并发笔记-锁(一)
文章目录
- 1. 基本问题与锁的概念 (The Basic Idea)
- 2. 锁的API与Pthreads (Lock API and Pthreads)
- 3. 构建锁的挑战与评估标准 (Building A Lock & Evaluating Locks)
- 4. 早期/简单的锁实现尝试及其问题 (Early/Simple Attempts)
- 4.1 控制中断 (Controlling Interrupts)
- 4.2 仅使用加载/存储指令 (Figure 28.1 - A Failed Attempt)
- 5. 基于硬件原子指令的自旋锁 (Hardware Primitives & Spin Locks)
- 5.1 测试并设置 (Test-and-Set / Atomic Exchange) (Figure 28.3)
- 5.2 其他原子指令
- 5.3 票据锁 (Ticket Lock) (使用 Fetch-and-Add 实现公平性) (Figure 28.7)
- 6. 避免过度自旋:操作系统支持 (Avoiding Excessive Spinning: OS Support)
- 6.1 简单方法:让步 (Yield) (Figure 28.8)
- 6.2 使用队列:休眠代替自旋 (Using Queues: Sleeping Instead Of Spinning) (Figure 28.9)
- 7. 高级主题与实际考量 (Advanced Topics & Real-World Considerations)
- 7.1 Linux Futex (Fast Userspace muTEX) (Figure 28.10 概念)
- 7.2 优先级反转 (Priority Inversion)
- 8. Peterson算法
- 8.1 核心思想
- 8.2 算法组件(共享变量)
- 8.3 算法流程(以进程P_i为例,另一个进程为P_j)
- 8.4 为什么Peterson算法能工作?(满足互斥的三个条件)
- 8.5 优点
- 8.6 缺点和局限性
- 9. 锁改进机制的演进流程
- 9.1 最原始尝试 - 控制中断
- 9.2 简单软件尝试 - 仅使用加载/存储指令(失败)
- 9.3 硬件原子指令支持 - 自旋锁(第一次重大改进)
- Test-and-Set 自旋锁
- 票据锁(改进公平性)
- 9.4 操作系统支持 - 避免过度自旋(第二次重大改进)
- 简单让步(Yield)
- 使用队列:休眠代替自旋
- 9.5 混合策略 - Linux Futex(最优化方案)
- 9.6 总结改进流程
- 10. 简要总结
1. 基本问题与锁的概念 (The Basic Idea)
- 核心问题: 在并发环境中,如何确保一系列指令(临界区, critical section)能够原子地 (atomically) 执行,以防止因中断或多线程/多处理器并发访问共享资源而导致的竞争条件。
- 锁 (Lock): 一种同步机制,程序员用它来"标记"临界区。其目标是确保在任何时刻,只有一个线程能够进入该临界区执行,使得这段代码如同一个不可分割的原子指令。
- 锁的状态: 锁变量自身通常有两种状态:
- 可用 (available / unlocked / free): 没有线程持有该锁。
- 已被获取 (acquired / locked / held): 某个线程正持有该锁。
2. 锁的API与Pthreads (Lock API and Pthreads)
- 基本操作:
lock(): 尝试获取锁。如果锁已被其他线程持有,则调用线程通常会等待(阻塞或自旋)。unlock(): 释放当前线程持有的锁,这可能唤醒一个正在等待该锁的线程。
- Pthreads: POSIX线程库提供了互斥量 (mutex) 作为锁的实现,类型为
pthread_mutex_t。pthread_mutex_lock(&mutex): 获取互斥锁。pthread_mutex_unlock(&mutex): 释放互斥锁。
- 锁的粒度:
- 粗粒度锁 (Coarse-grained locking): 用一个锁保护大块数据或多个数据结构。简单但可能限制并发性。
- 细粒度锁 (Fine-grained locking): 用多个锁分别保护不同的数据或数据结构的不同部分。复杂但能提高并发性。
3. 构建锁的挑战与评估标准 (Building A Lock & Evaluating Locks)
构建一个高效且正确的锁通常需要硬件原子指令和操作系统支持。
评估锁的主要标准:
- 互斥性 (Mutual Exclusion): 这是最基本的要求。锁必须能阻止多个线程同时进入临界区。
- 公平性 (Fairness): 等待锁的线程是否都有机会获取锁?是否存在某些线程会饿死 (starvation)(即永远无法获得锁)的情况?
- 性能 (Performance): 锁操作本身带来的开销。
- 无竞争情况下的开销(单个线程获取和释放锁)。
- 高竞争情况下的开销(多个线程争抢同一个锁),需考虑单CPU和多CPU场景。
4. 早期/简单的锁实现尝试及其问题 (Early/Simple Attempts)
4.1 控制中断 (Controlling Interrupts)
(主要用于早期单处理器系统内核)
- 原理: 在进入临界区前禁用中断,退出后启用中断。
- 缺点: 需要特权指令;滥用风险高;不适用于多处理器系统;长时间禁用中断会导致系统响应问题和中断丢失。
4.2 仅使用加载/存储指令 (Figure 28.1 - A Failed Attempt)
// lock_t结构定义
typedef struct __lock_t {int flag; // 0: lock is available, 1: lock is held
} lock_t;void init(lock_t *mutex) {mutex->flag = 0; // 初始化锁为可用
}void lock(lock_t *mutex) {while (mutex->flag == 1) // 检查锁是否被持有 (TEST); // 自旋等待 (spin-waiting)mutex->flag = 1; // 获取锁 (SET it!)
}void unlock(lock_t *mutex) {mutex->flag = 0; // 释放锁
}
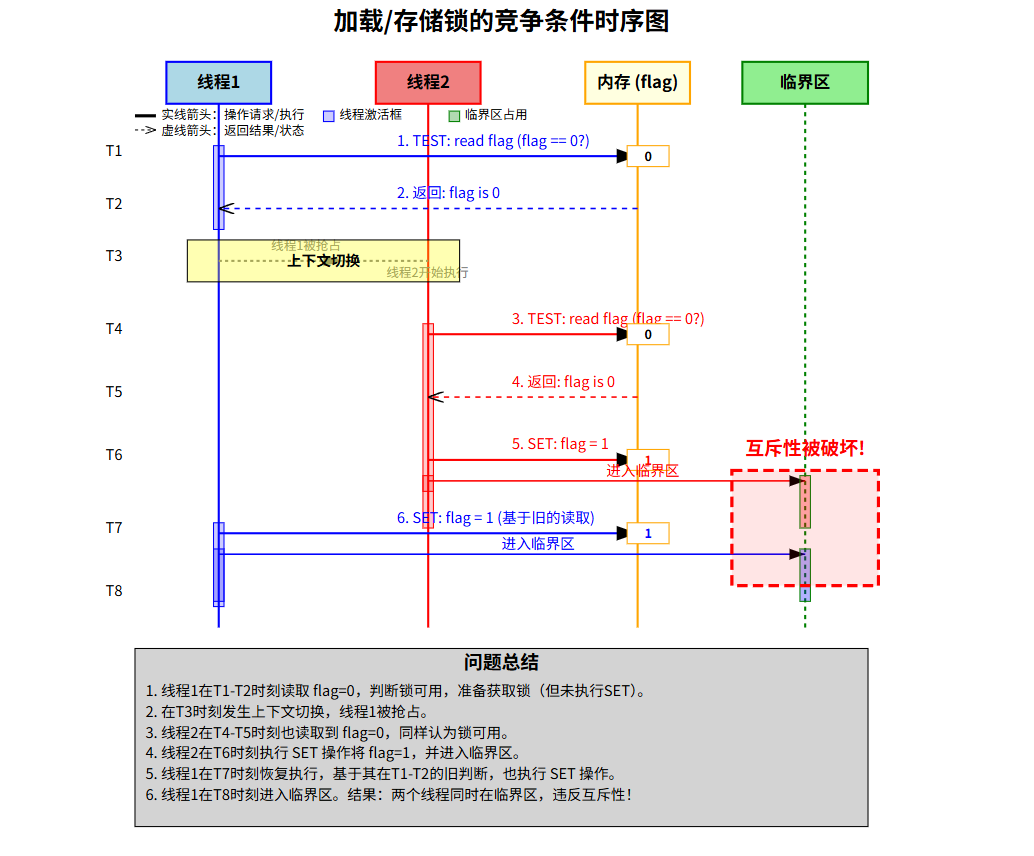
笔记:
- 原理: 尝试用一个共享
flag变量表示锁状态。 - 关键问题: 不正确! 在
while (mutex->flag == 1)(TEST) 和mutex->flag = 1(SET) 之间存在竞争条件。如果一个线程在TEST之后、SET之前被中断,另一个线程可能也通过TEST并进入临界区,破坏互斥性。 - 缺点: 不保证互斥性;引入了自旋等待 (spin-waiting),即使在单CPU上也可能浪费CPU。
- 目的: 此例说明了构建锁为何需要原子操作。
5. 基于硬件原子指令的自旋锁 (Hardware Primitives & Spin Locks)
现代CPU提供特殊的原子指令来构建锁。自旋锁是指当线程尝试获取一个已被持有的锁时,它会持续地循环检查(“自旋”)锁的状态,直到锁变为可用。
5.1 测试并设置 (Test-and-Set / Atomic Exchange) (Figure 28.3)
- 原子指令
TestAndSet(int *old_ptr, int new_val): 原子地读取*old_ptr的旧值,将*old_ptr设置为new_val,并返回旧值。
// lock_t结构定义同上
void init(lock_t *lock) { lock->flag = 0; }void lock(lock_t *lock) {// TestAndSet返回flag的旧值,并原子地将其设置为1// 若旧值为1 (锁已被持有),继续自旋// 若旧值为0 (锁可用),循环终止,锁已被当前线程获取 (flag已被原子设为1)while (TestAndSet(&lock->flag, 1) == 1); // 自旋等待
}void unlock(lock_t *lock) { lock->flag = 0; }
笔记:
- 关键:
TestAndSet的原子性保证了测试和设置操作之间不会被打断,从而确保互斥。 - 优点: 简单、保证互斥。
- 缺点: 仍是自旋等待;不保证公平性,可能导致线程饿死。
- 适用: 临界区非常短的多处理器系统。
5.2 其他原子指令
- 比较并交换 (Compare-and-Swap - CAS):
CAS(ptr, expected, new)原子地比较*ptr与expected,若相等则将*ptr更新为new,并返回操作是否成功(或旧值)。功能比Test-and-Set更强大。 - 加载链接/条件存储 (Load-Linked / Store-Conditional - LL/SC):
LL加载一个值,SC只有在该内存位置自LL以来未被其他操作修改过的情况下,才会将新值存储成功。 - 读取并加 (Fetch-and-Add):
FetchAndAdd(ptr, val)原子地读取*ptr的旧值,然后将*ptr增加val,并返回旧值。
5.3 票据锁 (Ticket Lock) (使用 Fetch-and-Add 实现公平性) (Figure 28.7)
typedef struct __lock_t {int ticket; // 下一个可用的票号int turn; // 当前轮到哪个票号
} lock_t;void lock_init(lock_t *lock) { lock->ticket = 0; lock->turn = 0; }void lock(lock_t *lock) {int myturn = FetchAndAdd(&lock->ticket); // 原子地获取票号while (lock->turn != myturn); // 自旋等待轮到自己的号
}void unlock(lock_t *lock) {// FetchAndAdd(&lock->turn, 1); // 更安全的做法是也用原子操作lock->turn = lock->turn + 1; // 书中简化
}
笔记:
- 原理: 模拟排队。
FetchAndAdd原子地分配唯一的、递增的ticket号。线程等待全局turn号轮到自己。 - 优点: 保证互斥性;保证公平性 (FIFO),避免饿死。
- 缺点: 仍然是自旋等待。
6. 避免过度自旋:操作系统支持 (Avoiding Excessive Spinning: OS Support)
自旋锁在某些情况(如单CPU高竞争、持有锁的线程被长时间阻塞)下效率低下。
6.1 简单方法:让步 (Yield) (Figure 28.8)
- 原理: 获取锁失败时,调用
yield()主动放弃CPU。
// lock_t结构定义同上,使用TestAndSet
void lock(lock_t *lock) {while (TestAndSet(&lock->flag, 1) == 1)yield(); // 如果锁被占用,则让出CPU
}
笔记:
- 优点: 在单CPU高竞争时,比纯自旋好,可能让持有锁的线程有机会运行。
- 缺点: 频繁
yield导致上下文切换开销大;不解决饿死问题。
6.2 使用队列:休眠代替自旋 (Using Queues: Sleeping Instead Of Spinning) (Figure 28.9)
JAVA的AQS引入了阻塞队列
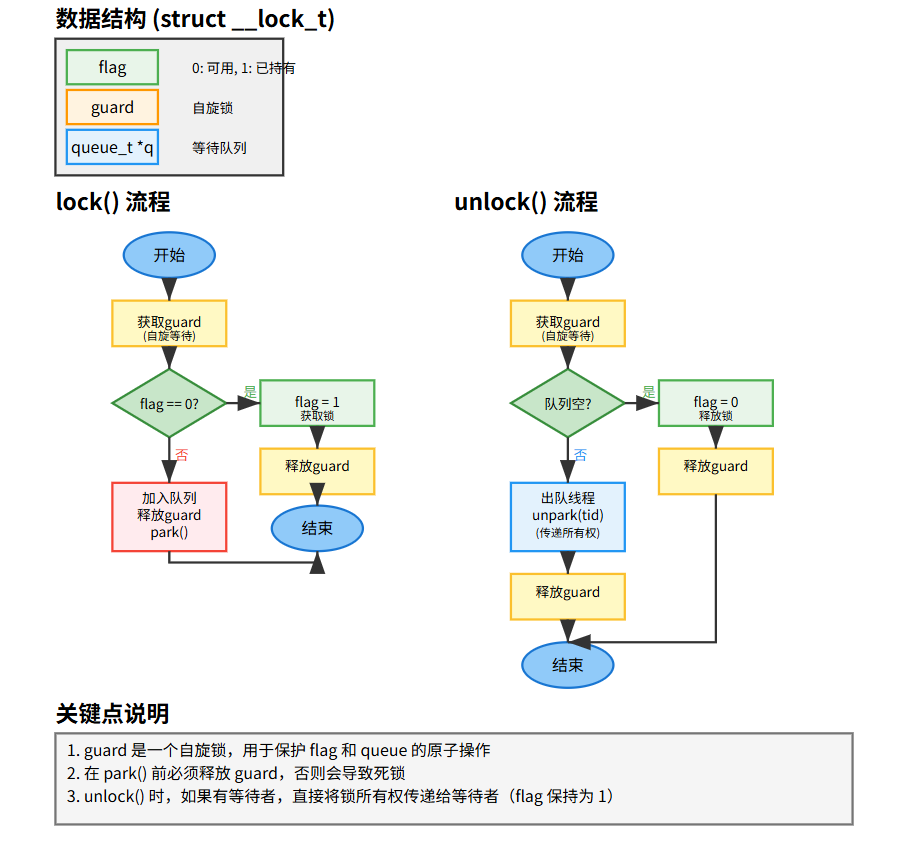
- 引入OS原语如 Solaris 的
park()(使线程休眠) 和unpark(threadID)(唤醒特定线程)。
typedef struct __lock_t {int flag; // 主锁状态 (0:可用, 1:已持有)int guard; // 保护flag和队列的自旋锁queue_t *q; // 等待线程队列
} lock_t;void lock_init(lock_t *m) { /* ... */ }void lock(lock_t *m) {while (TestAndSet(&m->guard, 1) == 1); // 获取guardif (m->flag == 0) { // 锁可用m->flag = 1;m->guard = 0; // 释放guard} else { // 锁被占用queue_add(m->q, gettid());m->guard = 0; // 在park前释放guard!park(); // 休眠}
}void unlock(lock_t *m) {while (TestAndSet(&m->guard, 1) == 1); // 获取guardif (queue_empty(m->q)) {m->flag = 0;} else {int tid = queue_remove(m->q);unpark(tid); // 唤醒等待者 (锁所有权直接传递)}m->guard = 0; // 释放guard
}
笔记:
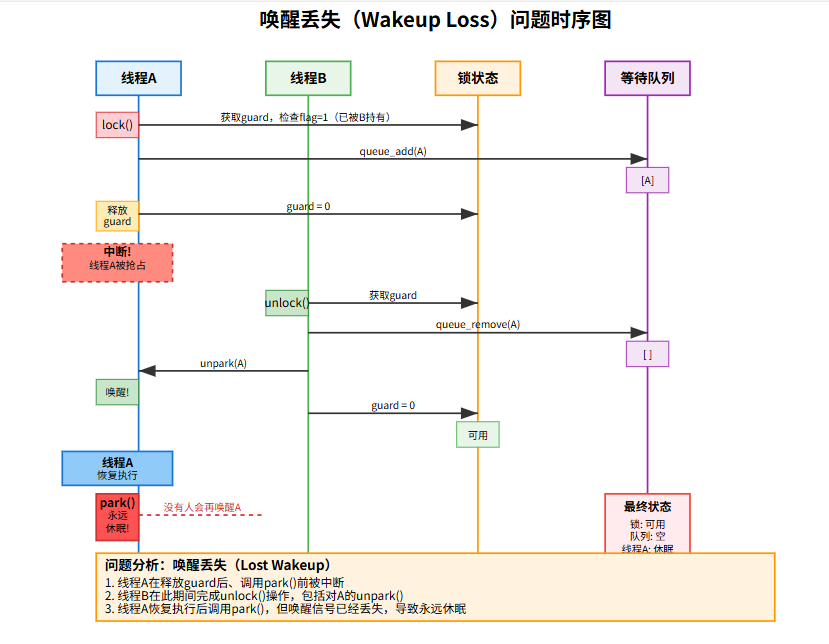
“唤醒丢失”(Lost Wakeup)问题的发生过程:
- 线程A尝试获取锁:发现锁被B持有,将自己加入等待队列
- 关键时刻:线程A释放guard后,在调用park()之前被中断/抢占
- 线程B释放锁:
- 获取guard
- 从队列中移除线程A
- 调用unpark(A)尝试唤醒A
- 释放guard
- 问题发生:线程A恢复执行后才调用park(),但唤醒信号已经在之前发送过了
- 结果:线程A永远休眠,因为没有人会再次唤醒它
这个问题的根源在于:
- park()和unpark()的语义不是对称的
- unpark()只是设置一个标志,如果线程还没有park(),这个标志会被"消费"掉
- 当线程A最终调用park()时,之前的唤醒信号已经丢失
解决方案通常包括:
- 使用条件变量等更高级的同步原语
- 确保park()和unpark()的调用顺序正确
- 在关键路径上使用原子操作或其他保护机制
- 原理: 用
guard自旋锁保护主锁状态flag和等待队列q。获取锁失败则入队休眠;释放锁时若队列不空则唤醒队首线程。 - 优点: 线程等待时不消耗CPU;通过队列可实现公平。
- 缺点: 实现复杂;有上下文切换开销;需要处理唤醒/等待竞争 (wakeup/waiting race)。
- 竞争问题: 线程A在释放
guard后、调用park()前被中断,此时锁被释放且线程A被unpark,之后A再执行park()就可能永远休眠。 - 解决: Solaris的
setpark()或Linuxfutex的机制。
- 竞争问题: 线程A在释放
7. 高级主题与实际考量 (Advanced Topics & Real-World Considerations)
7.1 Linux Futex (Fast Userspace muTEX) (Figure 28.10 概念)
- 原理: 一种混合策略,也是两阶段锁 (Two-Phase Lock) 的一种。
- 快速路径: 在用户空间通过原子操作尝试获取/释放锁。无竞争时非常快,不陷入内核。
- 慢速路径: 当检测到竞争,才陷入内核调用
futex_wait()休眠或futex_wake()唤醒。
// 极简伪代码概念
void mutex_lock(int *mutex_word) {if (atomic_try_acquire(mutex_word)) return; // 快速路径// 慢速路径:atomic_increment_waiters(mutex_word);while (1) {if (atomic_try_acquire(mutex_word)) { /* ... */ return; }futex_wait(mutex_word, EXPECTED_STATE_WHEN_HELD);}
}
void mutex_unlock(int *mutex_word) {atomic_release(mutex_word);if (has_waiters(mutex_word)) {futex_wake(mutex_word, 1);}
}
笔记:
- 优点: 无竞争时开销极低;竞争时休眠。
- 关键: 使用一个整数同时编码锁状态和等待者信息;依赖原子操作和内核
futex调用。
7.2 优先级反转 (Priority Inversion)
高优先级线程等待一个被低优先级线程持有的锁,而该低优先级线程可能因优先级更低而无法运行,导致高优先级线程也无法执行。
8. Peterson算法
8.1 核心思想
- 每个进程都有一个
flag,表示它是否想要进入临界区。 - 有一个共享的
turn变量,表示当前轮到哪个进程进入(如果双方都想进入)。
一个进程要进入临界区,必须满足以下两个条件之一:
- 另一个进程不想进入临界区。
- 或者,另一个进程想进入,但当前轮到自己。
8.2 算法组件(共享变量)
假设有两个进程P0和P1。
-
volatile boolean flag[2];flag[0]:如果P0想进入临界区,则为true;否则为false。flag[1]:如果P1想进入临界区,则为true;否则为false。- 初始化为
{false, false}。 volatile关键字提示编译器不要对这些变量的读写进行过度优化(例如缓存到寄存器中),因为它们可能被其他进程并发修改。但在现代多核处理器中,volatile不足以保证内存可见性和顺序性,需要内存屏障。
-
volatile int turn;- 表示如果两个进程都想进入临界区,轮到哪个进程。
- 如果
turn == 0,轮到P0;如果turn == 1,轮到P1。 - 初始化可以是0或1。
8.3 算法流程(以进程P_i为例,另一个进程为P_j)
进程P_i (其中 i 是0或1, j = 1 - i):
// 共享变量 (在进程/线程间共享)
volatile boolean flag[2] = {false, false};
volatile int turn; // 可以初始化为 0 或 1// 进程 P_i 的代码
// i = 0 或 1
// j = 1 - i (代表另一个进程的索引)// Entry Protocol (进入临界区前的代码)
flag[i] = true; // 1. 表达意愿:我想进入临界区
turn = j; // 2. 谦让:把机会让给另一个进程 j// 3. 检查条件并等待:
// - 如果进程 j 也想进入 (flag[j] == true)
// - 并且 当前确实轮到进程 j (turn == j)
// 那么,进程 i 就在这里自旋等待。
while (flag[j] && turn == j) {// busy wait (自旋等待)
}// ---- 临界区 (Critical Section) ----
// ... 执行需要互斥访问的代码 ...
// ---- 临界区结束 ----// Exit Protocol (离开临界区后的代码)
flag[i] = false; // 4. 取消意愿:我不再想进入临界区 (或已离开)// 这会允许另一个等待的进程进入// ---- 剩余区 (Remainder Section) ----
代码解释:
flag[i] = true;: 进程i设置自己的标志,表明它有兴趣进入临界区。turn = j;: 这是算法的关键一步。即使进程i想进入,它也"礼貌地"将turn设置为另一个进程j的。这表示:“如果你(进程j)也想进入,那么你先请。”while (flag[j] && turn == j): 这是等待条件。进程i会一直等待,只要满足以下两个条件:- 另一个进程
j也想进入 (flag[j] == true)。 - 并且,当前确实是进程
j的回合 (turn == j)。 - 如果
flag[j]为false(进程j不想进入),进程i可以直接进入。 - 如果
flag[j]为true但turn == i(轮到进程i了,因为进程j之前可能把turn设成了i),进程i也可以进入。
- 另一个进程
flag[i] = false;: 当进程i离开临界区后,它将自己的flag设为false,表明它不再占用临界区,其他进程可以尝试进入了。
8.4 为什么Peterson算法能工作?(满足互斥的三个条件)
-
互斥 (Mutual Exclusion): 不可能有两个进程同时在临界区。
- 假设P0和P1都想进入。它们都设置自己的
flag为true。 turn变量最终会被设置为0或1(取决于哪个进程最后执行turn = j;)。- 假设
turn最后被设置为0(P1执行了turn = 0;)。- P1的等待条件是
flag[0] && turn == 0。因为flag[0]是true,turn == 0也是true,所以P1会等待。 - P0的等待条件是
flag[1] && turn == 1。因为turn是0,所以turn == 1是false。因此P0的等待条件不满足,P0会进入临界区。
- P1的等待条件是
- 对称地,如果
turn最后被设置为1,则P1进入,P0等待。 - 因此,只有一个进程能通过
while循环。
- 假设P0和P1都想进入。它们都设置自己的
-
前进 (Progress / No Deadlock): 如果没有进程在临界区中,并且有进程想要进入临界区,那么这些想进入的进程中必须有一个能够最终进入。
- 如果P0想进入,P1不想进入 (
flag[1] == false)。P0设置flag[0] = true,turn = 1。P0的等待条件flag[1] && turn == 1因为flag[1]为false而不成立,P0进入。 - 如果两个进程都想进入,如上所述,
turn变量会确保其中一个进程最终会进入。
- 如果P0想进入,P1不想进入 (
-
有限等待 (Bounded Waiting / No Starvation): 一个请求进入临界区的进程不能无限期地等待。
- 当一个进程P_i想进入临界区时,它设置
flag[i] = true。它最多只会等待另一个进程P_j完成一次临界区操作。 - 因为一旦P_j退出临界区,它会设置
flag[j] = false,这将使P_i的while循环条件(flag[j] && turn == j)中的flag[j]为false,从而允许P_i进入。 - 即使P_j立即又想进入临界区,它会执行
turn = i,把优先权交给了P_i。
- 当一个进程P_i想进入临界区时,它设置
8.5 优点
- 纯软件方案:不需要特殊的硬件原子指令(如Test-and-Set, Compare-and-Swap),只需要原子性的读写共享变量。
- 简单优雅:对于两个进程的情况,逻辑相对清晰。
- 保证了互斥、前进和有限等待。
8.6 缺点和局限性
- 仅适用于两个进程/线程:这是其最大的局限性。不能直接推广到N个进程。对于N个进程,需要更复杂的算法,如Lamport面包店算法。
- 忙等待 (Busy Waiting):当进程在
while循环中等待时,它会持续消耗CPU周期,效率低下。 - 现代多核处理器上的问题 (Memory Model Issues):
- Peterson算法依赖于对共享变量
flag和turn的写操作对其他处理器立即可见,并且操作的顺序得到保证(例如,flag[i] = true;必须在turn = j;之前对其他处理器可见,并且while循环中的读操作能读到最新的值)。 - 现代CPU为了性能会进行指令重排和使用缓存,这可能导致一个CPU上的写操作不能立即被另一个CPU看到,或者执行顺序与代码顺序不一致。
volatile关键字在C/C++中主要用于防止编译器优化,不足以解决多核处理器上的内存可见性和指令重排问题。- 要在现代多核系统上正确实现Peterson算法(或其他类似的软件同步算法),需要使用内存屏障 (Memory Barriers/Fences) 指令来强制内存操作的顺序和可见性。这使得它不再是"纯"软件方案,并且增加了复杂性。
- 由于这些原因,在实际系统中,通常会使用基于硬件原子指令(如互斥锁
mutex的实现)或操作系统提供的同步原语,而不是直接使用Peterson算法。
- Peterson算法依赖于对共享变量
9. 锁改进机制的演进流程
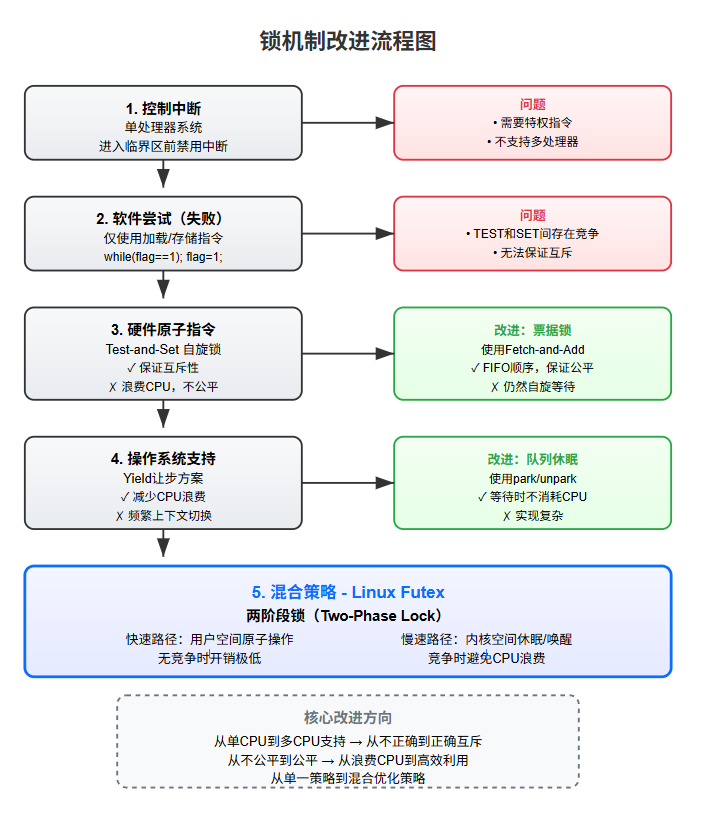
9.1 最原始尝试 - 控制中断
- 原理:在单处理器系统中,进入临界区前禁用中断,退出后启用中断
- 问题:需要特权指令、不适用于多处理器、长时间禁用中断会导致系统响应问题
9.2 简单软件尝试 - 仅使用加载/存储指令(失败)
void lock(lock_t *mutex) {while (mutex->flag == 1) ; // TESTmutex->flag = 1; // SET
}
- 问题:TEST和SET之间存在竞争条件,无法保证互斥性
9.3 硬件原子指令支持 - 自旋锁(第一次重大改进)
Test-and-Set 自旋锁
void lock(lock_t *lock) {while (TestAndSet(&lock->flag, 1) == 1); // 自旋等待
}
- 优点:通过原子操作保证了互斥性
- 缺点:持续占用CPU、不保证公平性
票据锁(改进公平性)
void lock(lock_t *lock) {int myturn = FetchAndAdd(&lock->ticket);while (lock->turn != myturn); // 自旋等待
}
- 优点:FIFO顺序,保证公平性,避免饿死
- 缺点:仍然是自旋等待,浪费CPU
9.4 操作系统支持 - 避免过度自旋(第二次重大改进)
简单让步(Yield)
void lock(lock_t *lock) {while (TestAndSet(&lock->flag, 1) == 1)yield(); // 主动放弃CPU
}
- 优点:在单CPU高竞争时比纯自旋好
- 缺点:频繁上下文切换开销大,不解决饿死问题
使用队列:休眠代替自旋
void lock(lock_t *m) {while (TestAndSet(&m->guard, 1) == 1);if (m->flag == 0) {m->flag = 1;m->guard = 0;} else {queue_add(m->q, gettid());m->guard = 0;park(); // 休眠}
}
- 优点:线程等待时不消耗CPU,通过队列实现公平
- 缺点:实现复杂,需要处理唤醒/等待竞争
9.5 混合策略 - Linux Futex(最优化方案)
- 两阶段锁策略:
- 快速路径:在用户空间通过原子操作尝试获取锁(无竞争时开销极低)
- 慢速路径:检测到竞争时,才陷入内核进行休眠/唤醒
void mutex_lock(int *mutex_word) {if (atomic_try_acquire(mutex_word)) return; // 快速路径// 慢速路径:陷入内核futex_wait(mutex_word, EXPECTED_STATE_WHEN_HELD);
}
9.6 总结改进流程
1. 控制中断 → 软件尝试 → 硬件原子指令 → OS支持 → 混合策略
-
每次改进都在解决前一版本的问题:
- 从单CPU到多CPU支持
- 从无法保证互斥到实现正确互斥
- 从不公平到公平(FIFO)
- 从浪费CPU到高效利用CPU
- 从单一策略到混合优化策略
-
最终的Futex实现结合了:
- 用户空间快速路径(无竞争时性能最优)
- 内核空间慢速路径(竞争时避免CPU浪费)
- 原子操作保证正确性
- 队列机制保证公平性
针对常见情况(无竞争)优化,同时正确处理特殊情况(高竞争)。
10. 简要总结
-
基本问题与锁的概念 (The Basic Idea)
- 并发编程的核心问题之一是如何原子地 (atomically) 执行一系列指令(即临界区,critical section),防止因中断或多线程/多处理器并发执行导致的竞争条件。
- 锁是一种机制,程序员用它来“标记”临界区,确保任何时候只有一个线程能进入该临界区执行,如同这段代码是一个不可分割的原子指令。
- 一个锁变量自身有状态:可用 (available/unlocked/free) 或 已被获取 (acquired/locked/held)。
-
锁的API与Pthreads (Lock API and Pthreads)
- 基本操作是
lock()(尝试获取锁,若锁被占用则等待) 和unlock()(释放锁,可能唤醒等待者)。 - POSIX 线程库 (Pthreads) 中对应的锁是 互斥量 (mutex),如
pthread_mutex_t,通过pthread_mutex_lock()和pthread_mutex_unlock()操作。 - 提到了粗粒度锁 (coarse-grained locking) 和 细粒度锁 (fine-grained locking) 的概念,后者通过使用多个锁保护不同数据以提高并发性。
- 基本操作是
-
构建锁的挑战与评估标准 (Building A Lock & Evaluating Locks)
- 构建一个高效且正确的锁需要硬件和操作系统的支持。
- 评估锁的三个主要标准:
- 互斥性 (Mutual Exclusion):是否能正确阻止多个线程同时进入临界区。
- 公平性 (Fairness):等待锁的线程是否都有机会获取锁,是否存在饿死 (starvation) 现象。
- 性能 (Performance):锁操作带来的开销,包括无竞争情况下的开销和高竞争情况下的开销(单CPU和多CPU场景)。
-
早期/简单的锁实现尝试及其问题 (Early/Simple Attempts)
- 控制中断 (Controlling Interrupts):
- 单处理器系统上的早期方法,通过在临界区前后开关中断实现原子性。
- 缺点:需要特权指令,滥用会导致系统问题;不适用于多处理器;长时间关中断会导致中断丢失。
- 仅使用加载/存储指令 (Just Using Loads/Stores - A Failed Attempt):
- 尝试用一个简单标志位 (flag) 来实现锁。
- 问题:
TEST标志位和SET标志位这两个操作之间可能发生中断或并发,导致多个线程同时进入临界区,无法保证互斥。 - 这种等待方式引入了自旋等待 (spin-waiting) 的概念。
- 控制中断 (Controlling Interrupts):
-
基于硬件原子指令的自旋锁 (Hardware Primitives & Spin Locks)
- 现代CPU提供了特殊的原子指令来构建锁:
- 测试并设置 (Test-and-Set / Atomic Exchange):原子地读取旧值并写入新值。
- 比较并交换 (Compare-and-Swap - CAS):原子地比较内存值与期望值,若相等则写入新值。
- 加载链接/条件存储 (Load-Linked / Store-Conditional - LL/SC):
LL加载一个值,SC只有在该值未被改变时才存储成功。 - 读取并加 (Fetch-and-Add):原子地读取一个值并将其增加。
- 使用这些原子指令可以构建自旋锁 (Spin Locks)。线程在获取锁失败时会循环检查锁状态。
- 评估自旋锁:
- 互斥性:正确。
- 公平性:基本自旋锁不保证公平,可能导致饿死。票据锁 (Ticket Lock) (使用 Fetch-and-Add) 可以实现公平性,按到达顺序获取锁。
- 性能:在单CPU上,如果持有锁的线程被抢占,其他线程自旋会浪费大量CPU时间。在多CPU上,如果临界区很短,自旋锁开销小,效率尚可。
- 现代CPU提供了特殊的原子指令来构建锁:
-
避免过度自旋:操作系统支持 (Avoiding Excessive Spinning: OS Support)
- 问题:自旋锁在某些情况下(如单CPU高竞争、持有锁的线程被长时间阻塞)效率低下。
- 简单方法:让步 (Yield):线程获取锁失败时调用
yield()主动放弃CPU。- 比纯自旋好,但若等待线程很多,仍有大量上下文切换开销,且不解决饿死问题。
- 使用队列:休眠代替自旋 (Using Queues: Sleeping Instead Of Spinning):
- 引入操作系统原语如 Solaris 的
park()(使线程休眠) 和unpark(threadID)(唤醒特定线程),或 Linux 的futex。 - 当线程获取锁失败时,将其加入等待队列并休眠。当锁被释放时,从队列中唤醒一个线程。
- 这种方法需要一个额外的保护锁 (guard lock) (通常是自旋锁) 来保护队列和锁状态本身的操作。
- 需要处理唤醒/等待竞争 (wakeup/waiting race) 问题,例如 Solaris 的
setpark()可以在park()前声明意图。
- 引入操作系统原语如 Solaris 的
-
高级主题与实际考量 (Advanced Topics & Real-World Considerations)
- 优先级反转 (Priority Inversion):高优先级线程等待一个被低优先级线程持有的锁(该低优先级线程可能无法运行),导致高优先级线程无法执行。
- 两阶段锁 (Two-Phase Locks):一种混合策略。第一阶段尝试自旋一小段时间,如果获取不到锁,则进入第二阶段,将线程休眠。Linux Futex锁实现有此特性。
参考:
ostep 28章