GPU架构对大模型推理部署到底有什么影响?
一、问题
实际生产中我们在阿里云租用GPU云服务器,面对那么多服务器应该怎么选择相关物理配置?
二、 GPU
2.1 GPU是什么
GPU的英文全称Graphics Processing Unit,图形处理单元。
说直白一点:GPU是一款专门的图形处理芯片,做图形渲染、数值分析、金融分析、密码破解,以及其他数学计算与几何运算的。GPU可以在PC、工作站、游戏主机、手机、平板等多种智能终端设备上运行。
GPU和显卡的关系,就像是CPU和主板的关系。前者是显卡的心脏,后者是主板的心脏。有些小伙伴会把GPU和显卡当成一个东西,其实还有些差别的,显卡不仅包括GPU,还有一些显存、VRM稳压模块、MRAM芯片、总线、风扇、外围设备接口等等。
2.2 GPU和CPU有什么区别
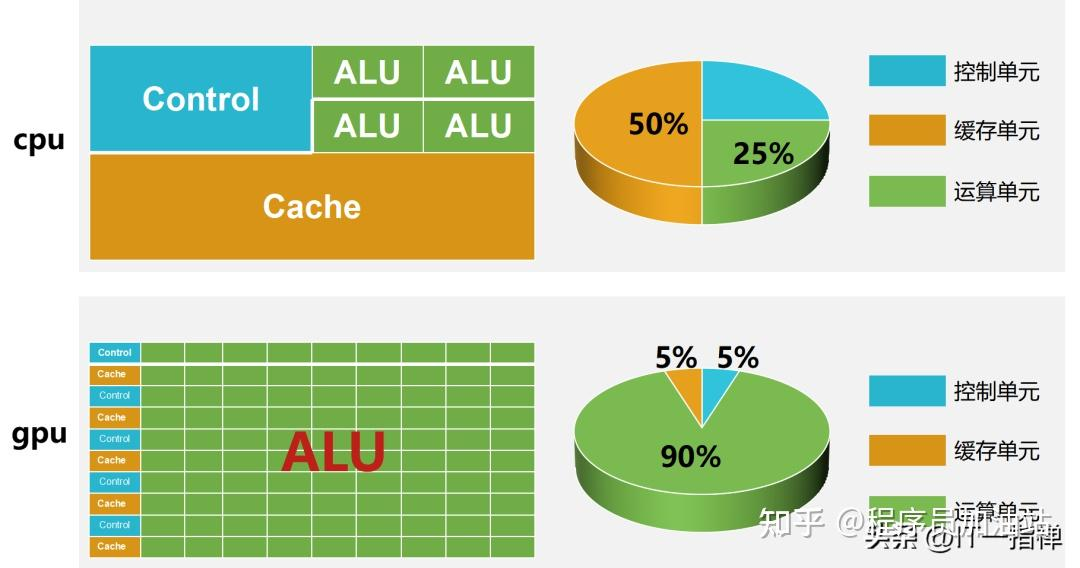
CPU和GPU都是运算的处理器,在架构组成上都包括3个部分:运算单元ALU、控制单元Control和缓存单元Cache。
但是,三者的组成比例却相差很大。
在CPU中缓存单元大概占50%,控制单元25%,运算单元25%;
在GPU中缓存单元大概占5%,控制单元5%,运算单元90%。

三、GPU与CPU的核心区别
| 特性 | CPU | GPU |
|---|---|---|
| 核心数量 | 通常4-128核心 | 数千至上万计算核心 |
| 核心设计 | 复杂指令集/高时钟频率 | 精简指令集/高度并行化 |
| 内存带宽 | 50-200 GB/s | 600-3000 GB/s (如H100) |
| 适用场景 | 串行逻辑/控制流 | 大规模并行计算 |
| 典型负载 | 操作系统/通用计算 | 矩阵运算/张量处理 |
关键差异:GPU通过SIMT架构(单指令多线程)实现海量线程并行,其显存带宽可达CPU的15倍以上,对百亿参数模型的权重加载速度具有决定性影响。
四、GPU内部架构深度解析
以NVIDIA Ampere架构为例:
┌───────────────────────┐ │ GPU Architecture │ ├───────────┬───────────┤ │ Streaming Multiprocessor (SM) │ │ ├─ CUDA Cores (64-128/SM) │ │ ├─ Tensor Cores (4-8/SM) │ → 混合精度矩阵加速 │ ├─ Shared Memory (192KB/SM) │ → 线程块通信 │ └─ L1 Cache/Register File │ ├───────────┼───────────┤ │ Memory Hierarchy │ │ ├─ HBM2/HBM3 (显存) │ → 80%能耗源于数据搬运 │ ├─ L2 Cache (40-80MB) │ → 降低全局内存访问延迟 │ └─ GDDR6X/HBM2e接口 │ └───────────┴───────────┘
核心组件作用:
- Tensor Core:专用硬件加速FP16/BF16/INT8矩阵乘加运算,使Transformer层的计算速度提升6-12倍
- 共享内存:实现线程块内高速数据共享,优化Attention计算中的KV缓存访问
- 异步拷贝引擎:计算与数据加载并行,隐藏内存延迟
五、GPU架构演进关键里程碑
| 架构世代 | 推出年份 | 技术突破 | 推理性能提升 |
|---|---|---|---|
| Fermi | 2010 | 首个支持ECC显存 | 基础架构 |
| Kepler | 2012 | 动态并行化 | 2.1x |
| Maxwell | 2014 | 能效比优化 | 3.5x |
| Pascal | 2016 | 首次支持FP16 | 5.8x → 大模型起点 |
| Volta | 2017 | 首代Tensor Core/ NVLink | 12x → Transformer时代 |
| Turing | 2018 | INT8/稀疏化支持 | 18x |
| Ampere | 2020 | 稀疏矩阵加速/ MIG技术 | 30x → GPT-3部署主力 |
| Hopper | 2022 | FP8精度/ Transformer引擎 | 50x → 千亿级模型 |
关键转折点:Volta架构引入的Tensor Core使Transformer层计算效率产生质的飞跃,而Ampere的稀疏化特性使LLM推理吞吐量提升3倍。
六、架构特性对推理部署的具体影响
-
计算能力维度
- Tensor Core代数:Hopper的第四代TC支持FP8,使175B模型推理速度提升80%
- SM数量倍增:A100 (108SM) vs V100 (80SM) → 同batch size延迟降低40%
-
内存子系统
# 带宽瓶颈示例:GPT-3 175B模型 model_size = 175e9 * 2Bytes (FP16) # 350GB显存需求 A100_bandwidth = 2TB/s → 理论加载时间 = 350GB / 2TB/s = 0.175s V100_bandwidth = 900GB/s → 0.389s (相差2.2倍)- HBM3显存(如H100的3.2TB/s)可将千亿模型加载时间压缩至秒级
-
互连技术
- NVLink 3.0:600GB/s双向带宽,使多卡推理通信开销从15%降至3%
- PCIe 5.0 vs 4.0:带宽翻倍(64GB/s → 128GB/s),减少CPU-GPU数据传输时延
-
专用加速单元
- Hopper的Transformer引擎:自动切换FP8/FP16精度,使Attention计算能效比提升30%
- 结构化稀疏支持:Ampere架构下Pruning模型的峰值算力翻倍
无 Tensor Core”指的是GPU硬件中缺失专门用于加速矩阵运算和低精度计算的专用核心。以下是详细解释:
七、Tensor Core 的核心功能
Tensor Core 是 NVIDIA 从 Volta 架构(2017) 开始引入的专用硬件单元,主要解决两种计算需求:
-
混合精度计算
- 支持 FP16(半精度)/BF16(脑浮点)/FP8(8位浮点)等高效率运算
- 相比传统CUDA核心,相同功耗下提供4-12倍吞吐量
-
张量运算加速
- 硬件级优化矩阵乘法(GEMM):D=A×B+C
- 单周期完成 4x4x4 矩阵运算(传统CUDA核心需数十周期)
八、有无 Tensor Core 的差异对比
| 特性 | 有 Tensor Core (如V100/A100) | 无 Tensor Core (如P100) |
|---|---|---|
| FP16 训练速度 | 125 TFLOPS(V100)→ 312 TFLOPS(A100) | 21.2 TFLOPS(仅软件模拟) |
| INT8 推理性能 | 224 TOPS(A10) | 不支持(需FP32模拟,效率低10倍) |
| 矩阵乘法加速 | 专用硬件电路,延迟降低80% | 依赖CUDA核心串行处理 |
| 功耗效率 | 1 TOPS/W(T4) | 0.1 TOPS/W(P100) |
| 典型代表显卡 | T4/V100/A100/H100 | P100/P40/M40 |
📌 示例场景:
在BERT模型推理中:
- T4(有Tensor Core): 可实时处理 1000 QPS
- P100(无Tensor Core): 仅能处理 80 QPS
九、“无Tensor Core”对实际应用的影响
1. 深度学习训练
- 训练时间翻倍:ResNet-50 训练从 1小时(V100)→ 2.5小时(P100)
- 无法支持大模型:LLaMA-7B 需至少 V100(带Tensor Core)
2. AI推理
- 低精度无效化:INT8/FP8 加速完全不可用
- 高延迟:实时光追/自动驾驶场景无法满足
3. 科学计算
- 浪费FP64潜力:P100虽有FP64优势,但缺乏张量加速
- 混合计算受限:CFD仿真中的AI耦合计算效率低下
十、技术演进路线
| 架构年份 | 代表显卡 | Tensor Core 能力 |
|---|---|---|
| 2016 Pascal | P100 | ❌ 完全缺失 |
| 2017 Volta | V100 | ✅ 初代(仅FP16) |
| 2020 Ampere | A100 | ✅ 第二代(支持TF32/FP8) |
| 2022 Hopper | H100 | ✅ 第四代(动态编程支持) |
十一、总结
当显卡标注“无 Tensor Core”时,意味着:
- 硬件层:缺少AI计算专用加速单元
- 软件层:无法启用
torch.compile()/TF-TRT等优化 - 应用层:
- ❌ 不能运行 Stable Diffusion XL
- ❌ 无法部署 vLLM 推理服务
- ❌ 大模型训练效率极低
我们选择GPU的时候需要考虑这个GPU架构是否有Tensor Core,Tensor Core对于模型的推理部署很重要,很多主流的推理框架都不支持老的GPU架构
十二、参考文章
一文搞懂 GPU 的概念、工作原理,以及与 CPU 的区别 - 知乎