故障诊断模型评估——混淆矩阵,如何使样本量一致(上)

往期精彩内容:
Python-凯斯西储大学(CWRU)轴承数据解读与分类处理
基于FFT + CNN - BiGRU-Attention 时域、频域特征注意力融合的轴承故障识别模型-CSDN博客
基于FFT + CNN - Transformer 时域、频域特征融合的轴承故障识别模型-CSDN博客
Python轴承故障诊断 (11)基于VMD+CNN-BiGRU-Attenion的故障分类-CSDN博客
Python轴承故障诊断 (13)基于故障信号特征提取的超强机器学习识别模型-CSDN博客
Python轴承故障诊断 (14)高创新故障识别模型-CSDN博客
Python轴承故障诊断 (15)基于CNN-Transformer的一维故障信号识别模型-CSDN博客
Python轴承故障诊断 (16)高创新故障识别模型(二)-CSDN博客
轴承故障全家桶更新 | 基于时频图像的分类算法-CSDN博客
Python轴承故障诊断 (17)基于TCN-CNN并行的一维故障信号识别模型-CSDN博客
独家原创 | SCI 1区 高创新轴承故障诊断模型!-CSDN博客
基于 GADF+Swin-CNN-GAM 的高创新轴承故障诊断模型-CSDN博客
Python轴承故障诊断 (18)基于CNN-TCN-Attention的创新诊断模型-CSDN博客
注意力魔改 | 超强轴承故障诊断模型!-CSDN博客
轴承故障全家桶更新 | 基于VGG16的时频图像分类算法-CSDN博客
轴承故障全家桶更新 | CNN、LSTM、Transformer、TCN、串行、并行模型、时频图像、EMD分解等集合都在这里-CSDN博客
Python轴承故障诊断 (19)基于Transformer-BiLSTM的创新诊断模型-CSDN博客
Python轴承故障诊断 (20)高创新故障识别模型(三)-CSDN博客
视觉顶会论文 | 基于Swin Transformer的轴承故障诊断-CSDN博客
Python轴承故障诊断 | 多尺度特征交叉注意力融合模型-CSDN博客
SHAP 模型可视化 + 参数搜索策略在轴承故障诊断中的应用-CSDN博客
速发论文 | 基于 2D-SWinTransformer+1D-CNN-SENet并行故障诊断模型-CSDN博客
Python轴承故障诊断 (21)基于VMD-CNN-BiTCN的创新诊断模型-CSDN博客
1DCNN-2DResNet并行故障诊断模型-CSDN博客
基于改进1D-VGG模型的轴承故障诊断和t-SNE可视化-CSDN博客
基于K-NN + GCN的轴承故障诊断模型-CSDN博客
故障诊断 | 创新模型更新:基于SSA-CNN-Transformer诊断模型-CSDN博客
独家首发 | 基于 2D-SwinTransformer + BiGRU-GlobalAttention的并行故障诊断模型-CSDN博客
位置编码祛魅 | 详解Transformer中位置编码Positional Encoding-CSDN博客
创新点 | 基于快速傅里叶卷积(FFC) 的故障诊断模型-CSDN博客
代码开源! | 变工况下的域对抗图卷积网络故障诊断-CSDN博客
超强 !顶会创新融合!基于 2D-SWinTransformer 的并行分类网络-CSDN博客
多模态-故障诊断 | 大核卷积开启视觉新纪元!-CSDN博客
超强!一区直接写!基于SSA+Informer-SENet故障诊断模型-CSDN博客
Transformer结构优势 ,How Much Attention Do You Need?-CSDN博客
故障诊断 | 一个小创新:特征提取+KAN分类-CSDN博客
故障诊断 | 信号降噪算法合集-CSDN博客
图卷积故障诊断,新增GAT、SGCN、GIN分类模型-CSDN博客
不能错过!故障诊断+时频图像分类大更新!-CSDN博客
智能故障诊断和寿命预测期刊推荐-CSDN博客
故障诊断一区直接写,图卷积+BiGRU-Attention 并行诊断模型-CSDN博客
故障诊断高创新!基于1D-GRU+2D-MTF-ResNet-CBAM的多模态融合分类模型_基于1dcnn-informer+matt融合的故障诊断模型-CSDN博客
创新首发! | 基于1DCNN-Informer+MATT融合的故障诊断模型_论文复现基于 1dcnn bilstm 的航空发动机故障分类研究-CSDN博客
轴承故障特征—SHAP 模型 3D 可视化_shap值溯源模型-CSDN博客
时频图像/多模态+顶会论文创新,故障诊断发文不是梦!-CSDN博客
江南大学轴承故障诊断教程+1DVGG-6种注意力机制合集!-CSDN博客
轴承寿命预测全家桶更新!新增西交XJTU-SY数据集+预测模型合集_hxd3b 型电力机车轴承寿命预测实例中,一张该模型预测结果-CSDN博客
最强更新!西储大学(CWRU)轴承数据集保姆级教程!-CSDN博客
故障诊断 SCI 1 区直接写!基于GADF+SwinTransformer-CBAM+GRU的多模态融合分类模型-CSDN博客
此次更新的代码,凡是购买过我们产品的粉丝,可以后台留言免费获取(或者去面包多网页上更新下载!)
前言
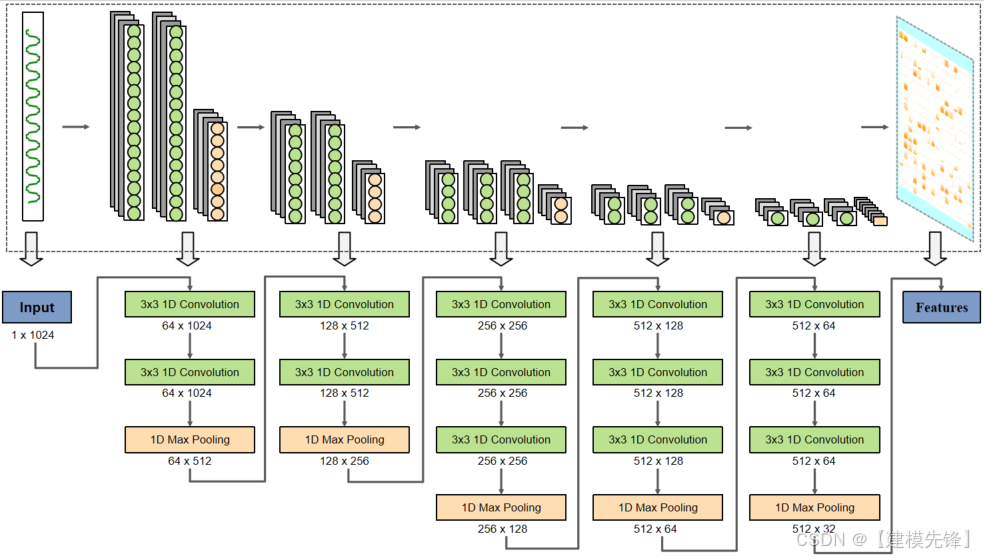
后台有粉丝询问分类模型中的混淆矩阵,如何设置相关参数,才能使样本量保持一致,本期我们围绕混淆矩阵的相关问题,推出基于凯斯西储大学(CWRU)轴承数据1DCNN分类模型进行讲解!
● 数据集:凯斯西储大学(CWRU)轴承数据
● 环境框架:python 3.9 pytorch 2.1 及其以上版本均可运行
● 模型实验:1DCNN
● 使用对象:入门学习,论文需求者
● 代码保证:代码注释详细、即拿即可跑通。
● 配套文件:详细的环境配置安装教程,模型、参数讲解文档
首先需要声明的是:
混淆矩阵用于评估分类模型的性能,尤其是在多类分类任务中,它展示了真实类别与预测类别之间的对应关系。每种类别的样本量不需要相等,特别是在我们往期模型里面,一般使用的公开数据集,都是属于平衡数据集,我们随机打乱样本,然后再划分训练集、验证集、测试集,会导致最终测试集混淆矩阵类别的样本量不完全相同,但是相差的数量不大,没有影响,特别是总体样本量越大,这种类别上的数量差距影响微乎其微。
在投稿过程中审稿人也没有这样的要求,但是我们还是有必要弄清楚和样本量相关的参数,参数之间是怎么影响的;当然混淆矩阵中类别样本量一致也有如下好处:一是方便计算测试集样本量;二是比较美观;三是可以体现出平衡数据集。
问题一 故障信号的样本量由哪些参数决定
故障信号的样本量由如下三个参数共同决定:
-
数据集序列长度
-
样本长度(窗口值)
-
重叠率
1 数据集序列长度
比如说在我们的西储大学(CWRU)十分类任务上,我们对整体数据集有一个截断,来保证我们的所有类别数量有相同的采样点数,当样本长度(窗口值)和重叠率固定的时候,数据集序列越长,样本量肯定越大,反之越小。
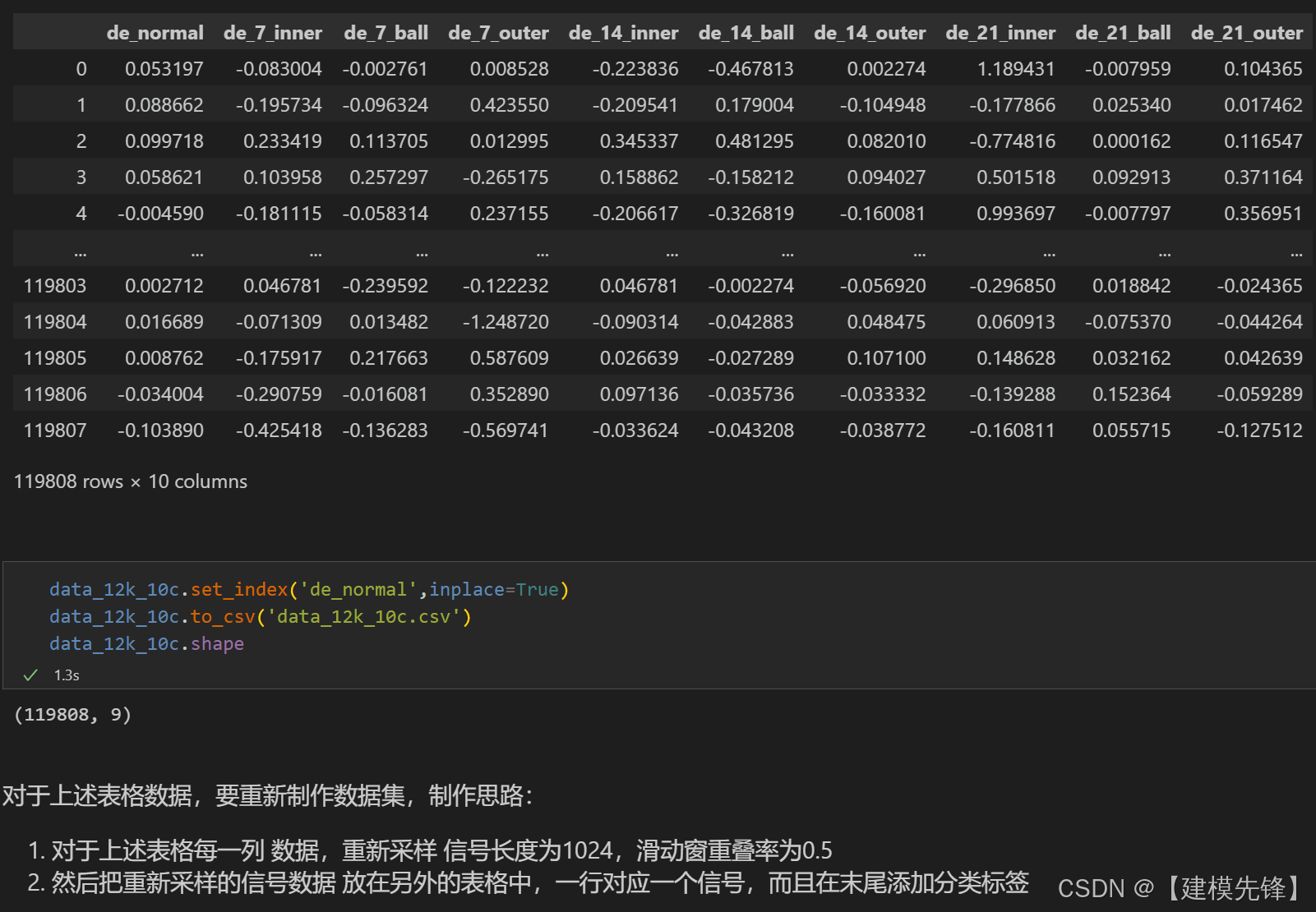
需要注意的是,这个截断值并没有固定,我们一般是按照采样点最少的故障类型的长度来进行截取,来保证整体不同类别有着相同的采样点数。如果需要来设计一定的样本量的时候,适当舍去一些样本量,也是可以的,比如说,假设现在整体数据序列是12000个采样点,当滑动窗口、重叠率固定的时候,一定要生成xx个样本,这样推算后,需要的总体采样点是10000个,那么我们舍弃掉末尾2000个采样点也是可以接受的(相当于给的数据集不一定全部用,用一部分也可以)
2 样本长度(窗口值)和 重叠率
数据集的切分方式也多种多样,切分步长也具有多样性,下面按照固定的参数设置进行数据的切分:
-
步长 window_step:1024 (每个样本长度为1024个点)
-
重叠率 overlap_ratio:0.5(切分相邻两个样本重叠率)
怎么理解重叠率呢?举例如下:

3 怎么计算总体样本量?
要计算在给定序列长度、样本窗口大小以及样本之间的重叠率条件下可以生成的样本数量,我们需要按照以下步骤进行:
第一步定义参数:
- 序列长度:L = 120000
- 样本窗口大小:W = 1024
- 重叠率:overlap = 0.5
- 步长(stride):stride = W * (1 - overlap) = 1024 * (1 - 0.5) = 512
第二步计算样本数量:
公式为:
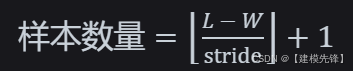
在我们的例子中:

最终每个类别生成233个样本,十分类总共生成2330个样本!然后在我们往期的模型里面,按照7:2:1 划分训练集、验证集、测试集的话,划分数量如下:
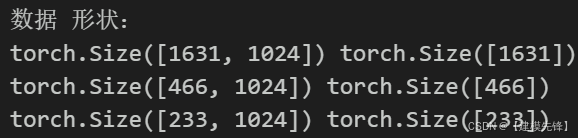
问题二 如何保证混淆矩阵类别样本量一致
1 影响样本量的其他参数
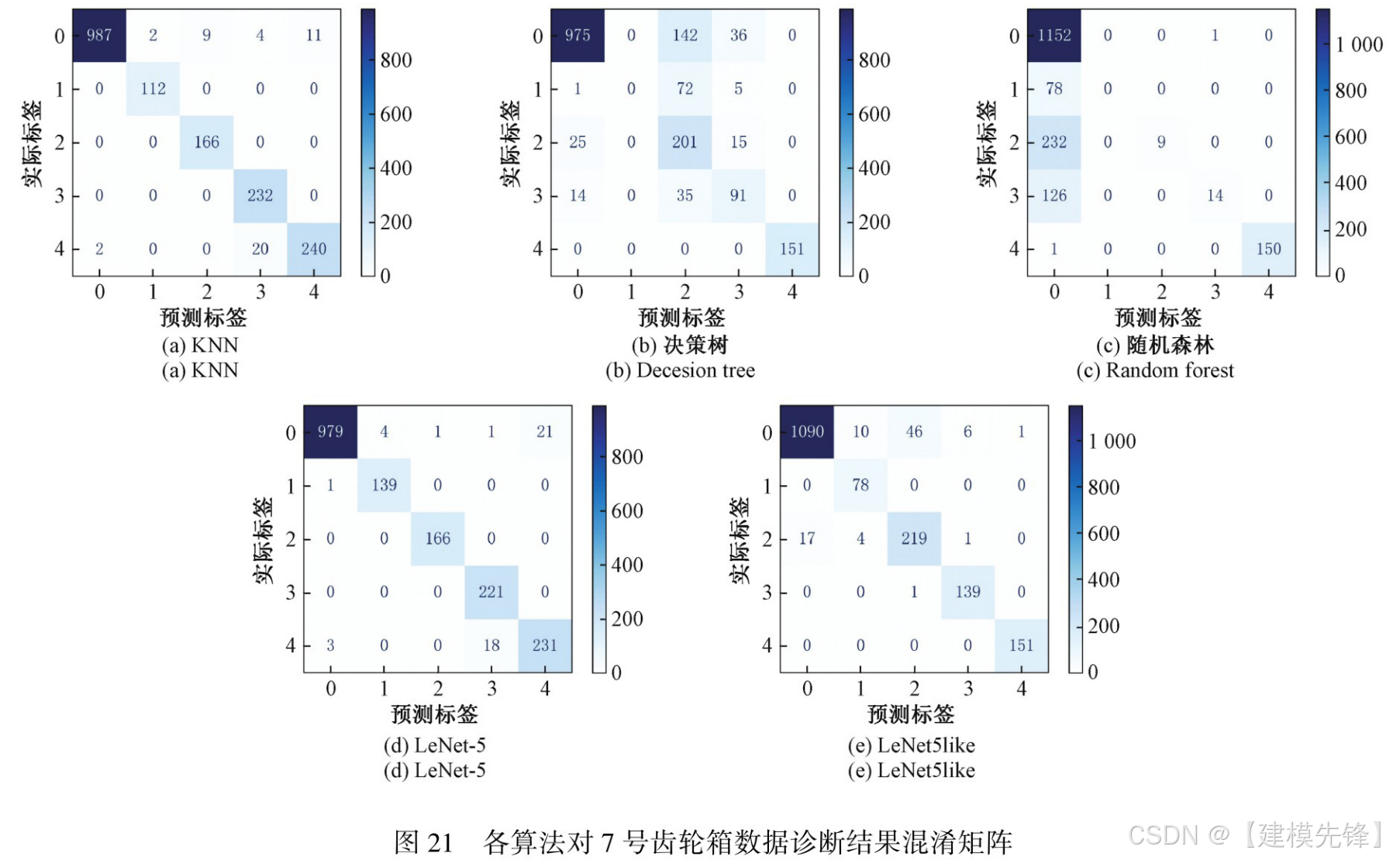
如果按照上述划分来做,可能是这样的评估结果:
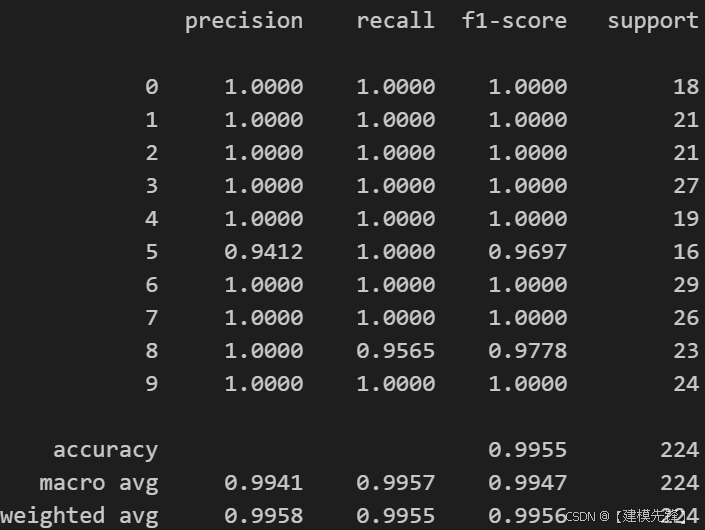
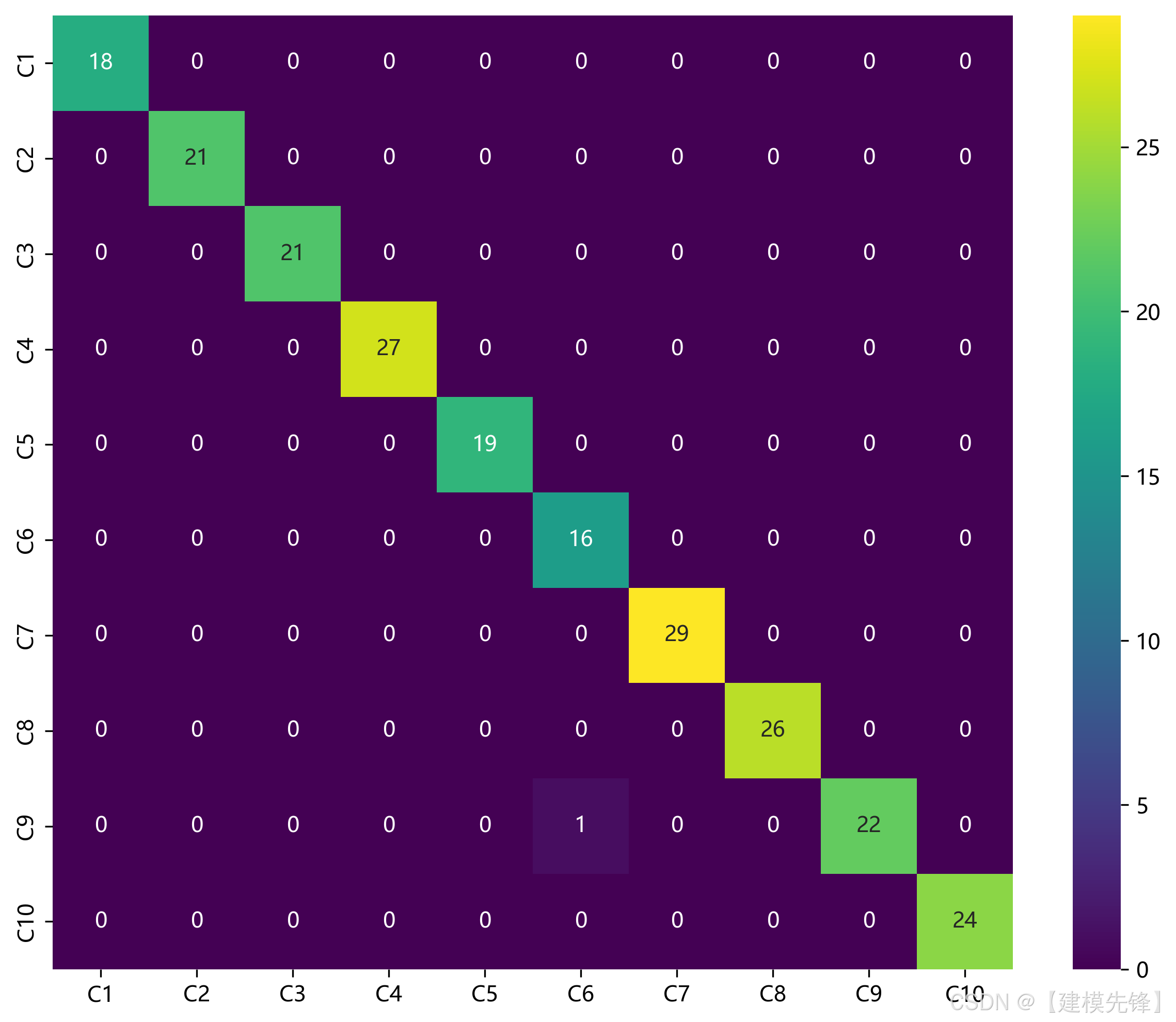
测试集样本量是 224 个,每个类别的样本量也不一致,可能就有同学问了,测试集明明划分的是 233 个样本?这就要提到 batch_size 的原因和drop_last=True,当设置这两个参数的时候,使用批量大小(batch size)进行训练时,数据集中的样本会被分成若干批次(batches)。如果样本总数不能被批量大小整除,那么最后一个批次的样本数量会少于批量大小。通常情况下,为了简化训练过程,最后一个不完整的批次可能会被丢弃,这是因为某些深度学习框架在默认情况下会忽略无法形成完整批次的样本。
如果我们不想丢弃不完整的批次样本,可以设置数据集加载器
drop_last=False,当 drop_last=False 时,数据加载器(如 PyTorch 中的 DataLoader)会在训练过程中将最后一个不完整的批次包含在内。这意味着,即使最后一个批次的样本数少于设置的批量大小(batch size),它也会被用于训练。这种情况下可能会对模型训练产生以下影响:
优点:是所有可用的数据都会被用于训练,不会浪费任何样本。这在数据量本身较少的情况下尤其重要,因为每个样本都可能对模型的学习有价值
缺点:
-
不完整批次可能导致该批次的梯度更新不那么稳定,特别是在批量归一化(Batch Normalization)等依赖于批次统计的操作中。这是因为计算的均值和方差会基于较少的样本数,可能引入一定的偏差。
-
但对于多数模型和任务,这种小的差异通常不会显著影响训练结果,特别是在数据量较大时。
所以 batch size 和 drop_last 的设置也会在一定程度上影响最终的测试集样本量(选择 drop_last=False 是合理的做法,尤其是在希望充分利用所有样本的情况下)
所以现在分情况来考虑参数的设置:
假设现在固定两个参数 :
- 样本窗口大小:W = 1024
- 重叠率:overlap = 0.5
2 情况一:drop_last=False (不用考虑 batch size)
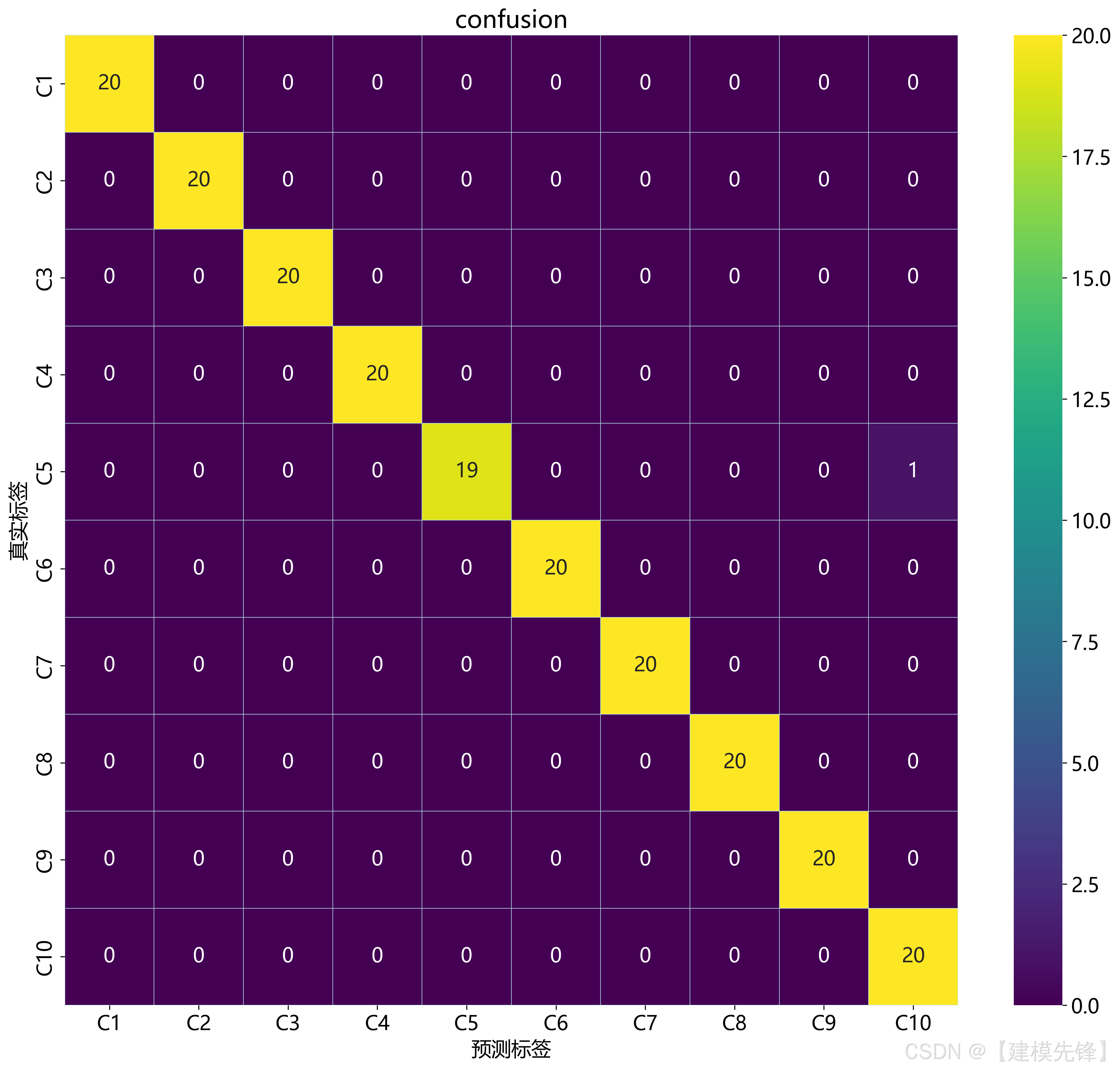
为了达到测试集混淆矩阵类别样本数量一致的目标,那测试集样本量一定是类别数的整数倍。
我们通过先假定测试集样本量,然后来反推问题一中的影响样本量的参数!现在是 10 分类任务,假定测试集中每类样本设置为 20!(测试集总样本量200)那么因为按照 7:2:1 划分训练集、验证集、测试集,测试集占比0.1,所以每个类样本总量为 200 个样本,此时窗口值为 1024, 重叠率为 0.5 , 根据公式:
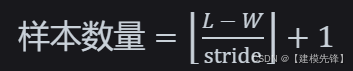
所以每类样本整体序列长度为( 200-1)*512+1024=102912,然后设置序列长度:
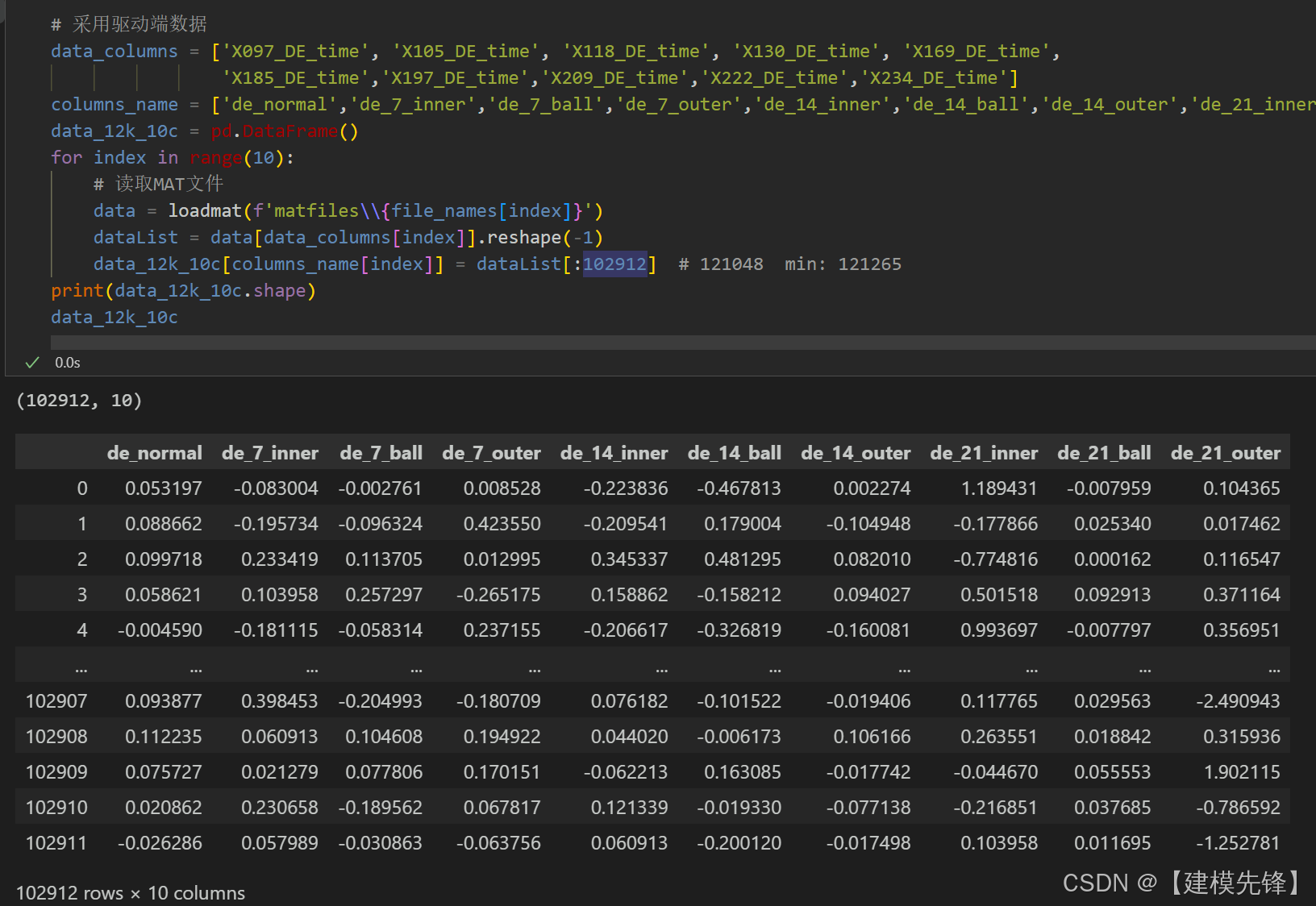
总体样本量为:
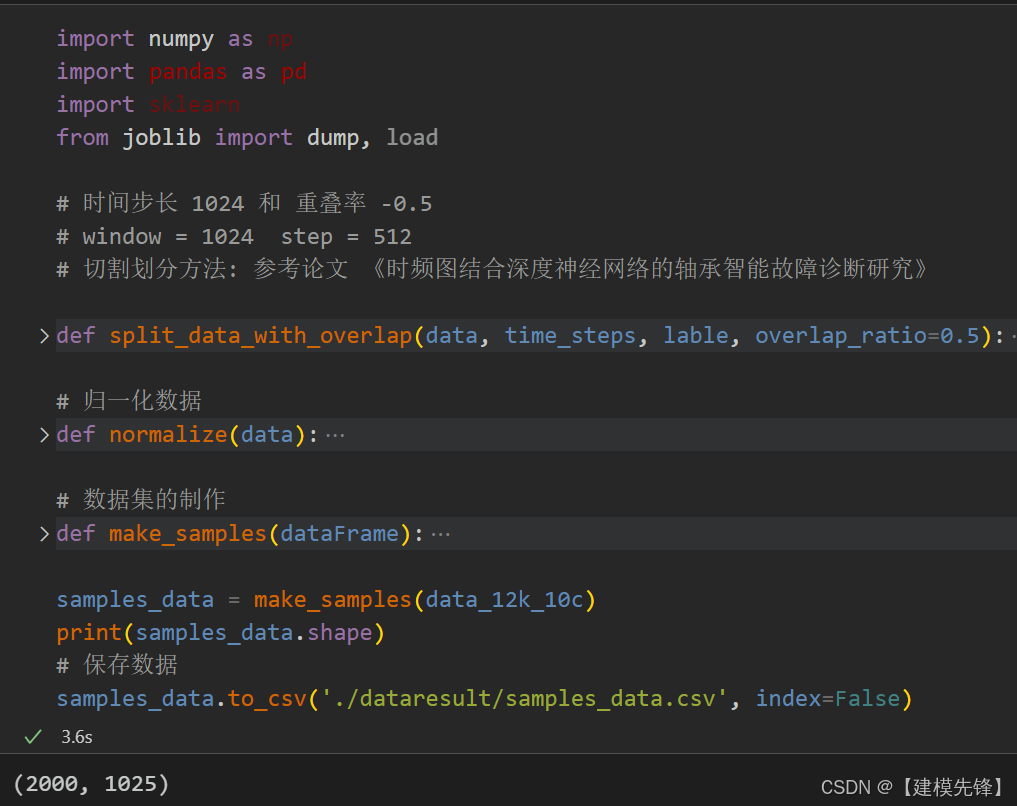
2000个样本,然后需要注意的是样本的划分,要保证划分的测试集中所有类别样本量一致的话,就需要进行分层抽样!
方法一:
利用 python 的 sklearn 包自带的数据划分函数
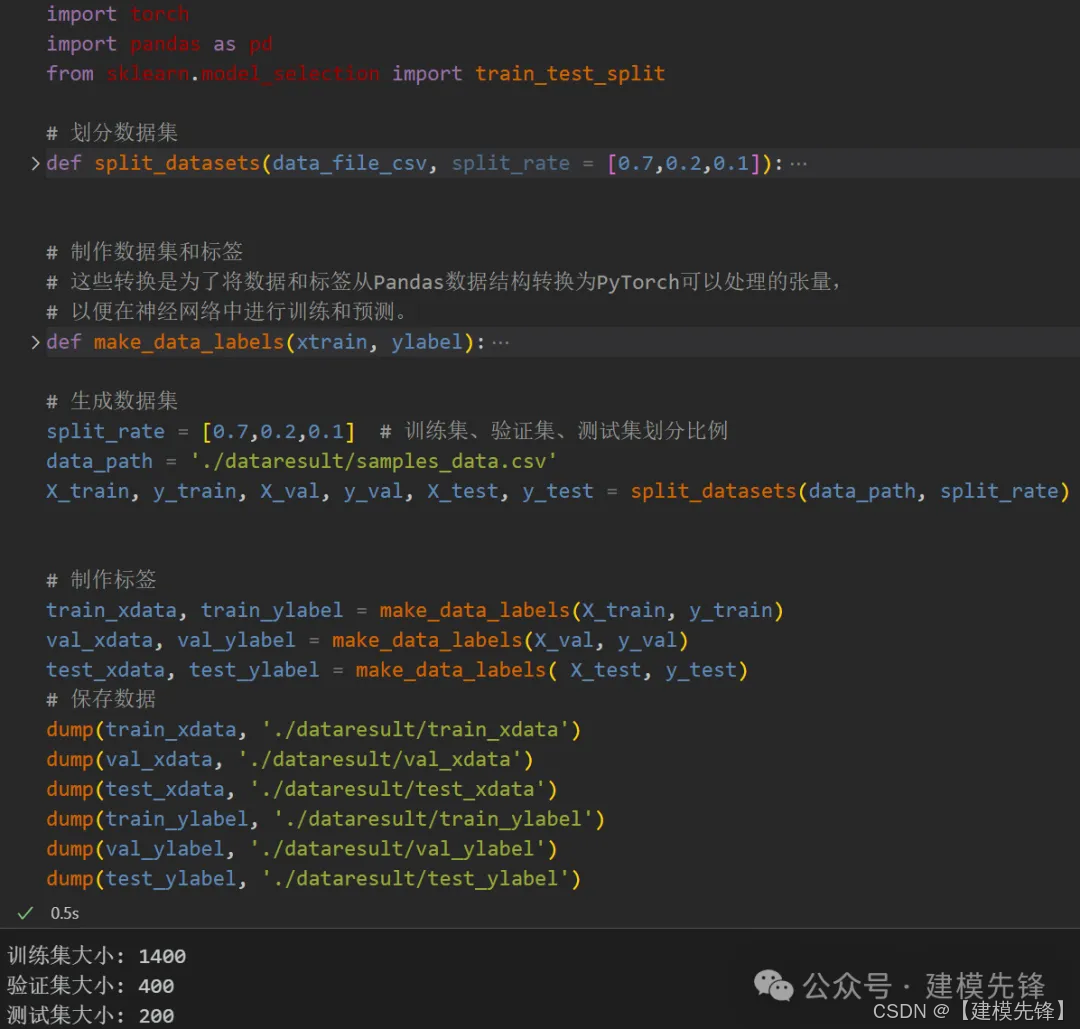
方法二:
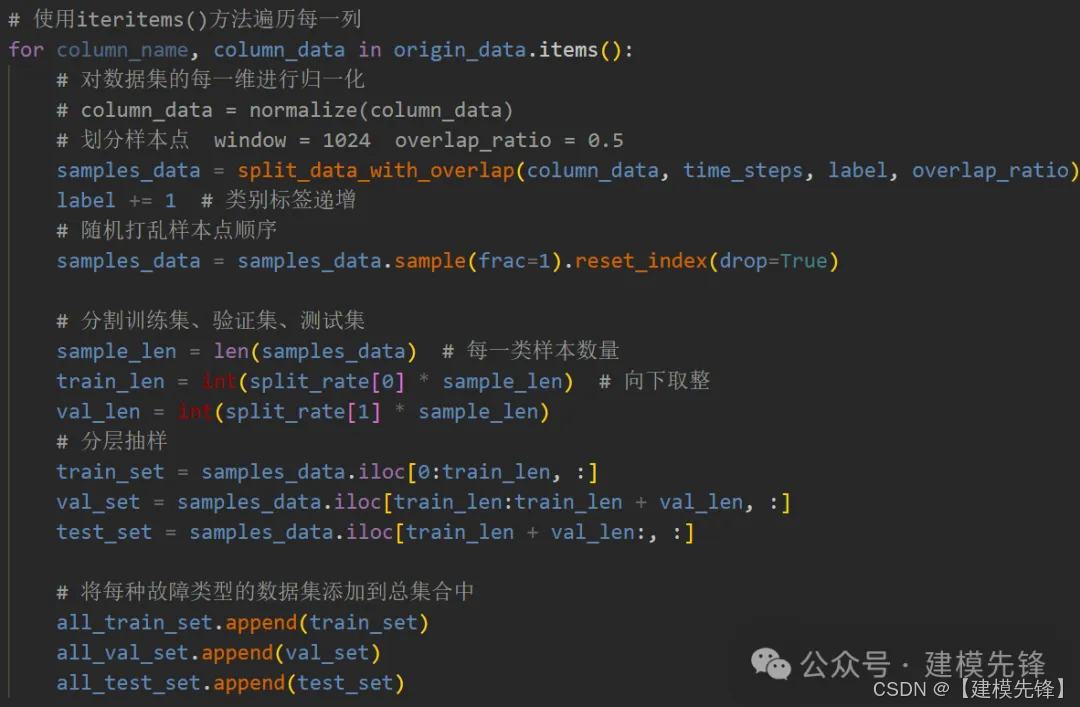
在数据集制作的时候就进行分层抽样
最终测试集混淆矩阵效果:
下一期我们会带来其他情况下样本量的计算方式,和混淆矩阵相关的学习教程!
3 代码、数据整理如下:
点击下方卡片获取代码!