【NCCL】DBT算法(double binary tree,双二叉树)
目录
前言
ring 不足,需要 tree
朴素二叉tree只利用了一半带宽,需要 双二叉 tree
双二叉树的构造
ringvs 双二叉树 测试
ring和tree的选择
nccl tree
tree搜索
基本概念解释
最大化局部性构建二叉树的方式
这种构建方式的好处
示例说明
前言
参考:万卡集群通信优化算法双二叉树:https://www.bilibili.com/video/BV1zSpnezEB8
3.1 NCCL源码二叉树构建算法:https://www.bilibili.com/video/BV1DErsYwEhc/
Massively Scale Your Deep Learning Training with NCCL 2.4 | NVIDIA Technical Blog
"double binary tree" 在并行计算/NCCL语境中特指一种用于高效集合通信的树形拓扑结构,由两个并行的二叉树组成。
从 ring 算法到 tree 算法,把时间复杂度从 n 提升到了 logn
ring-->tree-->db tree
ring 不足,需要 tree
ring算法 适合小规模集群,能够充分利用上行和下行的带宽。但是环越大,延迟线性增加,不适合大规模集群。

为了解决这个问题,线引入二维环算法,但仍然无法完全解决该问题,最后由引入了Tree算法

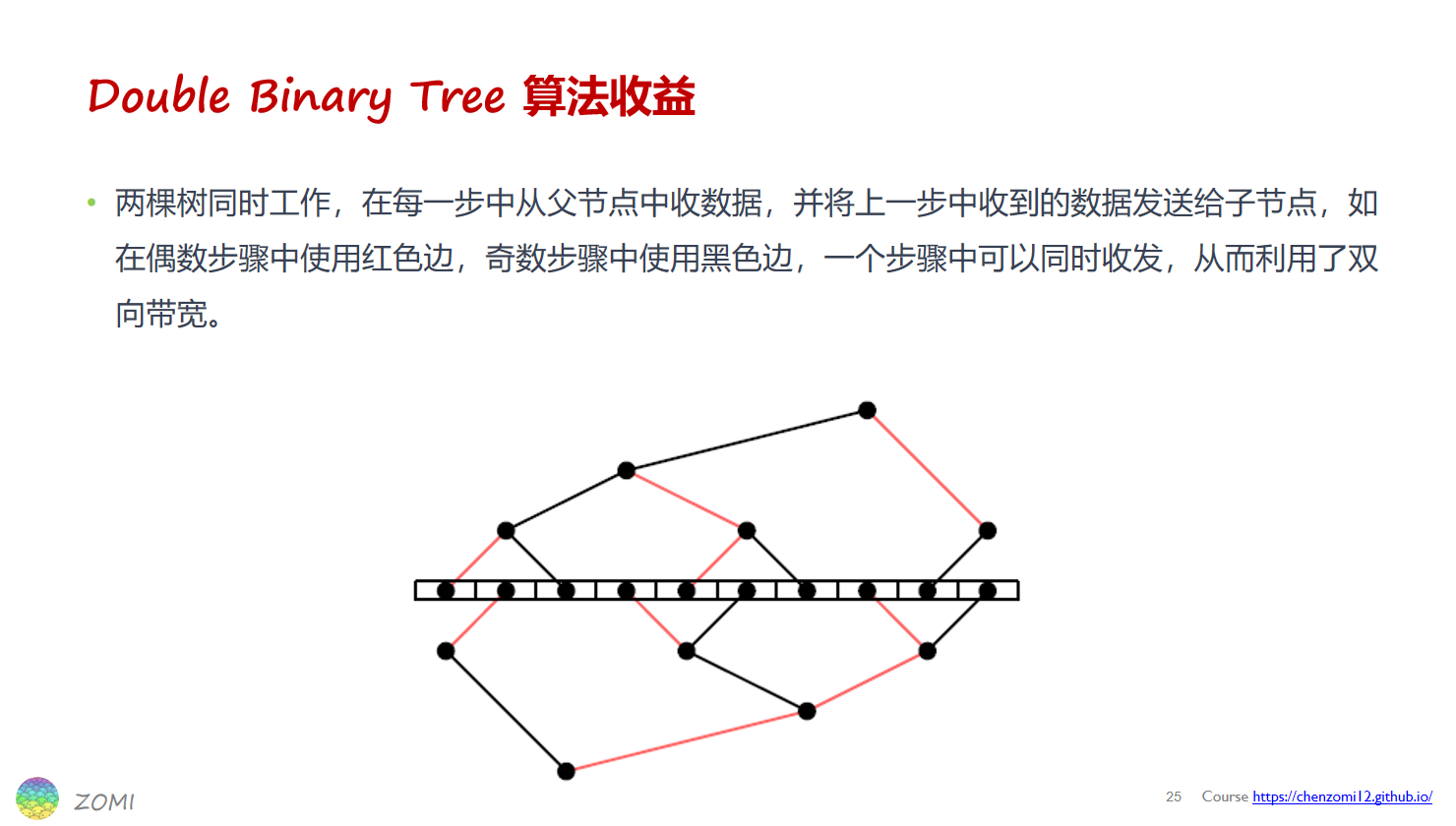
朴素二叉tree只利用了一半带宽,需要 双二叉 tree
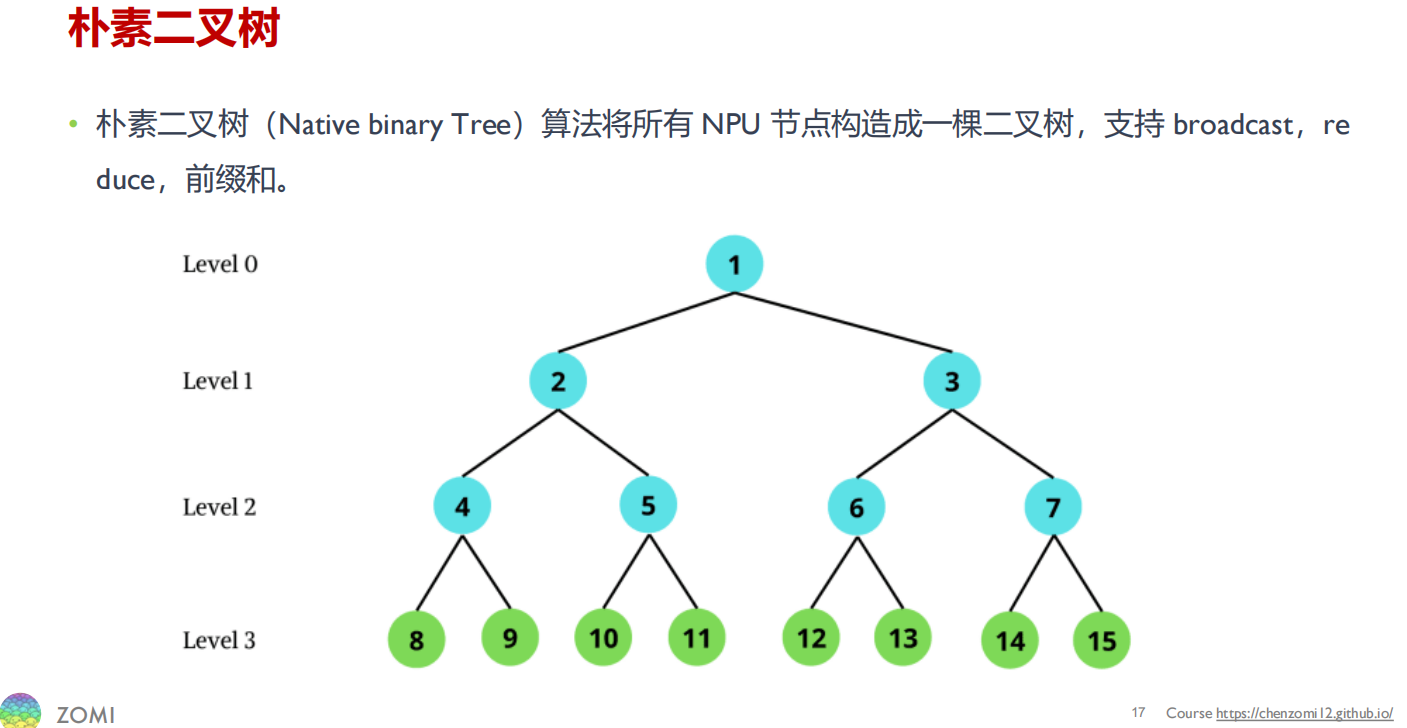
朴素二叉树(native binary tree)
缺点:叶子节点只接收不发送数据,只利用了带宽的一半,浪费了大量的(叶子节点的)带宽。
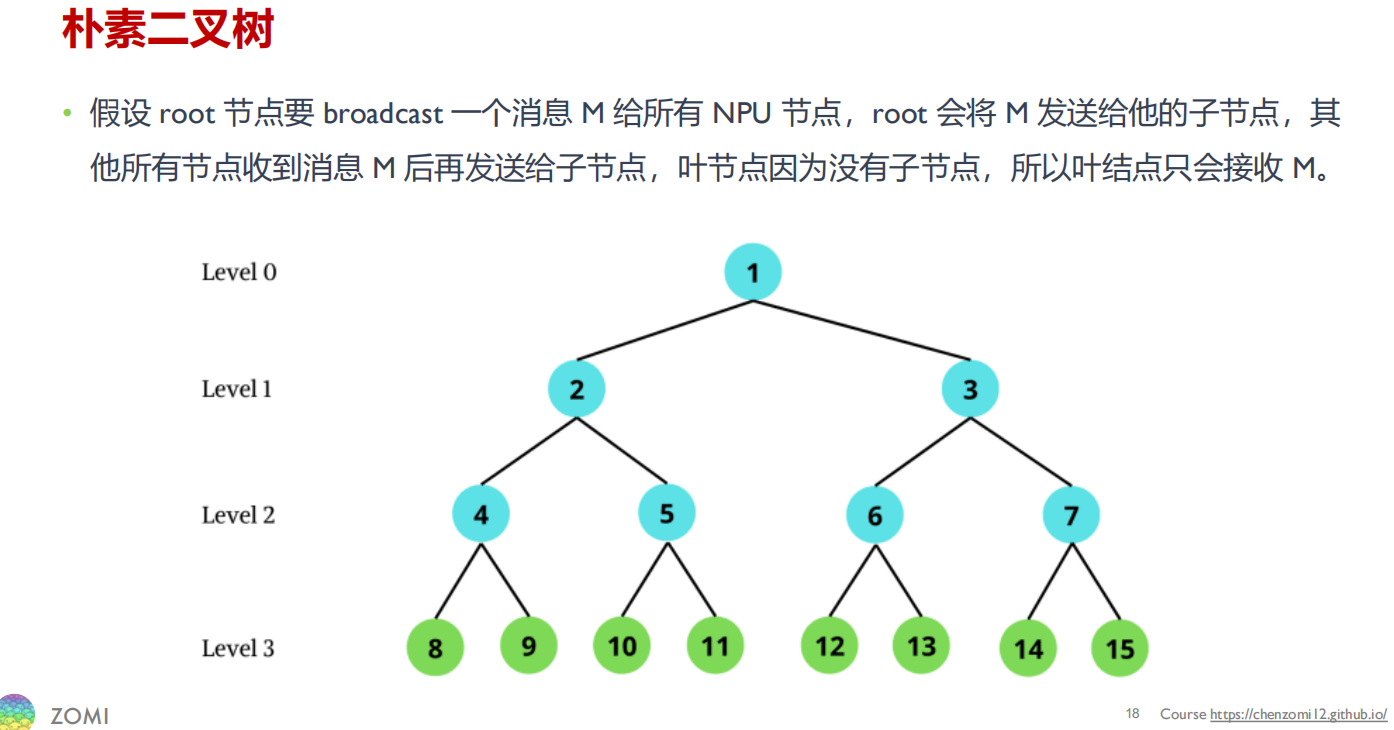
假设root节点要broadcast一个消息M给所有节点,root会将M发送给他的子节点,其他所有的节点收到消息M后再发送给子节点,叶节点因为没有子节点,所以叶结点只会接收M。这个过程可以将M切分为k个block,从而可以流水线起来。
双二叉树(Double Binary Tree)
为了解决朴素二叉树只利用了带宽的一半的缺点,引入双二叉树,算法介绍:
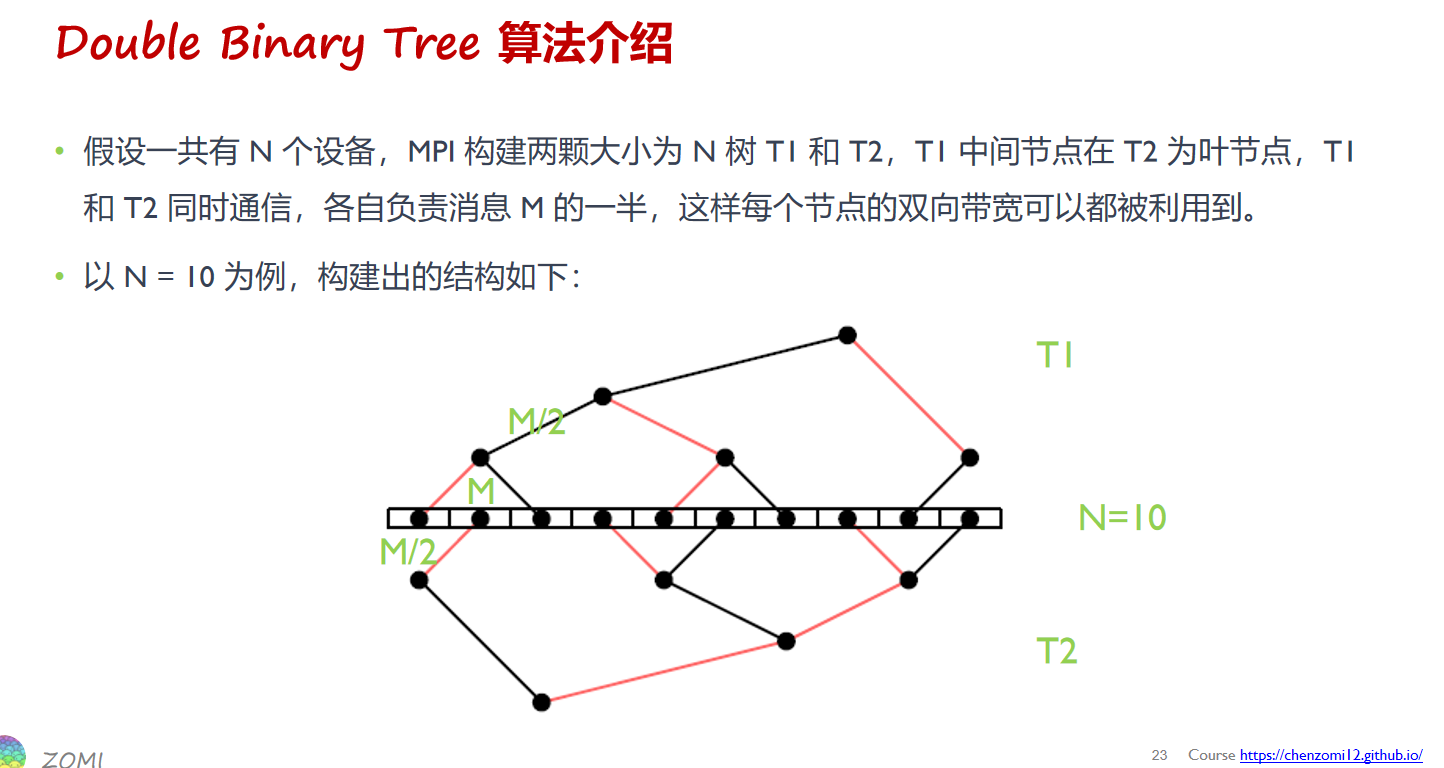
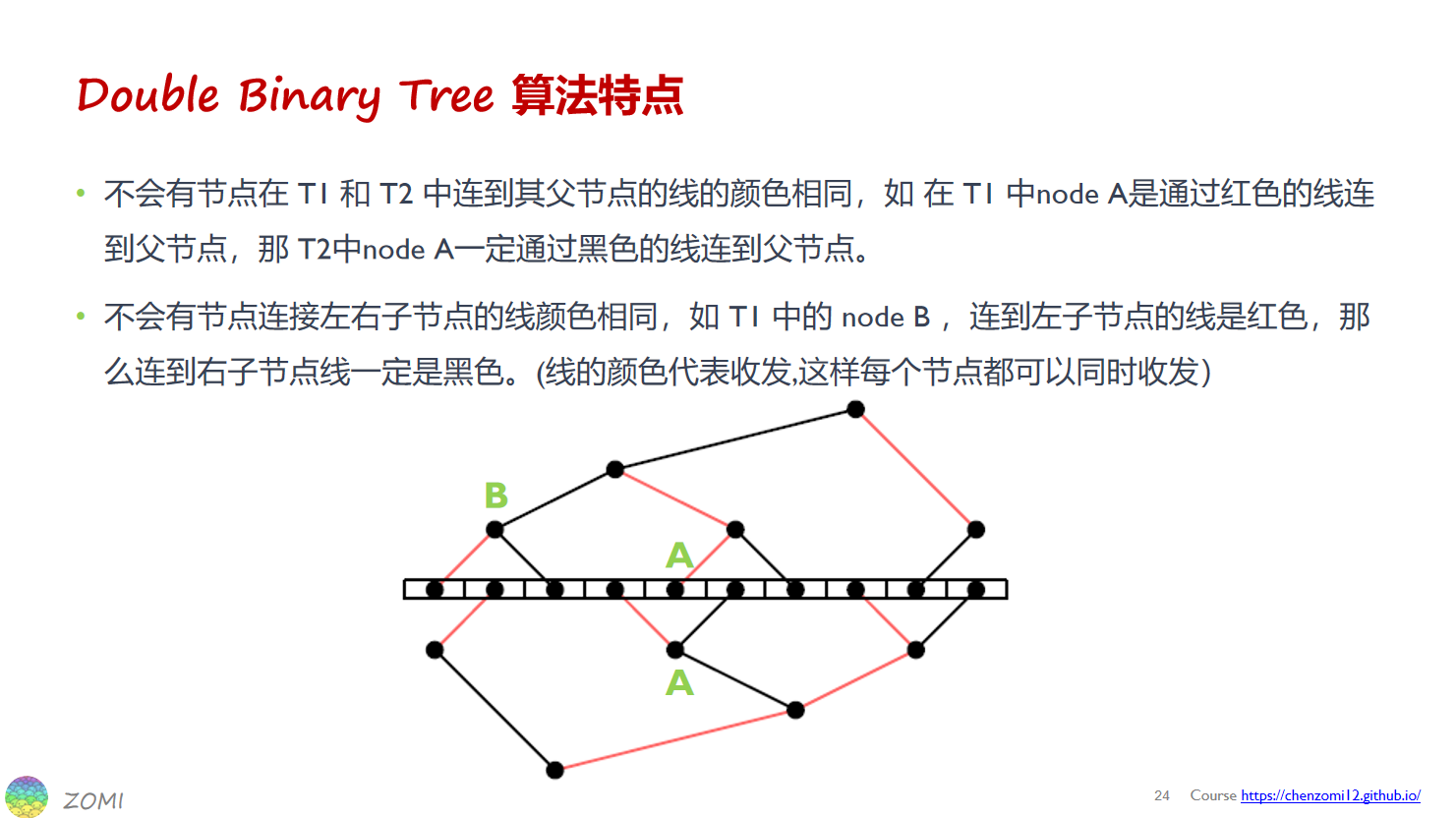
双二叉树的构造
双二叉树的构造
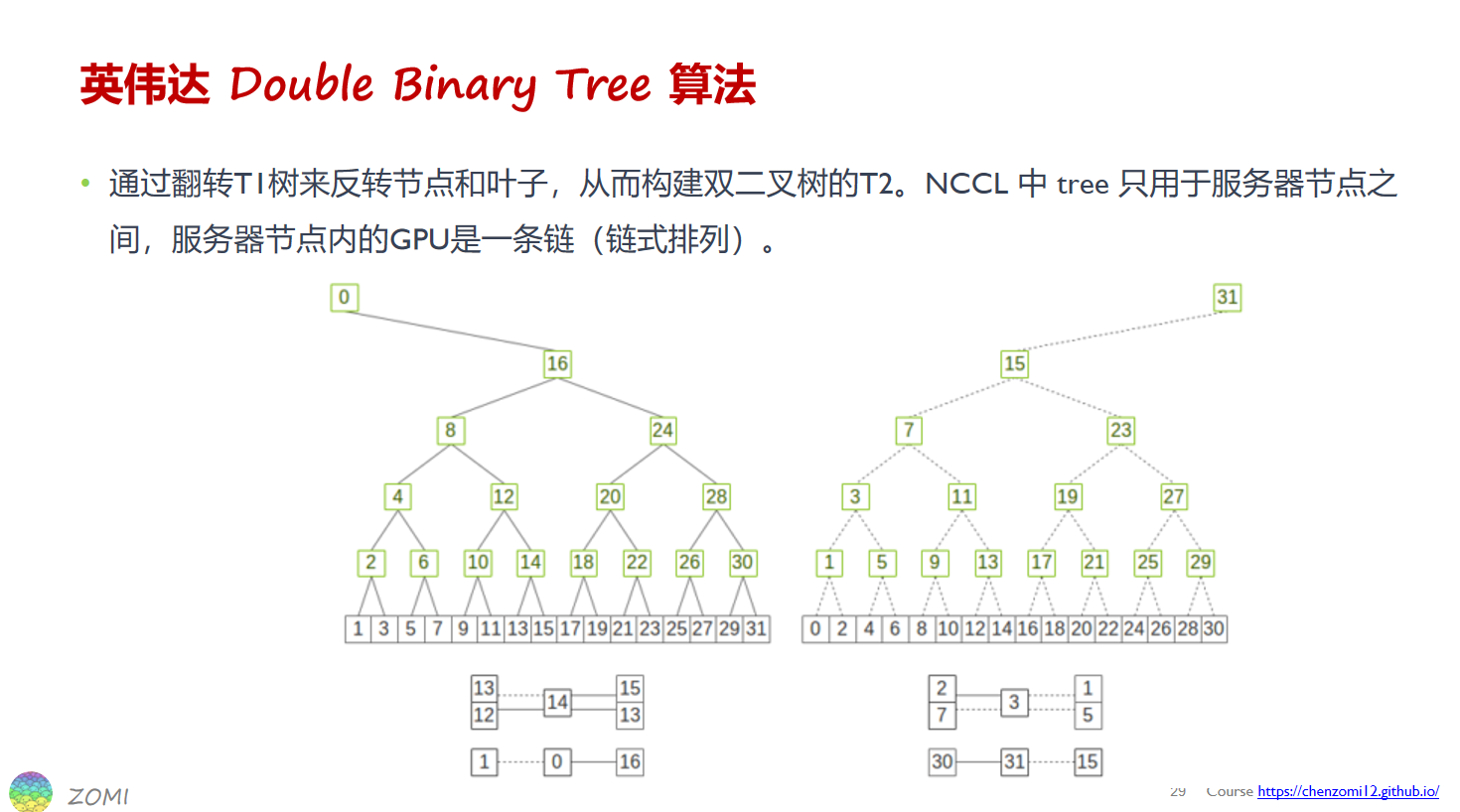
构造双二叉树有两种方法:shift位移法和mirror(镜像)法,
shift位移法:也就是先按正常序号构造T1,然后将每个节点的序号移一位,然后构造第T2。
mirror(镜像)法:既先按正常序号构造T1,然后将全部节点序号反转,然后构造第T2。
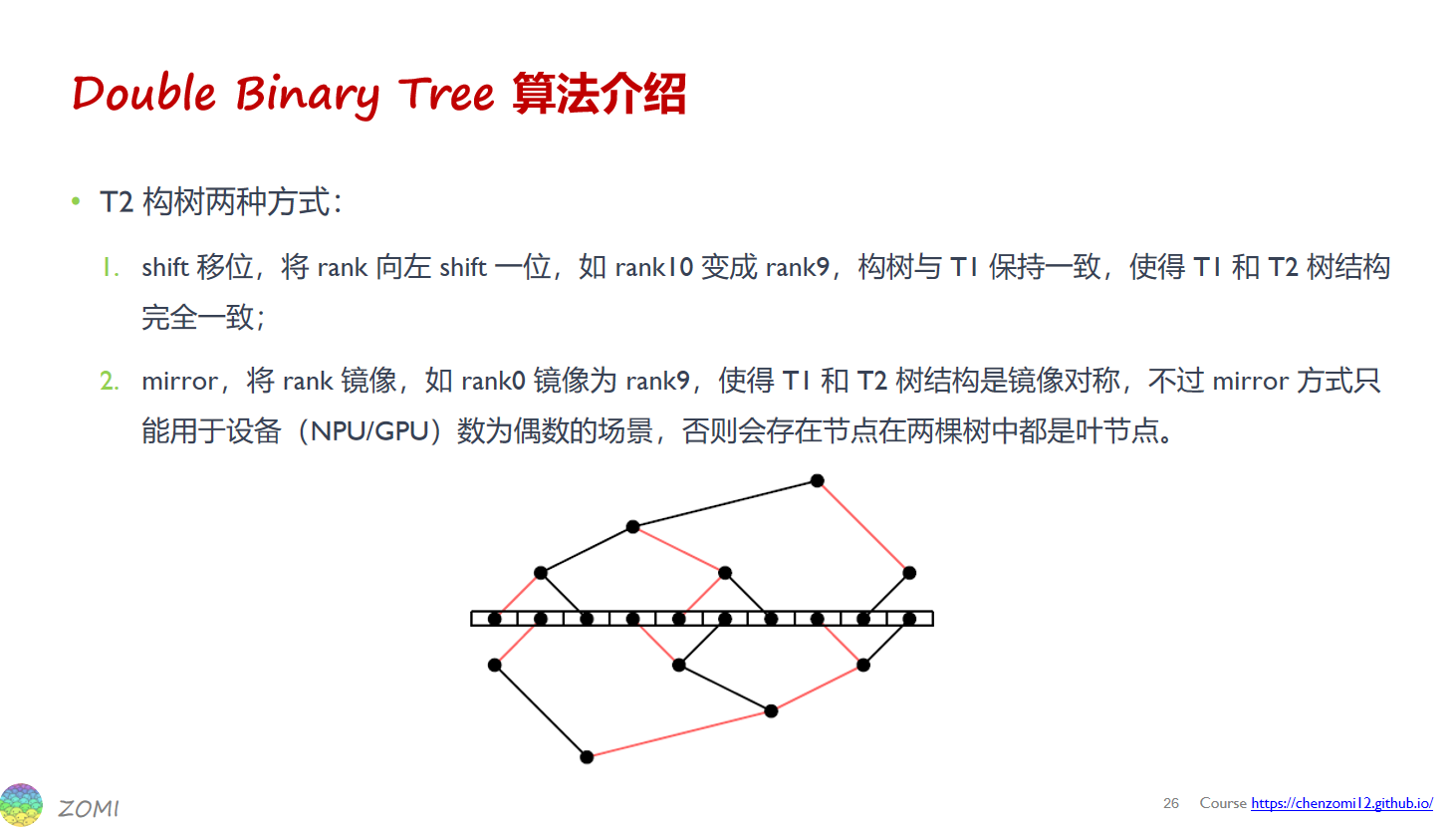
英伟达的双二叉树算法
NCCL 中,使用最大化局部性(见附录说明)的模式来构建二叉树,
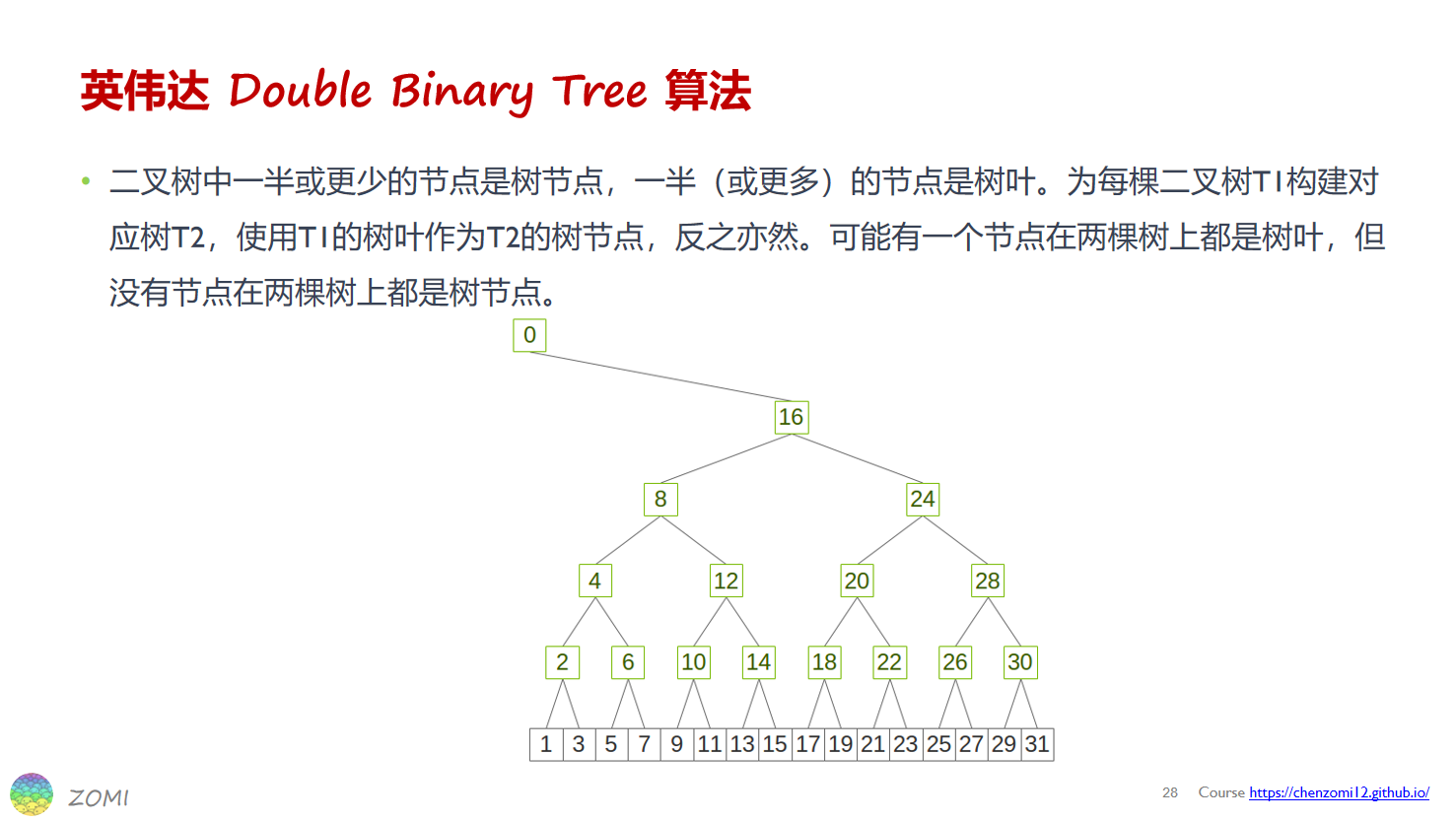
英伟达通过反转T1树的方式构建双二叉树的T2:

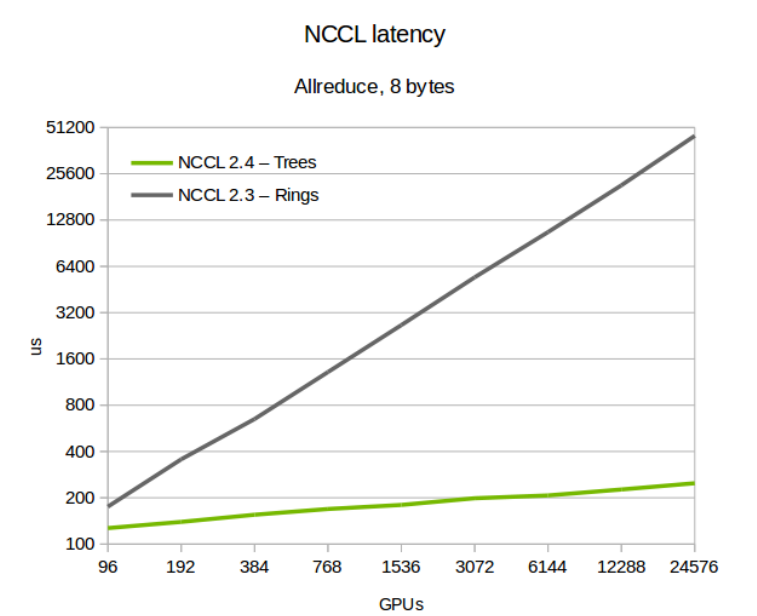
ringvs 双二叉树 测试
相比ring,双二叉树的优化效果测试:
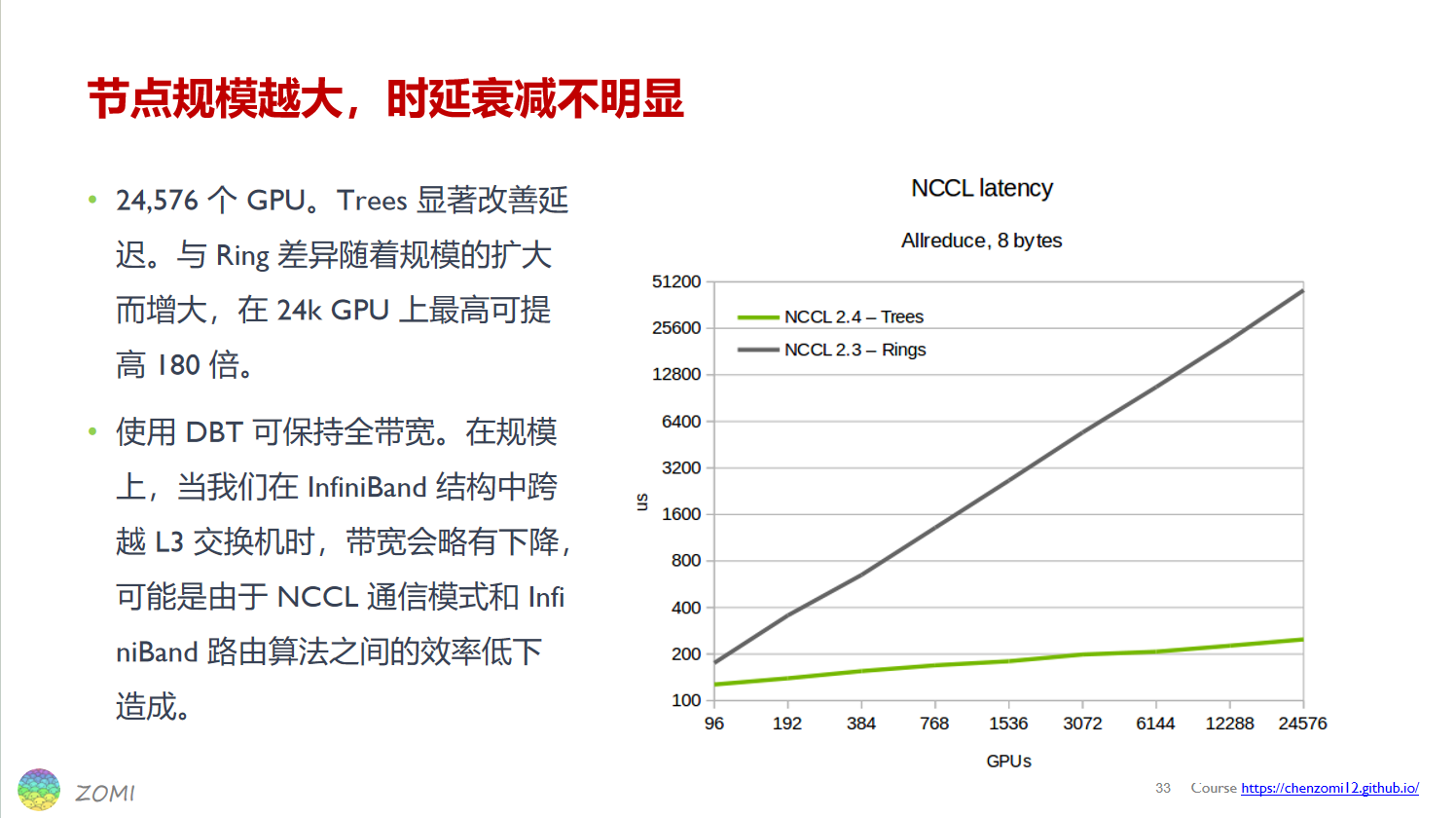
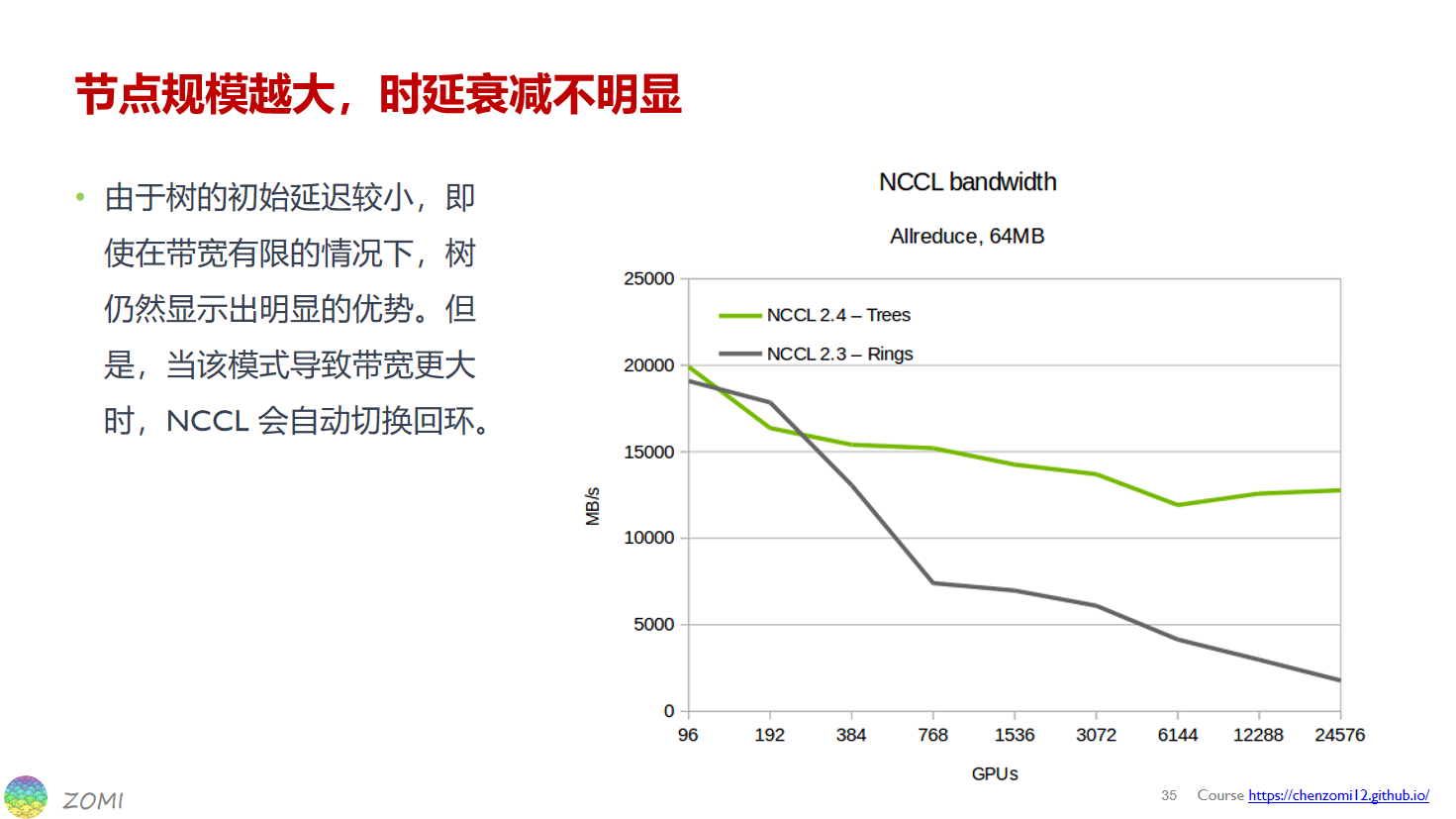
ring和tree的选择

NVIDIA NCCL 源码学习(十二)- double binary tree-CSDN博客
nccl tree
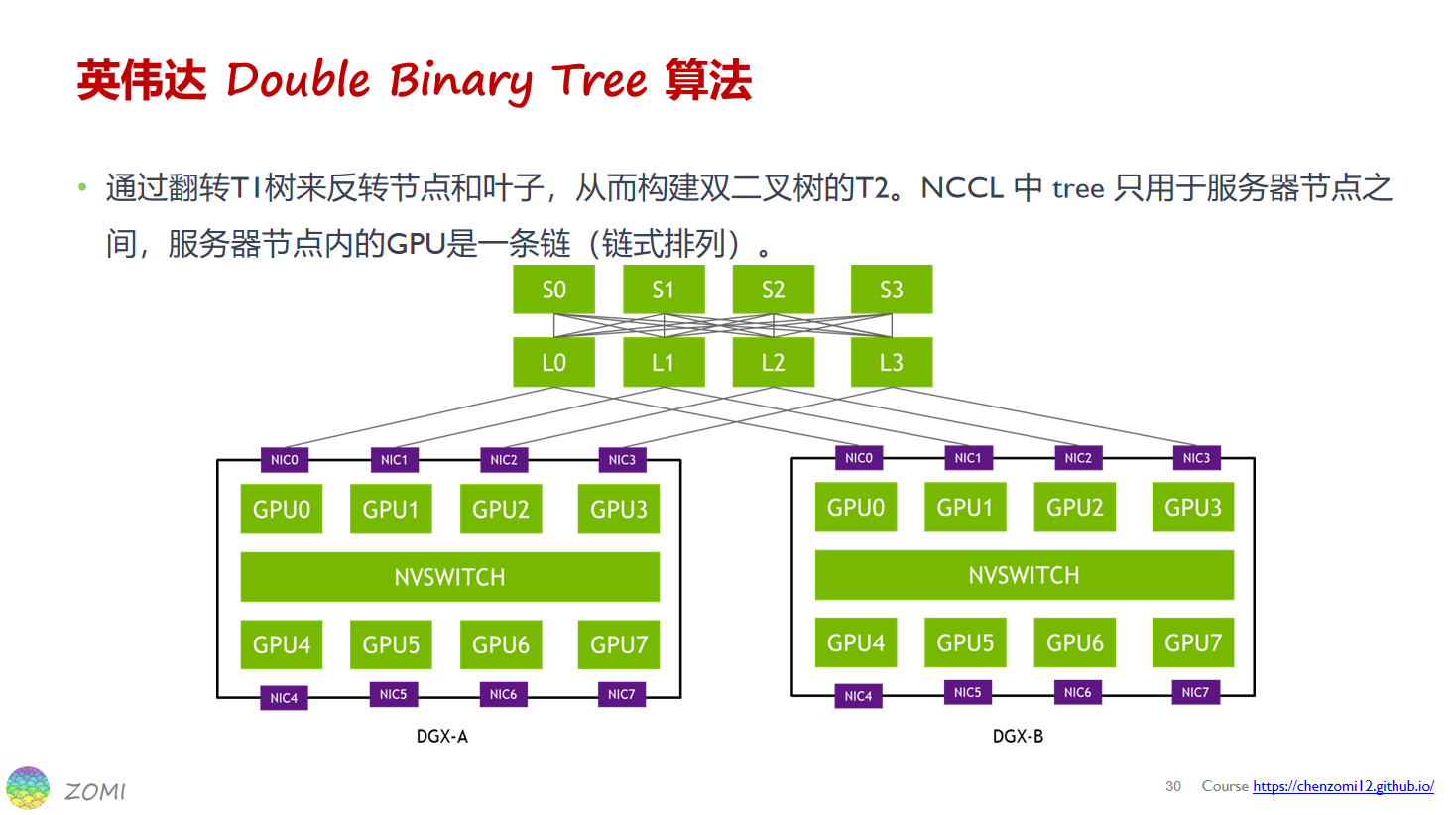
nccl中的tree只用于节点之间,节点内是一条链,2.7.8版本使用的pattern为NCCL_TOPO_PATTERN_SPLIT_TREE,假设为4机32卡,对于T2后边再介绍,T1如下所示:
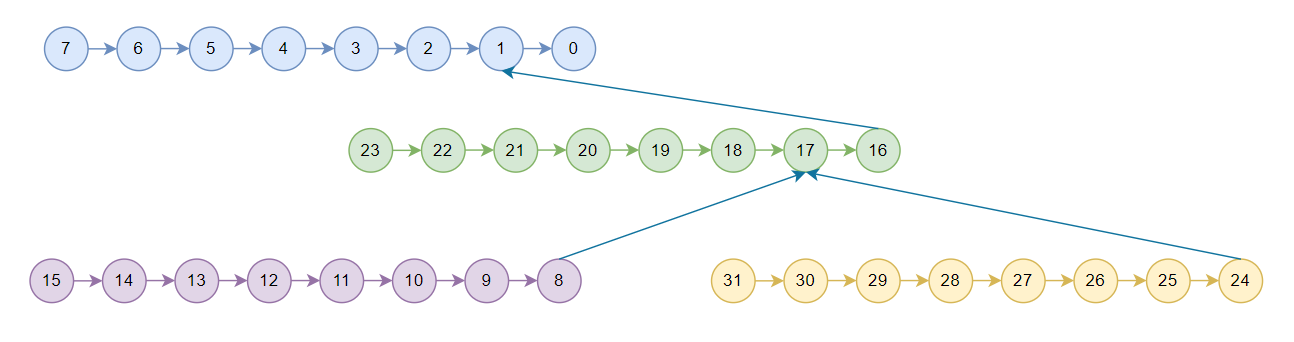
由于allreduce可以拆分为reduce和broadcast两个过程,所以nccl tree allreduce先执行reduce,数据按照图中箭头方向流动,称为上行阶段,从rank15,rank31,rank23,rank7开始一直reduce到rank 0,rank0拿到全局reduce的结果之后再按照箭头反方向开始流动,称为下行阶段,broadcast到所有卡。
tree搜索
如上所述,节点内为链,因此机内tree搜索的过程和ring搜索很像,指定pattern为NCCL_TOPO_PATTERN_SPLIT_TREE,然后执行ncclTopoCompute。
相关代码
构建二叉树
构建代码主要在src/graph/trees.cc和src/collectives/device/all_reduce.h文件中
trees.cc中的二叉树构建核心实现:
核心函数是ncclGetBtree和ncclGetDtree
构建过程:
基于rank的二进制位模式构建树结构
对奇数/偶数rank数采用不同策略
支持镜像树和偏移树构建
调用流程:
集合操作(如AllReduce)初始化时调用ncclGetDtree构建双二叉树
在设备端kernel中通过runTreeUpDown等函数使用构建好的树结构
树结构信息存储在ncclShmem.channel.tree中
AllReduce初始化
→ ncclGetDtree()
→ ncclGetBtree() ×2 (构建两个树)
→ 将树结构存储到channel信息中
设备端执行
→ runTreeUpDown()/runTreeSplit()
→ 使用预构建的树结构进行通信
📎07DBTree.pptx
附录:
基本概念解释
- 局部性:在计算机系统中,局部性原理是指程序和数据倾向于集中访问某些区域。在多 GPU 系统中,局部性通常指 GPU 之间的物理接近性或者通信延迟的接近性。例如,同一服务器内的 GPU 之间的通信延迟往往比不同服务器之间的 GPU 通信延迟要小,这种物理和延迟上的接近性就是局部性的体现。
最大化局部性构建二叉树的方式
- 物理位置优先:优先考虑将物理位置接近的 GPU 连接在一起。例如,在一个包含多个服务器的集群中,每个服务器上有多个 GPU,构建二叉树时会先把同一服务器内的 GPU 相互连接,形成子树,然后再将这些子树连接起来。这样可以减少跨服务器的数据传输,因为跨服务器的通信通常伴随着更高的延迟和更低的带宽。
- 通信延迟最小化:除了物理位置,还会考虑 GPU 之间的实际通信延迟。通过测量不同 GPU 对之间的通信延迟,将延迟较小的 GPU 优先连接在一起。例如,某些 GPU 可能通过高速的 NVLink 互连,而有些则通过 PCIe 总线连接,NCCL 会尽量利用 NVLink 这种低延迟、高带宽的连接来构建二叉树。
这种构建方式的好处
- 减少通信开销:通过最大化局部性,大部分的数据传输可以在低延迟、高带宽的通道上进行,从而减少了通信延迟和数据传输时间。例如,在 All - Reduce 操作中,数据可以在局部子树内先进行规约,然后再将结果向上传递,避免了大量数据在高延迟的通道上传输。
- 提高并行性:局部性好的二叉树结构可以让更多的 GPU 同时进行数据传输和计算,提高了整个系统的并行性。例如,同一子树内的 GPU 可以并行地进行数据交换,而不会相互干扰。
示例说明
假设一个系统中有 8 个 GPU,分布在 2 个服务器上,每个服务器有 4 个 GPU。使用最大化局部性的模式构建二叉树时,会先在每个服务器内部构建一个包含 4 个 GPU 的子树,然后再将这两个子树连接起来。这样在进行集体通信操作时,每个服务器内的 4 个 GPU 可以先在本地完成部分数据处理,然后再在两个服务器之间进行数据交换,从而减少了跨服务器的通信开销。