深入解析JMM:Java内存模型与并发编程
本文约8600字,需要20-30分钟阅读。
JMM(JAVA memory model)
3.0 一些基础概念
JMM,即Java memory model,是 Java 虚拟机规范中定义的一种抽象模型,用于描述 Java 多线程程序中不同线程之间如何通过内存进行交互。因此只是一种抽象出的、用于解决多线程编程中出现的问题(在多线程并发的情况下,会出现一系列的问题,例如由于cpu的指令重排序、或者编译优化后导致的可见性问题)的模型。或者你可以理解为一种约定俗成的规范,但之所以被称为【模型】,是因为这并非是确定的规范,而是对问题的抽象。因此JMM的出现设定了对应的规范和应对方法,开发者可以便利的利用JMM的规范和原则进行多线程编程而不至于出错。
下面是一些对于JMM的更详细的理解,读者可以阅读整篇文章后再来阅读这一部分:
1. JMM 是理论抽象,而非具体实现
- JMM 不直接规定 JVM 应该如何实现内存访问,而是定义了一个理论框架,说明在多线程环境下,哪些行为是允许的,哪些是不允许的。
- 不同的JVM(如HotSpot、OpenJ9)可以有不同的实现方式,只要它们遵守JMM的规则。
2. JMM 定义了线程、主内存和工作内存的交互方式
JMM 不仅仅是一套"写代码的规范",而是定义了线程如何与内存交互的正式模型:
- 主内存(Main Memory):存储共享变量(如堆中的对象)。
- 工作内存(Working Memory):每个线程有自己的工作内存(可能是CPU缓存或寄存器),存储它使用的变量的副本。
- 内存屏障(Memory Barriers):JMM 规定了何时需要同步内存,以确保可见性。
Thread 1 Thread 2| |v v
Working Memory Working Memory| |v v
---------Main Memory---------
这个模型描述了线程如何读取、写入和同步数据,而不仅仅是"如何写代码"。
3. JMM 提供了 happens-before 规则,而不仅仅是语法
JMM 的核心是 happens-before 关系,它定义了操作的可见性和顺序性,例如:
synchronized解锁 happens-before 后续的加锁。volatile写 happens-before 后续的读。- 线程启动(
Thread.start())happens-before 该线程的所有操作。
这些规则不仅仅是"编程建议",而是严格的数学约束,JVM 必须保证这些规则成立,否则程序的行为就是未定义的。
4. JMM 允许优化,但限制优化范围
- JVM 和 CPU 会进行指令重排序(Reordering)以提高性能,但 JMM 规定了哪些重排序是允许的,哪些是不允许的。
- 例如:
单线程下,int x = 1; int y = 2;x和y的写入顺序可以交换(JVM 可能优化)。
但在多线程下,如果另一个线程依赖x和y的写入顺序,JMM 会规定是否需要禁止这种优化。
JMM 的作用就是在保证正确性的前提下,允许最大程度的优化,而不仅仅是"告诉你怎么写代码"。
5. JMM 是语言无关的内存模型
- JMM 不仅适用于 Java,其他基于 JVM 的语言(如 Kotlin、Scala)也必须遵守它。
- 类似的模型也存在于其他语言,如 C++11 内存模型(C++ Memory Model),它们都是正式的并发理论,而不仅仅是编程规范。
JMM 更像是并发编程的"物理定律",而不仅仅是"编程风格指南"。
3.0.1 JMM和JVM的关系?
JVM是内存划分和线程管理,而JMM专门定义多线程并发场景下Java线程之间的可见性、有序性和原子性的约定。
jmm要解决的问题主要在如下几个方面:
- 原子性:保证指令不会受到线程上下文切换,要么都执行,要么都不执行。
- 可见性:保证指令不会受 cpu 缓存的影响。线程对共享变量的修改能被其他线程立马得知。
- 有序性:保证指令不会受 cpu 指令并行优化的影响
想必如果你有疑惑,也是在工作内存、主内存和JVM的内存模型上有区别,可以看下面:
3.0.2 JMM定义的内容?
- 主内存(Main Memory)
-
定义:在JMM中,主内存是所有线程共享的内存区域
-
存储内容:存储所有的共享变量(实例字段、静态字段等),约等于JVM堆中真正被多线程共享的部分 + 方法区的静态变量,或者是计算机中的内存(注意内存和外存的区别)
-
特点:
1.线程对共享变量的所有操作(读/写)都必须在主内存中进行
2.是线程间通信的媒介
3.对应于物理内存,但不等同于JVM堆内存
- 工作内存(Working Memory)
-
定义:每个线程私有的内存区域
-
存储内容:存储该线程使用到的变量的主内存副本,约等于 CPU缓存/寄存器 + 线程栈中的临时数据。这一部分可以展开说一下,因为涉及到了计算机组成原理的比较底层的内容。
cpu不会直接操作主存,而是寄存器、cache(当然,现代计算机都是多级缓存,一般是三级)。这是因为读写速度的不一致导致的,操作cache的性能更好,但这也衍生出一个问题,我们需要同步cache和主存中的数据,因为写入cache的数据并未写入主存,如果此时被修改,那可能会导致主存的数据出现错误,类似于数据库中的【丢失修改】。我们一般的cache写回主存的策略如下:
1.Write-Through(直写)
每次修改缓存时 同时写入主存
性能较差,但数据一致性最强
类似 volatile 的写操作
2.Write-Back(回写)
先只修改缓存,延迟写入主存(直到缓存行被替换)
性能更好,但可能导致 脏数据(其他CPU读到旧值)
类似普通变量的非同步访问
因此,JMM将cpu、cache和主存的同步问题抽象出来,使用synchronized、volatile等操作插入内存屏障,来解决这些一致性上的问题。(实际我们成为可见性,后面有) -
特点:
1.线程对变量的所有操作(读/写)都必须在工作内存中进行
2.不能直接访问其他线程的工作内存
3.对应于CPU缓存和寄存器,但不等同于JVM栈内存
也因此,JVM给JMM的内存上的问题你应该有了大致的理解:JVM的是在物理层面之上的抽象,即JVM的内存模型不考虑物理层面的cpu、cache、主存等问题,只是抽象为堆、栈、方法区等(实际情况更加复杂),而JMM则是对于物理设备的抽象,即对于硬件方面的抽象,并且让程序员可以用代码来解决这些一致性的问题。也因此,程序员不需要关注底层架构(不管是x86还是arm),都可以用volatile等关键字主动操作。所以,如果你对于计算机组成原理有了解,那么这里的JMM解决的就是相关的问题。
- 内存屏障
内存屏障(Memory Barrier),也称为内存栅栏(Memory Fence),是计算机系统中的一种同步机制,用于控制处理器对内存操作的顺序和可见性。
内存屏障主要有三个作用:
-
防止指令重排序
- 编译器和处理器为了提高性能会对指令进行重排序,内存屏障会限制这种重排序
-
保证可见性
- 确保屏障前的写操作对其他处理器/核心可见
- 强制刷新缓存或使缓存失效
-
保证执行顺序
- 确保某些操作按照程序顺序执行
内存屏障有以下几种类型
1. 硬件层面的内存屏障 了解即可
load是从内存到寄存器,store反之,从寄存器到内存
(1) LoadLoad屏障
- 确保屏障前的Load操作先于屏障后的Load操作完成
- 对应指令:
lfence(x86架构)
(2) StoreStore屏障
- 确保屏障前的Store操作先于屏障后的Store操作完成
- 对应指令:
sfence(x86架构)
(3) LoadStore屏障
- 确保屏障前的Load操作先于屏障后的Store操作完成
(4) StoreLoad屏障
- 确保屏障前的Store操作先于屏障后的Load操作完成
- 对应指令:
mfence(x86架构) - 这是最强的内存屏障,开销也最大
2. JVM中的内存屏障
JVM会根据不同平台将Java层面的同步操作转换为适当的内存屏障:
| Java操作 | 插入的内存屏障 |
|---|---|
| volatile读 | LoadLoad + LoadStore |
| volatile写 | StoreStore + StoreLoad |
| monitor enter | LoadLoad + LoadStore |
| monitor exit | StoreStore + StoreLoad |
| final字段写 | StoreStore |
内存屏障的实现原理
-
禁止重排序
- 在屏障两侧的指令不会被重排序跨越屏障
-
刷新缓存
- 强制将缓存数据写回主内存(对于写操作)
- 使缓存失效(对于读操作)
-
等待执行完成
- 确保屏障前的所有操作完成后再执行屏障后的操作
下面是一段代码,来理解主内存和工作内存:
public class MemoryVisibilityDemo {// 共享变量 - 存储在主内存中private static boolean sharedFlag = false;private static int sharedValue = 0;public static void main(String[] args) throws InterruptedException {// 线程A - 修改共享变量Thread threadA = new Thread(() -> {// 在工作内存中修改(对主内存不可见)// 如果没有同步操作,这些修改可能不会立即写回主内存sharedValue = 42; // 操作1sharedFlag = true; // 操作2System.out.println("Thread A: 修改完成");});// 线程B - 读取共享变量Thread threadB = new Thread(() -> {while (!sharedFlag) {// 空转等待,从工作内存读取sharedFlag}// 这里读取到的sharedValue可能是0或42 因为读取的是主内存的内容System.out.println("Thread B: sharedValue = " + sharedValue);});threadB.start();Thread.sleep(100); // 确保线程B先运行threadA.start();}
}
3.1 JMM解决的问题/并发编程的重要特性
说完了一些基础知识,下面先说一下可能会因为硬件出现哪些问题:
首先就是上面说到的cpu、cache之间的问题,这可能线程A写入cache而未写入主存,线程B读取到错误的主存数据导致一致性问题。还有一个问题就是指令重排序:现代处理器会进行指令级并行优化,即每一句代码会翻译为若干句的指令,编译器会在编译的时候进行一定程度的优化,因此这些指令的顺序可能会出现问题。这可能需要读者有计算机系统架构的知识,即了解流水线和乱序发射(当然,不知道也可以,需要知道的就是编译优化会导致指令的顺序发生改变,且这个改变很难判断,想了解可以看一看这个:文章)。由于指令重排序就可能导致多线程的执行结果和预期冲突。
针对这两种问题(cpu缓存模型和乱序发射),衍生出可见性和有序性的问题。
3.1.1 可见性
例如下面的代码,可能会一直运行。因为 run 没有使用 volatile 或同步机制,线程可能无法感知主线程的修改(JIT 可能将其优化为寄存器变量,导致永久循环)。说白了,主线程修改 run 时,虽然最终会同步到主内存,但线程 t 的工作内存可能缓存了旧值(未强制刷新)。
static boolean run = true;public static void main(String[] args) throws InterruptedException {Thread t = new Thread(() -> {while (run) {// ...}});t.start();sleep(1);run = false; // 线程t不会如预想的停下来
}图解如下:
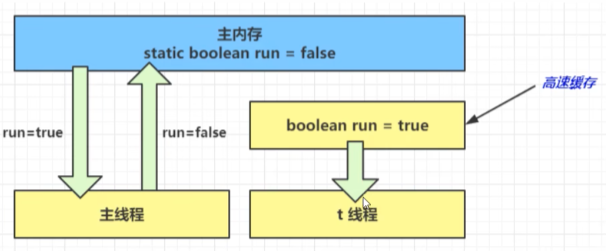
因此我们得出结论:可见性是关于cpu和缓存的问题。是否可见,即因为一些优化会导致在主线程的修改对于t线程是不可见的。也就是线程可能使用自己的工作内存而不去使用主内存。这样可以加快处理速度,因为对于代码示例,总运行while循环且总需要读取主内存会浪费资源。解决办法也很简单,就是将工作内存的可能会影响一致性的内容强制刷新到主内存。
volatile,易变的,如果用volatile修饰,则避免线程到自己的工作缓存中查找变量的值,而是每次都要从主内存中获取变量,因此不会出错。同时,synchronized也可以解决可见性问题,因为在jmm中,进入/退出synchronized同步块时,必须完成与主内存数据的同步(synchronized通过"锁的内存屏障"机制保证可见性)。可重入锁也可以。
注意,可见性被保证的同时不能保证原子性,这是两回事。一个是在本地内存和主内存的同步,一个是两个线程对一个变量由于指令交错导致的问题。因此synchronized既可以保证原子性也可以保证可见性,而volatile只能保证可见性。对于上面的修改方法,就是将静态变量加volatile的修饰符。
3.1.2 有序性
这个对应的是指令重排序的问题。执行顺序是可以改变的,在多线程的情况下会导致出错误。例如五段流水的情况下,指令重排序会导致冲突,进而导致错误。例如,b的值是依赖于a的,如果强行重排序,那一定会出现问题。
int a=3;
int b=a-1;
// 这里重排序就会导致错误
例如如下代码:这里的actor是压测工具的注解,通过大量测试探测到所有可能的内存可见性的问题。本段代码会因为指令重排序的原因,有概率将ready=true修改到num=2的前面,因此就会出现0这个结果。
public class ConcurrencyTest {int num = 0;boolean ready = false;@Actorpublic void actor1(I_Result r) {if (ready) {r.r1 = num + num;} else {r.r1 = 1;}}@Actorpublic void actor2(I_Result r) {num = 2;ready = true;}
}我们可以通过加volatile来解决,即:
volatile boolean ready = false;
这样可以防止ready之前的代码进行指令重排序。你可能疑惑为什么可以解决有序性?原理如下:
3.1.2.1 volatile的原理:
底层实现原理是内存屏障(Memory Fence/Barrier),即对volatile变量的写指令后加入写屏障,volatile变量的读指令之前加入读屏障。
- 保证可见性和有序性
写屏障保证在该屏障之前,对于共享变量的改动,都同步到主内存中。且确保指令重排序时,不会将写屏障之前的代码排到写屏障之后。
public void actor2(I_Result r){num = 2;ready=true;//ready 是 volatile 赋值带写屏障// 写屏障 也就是这个地方之前的内容都同步到主内存中
}
读屏障则是在该屏障之后,对于共享变量的读取加载的是主内存的最新数据。读屏障会保证指令重排序的时候,不会将读屏障之后的代码排在读屏障之前。
public void actor1(I_Result r){
// 读屏障 因为现在要读取ready
//ready 是 volatile 读取值带读屏障if(ready){r.r1=num + num;} else{r.r1 = 1;}
}
但还是要注意,读写屏障只能保证可见性(主内存,属于优化)和有序性(重排序,也是优化),但是不能保证指令交错,指令交错是由于多线程导致的。
3.1.2.2 double-checked locking问题(DCL)
这个例子的特点是,懒惰实例化,即先判断是否为null再创建单例。但是如果t1访问到null且还未修改,此时t2也访问null,则会创建两个实例。因此可以在方法上加synchronized,可以保证原子性。但是问题是,加入了synchronized,后续访问的效率变差。
public final class singleton{private singleton(){ }private static singleton INSTANCE = null;public static singleton getInstance(){if(INSTANCE == null){ // t1 t2INSTANCE = new singleton();}return INSTANCE;}
}
// double check
public final class singleton{private singleton(){ }private static singleton INSTANCE = null;public static singleton getInstance(){// 只有首次访问会synchronized 后续不需要if(INSTANCE == null){synchronized(singleton.class){// 对static方法加锁,实际上就是锁类if(INSTANCE == null){ INSTANCE = new singleton();}}} // if return INSTANCE;}
}
// 但是还是会出问题,第一个check的时候可能会因为指令重排导致问题。没有volatile会导致【双重检查锁定失效】的问题
构造过程实际上可能是三步:
- 分配内存空间
- 调用构造方法初始化对象内容
- 把INSTANCE指向分配的内存(此时INSTANCE!=null)
也就是先构造出对象再将instance指向构造出的对象。但是实际运行的时候可能会发生编译优化,即先进行分配再初始化。这样的重排序会导致这样的问题:
- 线程A 进入第一次if判断,INSTANCE为null,进入
synchronized块。 - 线程A 继续判断INSTANCE为null,执行
INSTANCE = new Singleton();,发生指令重排序 :先分配内存,再提前把INSTANCE指向了这块内存 ,还没初始化。 - 此时线程B 也进来,看到INSTANCE已经不是null(因为A已经提前让其指向了内存),于是B直接return INSTANCE 。
- 但此时A还没执行到对象初始化,INSTANCE代表的是一个“还未初始化完的对象”。
- B 拿到这个“半初始化”对象,继续使用可能报错或行为异常。
synchronized无法保证不出现错误,因为synchronized只能保证临界区内部的代码的顺序,对于临界区外的无法保证。但是使用volatile就可以解决问题,即将INSTANCE加上volatile的关键字。volatile保证写操作后,会插入写屏障,保证写操作以及之前发生的操作都刷新到主内存中,对其他线程都可见。也就是,在执行到INSTANCE=new Singleton();这个操作后,会插入写屏障,也就保证之前的操作其他线程可见,禁止写屏障之前的指令重排序。
所有更改后的代码如下:
public final class Singleton{private singleton(){ }private static volatile Singleton INSTANCE = null;public static Singleton getInstance(){// 只有首次访问会synchronized 后续不需要if(INSTANCE == null){synchronized(Singleton.class){// 对static方法加锁,实际上就是锁类if(INSTANCE == null){ INSTANCE = new Singleton();// 写屏障}}} // if return INSTANCE;}
}
3.1.3 happen-before
happens-before规定了一个线程对共享变量的写操作对其它线程的读操作可见。具体来说,如果操作 A “happens-before” 操作 B,那么操作 A 对共享内存的修改将对操作 B 可见。下面是一些满足happens-before的写法:
- 程序顺序规则:一个线程内,按照代码顺序,书写在前面的操作 happens-before 于书写在后面的操作;但是这里不是不能用重排序优化,是第一条代码一定在第二条代码执行结束前结束。
int x = 1; // 操作A
int y = x + 1; // 操作B (能看到A的修改)
- 解锁规则:对于lock和synchronized都适用,对一个锁的解锁happens-before随后对这个锁的加锁。也就是解锁后的修改都会同步到主内存。
synchronized(lock) { // 加锁x = 42;
} // 解锁
// 其他线程加锁时一定能看到x=42- volatile 变量规则:对volatile变量的写操作happens-before后续对它的读操作.
volatile boolean flag = false;// 线程A
x = 42; // 普通写
flag = true; // volatile写// 线程B
if (flag) { // volatile读// 这里保证能看到x=42
}
- 线程启动规则:线程start之前的写都可以。
int x = 0;Thread t = new Thread(() -> {// 这里保证能看到x=1
});
x = 1;
t.start();
- 有传递性,本例中y=10也是可见的。
volatile static int x;
static int y;new Thread(() -> {y = 10; // 线程 t1 设置 y 的值为 10x = 20; // 线程 t1 设置 x 的值为 20
}).start();new Thread(() -> {System.out.println(x); // 线程 t2 打印 x 的值
}).start();