【Mysql基础】一、基础入门和常见SQL语句

📚博客主页:代码探秘者-CSDN博客
🌈:最难不过坚持
✨专栏
| 🌈语言篇 | C语言\ C++ | Javase基础 | ||
|---|---|---|---|---|
| 🌈数据结构专栏 | 数据结构 | |||
| 🌈算法专栏 | 必备算法 | |||
| 🌈数据库专栏 | Mysql | Redis | ||
| 🌈必备篇 |
其他更新ing…
❤️感谢大家点赞👍🏻收藏⭐评论✍🏻,您的三连就是我持续更新的动力❤️
🙏作者水平有限,欢迎各位大佬指点,相互学习进步!

其他更新ing…
❤️感谢大家点赞👍🏻收藏⭐评论✍🏻,您的三连就是我持续更新的动力❤️
🙏作者水平有限,欢迎各位大佬指点,相互学习进步!
一、数据库常见概念
SQL
1.SQL概述
Structure Query Language(结构化查询语言)简称SQL,它被美国国家标准局(ANSI)确定为关系型数据库语言的美国标准,后被国际化标准组织(ISO)采纳为关系数据库语言的国际标准。数据库管理系统可以通过SQL管理数据库;定义和操作数据,维护数据的完整性和安全性。
2.SQL的优点
-
1、简单易学,具有很强的操作性
-
2、绝大多数重要的数据库管理系统均支持SQL
-
3、高度非过程化;用SQL操作数据库时大部分的工作由DBMS自动完成
3.sql通用语法
- 1.sql语句可以单行或者多行书写,以分号结尾
- 2.sql语句可以使用空格/缩进增强语句可读性
- 3.mysql数据库的sql语句不区分大小写,关键字建议使用大写
- 4.注释:
- 1,单行注释–注释内容 内容或者 #注释内容 (mysql特有
- 2.多行注释/* */
4.常用sql语句
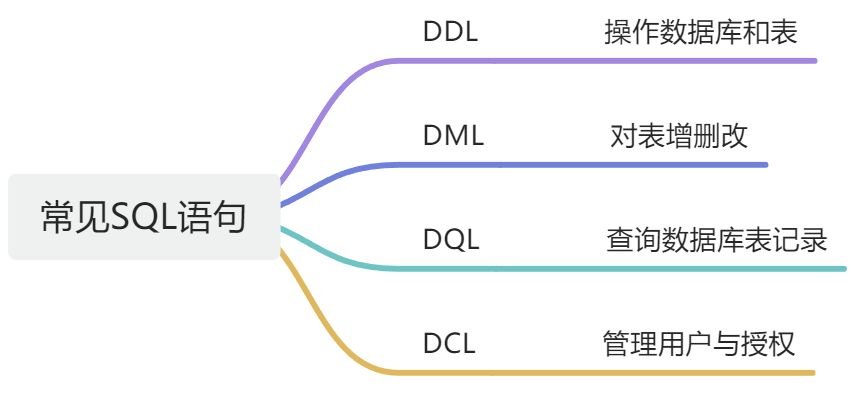
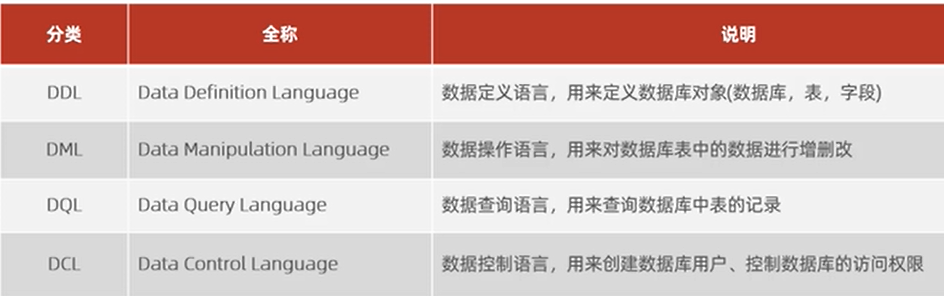
数据库
常见概念
- 1. DBMS 数据库管理系统 (软件)
- 2. DBA 数据库管理员
- 3. DB Database 数据库
一个数据库管理系统 ----> 可以保存很多个数据库
一个数据库中 ----> 保存很多个表
一个表中 ----> 保存很多条数据 很多字段
特点
① 可以持久化保存数据
② 保存数据有组织 有结构 表的形式存储
③ 以表的形式保存数据 方便操作
④ 提供了丰富的SQL语句 操作数据
分类以及特点


| 特性 | 关系型数据库 (RDBMS) | 非关系型数据库 (NoSQL) |
|---|---|---|
| 数据模型 | 表格模型,结构化数据 | 灵活,可以是非结构化、半结构化或结构化数据 |
| 查询语言 | SQL(结构化查询语言) | 各种数据库可能有不同的查询语言,例如MongoDB使用Mongo查询语言 |
| 事务支持 | 支持ACID事务 | 不同的NoSQL数据库对事务的支持程度不同,有些支持ACID,有些则支持最终一致性 |
| 扩展性 | 垂直扩展(增加单个服务器的性能) | 水平扩展(增加更多的服务器) |
| 一致性 | 强一致性 | 可能提供最终一致性或强一致性,取决于具体的数据库 |
| 适用场景 | 需要复杂查询、事务完整性、固定结构的应用 | 大数据、高并发、灵活数据模型的应用 |
| 典型例子 | MySQL, PostgreSQL, Oracle, SQL Server | MongoDB, Cassandra, Redis, Couchbase, Neo4j |
这是网上找到的图,了解一下

Mysql
安装以及配置
下载链接:https://dev.mysql.com/downloads/installer/
环境变量:path中引入mysql的安装目录即可
常见命令:
1. doc命令窗口net stop mysql服务名; 停止mysql服务net start mysql服务名; 启动mysql服务
2. 连接mysql服务mysql 【-hIP地址】 -uroot -p密码
开机自启(尽量弄):
【方式1】
打开“服务”管理器:
- Win+R,运行 services.msc 命令来打开服务管理器。
- 或者在“控制面板”中找到“管理工具”,然后打开“服务”。
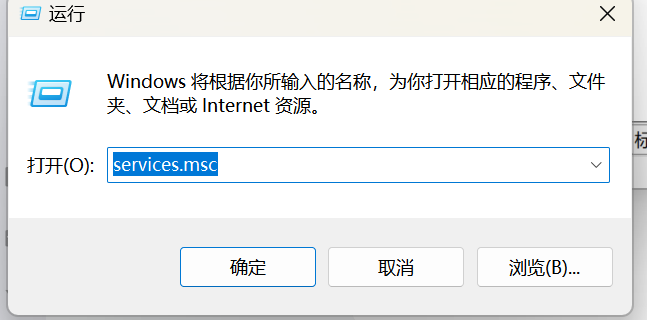
- 找到MySQL80 设置自动启动
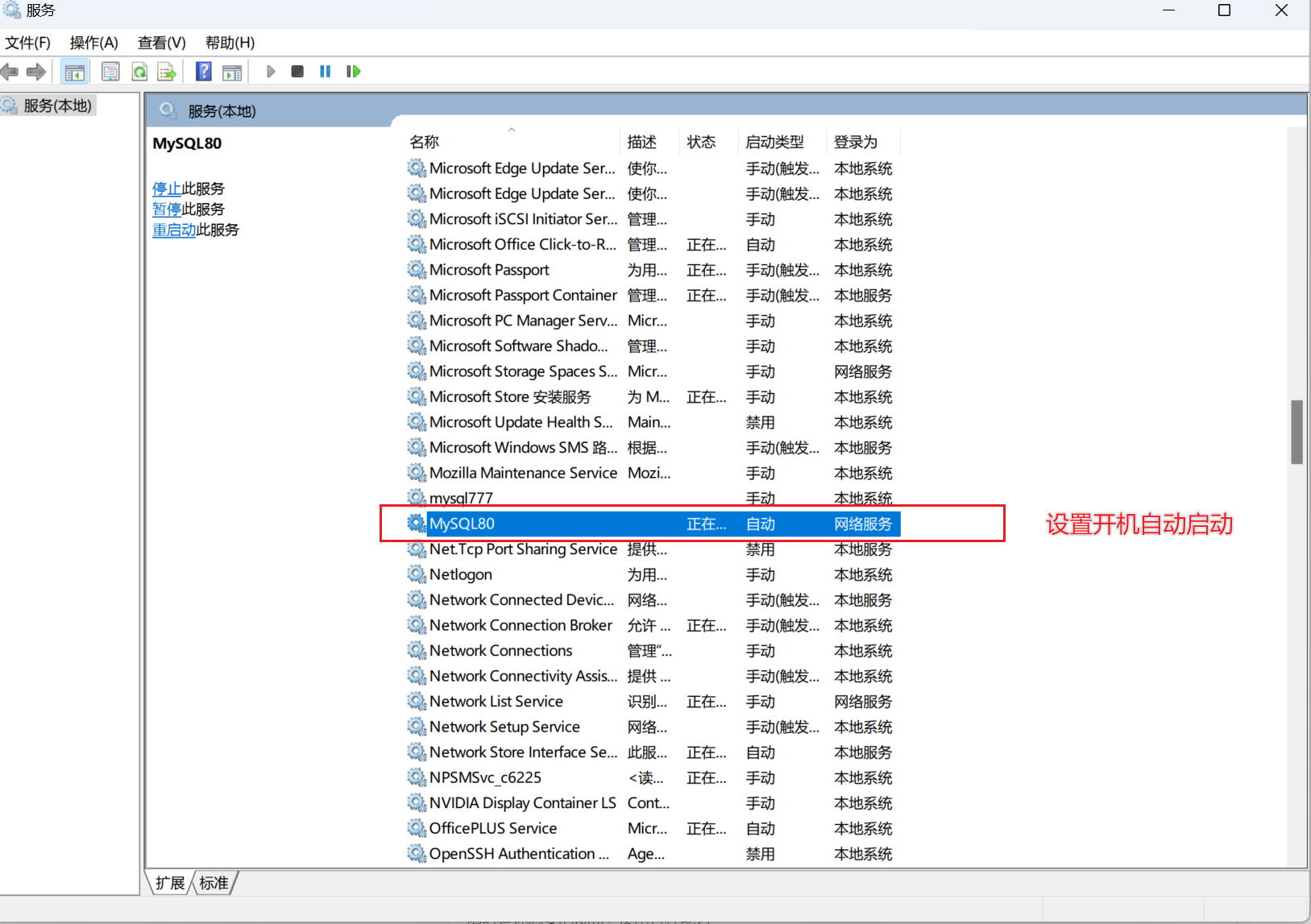
【方式2】
sc config mysql start=AUTO
【方式3】
如果出错,执行sql
SET sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
二、DDL(数据定义语言)

数据库指令:
查询所有数据库
SHOW DATABASES;
查询当前数据库
SELECT DATABASE();
创建
CREATE DATABASE (数据库名Database_Name);
create database if not exists (数据库名);
create database ithema default charset utf8mb4; -- 定义了字符集
删除
DROP DATABASE Database_Name;
DROP DATABASE if exists Database_Name;
使用
use Database_Name;
表指令:
创建表
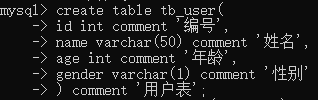
comment:注释
字段1类型 comment’',
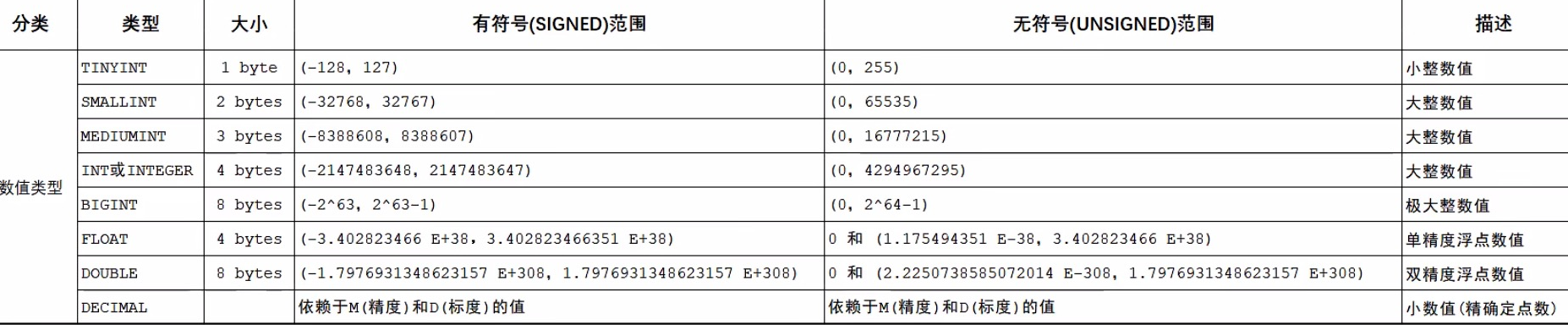
数值类型
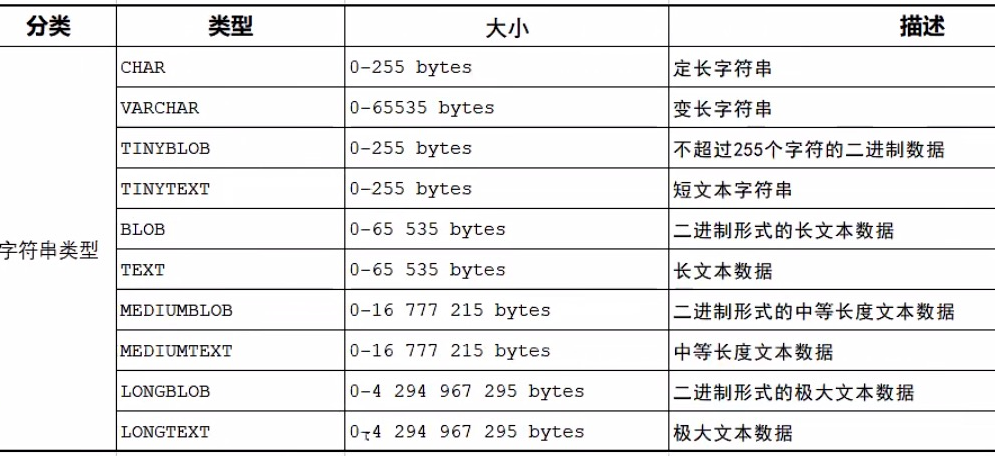

删除表
drop table [if exist] table-name;
删除指定表,并重新创建该表
truncate table table-name
修改表名
alter table table-name rename to new-table-name;
查询表结构
desc 表名;
查询指定表的建表结构
show create table 表名;
表操作 alert
添加字段
alter table 表名 add 字段名 类型 [comment '昵称'];
- comment为其添加的注释(可以不需要)
需要指定插入位置:
ALTER TABLE my_table ADD COLUMN new_column VARCHAR(255) AFTER existing_column;
- 可以使用FIRST(将字段添加到表的第一个位置)或AFTER(将字段添加到指定字段之后)。例如,将new_column添加到existing_column之后:
修改数据类型
alter table 表名 modify 字段名 类型;
修改字段名和字段类型
alter table 表名 change 旧字段名 新字段名 类型 [comment 'XX'];
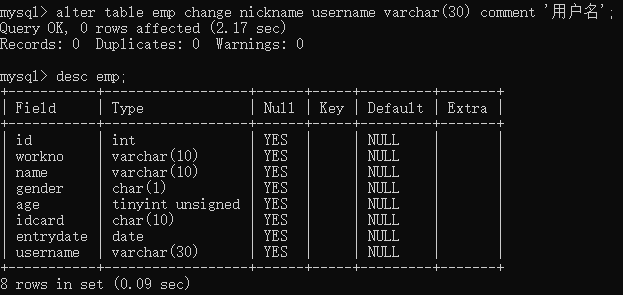
删除字段
alter table table-name drop 字段名;
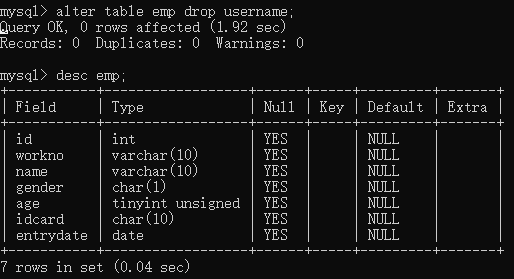
三、DML(数据操作语言)
INSERT 添加数据
- column—字段
- values—值
1. 给指定字段添加数据
INSERT INTO table_name (column1, column2, column3....)
VALUES (value1, value2, value3.....);
- (column1, column2, column3…) 是对应字段
2. 给全部字段添加数据
INSERT INTO table_name
VALUES (value1, value2, value3....);
3. 批量添加数据
INSERT INTO table_name (column1, column2, column3....),(column1, column2, column3....)
VALUES (value1, value2, value3.....),(value1, value2, value3.....);

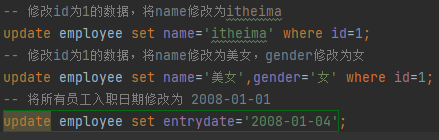
UPDATE 修改数据
UPDATE table_name SET [column_name1= value1,... column_nameN = valueN] [WHERE condition]
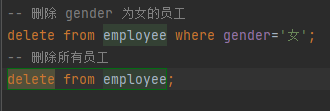
DELETE 删除数据
DELETE FROM table_name [WHERE condition];
不能删除某一字段的值,如果要删除,可以使用update将值改为NULL.
四、DQL(数据查询语言)
编写/执行顺序
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY -> LIMIT
- 选字段,表起始(不用记也行)
- 条件过滤(where)再分组(group by)
- 聚合条件排排序(c,m,a,s+having)
- 分页限制(limit)放最后。
SELECT字段列表
FROM表名字段
WHERE条件列表
GROUP BY分组字段列表
HAVING分组后的条件列表
ORDER BY排序字段列表
LIMIT分页参数
基本查询 select from

select 基本查询
-- 基本查询-- 1. 查询指定字段 name, workno, age 返回
select name,workno,age from emp;-- 2. 查询所有字段返回
select * from emp;
select id, workno, name, gender, age, idcard, workaddress, entrydate from emp;
as 起别名
-- 查询所有员工的工作地址,as 给字段起别名
select workaddress from emp;
select workaddress as '工作地址' from emp;
select workaddress '工作地址' from emp; -- as可以省略
distinct 去重
-- 查询员工的上班地址(distinct 不要重复)
select workaddress from emp;
select distinct workaddress from emp;
条件查询 where
SELECT * FROM Name_of_Table WHERE [condition];
常见运算符
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <> 或 != | 不等于 |
| 逻辑运算符 | 功能 |
|---|---|
| AND 或 && | 并且(多个条件同时成立) |
| OR 或 | |
| NOT 或 ! | 非,不是 |
-- 条件查询
-- 1. 查询年龄等于88的员工
select * from emp where age = 88;-- 2. 查询年龄小于20的员工信息
select * from emp where age < 20;-- 3. 查询年龄小于等于20的员工信息
select * from emp where age <= 20;-- 4. 查询没有身份证号的员工信息
select * from emp where idcard is NULL;-- 5. 查询有身份证号的员工信息
select * from emp where idcard is not NULL;-- 6. 查询年龄不等于88的员工信息
select * from emp where age != 88;| BETWEEN … AND … | 在某个范围内(含最小、最大值) |
|---|---|
| IN(…) | 在in之后的列表中的值,多选一 |
| LIKE 占位符 | 模糊匹配(_匹配单个字符,%匹配任意个字符) |
| IS NULL | 是NULL |
between and 和in
-- 7. 查询年龄在15岁(包含)到20岁(包含)直接的员工信息
select * from emp where age between 15 and 20;
select * from emp where age >= 15 and age <= 20;
select * from emp where age >= 15 && age <= 20;-- 8. 查询性别为女 且 年龄小于25岁的员工信息
select * from emp where gender = '女' and age < 25;-- 9. 查询年龄等于18 或 20 或 40 的员工信息
select * from emp where age = 18 or age = 20 or age = 40;
select * from emp where age in(18,20,40);
【注意】
- BETWEEN AND 用于指定一个连续的范围,包括两个端点。
- BETWEEN AND 的区间是左闭右闭,这里包括了15和20)
- 不是左闭右开!
- 使用 BETWEEN AND 时,如果顺序颠倒(例如 BETWEEN 10000 AND 5000),SQL语句会返回空结果,但不会报错。
- IN 用于指定一组不连续的、具体的值。
like 模糊查询
like 通过通配符定义模糊匹配的规则:
| 通配符 | 描述 | 示例 |
|---|---|---|
| % | 匹配任意长度的字符(包括零个字符) | **a% ** 匹配以 a 开头的字符串 |
| _ | 匹配单个字符 | a_ 匹配 ab, ac 等(第二个字符任意) |
-- 查询姓名为两个字的员工信息
select * from emp where name like '__';-- 查询身份证号最后一位是X的员工信息
select * from emp where idcard like '_________________X';
select * from emp where idcard like '%X';
常见场景
-- 1.匹配以特定字符开头
-- 查找以 "apple" 开头的字符串(如 "apple", "applepie")
SELECT * FROM fruits WHERE name LIKE 'apple%';
-- 2.匹配以特定字符结尾
-- 查找以 "ana" 结尾的字符串(如 "banana", "orangeana")
SELECT * FROM fruits WHERE name LIKE '%ana';
-- 3.匹配中间任意字符
-- 查找第三个字符是 "g" 的字符串(如 "logging", "blogging")
SELECT * FROM logs WHERE message LIKE '__g%';
-- 4.匹配任意位置的字符
-- 查找包含 "an" 的字符串(如 "banana", "android")
SELECT * FROM fruits WHERE name LIKE '%an%';-- 5.混合使用 % 和 _ 进行复杂匹配
-- 查找以 "a" 开头,第四个字符是 "t" 的字符串(如 "action", "artist")
SELECT * FROM words WHERE word LIKE 'a__t%';-- 6.转义:需要匹配 % 或 _ 本身,需使用 转义字符(默认是 \):
-- 查找包含 "%" 的字符串(如 "50%", "discount%")
SELECT * FROM products WHERE price LIKE '%\%%' ESCAPE '\';
-- 查找包含 "_" 的字符串(如 "user_name")
SELECT * FROM users WHERE username LIKE '%\_%' ESCAPE '\';
聚合查询 count, max, min, avg, sum
聚合查询是 SQL 中对一组数据进行 汇总计算 的操作,常用于统计、分组分析等场景。它通过 聚合函数(如 SUM、AVG、COUNT 等)对数据进行处理,并结合 GROUP BY 子句实现分组统计。
常见聚合函数:
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
SELECT 聚合函数(字段列表) FROM 表名;
SELECT count(id) from employee where workaddress = "广东省";
-- 聚合函数
-- 1. 统计该企业员工数量
select count(id) from emp;
select count(*) from emp;-- 2. 统计该企业员工的平均年龄
select avg(age) from emp;-- 3. 统计该企业员工的最大年龄
select max(age) from emp;-- 4. 统计该企业员工的最小年龄
select min(age) from emp;-- 5. 统计西安地区员工的年龄之和
select sum(age) from emp where workaddress = '西安';
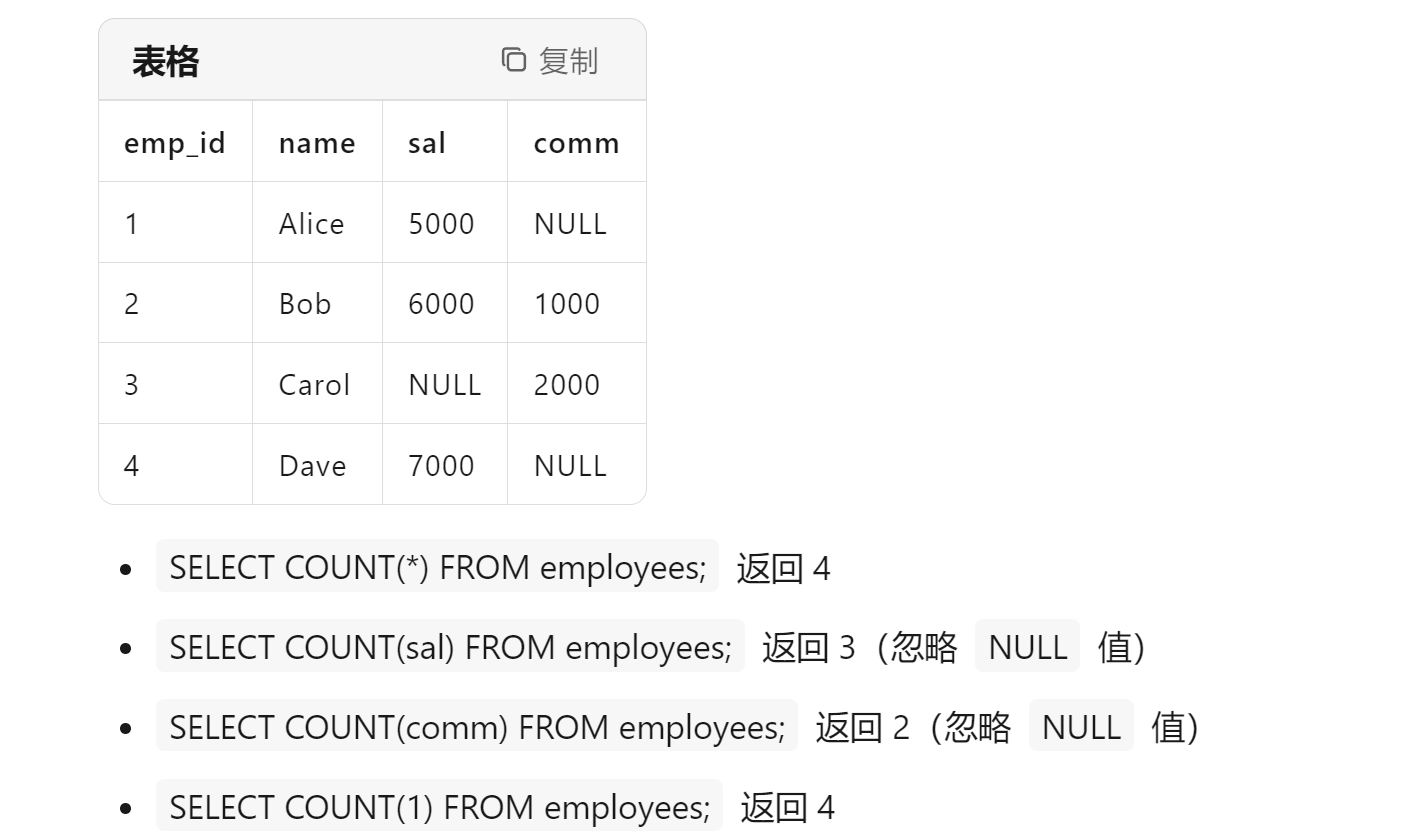
count(*) 、count(字段)、count(1)
count(*)
- 统计所有行的数量,包括(null值,就是不会忽略任何一行)
- 就是计算行数,不处理具体列,因此性能通常比较高
count(1)
- 和count(*) 几乎没有区别
count(字段)
- 统计指定字段不为null值的行数
比如:
分组查询 group by
SELECT 字段列表 FROM 表名 [ WHERE 条件 ] GROUP BY 分组字段名 [ HAVING 分组后的过滤条件 ];
where 和 having 的区别
- 执行时机不同:
- where是分组之前进行过滤,不满足where条件不参与分组;
- having是分组后对结果进行过滤。
- 判断条件不同:
- where不能对聚合函数进行判断而having可以。
-- 分组查询
-- 1. 根据性别分组,统计男性员工 和 女性员工的数量
select gender, count(*) from emp group by gender;-- 2. 根据性别分组,统计男性员工 和 女性员工的平均年龄
select gender, avg(age) from emp group by gender;
having
- 分组后再过滤
- 下面取了一个别名,用别名进行过滤
-- 3. 查询年龄小于45的员工,并根据工作地址分组,获取员工数量大于等于3的工作地址
select workaddress, count(*) from emp where age < 45 group by workaddress having count(*) >= 3;
select workaddress, count(*) as adress_count from emp where age < 45 group by workaddress having adress_count >= 3;
【注意】
- 执行顺序:where > 聚合函数 > having
- 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义
排序查询 order by
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1, 字段2 排序方式2;
排序方式
- ASC: 升序(默认)
- DESC: 降序
多字段排序
如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
-- 排序查询
-- 1. 年龄升序
select * from emp order by age ASC;
select * from emp order by age;-- 2. 入职时间降序
select * from emp order by entrydate DESC;-- 3. 年龄升序,年龄相同,入职时间降序
select * from emp order by age asc, entrydate desc;
分页查询 limit
SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查询记录数;
【注意】
- 起始索引从0开始,起始索引 = (查询页码 - 1) * 每页显示记录数
- 分页查询是数据库的方言,不同数据库有不同实现,MySQL是LIMIT
- 如果查询的是第一页数据,起始索引可以省略,直接简写 LIMIT 10
-- 分页查询
-- 1. 查询第1页员工数据,每页展示10条记录
select * from emp limit 10;
select * from emp limit 0,10;-- 2. 查询第2页员工数据,每页展示10条记录---起始索引=(查询页码 - 1)*每页显示记录数, 查询记录数
select * from emp limit 10, 10;
DQL语句练习
-- DDL语句联系
-- 1. 年龄20,21,22,23的女性 (条件查询)
select * from emp where gender='女' and age in (20,21,22,23);-- 2. 男性,年龄20-40(含),姓名三个字 (条件查询)
select * from emp where gender='男' and (age between 20 and 40) and name like '___';-- 3. 年龄 < 60 的男女人数 (分组查询,聚合查询)
select gender, count(*) from emp where age < 60 group by gender;-- 4. 年龄 <= 35 的姓名和年龄,年龄升序,相同,入职时间降序 (排序查询)
select name,age from emp where age <= 35 order by age ASC, entrydate DESC;-- 5. 性别男,年龄20-40(含)之内的前5个,年龄升序,相同,入职时间升序 (排序查询,分页查询)
select name,gender,age,entrydate from emp where gender='男' and (age between 20 and 40) order by age ASC, entrydate ASC limit 0,5;
五、DCL(数据控制语言)
用于管理数据库用户,控制数据库访问权限
查询用户
USER mysql;
SELECT * FROM user;
创建用户 create
CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';
修改用户密码 alter
ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码';
删除用户 drop
DROP USER '用户名'@'主机名';
-- 创建用户itcast,只能在当前主机localhost访问,密码123456
create user 'itcast'@'localhost' identified by '123456';-- 创建用户heima,能在任意主机访问,密码123456
create user 'heima'@'%' identified by '123456';-- 修改heima密码1234
alter user 'heima'@'%' identified with mysql_native_password by '1234';-- 删除用户itcast@localhost
drop user 'itcast'@'localhost';
【注意】
- 主机名可以使用 % 通配
权限控制
常用权限:
| 权限 | 说明 |
|---|---|
| ALL, ALL PRIVILEGES | 所有权限 |
| SELECT | 查询数据 |
| INSERT | 插入数据 |
| UPDATE | 修改数据 |
| DELETE | 删除数据 |
| ALTER | 修改表 |
| DROP | 删除数据库/表/视图 |
| CREATE | 创建数据库/表 |
查询权限 show grants
SHOW GRANTS FOR '用户名'@'主机名';
授予权限 grant
GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'主机名';
撤销权限 revoke
REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名';
例子
-- 查询权限
show grants for 'heima'@'%';-- 授予权限 (授予针对于itcase这个数据库的所有表的所有权限)
grant all on itcase.* to 'heima'@'%';-- 查询权限 (撤销针对于itcase这个数据库的所有表的所有权限)
revoke all on itcase.* from 'heima'@'%';
注意事项
- 多个权限用逗号,分隔
- 授权时,数据库名和表名可以用 * 进行通配,代表所有