每日代码解读专栏:OpenVLA(Action)部分的解读
OK。我们今天继续来进行OpenVLA的解读。
那么今天,我们将会来进行Action生成部分的解读。也就是说,它是通过训练VLM,进而如何生成Action的。这里面有什么需要注意的地方。那将会在我们今天这篇文章中给大家一一阐述。
我们实际上是话接上文了哈,在上篇文章中,我们是说到了OpenVLA的视觉部分。那么在本篇,我们将会带领大家详细地看一看有关于其Action部分的生成的内容。
也就是这个PipeLine后面这个部分:
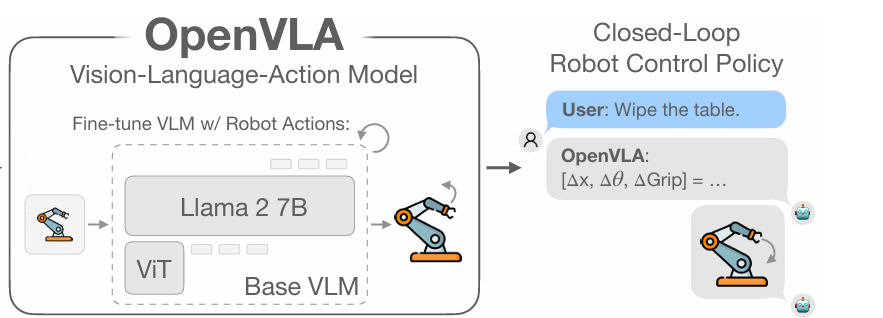
那么我们主要是要看这个文件:https://github.com/openvla/openvla/blob/main/prismatic/models/vlas/openvla.py
其实可以看到,这个代码文件并不长,函数也并不多(相较于我们之前所说过的那些来说)。因此,理解起来也没有像之前的那样繁琐。
其核心就是在一处,我们会在下面去说。
那么,废话少说,我们就直接开始我们今天的代码实战部分吧~~~
在此之前呢,可以来大体看一下它都有哪些部分:
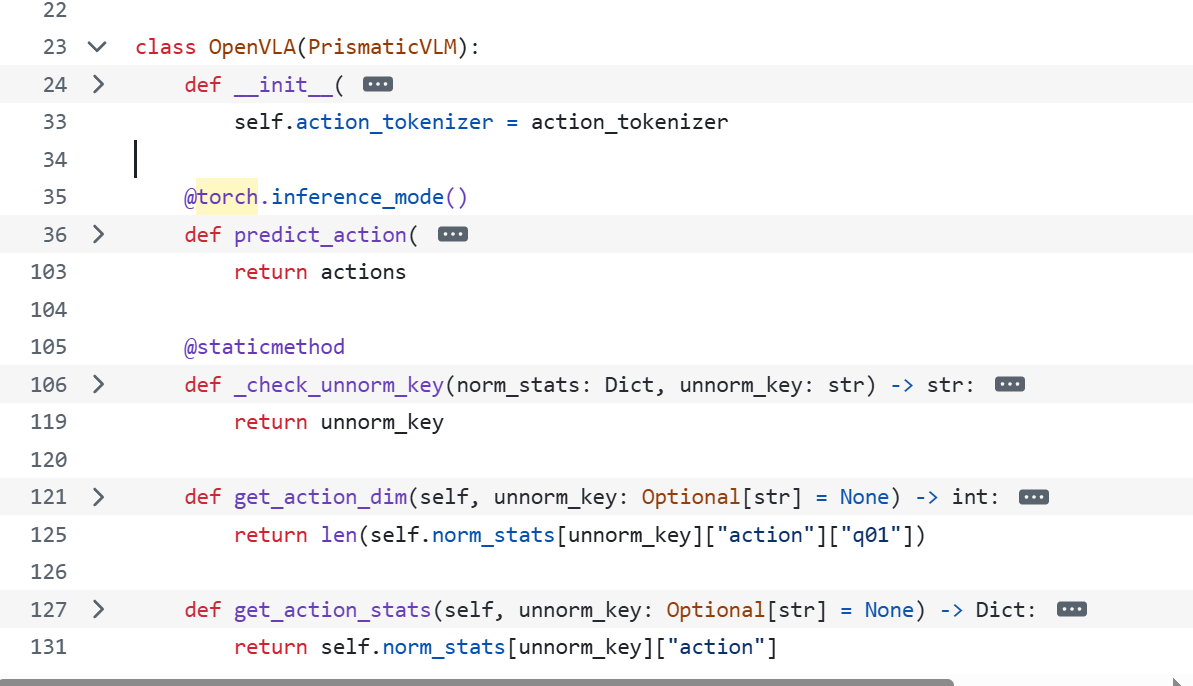
可以看出,它一共是有四个部分来组成。那我们就从头开始说起,先来看看它的初始化吧
一、OpenVLA 的初始化
def __init__(self,*args,norm_stats: Dict[str, Dict[str, Dict[str, Dict[str, List[float]]]]],action_tokenizer: ActionTokenizer,**kwargs,) -> None:super().__init__(*args, **kwargs)self.norm_stats = norm_statsself.action_tokenizer = action_tokenizer
我们可以看到,在 OpenVLA 的初始化方法中,它继承了 PrismaticVLM 的初始化逻辑,这使得 OpenVLA 具备了 PrismaticVLM 的基本特性与功能。在此基础上,它额外接收了两个关键参数:norm_stats和action_tokenizer。
其中,norm_stats是一个复杂的字典结构,它存储了用于动作归一化和反归一化的统计信息。这些统计信息对于将模型输出的归一化动作值转换为真实世界中机器人可执行的实际动作范围至关重要。不同的数据集或任务场景可能有不同的动作范围规范,norm_stats就像是一本记录这些规范的 “字典”,帮助 OpenVLA 准确适配各种情况。
而另外一个,action_tokenizer,则是一个动作分词器,它负责在离散的动作令牌(token)和连续的动作向量之间进行转换。在自然语言处理中,分词器将文本分割成一个个单词或子词,而action_tokenizer在这里的作用类似,它将机器人的连续动作空间进行离散化表示,以便模型能够更好地处理和生成动作指令,同时也能将模型生成的离散动作令牌解码为实际的连续动作向量。
那这些大家心里有个数,做个了解就可以啦。
我们继续往下看。
二、核心预测动作方法
@torch.inference_mode()
def predict_action(self, image: Image, instruction: str, unnorm_key: Optional[str] = None, **kwargs: str) -> np.ndarray:"""Core function for VLA inference; maps input image and task instruction to continuous action (de-tokenizes).@param image: PIL Image as [height, width, 3]@param instruction: Task instruction string@param unnorm_key: Optional dataset name for retrieving un-normalizing statistics; if None, checks that modelwas trained only on a single dataset, and retrieves those statistics.@return Unnormalized (continuous) action vector --> end-effector deltas."""image_transform, tokenizer = self.vision_backbone.image_transform, self.llm_backbone.tokenizer# Build VLA Promptprompt_builder = self.get_prompt_builder()prompt_builder.add_turn(role="human", message=f"What action should the robot take to {instruction.lower()}?")prompt_text = prompt_builder.get_prompt()# Prepare Inputsinput_ids = tokenizer(prompt_text, truncation=True, return_tensors="pt").input_ids.to(self.device)if isinstance(tokenizer, LlamaTokenizerFast):# If the special empty token ('') does not already appear after the colon (':') token in the prompt# (after "OUT:" or "ASSISTANT:"), insert it to match the inputs seen at training timeif not torch.all(input_ids[:, -1] == 29871):input_ids = torch.cat((input_ids, torch.unsqueeze(torch.Tensor([29871]).long(), dim=0).to(input_ids.device)), dim=1)else:raise ValueError(f"Unsupported `tokenizer` type = {type(tokenizer)}")# Preprocess Imagepixel_values = image_transform(image)if isinstance(pixel_values, torch.Tensor):pixel_values = pixel_values[None, ...].to(self.device)elif isinstance(pixel_values, dict):pixel_values = {k: v[None, ...].to(self.device) for k, v in pixel_values.items()}else:raise ValueError(f"Unsupported `pixel_values` type = {type(pixel_values)}")# Invoke super().generate --> taps into `GenerationMixin` which (redirects) to `forward()`autocast_dtype = self.llm_backbone.half_precision_dtypewith torch.autocast("cuda", dtype=autocast_dtype, enabled=self.enable_mixed_precision_training):# fmt: offgenerated_ids = super(PrismaticVLM, self).generate(input_ids=input_ids, # Shape: [1, seq]pixel_values=pixel_values, # Shape: [1, 3, res, res] or Dict[str, ...]max_new_tokens=self.get_action_dim(unnorm_key),**kwargs)# fmt: on# Extract predicted action tokens and translate into (normalized) continuous actionspredicted_action_token_ids = generated_ids[0, -self.get_action_dim(unnorm_key) :]normalized_actions = self.action_tokenizer.decode_token_ids_to_actions(predicted_action_token_ids.cpu().numpy())# Un-normalize Actionsaction_norm_stats = self.get_action_stats(unnorm_key)mask = action_norm_stats.get("mask", np.ones_like(action_norm_stats["q01"], dtype=bool))action_high, action_low = np.array(action_norm_stats["q99"]), np.array(action_norm_stats["q01"])actions = np.where(mask,0.5 * (normalized_actions + 1) * (action_high - action_low) + action_low,normalized_actions,)return actions
这段代码也是主要的代码片段。我们来拆分着解读一下。可以拆成下面四块儿来去理解:
点击每日代码解读专栏:OpenVLA(Action)部分的解读查看全文