【AI论文】使用检索和代码工具将LLM Agent提取为小型模型
摘要:大型语言模型(LLMs)擅长复杂的推理任务,但计算成本仍然很高,限制了它们的实际部署。 为了解决这个问题,最近的研究工作集中在利用教师LLM的思想链(CoT)痕迹将推理能力提取到更小的语言模型(sLM)中。 然而,这种方法在需要罕见的事实知识或精确计算的情况下会遇到困难,在这种情况下,由于能力有限,sLMs往往会产生幻觉。 在这项工作中,我们提出了代理蒸馏,这是一个框架,不仅可以转移推理能力,还可以将基于LLM的代理的全部任务解决行为转移到具有检索和代码工具的sLM中。 我们从两个互补的轴上改进了代理蒸馏:(1)我们引入了一种称为第一想法前缀的提示方法来提高教师生成轨迹的质量; 以及(2)我们提出了一个自洽的动作生成,以提高小型代理的测试时间鲁棒性。 我们在事实和数学领域的八个推理任务上评估了我们的方法,涵盖了领域内和领域外的泛化。 我们的结果表明,小至0.5B、1.5B、3B参数的sLMs可以实现与使用CoT蒸馏微调的下一级较大的1.5B、3B、7B模型相媲美的性能,这表明了代理蒸馏在构建实用的、使用工具的小代理方面的潜力。 我们的代码可以在 github 上找到。Huggingface链接:Paper page,论文链接:2505.17612
研究背景和目的
研究背景
大型语言模型(LLMs)在复杂现实世界任务中取得了显著成就,其性能甚至在某些领域超越了平均人类水平,如大学水平的数学考试和高风险领域的任务处理。然而,随着LLMs的广泛应用,其高昂的推理成本逐渐成为负担。为了应对这一挑战,研究者们开始关注小型语言模型(sLMs),旨在保留较大模型问题解决能力的同时,降低计算成本。尽管预训练和后训练方法的进步不断提升了sLMs的能力,但它们在解决复杂任务时仍难以达到LLMs的水平。
传统的推理蒸馏方法通过让sLMs模仿教师LLMs生成的思想链(Chain-of-Thought, CoT)痕迹来训练,尽管这种方法在数学推理等任务中取得了一定成效,但在需要罕见事实知识或精确计算的场景中,sLMs容易产生幻觉,导致性能下降。例如,在回答“2010年投资100美元于苹果股票到2020年价值多少?”这类问题时,既需要股票历史数据的事实知识,也需要算术推理能力。LLMs可以利用记忆的知识和数值技能正确回答,但简单地将这种推理痕迹蒸馏到sLM中并不能保证泛化能力,尤其是在蒸馏过程中未见过的新知识或计算。
研究目的
本研究旨在提出一种名为“代理蒸馏”(Agent Distillation)的框架,该框架不仅将推理能力,还将基于LLM的代理的完整任务解决行为转移到具有检索和代码工具的sLM中。通过引入两种简单而有效的方法来改进蒸馏过程:一是提出“第一想法前缀”(First-Thought Prefix, ftp)方法,以提高教师生成轨迹的质量;二是提出“自洽动作生成”(Self-Consistent Action Generation, sag)方法,以提高小型代理在测试时的鲁棒性。研究的目标是验证sLMs能否通过模仿LLM代理的行为,学会使用工具(如检索和代码执行)来解决问题,从而在不依赖记忆大量事实知识和计算的情况下,表现出与LLMs相当的问题解决能力。
研究方法
代理蒸馏框架
代理蒸馏框架的核心思想是将LLM代理的“思考-行动-观察”(Thought-Action-Observation, TAO)轨迹蒸馏到sLM中。与传统的CoT蒸馏不同,代理蒸馏不仅关注推理过程,还关注代理如何与环境交互,通过行动(如代码执行、检索)来解决问题,并观察结果以调整策略。
-
第一想法前缀(ftp):为了改善教师轨迹的质量,研究提出在生成代理轨迹时,使用CoT推理的第一步作为前缀,引导代理生成更结构化的思考过程。这种方法通过整合CoT推理的初始步骤作为代理第一想法的前缀,来增强教师轨迹的质量,而不需要额外的微调。
-
自洽动作生成(sag):为了提高小型代理在测试时的鲁棒性,研究提出在生成动作时,采样多个候选动作,并使用轻量级代码解释器过滤掉解析或执行错误的序列,通过多数投票选择产生一致结果的行动。
实验设置
-
任务与数据集:研究在事实推理和数学推理两大类任务上评估代理蒸馏的效果,每个类别均包含领域内和领域外泛化任务。具体使用的数据集包括HotPotQA、Bamboogle、MuSiQue、2WikiMultiHopQA(事实推理)和MATH、GSM-Hard、AIME、OlymMATH(数学推理)。
-
模型选择:教师模型采用Qwen2.5-32B-Instruct,学生模型则使用Qwen2.5-Instruct系列的0.5B、1.5B、3B和7B参数模型。所有学生模型在蒸馏前均经过指令微调。
-
训练与推理细节:使用Wikipedia2018作为知识库,e5-base-v2作为文档和查询嵌入模型。学生模型通过参数高效微调(LoRA)进行训练,每个模型训练2个epoch,批量大小为8,学习率为2·10^-4。推理时使用贪婪解码,最大步骤设为5。对于sag方法,在主要实验中设置N=8,温度为0.4。
研究结果
整体结果
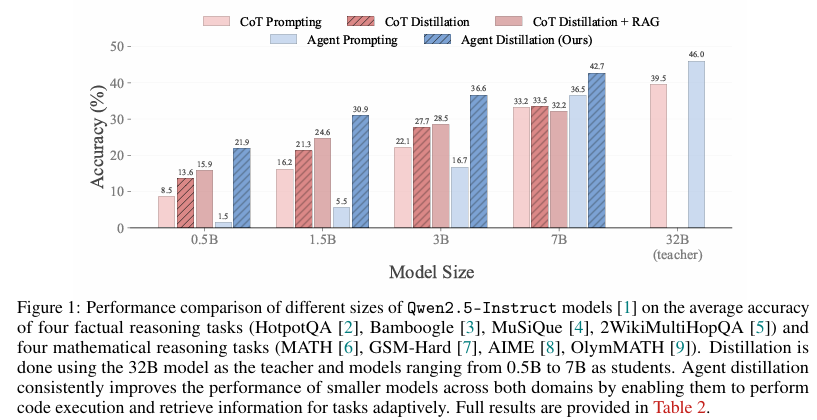
实验结果表明,代理蒸馏显著提升了sLMs在所有模型尺寸上的性能。在蒸馏前,大多数尺寸的模型(除7B外)仅通过提示难以产生有效的代理行为,经常生成错误或不可解析的代码动作。相比之下,蒸馏后的代理在事实和数学领域的领域外任务上均表现出色,甚至在某些任务上超过了使用CoT蒸馏的更大模型。
具体而言,0.5B的代理模型达到了与1.5B CoT蒸馏模型相当的性能,1.5B代理模型达到了3B CoT蒸馏模型的水平,3B代理模型超越了7B CoT蒸馏模型,而7B代理模型甚至超过了32B CoT蒸馏模型。这些结果表明,代理蒸馏使小型模型能够匹配或超过通过CoT蒸馏训练的更大模型的性能,为构建高效、实用的语言代理提供了新途径。
事实推理结果
在事实推理任务上,检索增强了CoT蒸馏模型在基于事实的推理基准测试中的性能。然而,由于检索的静态特性,它在需要动态或自适应信息使用的任务(如数学推理)中可能会降低性能。相比之下,蒸馏后的代理表现优于甚至增强了检索的CoT模型,因为它们能够在推理过程中主动检索和整合知识,而不是依赖预先获取的文档。
数学推理结果
在数学推理任务上,蒸馏后的代理展示了强大的整体性能。1.5B、3B和7B模型在AIME和OlymMATH基准测试上表现出色,得益于通过蒸馏获得的代码工具使用能力,能够处理复杂的计算。在GSM-hard任务上,代理蒸馏提高了在罕见数字组合(如多位算术)上的推理鲁棒性。尽管在MATH500任务上的表现落后于CoT蒸馏模型,但研究指出,这可能是由于Qwen2.5系列在大学水平数学上的大量指令微调所致。
研究局限
-
模型系列限制:实验仅限于Qwen2.5模型系列,尽管预期该方法能推广到其他模型家族,但尚未在其他广泛使用的语言模型(如LLaMA或Gemma)上验证其有效性。
-
教师模型限制:仅从单个教师模型(Qwen2.5-32B)进行蒸馏。使用更强或更大的教师模型(特别是专有的闭源模型如GPT-4)可能会进一步提升学生代理的性能,但由于计算和预算限制,这些实验未能进行。
-
教师轨迹数量:未研究每个问题教师轨迹数量对学生性能的影响,而这是先前CoT蒸馏研究中的一个重要因素。探索这一变量可能提供关于如何优化代理蒸馏的进一步见解。
-
代理应用限制:当前工作仅关注利用检索和代码执行工具解决现实世界问题的代理,其他代理应用(如具身代理或基于网络的代理)尚未探索。未来研究可将代理蒸馏扩展到这些更广泛的设置中。
未来研究方向
-
模型泛化性:将代理蒸馏方法应用于其他模型家族,验证其普遍性和有效性。
-
更强教师模型:探索使用更强或更大的教师模型进行蒸馏,以进一步提升学生代理的性能。
-
教师轨迹数量优化:研究教师轨迹数量对学生性能的影响,优化蒸馏过程。
-
更广泛的代理应用:将代理蒸馏扩展到具身代理、基于网络的代理等更广泛的设置中,利用工具增强的环境(如网络浏览器、模拟器或桌面接口)进一步提升代理的能力。
-
安全性与责任性:鉴于蒸馏后的代理能够检索网络信息并执行代码,未来研究应关注如何集成稳健的安全措施,包括行为监控、工具使用限制和安全部署实践,以防止恶意行为的自动化。
综上所述,本研究提出的代理蒸馏框架为将LLM代理的复杂行为和能力转移到sLM中提供了新途径,展示了sLMs在无需大量计算资源的情况下,通过模仿和学习LLM代理的行为,实现高效问题解决的潜力。未来的研究将进一步探索该方法的泛化性、优化蒸馏过程,并关注其在实际应用中的安全性和责任性。