vllm eagle支持分析
1、eagle支持存在的问题
(1)增加了eagle后,vllm速度反而变慢,在此issue有跟踪
[Performance]: vllm Eagle performance is worse than expected · Issue #9565 · vllm-project/vllm · GitHub
(2)该提出者对比vllm官方和eagle实现后,进行部分修复,提高了了速度,但不如不使用eagle的vllm,此PR 1月11已经合并至 master分支

2、 源码分析
batch_expansion.py
class BatchExpansionTop1Scorer(SpeculativeScorer):"""Implements a speculative scorer that uses batch expansion to getprobabilities of speculative tokens according to the scoring model.Batch expansion converts a list of sequences and multiple query positionsto a new batch of sequences, each with a single query position. This allowsfor MQA-like scoring in speculative decoding without requiring an MQAkernel.It is strictly less efficient than MQA scoring.It only supports scoring the top1 proposal tokens of the proposer, insteadof topk/tree.- 替代topk/tree,批量,每个query只有一个位置,类似MQA,但又没有使用MQA内核
- SpeculativeScorer为接口
1. 核心功能概述
作用:使用 batch expansion 技术,将原始序列和多个提议 token 扩展成一个新批次,每个序列对应一个查询位置,从而实现对每个提议 token 的评分。
适用场景:适用于不支持 MQA(Multi-Query Attention)核函数的硬件或模型。
性能对比:相比 MQA 评分效率更低。
2. 主要调用流程
2.1 入口方法 score_proposals
def score_proposals(self,execute_model_req: ExecuteModelRequest,proposals: SpeculativeProposals,
) -> SpeculativeScores:
输入参数:
- execute_model_req: 当前执行请求。
- proposals: 提议的 token 及其长度信息。
输出:经过评分后的 SpeculativeScores。
2.2 数据预处理与过滤
将提议 token 和长度转换为 Python 列表。
去除包含无效 token ID (VLLM_INVALID_TOKEN_ID) 的提议
2.3 调用 _expand_batch
功能:根据提议 token 扩展原始 batch。
返回值:
spec_indices: 需要评分的序列索引。
non_spec_indices: 不需要评分的序列索引。
target_seq_group_metadata_list: 新生成的扩展后序列组元数据列表。
num_scoring_tokens: 总共需要评分的 token 数量。
2.4 模型推理
使用扩展后的 seq_group_metadata_list 构造新的执行请求并调用模型进行推理。
2.5 结果合并与返回
根据是否有非评分序列选择不同的合并策略
3. 关键辅助方法
3.1 _expand_batch
功能:创建一个新的 batch,每个序列只包含一个 query token。
关键步骤:
使用 split_batch_by_proposal_len 拆分原始 batch。
对每个需要评分的序列调用 _create_scoring_model_input 创建目标序列。
3.2 _create_scoring_model_input
功能:为每个原始序列创建多个目标序列,用于评分。
3.3 _contract_batch
功能:将扩展后的 batch 输出结果映射回原始 batch。
关键操作:
使用 reshape 将输出 tensor 重新组织为 [batch_size, k+1]。
将评分结果填充到 SpeculativeScores 对象中。
3.4 _contract_non_speculative
功能:处理不需要评分的序列输出,如 prefill 请求或未启用 speculation 的 decode 请求。
4. 流程图示意
score_proposals
├── 数据准备 & 过滤无效提议
├── 调用 _expand_batch 扩展 batch
│ ├── split_batch_by_proposal_len 分离 spec/non-spec 序列
│ └── create_scoring_model_input 创建目标序列
├── 模型推理 (execute_model)
└── 合并输出├── contract_batch_all_spec 或 contract_batch└── contract_non_speculative 处理非评分序列
5. 设计考量与优化点
批量扩展 vs 单次推理:虽然效率较低,但避免了对特殊核函数(如 MQA)的依赖。
内存优化:使用 reshape 和 indexing 避免显式复制大量 tensor。
兼容性:支持 chunked prefill、prompt logprobs 等高级特性。
(1)test_batch_expansion.py 分析
1. 测试用例:test_create_target_seq_id_iterator
每次生成 100 个目标序列 ID。
🔍 验证点
确保所有新生成的序列 ID 都大于输入的所有原始序列 ID。
📌 关键逻辑
调用了 BatchExpansionTop1Scorer._create_target_seq_id_iterator(seq_ids) 方法:
为每个需要评分的新序列分配一个唯一的、大于所有原始 seq_id 的 ID。
这是防止序列 ID 冲突的重要机制。
问题:为什么要大于原始序列ID?
2. 测试用例:test_get_token_ids_to_score
🧪 参数化
测试不同长度的提议 token 数量(k=1、2、6)。
🔍 验证点
确认 _get_token_ids_to_score 正确返回了用于评分的 token IDs 列表。
📌 示例输入
draft_model_runner.py
draft_model_runner.py 是 vLLM 中用于实现 Speculative Decoding 的 draft 模型推理核心模块,主要负责在 GPU 上高效运行 draft model 来生成多个 speculative tokens。它通过避免频繁的 CPU-GPU 数据传输和序列化操作来提升性能。
📌 文件概览
文件结构
实现了 TP1DraftModelRunner 类
包含 GPU 多步前向传播、输入更新、条件判断等关键逻辑
支持 Flash Attention 和部分优化策略(如 skip sampler cpu output)
目标
高效地在 GPU 上连续执行多个 forward pass,生成 k 个 speculative tokens。
减少 speculative decoding 过程中的通信开销和同步延迟。
🔍 核心类:TP1DraftModelRunner
🧱 继承关系:
class TP1DraftModelRunner(ModelRunnerWrapperBase)
✨ 特性支持:
仅支持 decode 模式(不支持 prefill)
仅支持 FlashAttention 后端(当前限制)
不支持 LoRA / Prompt Adapter(目前限制)
⚙️ 主要方法分析
1. supports_gpu_multi_step()
功能
判断是否可以使用 GPU multi-step 推理。
✅ 支持条件:
仅 decode 模式(无 prompt)
使用 FlashAttention 或 Triton MLA 后端
无 LoRA / Prompt Adapter
当前 TP = 1(暂不支持多 TP)
⚠️ TODO
支持其他 attention backend
支持 LoRA
支持 Prompt Adapter
2. _gpu_advance_step()
功能
根据上一步的输出 token 更新模型输入张量,准备下一步的 forward pass。
🧠 关键操作:
更新 attn_metadata
更新 sampling_metadata
构造新的 model_input
跳过 sampler 的 CPU 输出(节省时间)
支持 Tensor Parallelism=1
📈 性能优化点:
输入数据始终保留在 GPU 上
避免重复的 CPU 到 GPU 数据拷贝
复用 sampling tensors
# Update attn_metadataattn_metadata = model_input.attn_metadataassert isinstance(attn_metadata, FlashAttentionMetadata)attn_metadata.advance_step(model_input, sampled_token_ids,self.block_size, num_seqs, num_queries)# Update sampling_metadatasampling_metadata = model_input.sampling_metadataself._update_sampling_metadata(sampling_metadata, num_seqs,num_queries)# Create new inputnew_model_input = self._model_input_cls(input_tokens=model_input.input_tokens,input_positions=model_input.input_positions,attn_metadata=attn_metadata,seq_lens=attn_metadata.seq_lens,query_lens=model_input.query_lens,lora_mapping=model_input.lora_mapping,lora_requests=model_input.lora_requests,multi_modal_kwargs=model_input.multi_modal_kwargs,sampling_metadata=model_input.sampling_metadata,is_prompt=False,)问题:这段代码比较难以理解
- attn_metadata需要更新吗?
- 构建的输入是否包含attention_mask
3. execute_model()
功能
执行 num_steps 步前向传播,返回每一步的 SamplerOutput。
🔄 核心流程:
检查限制条件
TP > 1 不支持
LoRA / Prompt Adapter 不支持
Multi-modal 不支持
初始化参数
设置 active loras(如果启用)
开始注意力计算上下文
执行 num_steps 步推理
如果启用 CUDA Graph,则使用图执行
否则逐次调用模型并采样输出
处理 bonus token(如果有)
修正 bonus token 对应位置的输出值(防止错误覆盖)
🧪 示例调用:
model_outputs = draft_model_runner.execute_model(execute_model_req=expanded_request,kv_caches=kv_caches,num_steps=sample_len
)
📊 性能优化点总结


 如果启用了 CUDA Graph,则从缓存中取出已编译的图模型
如果启用了 CUDA Graph,则从缓存中取出已编译的图模型
否则使用原始模型进行推理
with set_forward_context(model_input.attn_metadata,self.vllm_config):hidden_states = model_executable(input_ids=model_input.input_tokens,positions=model_input.input_positions,intermediate_tensors=intermediate_tensors,**MultiModalKwargs.as_kwargs(multi_modal_kwargs,device=self.device),**model_execute_kwargs,)🔍 关键点:
使用 set_forward_context(attn_metadata) 设置当前的注意力上下文
调用模型进行前向传播,得到 hidden_states
计算 logits 并通过 sampler 采样下一个 token
更新 model_input 为下一步准备新的 attention 元数据
🧠 注意力构造的核心方法:_gpu_advance_step()
这个方法负责在 GPU 上更新 attention metadata,使得每一步的前向传播都能正确地基于上一步的结果继续执行。
️ 功能详解:
更新 attn_metadata:调用 advance_step(...) 方法,将新采样的 token 加入 KV Cache
构建新的 ModelInput:包含更新后的 attention 元数据、token IDs、位置信息等
跳过 CPU 输出:为了性能优化,直接在 GPU 上操作,避免频繁拷贝
示例:Attention Metadata 更新流程
# 初始输入
model_input = {input_tokens,input_positions,attn_metadata: FlashAttentionMetadata(...)
}# 第一次 forward
hidden_states = model(input_tokens, input_positions, attn_metadata)
output = sampler(hidden_states)
new_model_input = _gpu_advance_step(model_input, output)# 第二次 forward 使用更新后的 attn_metadata
hidden_states = model(new_model_input.input_tokens, new_model_input.input_positions, new_model_input.attn_metadata)
...
在 vLLM 的 draft_model_runner.py 中,TP1DraftModelRunner._gpu_advance_step() 方法中调用了 attn_metadata.advance_step(...) 来更新注意力机制的元数据。这一操作是构建 speculative decoding 多步推理流程中的关键步骤。
🔍 分析目标:FlashAttentionMetadata.advance_step()
该方法定义在:
vllm/attention/backends/flash_attn.py
📌 advance_step() 的核心逻辑
以下是基于 FlashAttentionMetadata.advance_step() 的典型实现(伪代码):
def advance_step(self, model_input, sampled_token_ids, block_size, num_seqs, num_queries):# Step 1: 更新 slot mapping(slot 映射)# 将当前新生成的 token 放入下一个可用 slotself.slot_mapping = torch.cat([self.slot_mapping, next_slot_indices], dim=0)# Step 2: 更新 seq_lens(每个序列的长度)self.seq_lens += 1 # 每个序列都增加了 1 个 token# Step 3: 更新 block tables(KV Cache 块表)for i in range(num_seqs):if self.seq_lens[i] % block_size == 0:# 需要分配新的 blocknew_block_idx = allocate_new_block()self.block_tables[i].append(new_block_idx)# Step 4: 更新 context length(上下文长度)self.context_len += num_queries # 所有 query 各增加一个 token# Step 5: 更新其他 metadata(如 batch size 等)...
注意力机制更新的关键组件
1. Slot Mapping
每个 token 在 GPU 缓存中都有一个唯一的 slot index。
新生成的 token 会被映射到一个新的 slot。
slot_mapping 是一个 tensor,记录了当前所有 token 对应的缓存位置。
⚠️ 重要优化点:避免频繁从 GPU 拷贝回 CPU,直接在 GPU 上维护这些索引。
2. Sequence Lengths (seq_lens)
记录每个序列的当前长度。
每次调用 advance_step() 都会加 1。
3. Block Tables
每个序列的 KV 缓存由多个 block 构成。
当当前 block 已满时,需为序列分配新的 block。
block_tables 是一个 list of lists,记录每个序列使用的 block indices。
4. Context Length
表示当前 attention 操作的上下文长度。
在多步 speculative decoding 中,每步都会扩展这个值。

 📚 参考文档
📚 参考文档
Flash Attention Paper (DAO et al.)
vLLM Attention Implementation
Speculative Decoding Paper (Lehman et al.)
问题:
- flash attention可能与经典的注意力机制不一样
Debug
prepare_model_input


spec_decode_worker.py

这里scorer_worker为woker_base,输出为

hidden_states维度,1x3584
self.previous_hidden_states is None,根据hidden_states构建previous_hidden_states
sampler_output.prefill_hidden_states,5x3584
execute_model_req.previous_hidden_states 同上
_num_spec_prefill_steps为1

第二次从这里进入:

 attn_state是个复杂的对象
attn_state是个复杂的对象
attn_metadata没有变化
 草稿的一次前向
草稿的一次前向

 hidden_states维度为5x3584
hidden_states维度为5x3584
计算logits输出token
 使用默认的Runner
使用默认的Runner
得到一个output_token
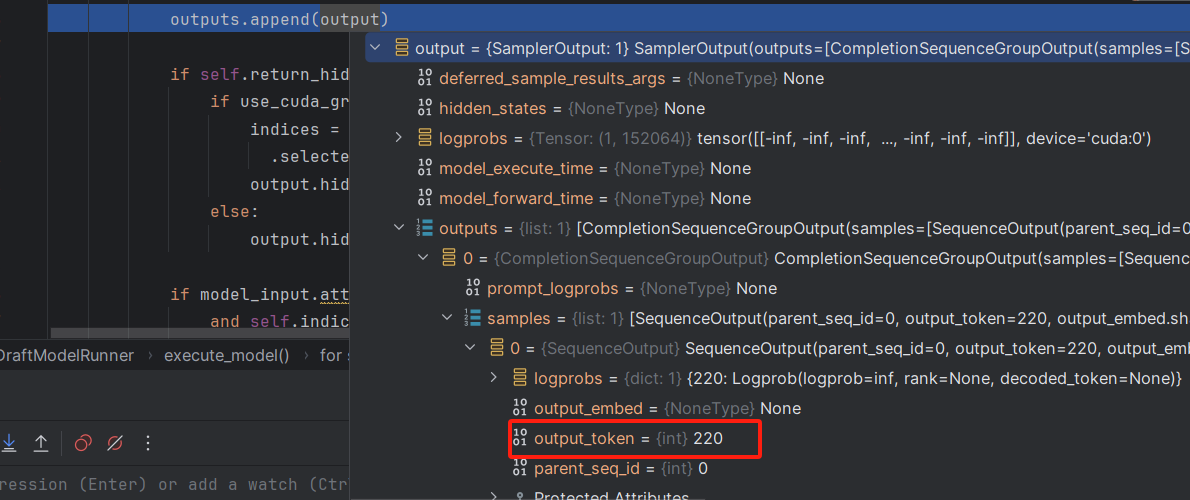 怎么到下面这里就变成1602了?
怎么到下面这里就变成1602了?
增加一条token

注意这里可以是多个请求序列:
 llm_engine中这里终于执行完了
llm_engine中这里终于执行完了
草稿生成第一个token后,no_spec为Fase,继续走草稿生成。
这时候使用use_cuda_graph了(为什么?)

graph_batch_size为1,这个操作的目的是扩充到batch_size张量大小。使用空的值填充
attn_metadata依旧没有变化
 这时input_ids为1602,batch_size能否修改为2
这时input_ids为1602,batch_size能否修改为2

draft_model前向4次获得4个token
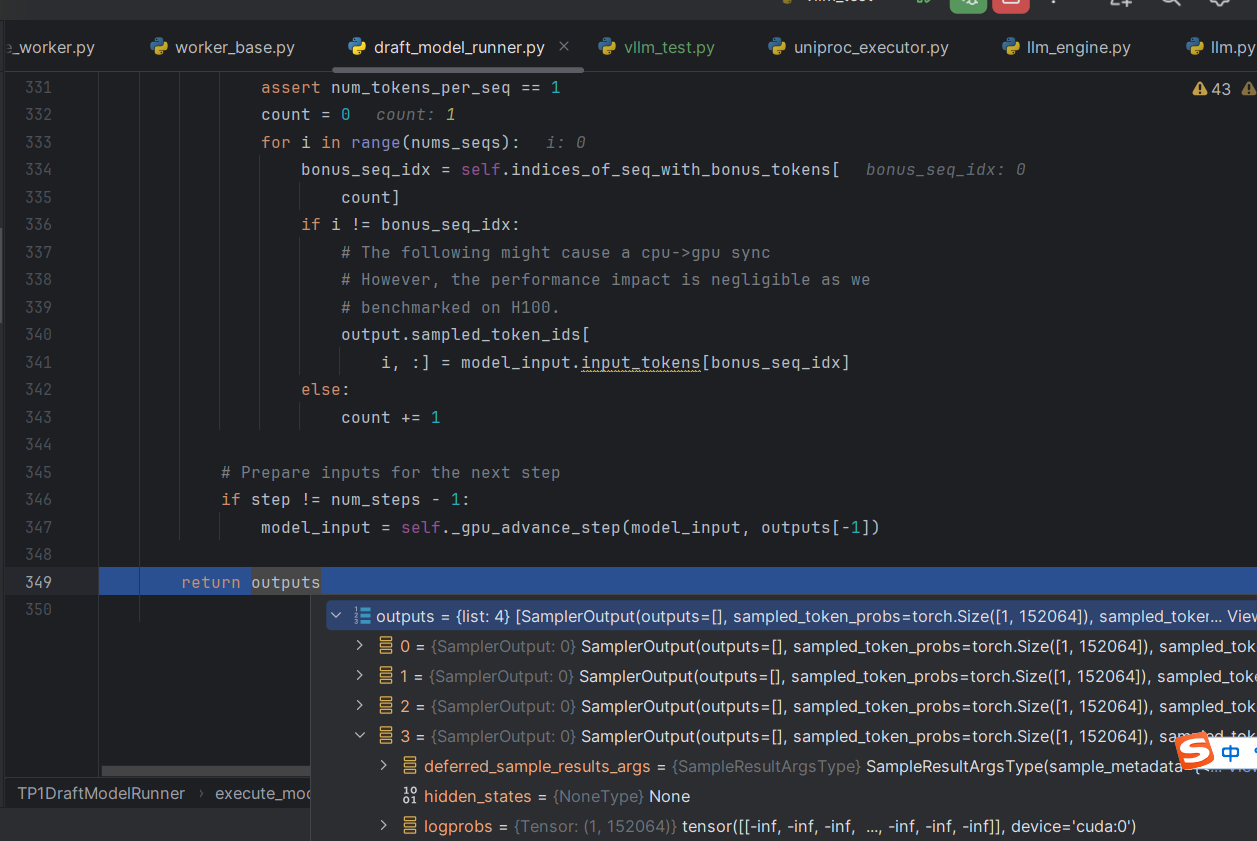 top1_proposer.py
top1_proposer.py

4个token和概率


进行top1scorer
 到了batch_expansion了。
到了batch_expansion了。
 这里有几个重要信息。
这里有几个重要信息。

第一个token为target模型生成
后面4个token为草稿生成,这里面output_token_ids逐步从1602到1602,...198

 构建target_model的输入:
构建target_model的输入:
Input_tokens长度为5个有效的,3个为0? input_positions从5开始编号。

为什么seq_lens和query_lens的值是这样?代表什么意思
 worker_base中 执行一次目标模型前向,获得这5个token的logprobs
worker_base中 执行一次目标模型前向,获得这5个token的logprobs

开始验证tokens


下一次根据9906作为输入,相当于草稿没有接受,使用目标模型的输出
 hidden_states重置
hidden_states重置
自定义注意力改造
1、attention_mask分析
在flash_attention中attention_mask是没有用到的
def compute_slot_mapping(is_profile_run: bool, slot_mapping: List[int],seq_id: int, seq_len: int, context_len: int,start_idx: int, block_size: int,block_tables: Dict[int, List[int]]):"""Compute slot mapping."""if is_profile_run:# During memory profiling, the block tables are not# initialized yet. In this case, we just use a dummy# slot mapping.# In embeddings, the block tables are {seq_id: None}.slot_mapping.extend([PAD_SLOT_ID] * seq_len)return# Mask the [0, start_idx) tokens of the prompt with# PAD_SLOT_ID, where start_idx is max(0, seq_len -# sliding_window). For example, if the prompt len is 10,# sliding window is 8, and block size is 4, the first two# tokens are masked and the slot mapping will be# [-1, -1, 2, 3, 4, 5, 6, 7, 0, 1].padding_mask_len = max(0, start_idx - context_len)slot_mapping.extend([PAD_SLOT_ID] * padding_mask_len)range_start = max(start_idx, context_len)range_end = seq_lennumel = range_end - range_startblock_table = block_tables[seq_id]# numpy implementation will be faster than python if we have# many elements, otherwise it will be slower.if numel < _COMPUTE_SLOT_MAPPING_NUMPY_NUMEL:_compute_slot_mapping_python(slot_mapping, block_table, range_start,range_end, block_size)else:_compute_slot_mapping_numpy(slot_mapping, block_table, range_start,range_end, block_size)TAttentionMetadata = TypeVar("TAttentionMetadata", bound='AttentionMetadata')

问题1:block_tables和注意力、kvcache之间的关系
问题:如何参考attention_mask树注意力实现vllm的注意力
eagle2的实现中,通过将id扁平化为1d,如it is has a the 这几个token,对应的input_ids为[203, 66, 888, 46, 52]。草稿阶段有[it, it is, it has, it is a, it is the]5条路径,转成ids路径为[[203],[203, 66], [203, 888], [203, 66, 46], [203, 66, 52] ]要验证这几条路径的概率,可在prefill阶段,通过transformer的attention_mask实现,其掩码矩阵为[[1, 0, 0, 0, 0], [1, 1, 0, 0, 0], [1, 0, 1, 0, 0, 0], [1, 1, 0, 1, 0], [1, 1, 0, 0, 1]]。 然而在vllm中,通过padding_mask构造slot_mapping替代了attention_mask,请问如何在vllm中的prefill阶段,做一次前向计算实现以上掩码替代,计算这几条id路径的概率计算,且保持batch_size的维度为1
qwen3-thinking模式效果最好:
#优化以上方案,input_ids 扁平化的时候 token可以复用吗,总长度能否控制为token数目
在 vLLM 中优化 Eagle2 的多路径验证时,可通过 共享 token 前缀 和 差分路径表示 实现 input_ids 扁平化复用,将总长度从 Σ(path_len) 降低至 unique_tokens。以下是优化方案
1. 输入构造:共享前缀 + 差分后缀
(1) 原始路径
paths = [[203], # path0: [it][203, 66], # path1: [it, is][203, 888], # path2: [it, has][203, 66, 46], # path3: [it, is, a][203, 66, 52] # path4: [it, is, the]
]
(2) 共享前缀提取
公共前缀:[203](所有路径共享)
差分后缀:每个路径仅存储与前缀的差异部分:
diffs = [[], # path0: 无差异[66], # path1: + [is][888], # path2: + [has][66, 46], # path3: + [is, a][66, 52] # path4: + [is, the]](3) 扁平化输入
共享部分:仅存储一次 [203]
差分部分:按路径拼接
input_ids = [203, 66, 888, 46, 52] # 总长度 = 5(而非 11)2. Slot Mapping 构造:共享槽位分配
(1) 共享前缀槽位
公共前缀 [203] 分配槽位 0
所有路径均引用该槽位
(2) 差分路径槽位
每个差分路径分配独立槽位范围:
path_slots = {0: [0], # path0: 仅共享前缀1: [0, 1], # path1: 共享 [0] + 差分 [1]2: [0, 2], # path2: 共享 [0] + 差分 [2]3: [0, 1, 3], # path3: 共享 [0] + 差分 [1, 3]4: [0, 1, 4] # path4: 共享 [0] + 差分 [1, 4]}(3) 最终 slot_mapping
每个路径的 token 映射到共享或独立槽位:
slot_mapping = [# path0: [0, -1, -1, -1, -1] → 只需 1 个有效槽位0, -1, -1, -1, -1,# path1: [0, 1, -1, -1, -1] → 共享 0, 差分 10, 1, -1, -1, -1,# path2: [0, 2, -1, -1, -1] → 共享 0, 差分 20, 2, -1, -1, -1,# path3: [0, 1, 3, -1, -1] → 共享 0, 差分 1,30, 1, 3, -1, -1,# path4: [0, 1, 4, -1, -1] → 共享 0, 差分 1,40, 1, 4, -1, -1]3. Block Tables 构造:共享块隔离
(1) 共享块管理
公共前缀 [203] 存储在块 0
每个差分路径分配独立块:
block_tables = {0: [0], # path0: 仅共享块 01: [0, 1], # path1: 共享块 0 + 差分块 12: [0, 2], # path2: 共享块 0 + 差分块 23: [0, 1, 3], # path3: 共享块 0 + 差分块 1,34: [0, 1, 4] # path4: 共享块 0 + 差分块 1,4}(2) 块大小假设
块大小 block_size = 4,每个块可容纳多个 token
4. 前向计算与概率提取
(1) 输入参数构造
# 扁平化 input_ids 长度为 5(而非 11)
model_input = {"input_ids": torch.tensor([input_ids], dtype=torch.long), # shape: [1, 5]"slot_mapping": torch.tensor([slot_mapping], dtype=torch.long), # shape: [1, 25]"block_tables": block_tables,"seq_lens": [5], # 总 token 数量"query_lens": [1, 2, 2, 3, 3], # 各路径有效长度
}
(2) 概率提取逻辑
定位路径结束位置(基于差分路径的槽位):
path_end_indices = [0, 1, 2, 3, 4] # 对应槽位 [0, 1, 2, 3, 4]# 提取概率path_probs = []for idx in path_end_indices:token_logits = logits[0, idx, :] # shape: [vocab_size]probs = torch.softmax(token_logits, dim=-1) # 归一化path_probs.append(probs)
问题3:多条路径会增大vllm计算开销吗
另外若只有一条路径(一般情况的prefill),即input_ids = [203, 66, 888, 46, 52] ,其block_tables和slot_mapping如何构建,对比下速度怎么样
1. 多条路径是否会增大 vLLM 计算开销?
(1) 开销来源分析
内存开销:
KV Cache 占用:多路径需要为每条路径分配独立的物理槽位(slot),即使共享前缀(如 it)也无法复用 KV Cache(除非显式共享)。
Slot Mapping 和 Block Tables:需要额外存储多路径的映射关系(如 slot_mapping 长度为 max_seq_len * num_paths)。
计算开销:
Attention 计算:多路径的 query_len 总和增加(如 5 条路径总 query_len=1+2+2+3+3=11),导致注意力矩阵计算量上升。
并行效率:vLLM 的注意力计算基于 CUDA 核函数,理论上支持多路径并行,但受限于硬件资源(如 GPU 显存带宽),实际加速比可能低于理论值。
(2) 优化后的开销对比
共享前缀复用:若显式共享前缀(如 it),可复用其 KV Cache,减少重复计算。
块表隔离:通过 block_tables 隔离路径上下文,避免跨路径干扰,但需额外管理块表。

2. 单路径场景下的 Slot Mapping 与 Block Tables 构建
(1) 输入定义
扁平化输入:input_ids = [203, 66, 888, 46, 52]
序列长度:seq_len = 5
(2) Slot Mapping 构造
逻辑:所有 token 顺序分配槽位,无填充。
代码实现:
slot_mapping = [0, 1, 2, 3, 4] # 每个 token 对应唯一槽位 (3) Block Tables 构造
块大小:假设 block_size = 4
分配逻辑:按槽位顺序分配块号
block_tables = {0: [0, 1] # 块0: 槽位0-3,块1: 槽位4-7(实际仅用槽位4)}备注:相当于这条路径有两个块
(4) 输入参数构造
model_input = {"input_ids": torch.tensor([input_ids], dtype=torch.long), # shape: [1, 5]"slot_mapping": torch.tensor([slot_mapping], dtype=torch.long), # shape: [1, 5]"block_tables": block_tables,"seq_lens": [5],"query_lens": [5], # 单路径无需差分长度
}

 问题4:vllm中如何实现稀疏注意力的
问题4:vllm中如何实现稀疏注意力的
在 vLLM 中实现稀疏注意力的核心机制依赖于 Slot Mapping 和 Block Tables 的物理缓存管理策略。与传统的 attention_mask 不同,vLLM 通过 隐式映射 实现稀疏注意力,避免显式构造掩码矩阵,从而提升计算效率。以下是具体实现方式1. 核心机制:Slot Mapping 与 Block Tables
(1) Slot Mapping
作用:将每个 token 映射到物理缓存槽位(slot ID),无效位置用 PAD_SLOT_ID (-1) 标记。
实现逻辑:
有效 token 分配唯一槽位(如 0, 1, 2, ...)。
无效 token(需屏蔽的位置)标记为 -1,不参与注意力计算。
示例:
# 假设输入序列长度为5,需屏蔽第2个和第4个tokeninput_ids = [203, 66, 888, 46, 52]slot_mapping = [0, 1, -1, 2, -1] # 仅槽位0,1,2有效(2) Block Tables
作用:管理物理缓存块(block)的分配,每个块包含固定数量的槽位(如 block_size=4)。
实现逻辑:
槽位按块分配,例如槽位 0-3 属于块0,槽位 4-7 属于块1。
通过 block_tables 显式指定每个序列使用的块列表。
示例:
block_tables = {0: [0, 1] # 序列0使用块0和块1(槽位0-3, 4-7)}2. 稀疏注意力的实现步骤
(1) 输入构造
将需要关注的 token 扁平化为一维数组,并标记无效位置:
input_ids = [203, 66, 46] # 有效 token 为 [it, is, a]
# 对应原始序列 [it, is, has, a, the] 中的稀疏选择
(2) Slot Mapping 构造
为有效 token 分配槽位,无效位置填充 -1:
# 假设最大序列长度为5,屏蔽第2个和第4个token
slot_mapping = [0, 1, -1, 2, -1] # 有效槽位为0,1,2
(3) Block Tables 构造
按槽位分配物理块:
# 块大小为4,槽位0-3属于块0,槽位4-7属于块1
block_tables = {0: [0, 1] # 序列0使用块0和块1
}
(4) 输入参数配置
将上述参数传递给模型:
model_input = {"input_ids": torch.tensor([input_ids], dtype=torch.long),"slot_mapping": torch.tensor([slot_mapping], dtype=torch.long),"block_tables": block_tables,"seq_lens": [5], # 实际序列长度(含填充)"query_lens": [3] # 有效 token 数量
}
问题5:分析下,为什么槽位数目为5,按block_size为4计算,只有2个块,为什么block_tables中差分块可以为4?在vllm中多条路径是并行计算的吗

 2、实际前向
2、实际前向





这里长度变为4