(cvpr2025) Frequency Dynamic Convolution for Dense Image Prediction
代码:https://github.com/Linwei-Chen/FDConv
首先回顾一下动态卷积 CondConv (NeurIPS2019),如下图所示。当前的卷积对所有样本采用相同的卷积参数,不能根据输入样本的特点调整参数。因此,谷歌提出了CondConv,可以根据输入动态生成一组系数,动态调整卷积核的参数。
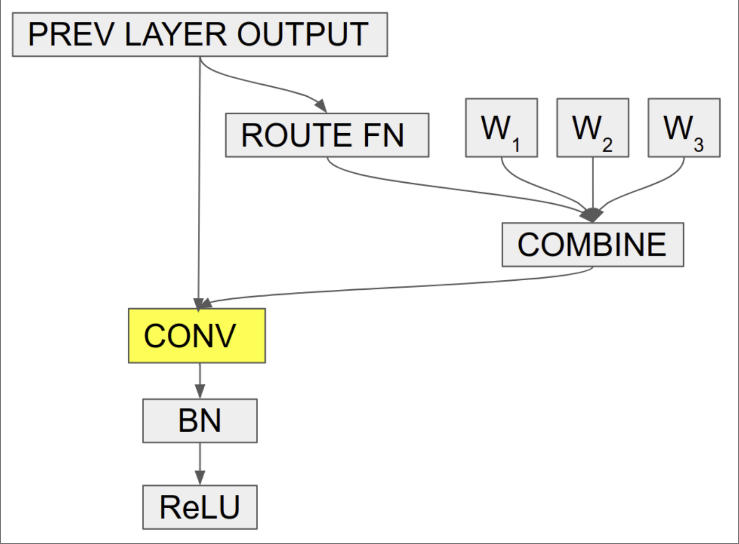
这个工作提出了 Frequency Dynamic Convolution (FDConv) 用于密集预测,即对图像中的每个像素进行预测,生成与输入图像尺寸对应的密集型输出(如像素级标签,深度值等)。
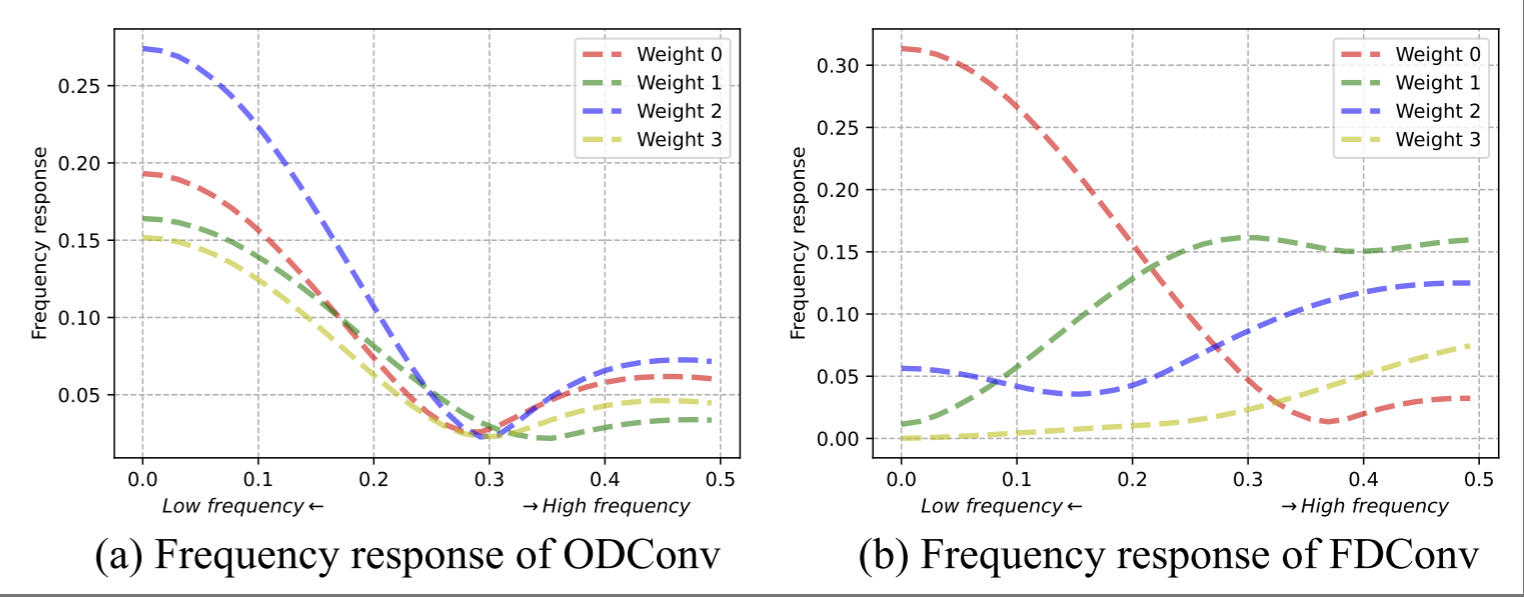
研究动机: 作者指出,CondConv 的主要问题在于生成的多个卷积权值 频域响应高度相似 ,如下图(a)所示,缺乏 frequency response diversity,影响模型模型自适应捕获频率信息的能力。例如,提取低频分量有助于抑制噪声,而高频分量则捕获细节和边界,这对于目标和背景区分至关重要。
为了解决这个问题,作者提出了 FDConv ,可以增加 frequency adaptability 同时参数没有明显增加。FDConv 主要包括三个模块:Fourier Disjoint Weight (FDW), Kernel Spatial Modulation (KSM), Frequency Band Modulation (FBM)。总体结构图如下所示。下面具体介绍三个模块。
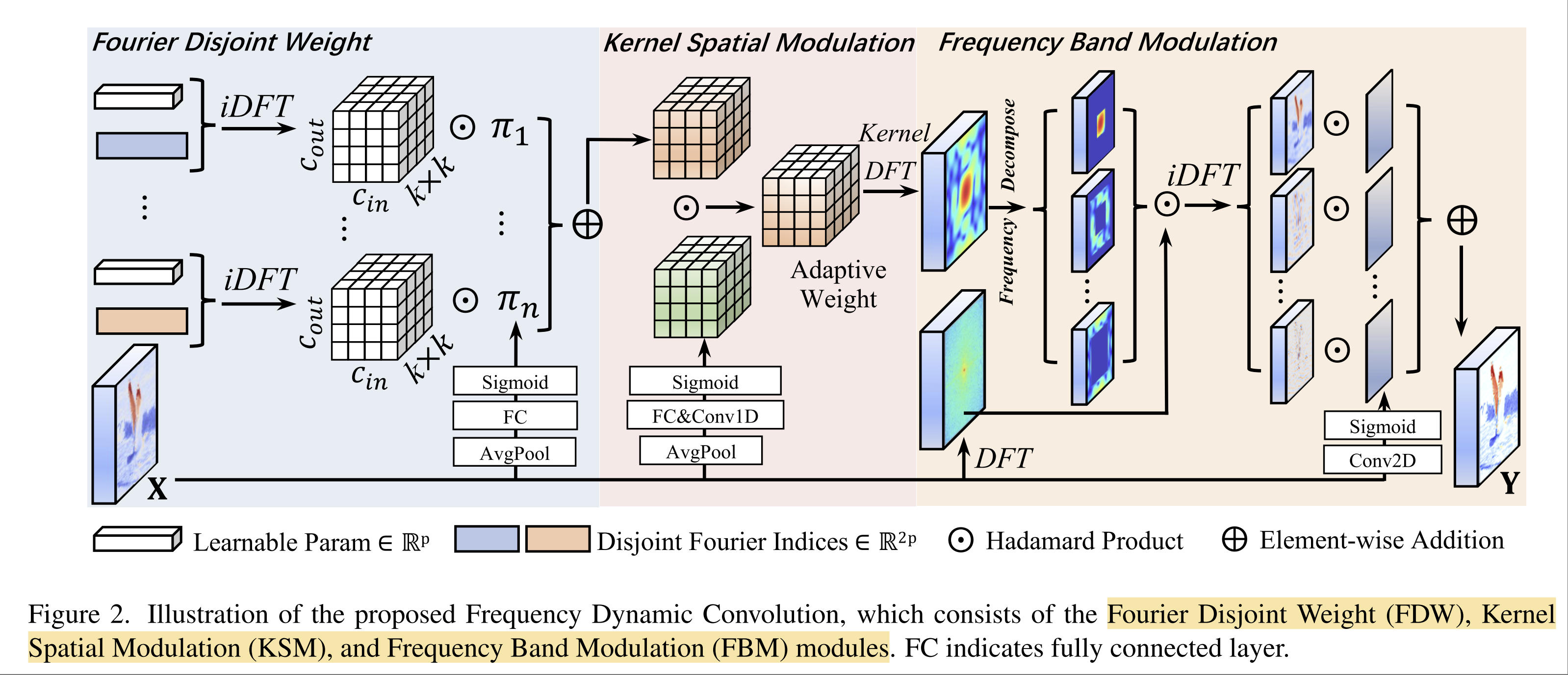
Fourier Disjoint Weight. 之前的 CondConv 比较消耗存储,只能生成不多的卷积核,但是 FDW 可以生成10个以上的卷积核。卷积的参数开销是 k × k × C i n × C o u t k\times k\times C_{in} \times C_{out} k×k×Cin×Cout . 如下图所示,这些参数展成一个二维矩阵P,在频率域上分为多个组(图中分了2组,蓝色的是一组,橙色的是一组)。作者以第一组为例,不需要要学习的参数置为0(图中白色),然后做逆DFT变换,由频率域变到空间域,然后做 crop ,得到参数 k × k × C i n × C o u t k\times k\times C_{in} \times C_{out} k×k×Cin×Cout 。因为分了很多组,每个组是和不同频域成分相关的,因此频域响应自然就不同了。

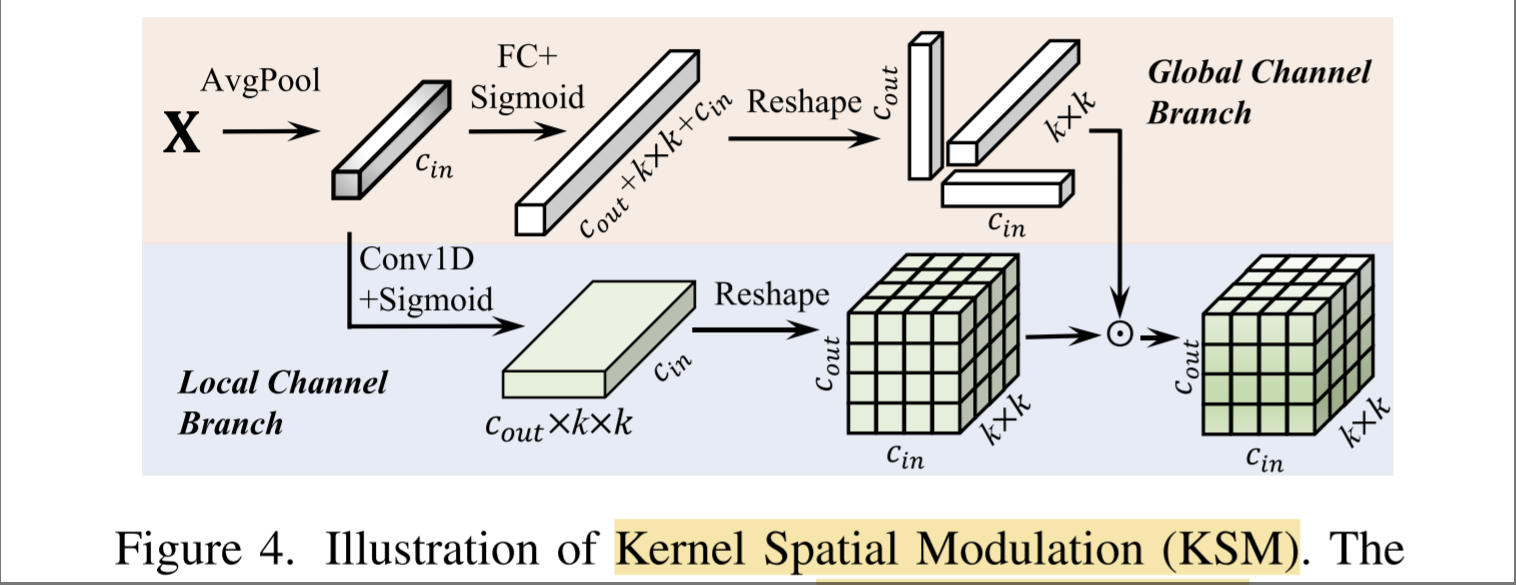
Kernel Spatial Modulation. 得到多个卷积核后,下一步就是根据输入的特征X加权融合了。回想 CondConv 将输入特征 X 使用 Pooling + Linear 操作得到一组系数,通过线性加权融合多个卷积核。作者认为这样过于粗糙,因此提出了 Kernel Spatial Modulation 来融合多个卷积核。如下图所示,包括Global 和 Local 两个分支,图里描绘的非常清楚,不多介绍了。
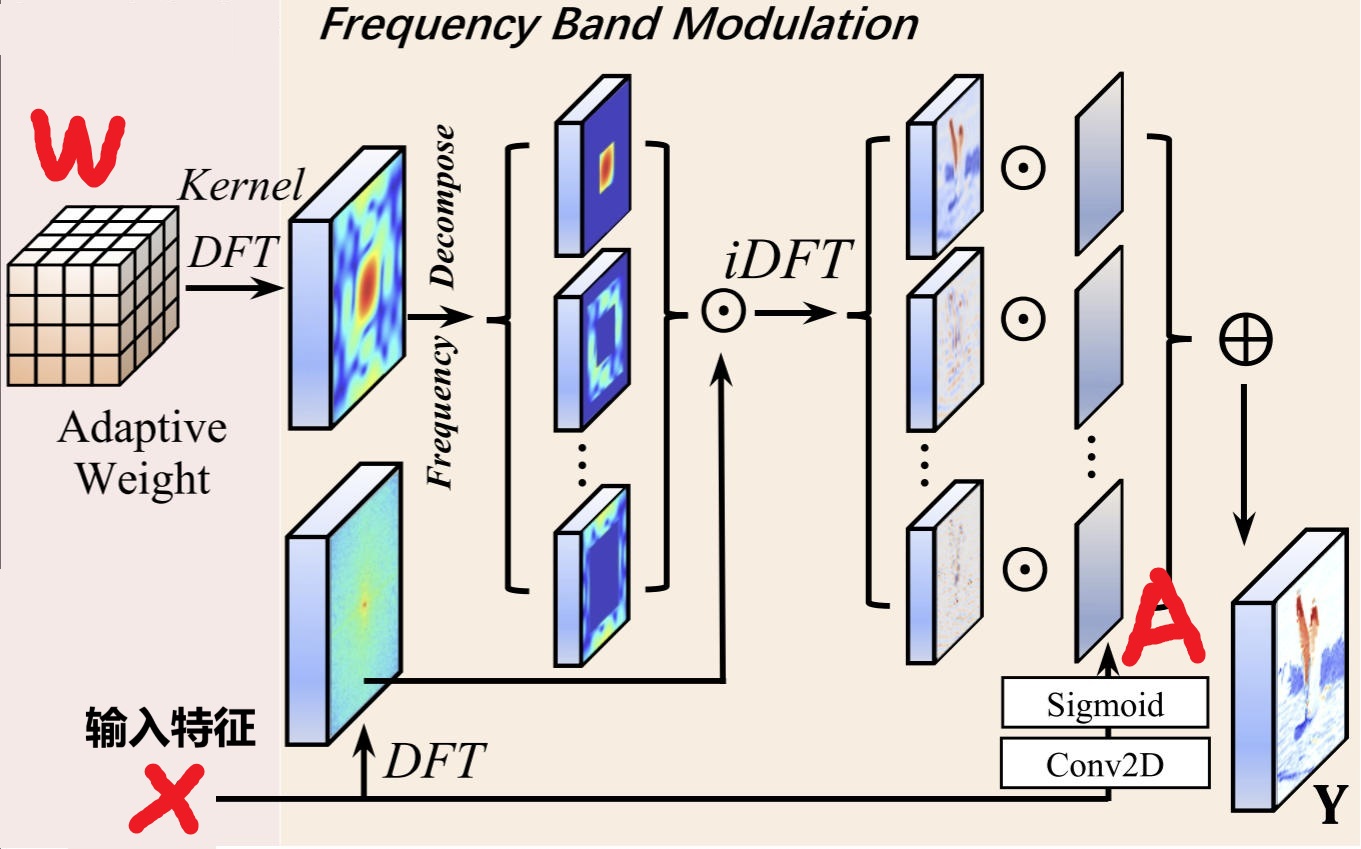
Frequency Band Modulation. 作者引用一个文献,指出空间卷积和频域的逐元素相乘是等效的。上面两个步骤以后,正常操作是将卷积参数W和输入特征X逐元素相乘融合即可。作者认为卷积是空间不变的(即对所有位置使用相同的卷积核),这限制了性能。为了解决这个问题,作者在频域中将卷积参数W分为多个频率分量(论文中写的是{0, 1/16,1/8,1/4,1/2}),与输入特征X在频率域进行逐元素相乘即完成卷积。得到卷积结果以后,作者又使用一个权重矩阵A,对各个频域分量的卷积结果进行加权。
FDConv 可以用于很多网络,实验部分可以参考作者论文,这里不过多介绍了。