缓冲区的用途 和 fork复制进程
printf隐藏的缓冲区
(1)为什么会有缓冲区?
#include <stdio.h>int main(){printf("hello");}运行之后 和平时似乎没什么区别。原因是因为此时程序已经结束了,会刷新缓冲区的内容;
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(){printf("hello");sleep(3);exit(0);
}这里可以发现 hello明显打印经过了时间的等待 之后才出现在屏幕上。
强制刷新
方法一:遇到\n自动刷新 printf("hello\n");
方法二:使用fflush刷新屏幕 fflush(stdout);
方法三:_exit与exit
exit是先刷新缓冲区,然后再调用_exit(真正的退出);
_exit直接退出 不会刷新缓冲区;
总结
printf将内容先写入到缓冲区,缓冲区刷新到界面上的条件是:
(1)缓冲区放满
(2)缓冲区未满,强制刷新缓冲区到屏幕上(\n 或者 fflush(stdout))
(3)程序结束,自动刷新缓冲区:exit方法;
缓冲区的存在 是因为屏幕是一个硬件设备 是由操作系统来管理的,因此printf打印的时候 需要调用操作系统的接口才能完成,这个时候我们需要从 用户态切换到内核态 这个开销是非常大的。
缓冲区的存在主要是为了减少用户态和内核态之间的频繁切换,从而提高系统的整体效率。
数据暂存:缓冲区可以暂存从用户态传入的数据,当数据积累到一定程度后再一次性传递给内核态,这样可以减少切换次数。
速度匹配:不同设备的数据传输速度可能不同,缓冲区可以协调这些速度差异,使得数据传输更加平稳和高效。
错误处理:缓冲区还可以用于暂存错误信息,当发生错误时,系统可以更灵活地处理这些错误,而不是立即中断当前操作。
缓冲区通常由操作系统管理,操作系统会在内存中分配一块区域作为缓冲区。应用程序将数据写入缓冲区,操作系统负责将缓冲区中的数据传递给硬件设备。同样,从硬件设备读取的数据也会先存入缓冲区,然后由应用程序从缓冲区中读取。
fork复制进程
(1)shell
在计算机中 shell俗称壳(用来区别于核),是指“为使用者提供操作界面”的软件(命令解析器)。他类似于DOS下的COMMAND.COM和后来的cmd.exe。他接受用户命令,然后调用相应的应用程序。
我们就是通过命令解释器(shell)(bash是命令解释器中的一种)和内核和系统进行交互的;
例如 在Linux中 我们输入ls命令 将ls交给bash,bash帮我们运行ls,然后再将运行出来的结果交给用户。bash作为用户和内核的一个媒介 进行命令解释
(2)fork是如何复制进程的?
fork是把已经有的进程完全复制一份,连带着把PCB也复制了一份,然后申请了一个PID,子进程的PID=父进程的PID+1;
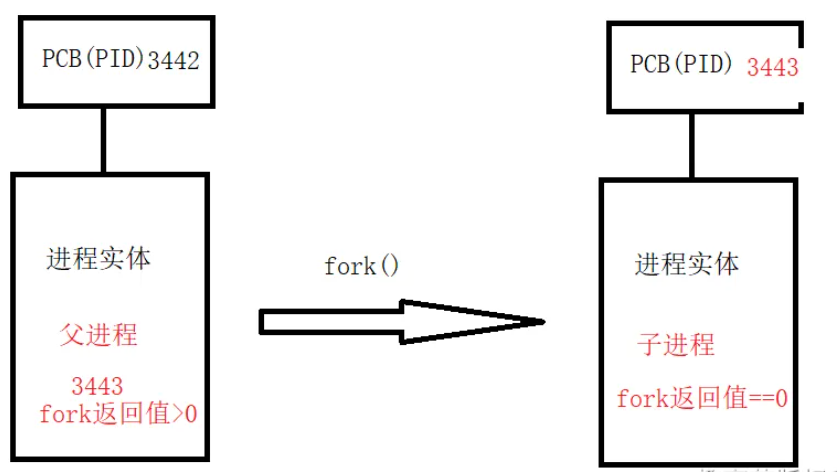
如果父子进程想要做不同的事情,那么就需要通过其返回值来判断
#include <stdio.h>
#include <unistd.h>
#include <assert.h>
#include <stdlib.h>int main()
{char *s=NULL;int n=0;//控制父子进程执行的次数;pid_t id=fork();assert(id!=-1);if(id==0)//子进程{s="child";n=3;}else//父进程{s="parent";n=7;}//父子进程int i=0;for(;i<n;i++){printf("s=%s\n",s);sleep(1);}exit(0);
}父子进程是两个独立的进程,各自执行各自的代码;如果父子进程要做不一样的事情,就需要通过if else返回值来操作;
(3)fork的时机
fork产生的子进程并不是从头开始执行,而是从fork之后开始执行,也就是说fork下面的代码 子进程才开始执行,具体的是说从返回值这里子进程开始执行,子进程不会再fork了,所以不会出现子进程再去fork产生一个子进程的问题。
返回值上 父进程返回子进程的PID 子进程返回0
(4)getppid与getpid
getppid:得到的是一个进程的父进程PID
getpid:得到的是当前进程的PID
