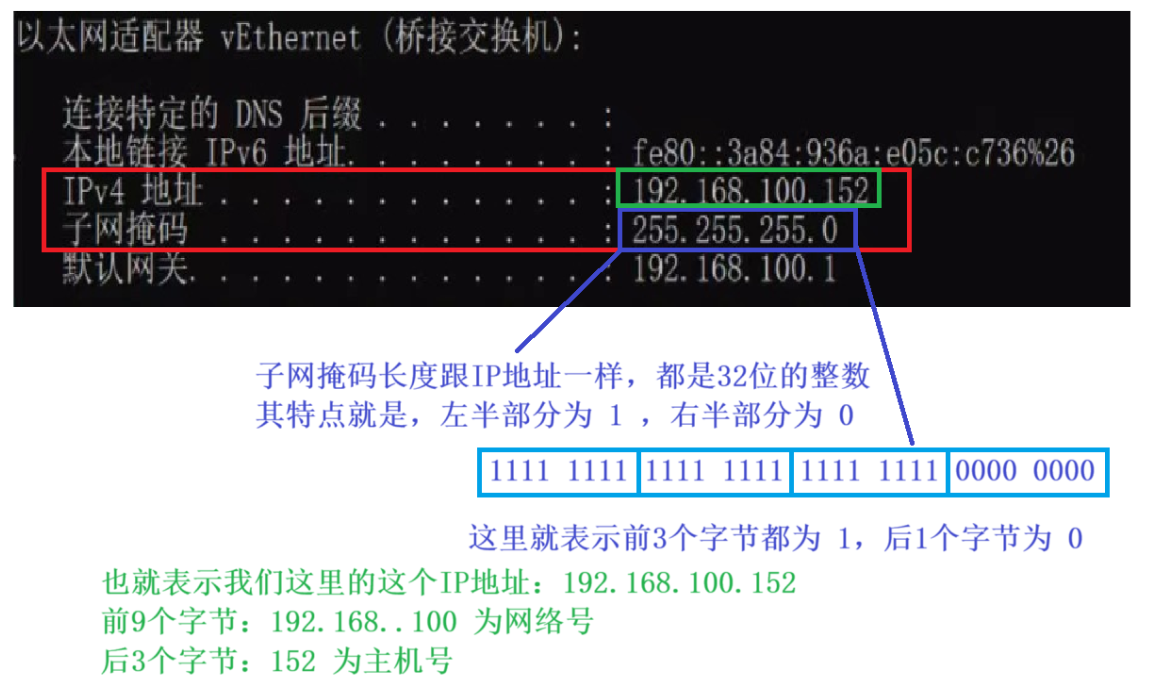
网络中规定:同一个局域网中的设备,网络号必须相同,主机号必须不同;两个相邻的局域网,网络号必须不同。
除了子网掩码还有一种方式叫做 “ ABCDE 五类网络 ” ,如下图:
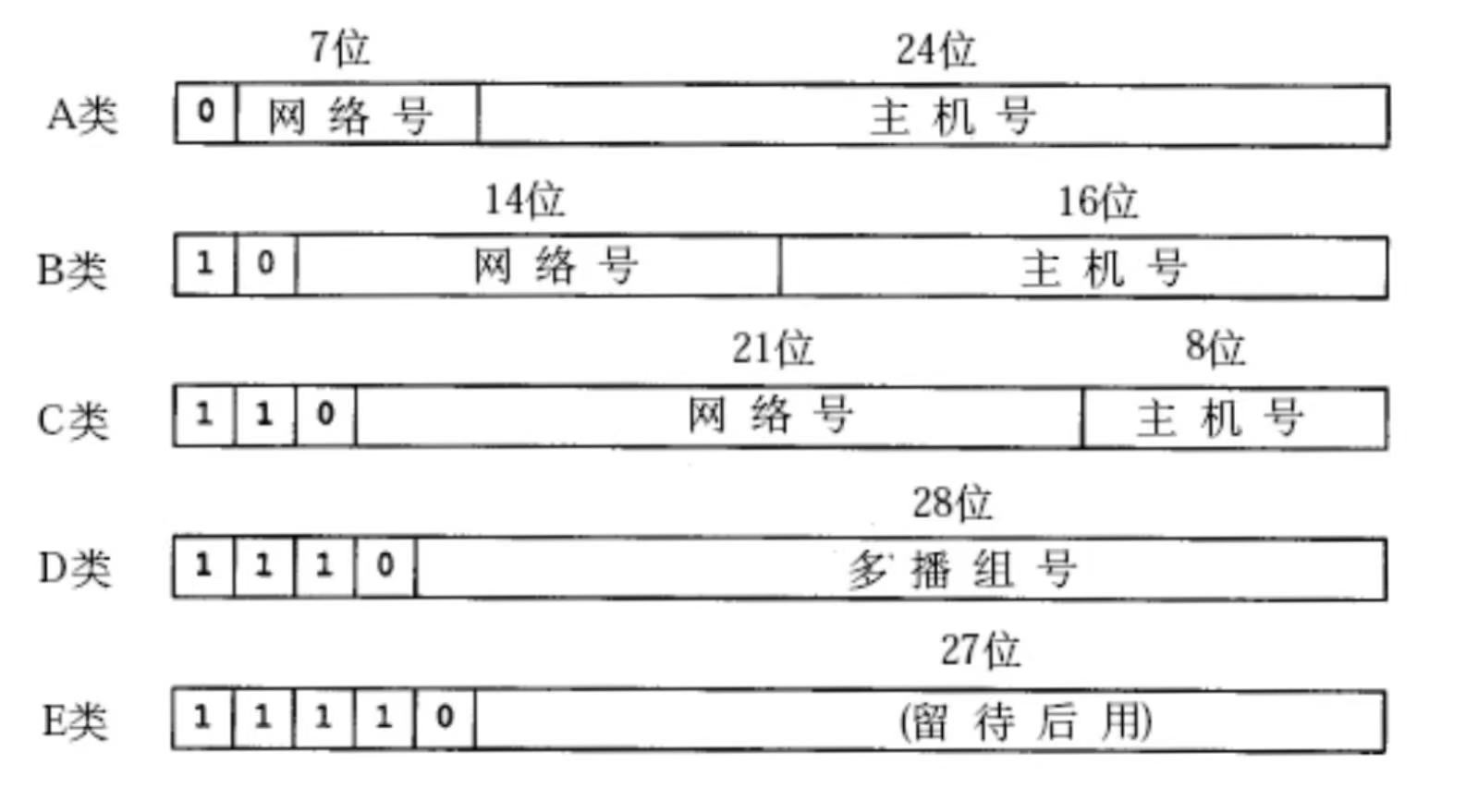
这一种方法呢,已经是上古时期的划分方式了,现在基本淘汰不用了,所以咱们就不过多赘述了。
二 . 特殊的 IP 地址
(1)主机号为全 0(二进制)
此时这个 IP 就是表示当前网段(相当于网络号)。因此我们在给局域网的某个设备分配 IP 地址的时候,是不能将主机号设置为全 0 的。
(2)主机号为全 1(二进制)
这样的 IP 我们称为 “ 广播 IP ” ,也就是说当我们向这个 IP 地址上发送数据包,它就会传输给整个局域网中的所有设备。(手机投屏常用广播 IP 实现)注意,TCP 不支持广播,UDP 可以。
(3)环回 IP(loopback)
环回 IP 就是指 IP 地址格式为 127.* 这种样式的 IP 。
那么什么是环回 IP 呢?就像一个环一样,相当于 “ 自发自收 ” ,给这个 IP 上发一个数据,就会从这个 IP 上收回一个相同的数据。就像自己发给自己。
使用环回 IP 一般用来测试,在写网络程序的时候,大多数情况都是为了跨主机通信,往往需要先自行测试,一台主机测试客户端和服务器之间能否正常交互。(一般使用的环回 IP 就是 127.0.0.1,虽然其他 127 开头的 IP 也是可以的,但是很少见)
三 . 路由选择
网络是很复杂的网状结构,从一个节点到另一个节点,很可能会存在很多路线。
这一点不难理解,大家肯定都用过导航吧?我不信有人还没用过地图。比如当我使用高德地图,输入我想要去的地点,然后就会出现很多条路线选择,这些不同线路会有很多种,有的用时较少,用的花费较少,有的转站较少等等。
我们 IP 协议中的路由选择虽然表面上看起来跟导航的这种路线选择一样,但是它俩本质上是有很大区别的,我们使用软件导航的路线选择,是通过卫星知道整个地图和路线的全貌的,所以它能够快速的计算出 “ 用时 ” “ 成本 ” 各方面的 “ 最优解 ” 。
在我们的 IP 中的路由选择中,每个路由器是无法知道整个网络结构的全貌的,只能知道一小部分(这一 “ 小部分 ” 我们称之为路由表,路由表是路由器内部维护的重要数据结构,类似于 Hash,key 就相当于 IP 地址(网络号),value 就是对应的网络接口(往哪个方向走),IP 数据报达到路由器,就要进行路由表查表操作,查表就是看 IP 数据报中的目的 IP 在路由表中是否存在,如果查到了,就按照路由表中指向的方向继续转发,若没查到,路由表会有一个默认选项:下一跳,会指向一个更高层级的路由器,这个路由器认识的设备范围更广),也就是相邻路由器的情况,所以 IP 协议中的路由选择无法做到 “ 最优解 ” ,只能做到 “ 较优解 ” 。
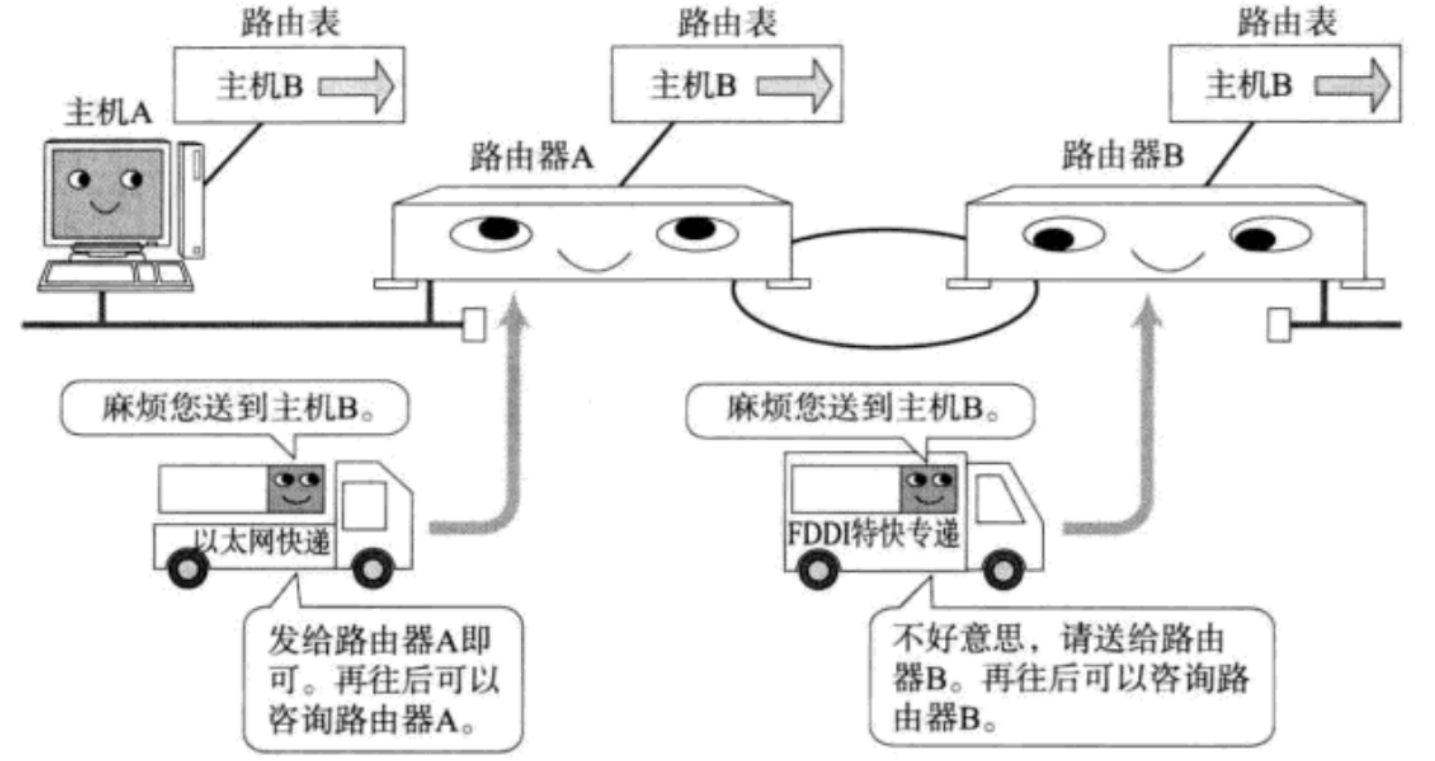
IP 协议中的路由选择就有点像我们在过去那个没有设备没有导航的年代,我们要去一个很远很远的地方,但是我们不知道路,我们就从起点开始,问一个我们旁边的路人,他也不知道终点该往哪里走,具体走哪条路线,但是知道大概在哪个方向,所以咱们就拿着已知信息,顺着这个方向,走了一会儿,走到了下一个城市,咱们又问一个旁边的大哥,他也不知道具体路线,又给我们指了大概方向,咱们又起身前往下一个城市。IP 协议中的路由选择大概就是这种感觉。
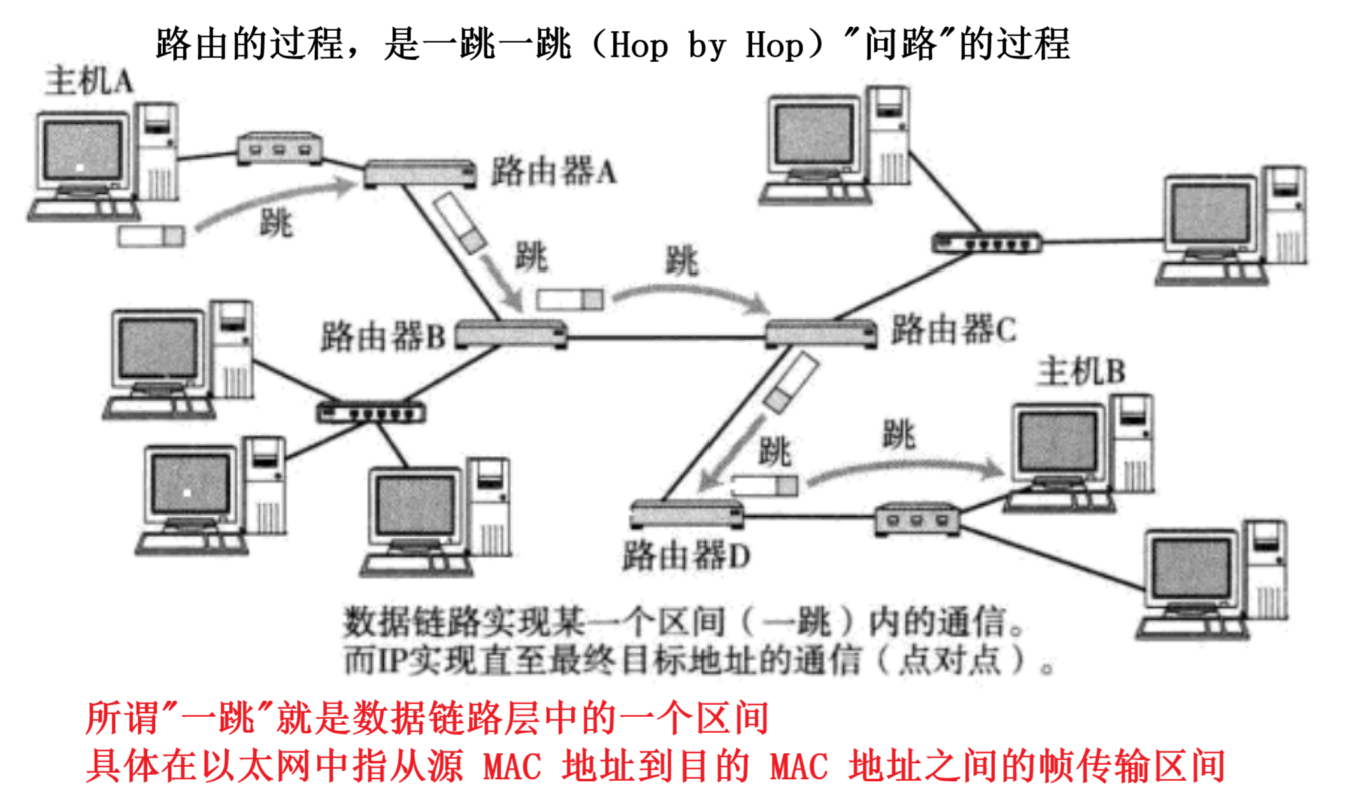
上面我们讨论的过程,我只我为了让大家清晰理解的一个简单的概述,真实的转发过程会更加复杂,真实的网络结构(尤其是广域网)是非常非常复杂的。
四 . 数据链路层
(1)认识以太网
1 . “ 以太网 ” 不是一种具体网络,而是一种技术标准,既包含了数据链路层的内容,也包含了一些物理层的内容。例如:规定了网络拓扑结构,访问控制,传输速率等等。
2 . 以太网中的网线必须使用双绞线,传输速率有 10 M、100 M、1000M 等。
3 . 以太网是当前应用最广泛的局域网技术,和以太网并列的还有令牌环网,无线 LAN 等。
(2)以太网帧格式

MAC 地址与 IP 地址的区别:
1 . MAC 地址使用 6 字节表示,而 IP 地址是 4 个字节:
从空间范围上来说,整整比 IP 地址大了 6w 多倍。MAC 地址当前仍可以给每一个设备都分配一个唯一的 MAC 地址值,一般一个网卡,在出厂的时候,MAC 地址就被分配好了,就写死了,不能够更改。所以 MAC 地址也可以作为设别的身份标识。
2 . 适用的场景不同
MAC 地址的使用在数据链路层,用来实现两个相邻设备之间的数据转发。(微观)
IP 地址的使用在网络层,立足于整个转发流程,进行路径规划。(宏观)
五 . DNS 应用层协议
DNS 是一整套从域名映射到 IP 的系统,“ 域名 ” 也就是 “ 网名 ”,代表了 IP 地址。这两者之间存在着对应关系,一般是一个域名对应一个或者多个 IP ,也可能存在多个域名对应一个 IP 。
咱们都知道,我们的 IP 地址是点分十进制表示的,但是这样还是对人类不够友好,所以咱们进一步转换成,用单词字符串来表示 IP 地址。而把 “ 域名 ” 转化为 “ IP地址 ” 这样的一套系统,就称为域名解析系统。
早期的域名解析系统,非常简单,是通过一个简单的文件来实习的:hosts,这一文本文件就记录了 IP 地址与域名之间的对应关系。但是这种方法如今基本不用了(虽然仍然有效)。
为什么不实用了呢?因为我们时代的变迁,科技的飞速发展,这种靠文件来维护的方式已经不能满足我们的需求了。网站太多了,域名也有很多,IP 地址也有很多,靠文件来维护,不现实也不够方便。为了解决上述问题,DNS 服务器就应运而生了。将 hosts 文件放在 DNS 服务器里,当某个电脑需要进行域名维护的时候,就访问 DNS 服务器即可。
这个时候可能就有小伙伴要问了,全世界这么多设备上网,每时每刻都在访问 DNS 服务器,服务器能抵挡这么大访问流量的冲击嘛?咱们采取的应对方案是,多搞出一些 DNS 服务器即可,这些多出来的 DNS 服务器我们称之为 “ 镜像服务器 ” ,事实上,全世界有着数不清的镜像服务器,往往都是一些运行商 / 互联网公司进行维护的。每个人上网的时候,都会就近访问 DNS 服务器。
此时有数据需要变更怎么办呢?一旦有数据需要变更,就修改这个基准服务器,其他服务器就会从基准的服务器同步数据。这一基准服务器我们称之为 “ 根服务器 ”。
全球一共有 13 台这种 “ 根服务器 ” ,其中漂亮国占 10 台,咱们国家没有。理论上来说,只要美丽国将一个国家的域名里的数据从根服务器中删掉, 就意味着这个国家的网络就会陷入瘫痪,大家注意,这是历史真实发生过的事件,比如:2003年的伊拉克战争、2004年的叙利亚事件、2021年的伊朗网络查封事件。
这也就是我在上一期提到过的为什么咱们国家会在 15 年的雪人计划中大力部署了 4 台 IPv6 根服务器,就是为了避免这种情况发生,更断绝某些国家想要在网络领域卡我们脖子的想法。
OKK,今天的内容就说这么多了,有关网络原理及编程的板块咱们也就聊这么多了。这一部分的知识都是抽象概念,诸君还需融入自己的理解,话不多说,咱们下期再见吧,与诸君共勉!!!