【力扣数据库知识手册笔记】索引
索引
索引的优缺点
| 优点 |
|---|
| 1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。 |
| 2. 可以加快数据的检索速度(创建索引的主要原因)。 |
| 3. 可以加速表和表之间的连接,实现数据的参考完整性。 |
| 4. 可以在查询过程中,使用优化隐藏器(隐藏索引?),提高系统性能。 |
| 缺点 |
|---|
| 时间上:创建和维护索引都要耗费时间; 当对数据进行增删改除时,索引也要动态的维护(降低了数据的维护速度)。 |
| 空间上:索引要占物理空间,如果要建立簇族索引,需要的空间更大。 |
索引的数据结构
数据库索引根据结构分类,分为B树索引、Hash索引和位图索引三种。
B树索引
又称平衡树索引,以树结构组织,有一个或者多个分支结点,分支结点又指向单级单叶结点。其中,分支结点用于遍历树,叶结点则保存真正的值和位置信息。结构如下:
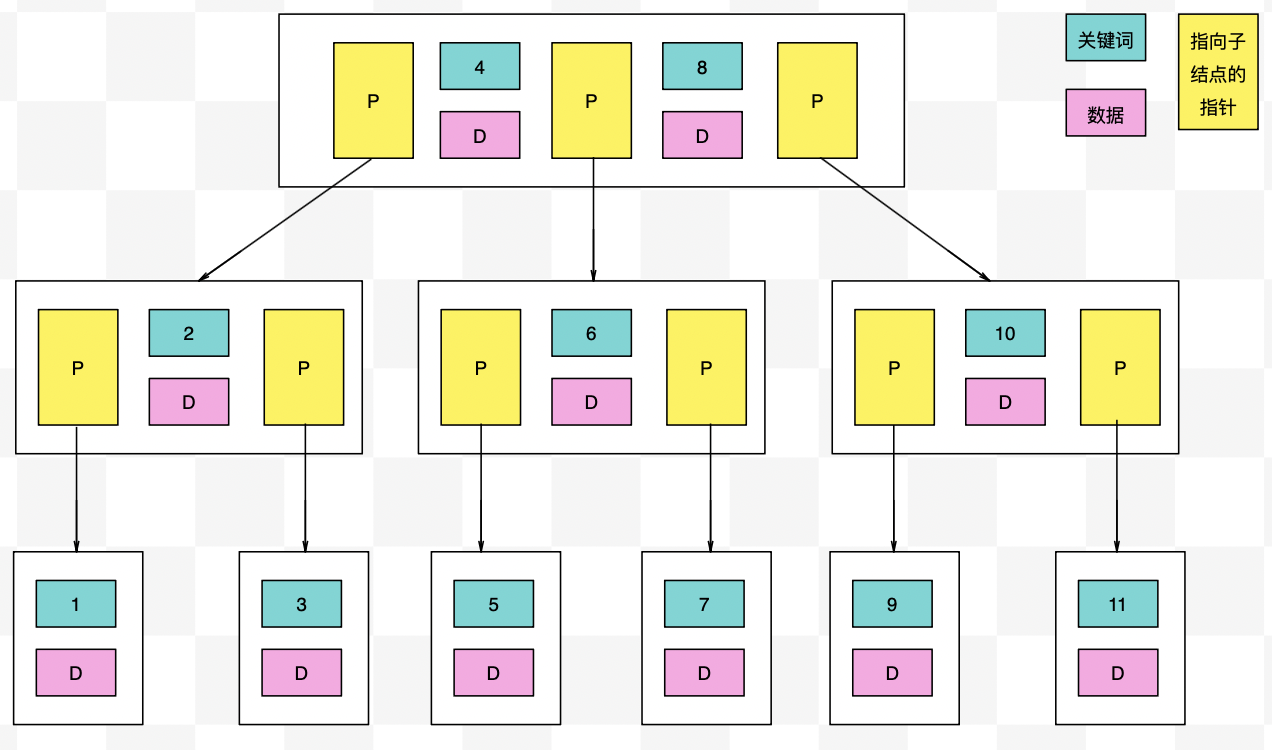
m阶B树有如下特性:
- 每个结点最多m个子结点;
- 除了根结点和叶子结点外,每个结点最少有 ⌈ m 2 ⌉ \lceil \frac{m}{2} \rceil ⌈2m⌉个子结点;
- 所有的叶子结点都位于同一层;
- 每个结点都包含k个元素(关键字), ⌊ m 2 ⌋ ≤ k < m \lfloor \frac{m}{2} \rfloor \le k <m ⌊2m⌋≤k<m;
- 每个结点中的元素(关键字)从小到大排列;
- 每个元素子左结点的值,都小于等于该元素,右结点的值都大于等于该元素。
B+树索引
B+树是在B树基础上的一种优化,使其更适合实现外存储索引结构。结构如下:

m阶b+树的特性:
- 所有非叶子结点只存储关键字信息;
- 所有具体数据都存在叶子结点中;
- 所有的叶子结点包含了全部元素的信息;
- 所有叶子结点之间都有一个链指针。
Hash索引
哈希索引采用一定的哈希算法(常见哈希算法有直接定址法、平方取中法、折叠法、除数取余法、随机数法),将数据库字段数据转换成定长的Hash值,与这条数据的行指针一并存入Hash表的对应位置,如果发生Hash碰撞(两个不同关键字的Hash值相同),则在对应Hash键下以链表形式存储。
检索时不需要类似B+树那样从根结点到叶子结点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,平均检索时间为 O ( 1 ) O(1) O(1)。
位图索引
B树索引擅长于处理包含许多不同值的列,但是在处理基数较小的列时会变得很难使用,如只有几个固定值,如性别、婚姻状况、行政区等,要么不使用索引,要么建立位图索引。
位图索引为存储在某列中的每个值生成一个位图,例如对婚姻状况(未婚、已婚和离婚),可以生成三个向量,每个位图为每一个人都分配了0/1值,每个人三者中只存在一个1,当进行数据查找时,只需要查找相关位图中的所有1即可。
位图索引适合静态数据,不适合索引频繁更新的列。
使用B+树索引的好处
- B+树内部结点只存放键,一次读取可以在同一内存页中获取更多的键,可以更快地缩小查找范围。
- B+树的叶结点由一条链相连,因此当需要进行一次全数据遍历的时候,B+树只需要使用O(logN)
时间找到最小结点,然后通过链进行O(N)顺序遍历即可;找数据时先找到结点,然后链表遍历。
Hash索引和B+树索引的区别
- Hash索引进行等值查询更快,但是无法进行范围查询;
- Hash索引不支持使用索引进行排序;
- Hash索引不支持模糊查询以及多列索引的最左前缀匹配(因为Hash函数不可预测);
- Hash索引任何时候都避免不了回表查询数据,而B+树在符合聚簇索引,覆盖索引等的时候可以只通过索引完成查询;
- Hash索引当某个键值存在大量重复的时候,发生Hash碰撞,此时效率可能极差;B+树的查询效率比较稳定,对于所有的查询都是从根结点到叶子结点,且树的高度较低。
什么是前缀索引?
索引开始的几个字符,而不是索引全部值,避免因为需要索引很长的字符列使得索引变大变慢,这种索引被称为前缀索引,以节约空间并得到好的性能。
建立前缀索引的前提:前缀的辨识度高(如密码)。
前缀索引需要的空间变小,但也会降低选择性(不重复的索引值/表中所有行数T,范围为1/T~1)。
高选择性的索引在查找匹配的时候可以过滤掉更多的行,唯一索引的选择率为1,为最佳值。
什么是最左前缀匹配原则?
在MySQL建立联合索引(多列索引)时会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。
用索引当限制条件查询时需要从左往右,连续匹配;范围查询会中断匹配,中断即止。
添加索引的原则
- 在查询中很少使用或参考的列不要创建索引。
- 只有很少数据值的列不要创建索引(区分度太低,索引不能明显加快检索速度)。
- 定义为text、image和bit数据类型的列不应该增加索引(这些数据量处于相当大和相当小两个极端)。
- 当修改性能远远大于检索性能时,不应该创建索引。
- 定义有外键的数据列一定要创建索引。
什么是聚簇索引?
- 聚簇索引,又称为聚集索引,并不是一种索引类型,而是一种数据存储方式。指的是将数据存储和索引放到一起,找到索引也就找到了数据。
MySQL里只有INNODB表支持聚簇索引,INNODB表数据本身就是聚簇索引,非叶子结点按照主键顺序存放,叶子结点存放主键以及对应的行记录。
特点:
- 索引和数据存放在一起,所以具有更高的检索效率;
- 相比于非聚簇索引,可以减少磁盘的IO数;
- 表的物理存储依据聚簇索引的结构,所以一个数据表只能有一个聚簇索引,但是可以有多个非聚簇索引;
- 会在频繁使用、排序的字段上创建聚簇索引。
- 非聚簇索引:除聚簇索引外所有索引,也是B树结构,不存储真正的数据行,只包含一个指向数据行的指针。
| 类型 | 定义 | 举例 |
|---|---|---|
| 复合索引 | 一个索引包含多个列(字段)的索引。 | CREATE INDEX idx_user_name_age ON user(name, age); 表示一个同时作用在 name 和 age 字段上的索引。 |
| 覆盖索引 | 指某条 SQL 查询所需要的所有列都包含在某个索引中,不需要回表查询数据。 | 若查询 SELECT name, age FROM user WHERE name = 'Tom',并且有上面的复合索引,则这个索引就是一个覆盖索引。 |