谢赛宁团队提出 BLIP3-o:融合自回归与扩散模型的统一多模态架构,开创CLIP特征驱动的图像理解与生成新范式
BLIP3-o 是一个统一的多模态模型,它将自回归模型的推理和指令遵循优势与扩散模型的生成能力相结合。与之前扩散 VAE 特征或原始像素的研究不同,BLIP3-o 扩散了语义丰富的CLIP 图像特征,从而为图像理解和生成构建了强大而高效的架构。
此外还发布了包含 2000 万张带详细标题的图片(BLIP3o Pretrain Long Caption)和 400 万张带短标题的图片(BLIP3o Pretrain Short Caption)的数据集。
亮点
-
完全开源:完全开源训练数据(预训练和指令调整)、训练方案、模型权重、代码。
-
统一架构:用于图像理解和生成。
-
CLIP 特征扩散:直接扩散语义视觉特征,以实现更强的对齐和性能。
-
最先进的性能:涵盖广泛的图像理解和生成基准。
支持的任务
-
文本 → 文本
-
图像→文本(图像理解)
-
文本→图像(图像生成)
-
图像 → 图像(图像编辑)
-
多任务训练(图像生成和理解混合训练)

相关链接
-
论文:https://arxiv.org/pdf/2505.09568
-
代码:https://github.com/JiuhaiChen/BLIP3o
-
模型:https://huggingface.co/BLIP3o/BLIP3o-Model
-
预训练:https://huggingface.co/datasets/BLIP3o/BLIP3o-Pretrain
-
优化:https://huggingface.co/datasets/BLIP3o/BLIP3o-60k
论文阅读

在近期的多模态模型研究中,统一图像理解和生成越来越受到关注。尽管图像理解的设计方案已被广泛研究,但用于统一图像生成框架的最佳模型架构和训练方法仍未得到充分探索。
鉴于自回归和扩散模型在高质量生成和可扩展性方面的巨大潜力,作者对它们在统一多模态环境中的应用进行了全面的研究,重点关注图像表征、建模目标和训练策略。基于这些研究,论文提出了一种新颖的方法,该方法使用扩散变换器来生成语义丰富的CLIP图像特征,这与传统的基于VAE的表征不同。这种设计既提高了训练效率,又提升了生成质量。
此外,作者证明了统一模型的顺序预训练策略——先进行图像理解训练,然后再进行图像生成训练——在保留图像理解能力的同时,发展强大的图像生成能力,具有实用优势。最后,作者精心策划了一个高质量的指令调整数据集 BLIP3o-60k,用于图像生成,通过为 GPT-4o 提供涵盖各种场景、物体、人体手势等内容的多样化字幕。基于论文提出的创新的模型设计、训练方案和数据集,作者开发了 BLIP3-o,这是一套最先进的统一多模态模型。BLIP3-o 在涵盖图像理解和生成任务的大多数热门基准测试中均取得了卓越的性能。
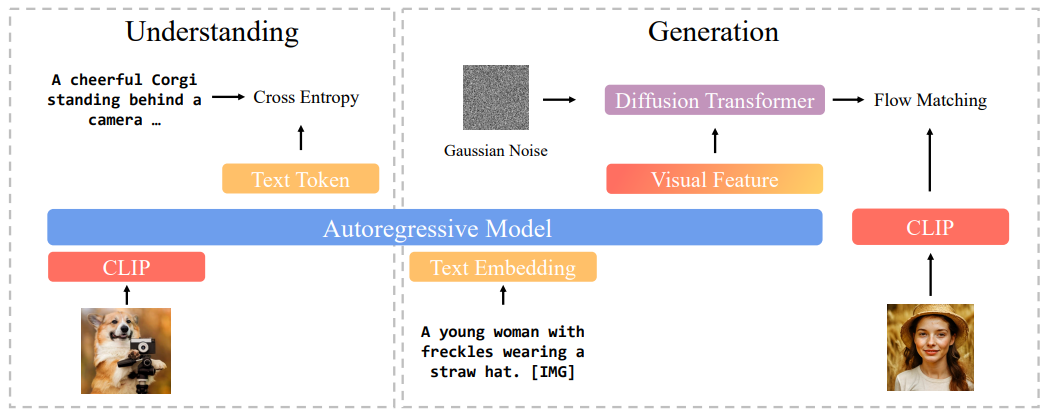
BLIP3-o 的架构。 在图像理解部分,我们使用 CLIP 对图像进行编码,并计算目标文本标记和预测文本标记之间的交叉熵损失。在图像生成部分,自回归模型首先生成一系列中间视觉特征,然后将其作为条件输入,输入到扩散变换器中,该变换器生成 CLIP 图像特征,以近似真实的 CLIP 特征。通过使用 CLIP 编码器,图像理解和图像生成共享相同的语义空间,从而有效地统一了这两个任务。
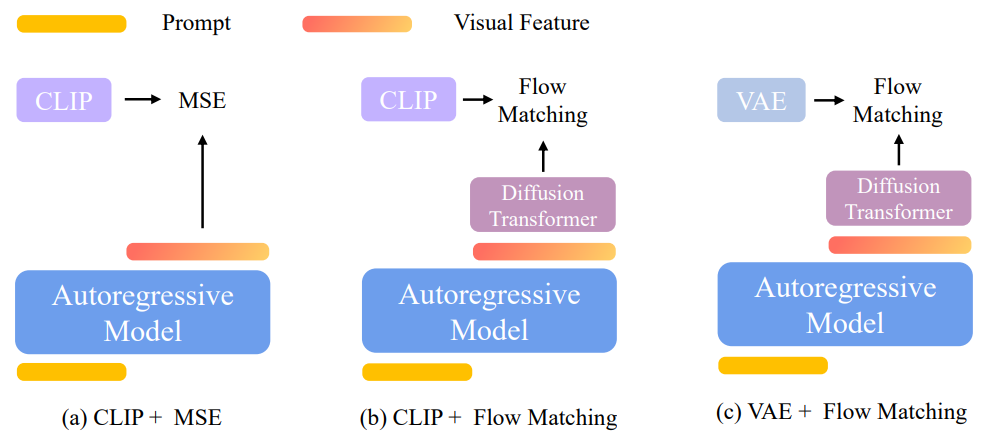
统一多模态模型中图像生成的三种设计选择。所有设计均采用自回归 + 扩散框架,但其图像生成组件有所不同。对于流匹配损失,我们保持自回归模型不变,仅对图像生成模块进行微调,以保留模型的语言能力。
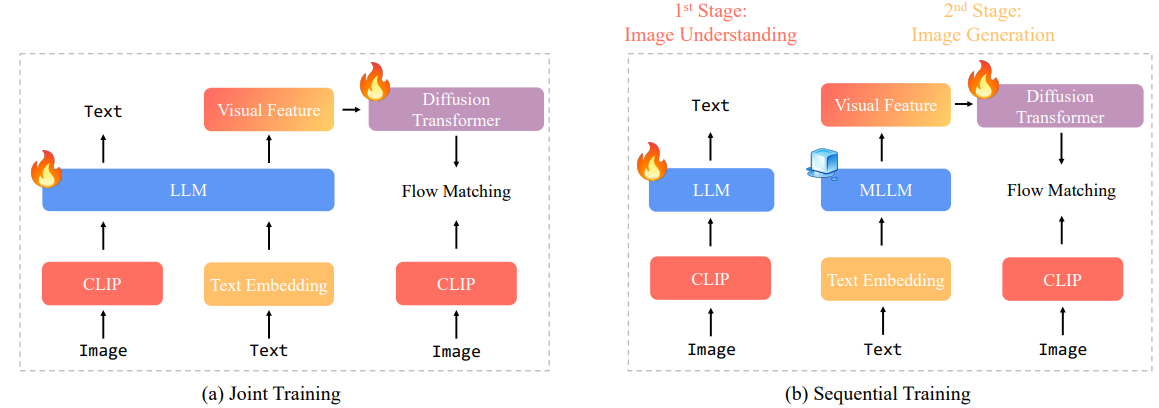
联合训练 vs. 顺序训练:联合训练通过混合图像理解和图像生成数据进行多任务学习,同时更新自回归主干网络和生成模块。顺序训练将两个过程分开:首先,模型仅进行图像理解任务的训练;然后冻结自回归主干网络,并在第二阶段仅训练图像生成模块。
实验结果


BLIP3-o 8B 在 1024×1024 分辨率下的可视化结果
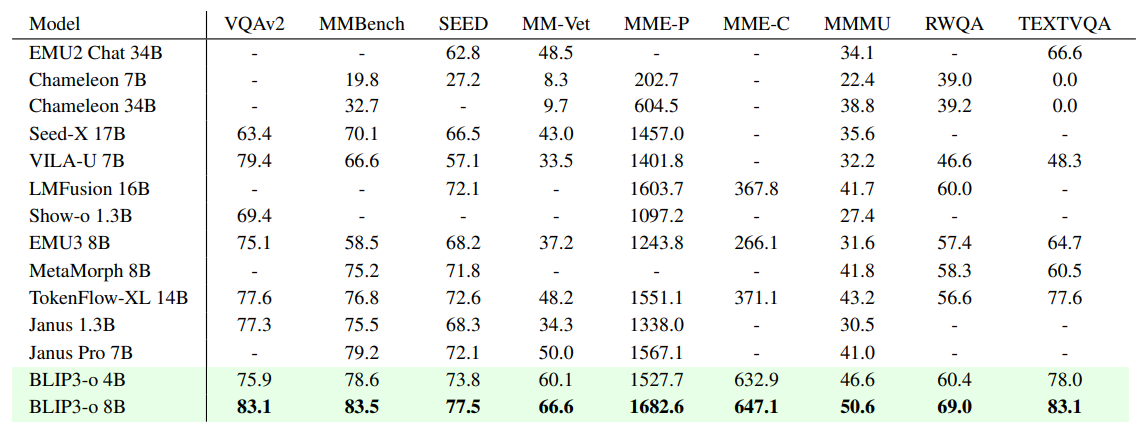
图像理解基准测试的结果。用粗体突出显示最佳结果。
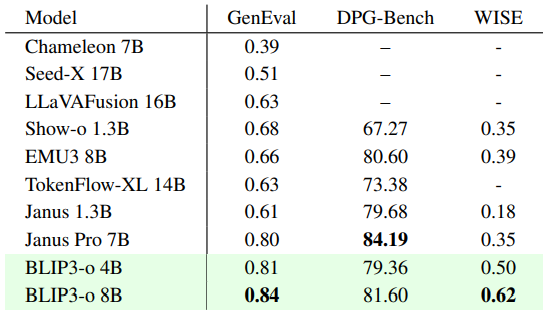
图像生成基准结果
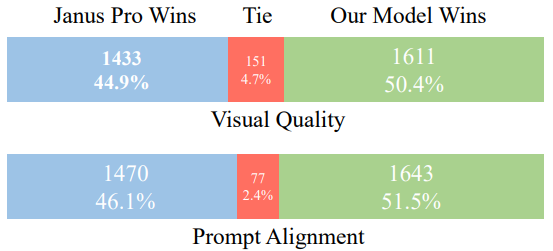
Janus Pro 与模型在 DPG-Bench 上的人体研究结果。
结论
论文首次系统地探索了用于统一多模态建模的混合自回归和扩散架构,并评估了三个关键方面:图像表征(CLIP 与 VAE 特征)、训练目标(光流匹配与 MSE)以及训练策略(联合与顺序)。实验表明CLIP 嵌入与光流匹配损失相结合,能够提高训练效率并提升输出质量。基于这些洞察,作者推出了 BLIP3-o,这是一系列最先进的统一模型,并基于 60k 指令集调整数据集 BLIP3o-60k 进行了增强,显著提升了快速对齐和视觉美感。此外,作者正在积极开发该统一模型的应用,包括迭代图像编辑、视觉对话和逐步视觉推理。