LLM词编码机制:词映射
LLM词编码机制:词映射
基于 BERT 架构的分词器对“中国首都”进行编码
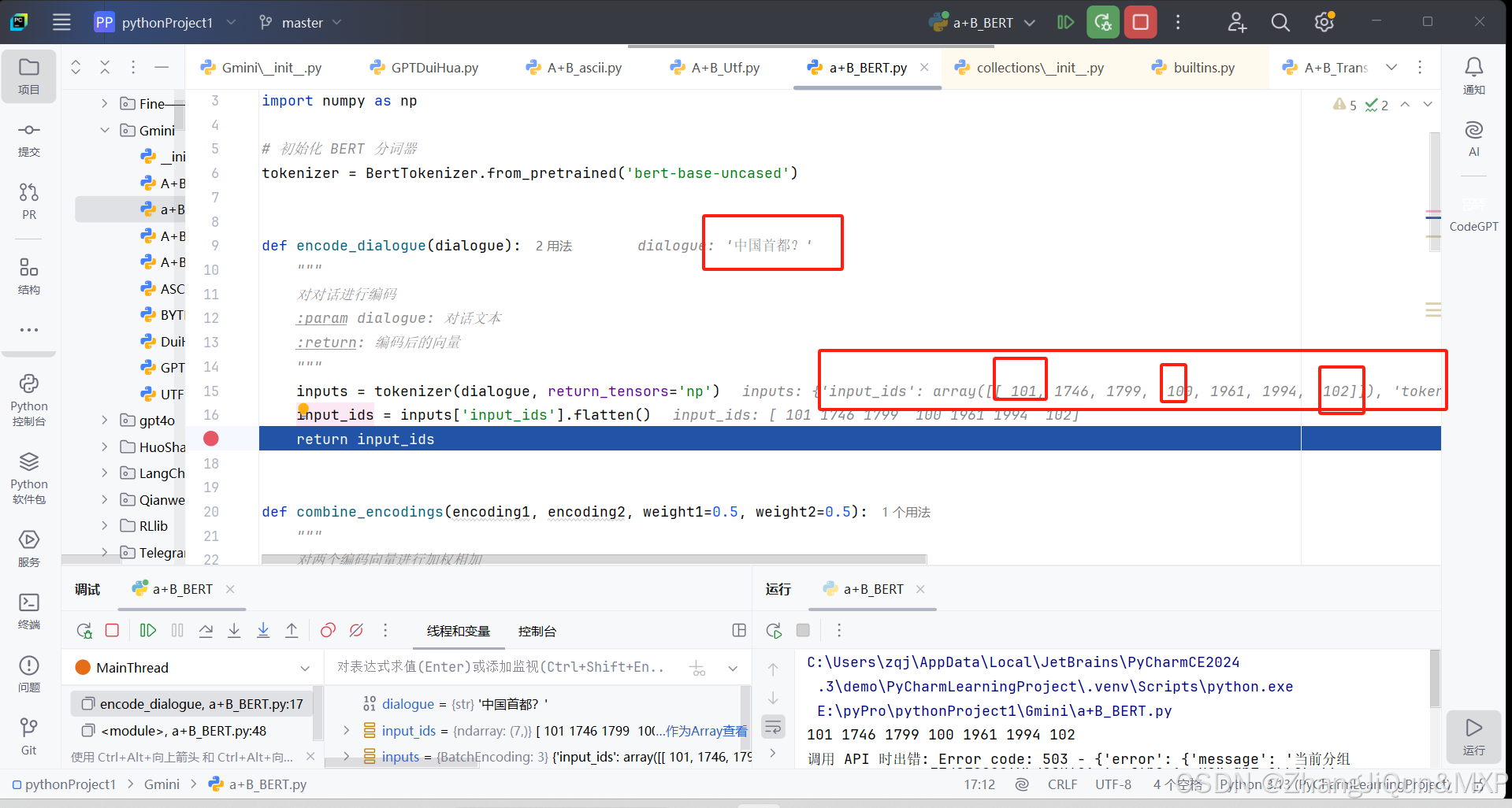
各部分含义
1. input_ids
input_ids 是将输入文本分词后,每个词元(token)对应在词表中的索引。在 BERT 及其相关模型里,通常会有一些特殊的 token 索引,常见的有:
101:表示分类标记[CLS],一般位于序列的起始位置,用于分类任务。102:表示分隔标记[SEP],用于分隔不同的句子。100:表示未知词元[UNK],当遇到词表中不存在的词时会用它来替代。
对于 array([[ 101, 1746, 1799, 100, 1961, 1994, 102]]),整体是一个二维数组,这