SWiRL:数据合成、多步推理与工具使用
SWiRL:数据合成、多步推理与工具使用
在大语言模型(LLMs)蓬勃发展的今天,其在复杂推理和工具使用任务上却常遇瓶颈。本文提出的Step-Wise Reinforcement Learning(SWiRL)技术,为解决这些难题带来曙光。它通过创新的合成数据生成和强化学习方法,显著提升模型表现,快和我一同深入探究这项技术的奥秘吧!
论文标题
Synthetic Data Generation & Multi-Step RL for Reasoning & Tool Use
来源
arXiv:2504.04736v2 [cs.AI] + https://arxiv.org/abs/2504.04736
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
大语言模型(LLMs)在自然语言处理领域成果斐然,展现出强大的能力,像Gemini 2、Claude 3等模型不断涌现,为该领域带来诸多突破。然而,它们在处理复杂任务时却面临困境。当遇到需要多步推理和工具使用的任务,如多跳问答、数学解题、编码等,LLMs往往表现不佳。同时,传统的强化学习方法,像RLHF、RLAIF等,主要针对单步优化,难以应对多步任务中复杂的推理和工具调用需求。因此,如何提升LLMs在多步推理和工具使用方面的能力,成为当前亟待解决的问题 。
研究问题
-
传统强化学习(RL)方法,如RLHF、RLAIF等,主要聚焦于单步优化,难以应对多步任务中复杂的推理和工具调用需求。
-
多步推理过程中,中间步骤的错误容易导致最终结果错误,如何保证模型在整个推理链条上的准确性,并有效从错误中恢复,是一大挑战。
-
在多步任务中,模型需要学会合理分解问题、适时调用工具、准确构造工具调用指令等,现有方法在这些方面的指导和优化能力不足。
主要贡献
1. 提出SWiRL方法:创新地提出了Step-Wise Reinforcement Learning(SWiRL),这是一种针对多步优化场景的合成数据生成和离线RL方法,有效提升模型在多步推理和工具使用任务中的能力。
2. 实现跨数据集泛化:SWiRL展现出强大的泛化能力,在不同的多跳问答和数学推理数据集上都取得了优异成绩。例如,在HotPotQA数据集上训练的SWiRL模型,在GSM8K数据集上的零样本性能相对提升了16.9% 。
3. 分析数据过滤策略:深入分析了多步推理和工具使用场景中合成数据过滤策略的影响,发现基于过程过滤的数据能让模型学习效果最佳,且模型能从包含错误最终答案的轨迹中学习,这与传统监督微调(SFT)方法不同。
4. 探索模型和数据集规模影响:研究了训练数据集大小和模型大小对SWiRL性能的影响,发现即使只有1000条轨迹也能显著提升模型性能,且较大模型在SWiRL训练下的泛化能力更强。
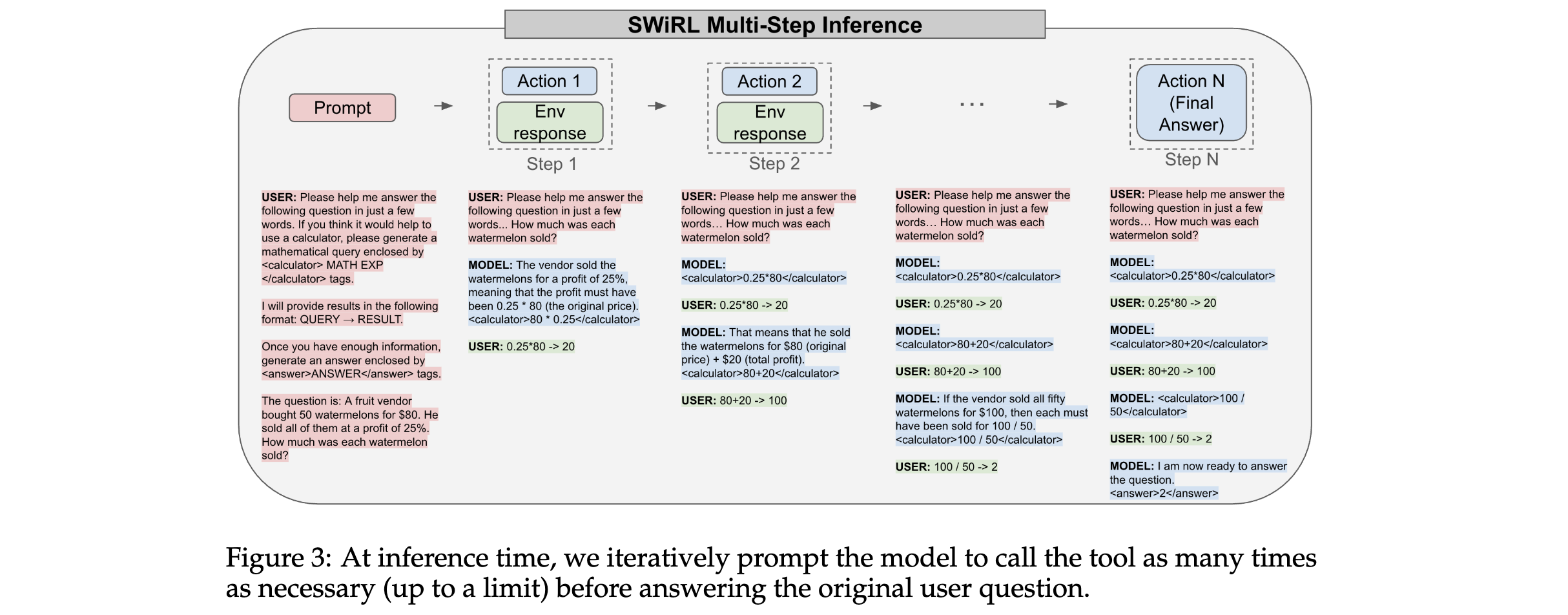
方法论精要
1. 核心算法/框架:SWiRL分为两个阶段。第一阶段是合成数据生成与过滤,通过迭代提示模型生成多步推理和工1具使用的轨迹,并对其进行不同策略的过滤;第二阶段是基于这些合成轨迹,使用逐步强化学习方法优化生成式基础模型。
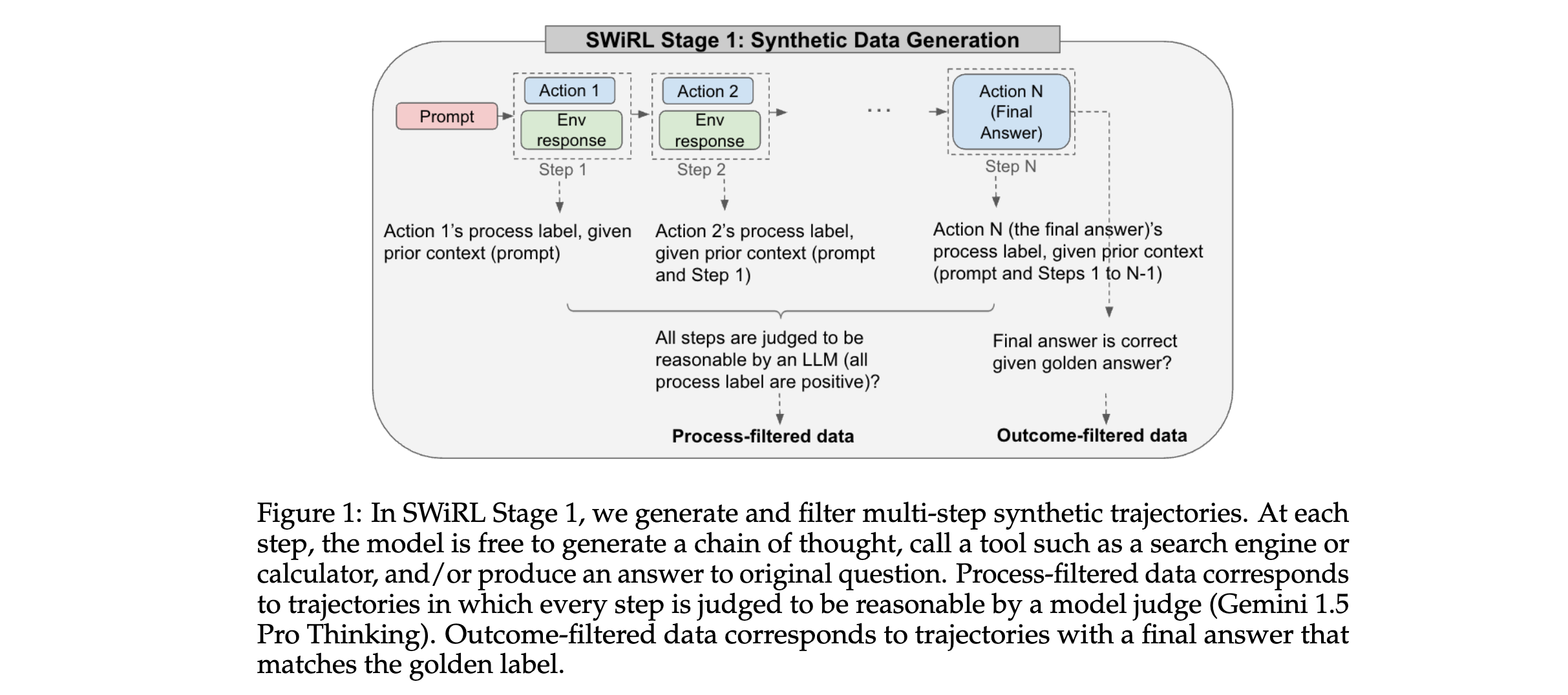
2. 关键参数设计原理:在逐步强化学习阶段,目标函数是期望的逐步奖励之和 J ( θ ) = E s ∼ T , a ∼ π θ ( s ) [ R ( a ∣ s ) ] J(\theta)=E_{s \sim T, a \sim \pi_{\theta}(s)}[R(a | s)] J(θ)=Es∼T,a∼πθ(s)[R(a∣s)] 。其中, π θ \pi_{\theta} πθ 是由 θ \theta θ 参数化的基础模型,通过SWiRL进行微调; T T T 表示合成多步轨迹中的所有状态集合;奖励信号 R ( a ∣ s ) R(a | s) R(a∣s) 由生成式奖励模型(如Gemini 1.5 Pro)评估,根据给定上下文 s s s 下生成响应 a a a 的质量来确定。

3. 创新性技术组合:将合成数据生成、多步推理和工具使用相结合,通过迭代生成多步轨迹并转换为多个子轨迹,在子轨迹上进行合成数据过滤和RL优化。这种方法能够在每一步推理后给予模型直接反馈,使模型学习更具上下文感知能力。
4. 实验验证方式:选择了五个具有挑战性的多跳问答和数学推理数据集,包括HotPotQA、MuSiQue、CofCA、BeerQA和GSM8K。基线方法选取了当前一些先进的语言模型,如GPT-4、GPT-3.5、Gemini 1.0 Pro等。通过对比在这些数据集上的性能,评估SWiRL的有效性。
实验洞察
在实验环节,研究团队对SWiRL展开了多维度探究,获得了一系列关键发现。
1. 性能优势:SWiRL在多个复杂任务数据集上表现卓越。在GSM8K数学推理数据集上,相比基线方法,其相对准确率提升21.5%;HotPotQA多跳问答数据集提升12.3%;CofCA数据集提升14.8%;MuSiQue数据集提升11.1%;BeerQA数据集提升15.3%。这表明SWiRL能显著增强模型在多步推理和工具使用任务中的表现,远超传统方法。
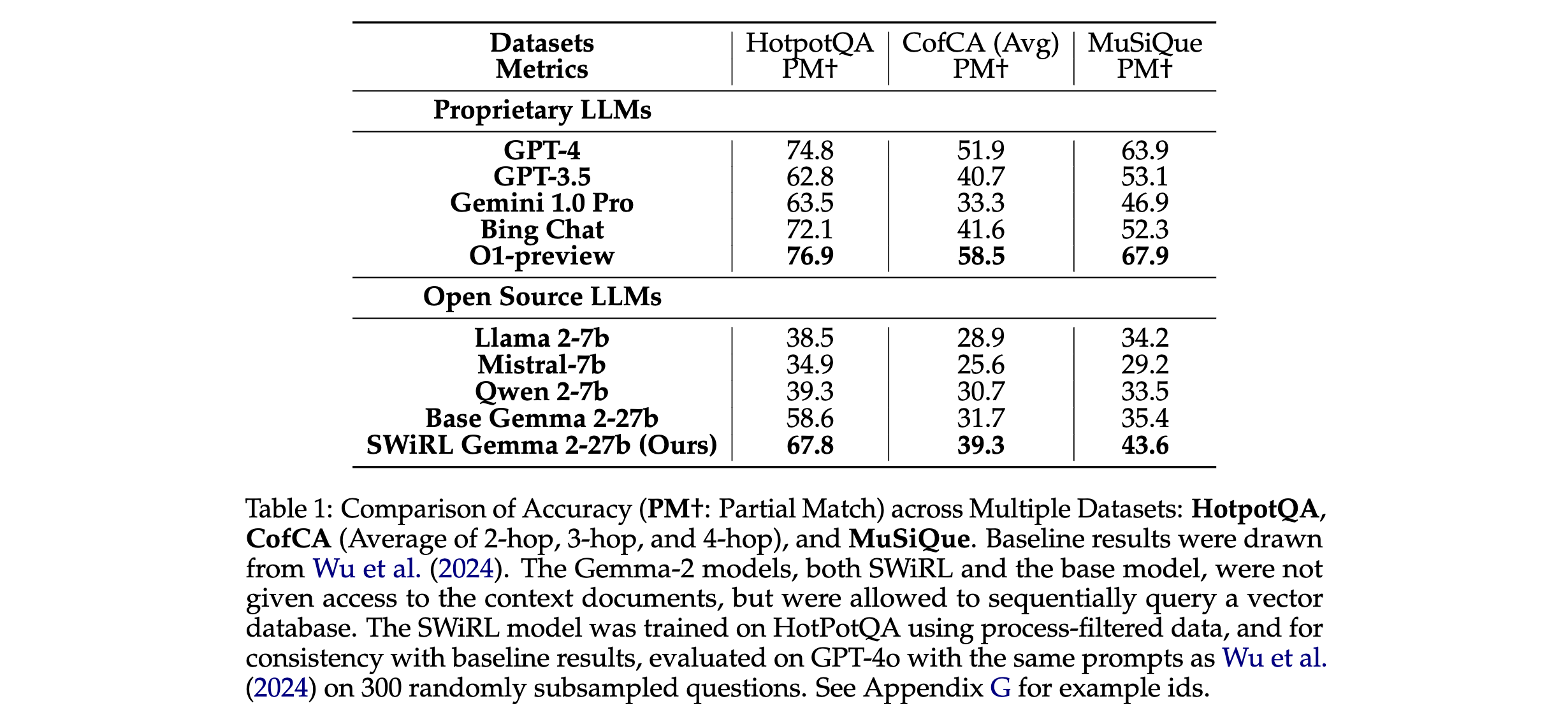
2. 泛化能力验证:SWiRL展现出良好的跨任务泛化性。在HotPotQA数据集训练的模型,在GSM8K上零样本性能相对提升16.9%;反之,在GSM8K训练的模型,在HotPotQA上性能提升9.2%。这意味着SWiRL训练的模型能将在某一任务中学到的多步推理和工具使用能力,有效迁移到其他不同类型任务中。
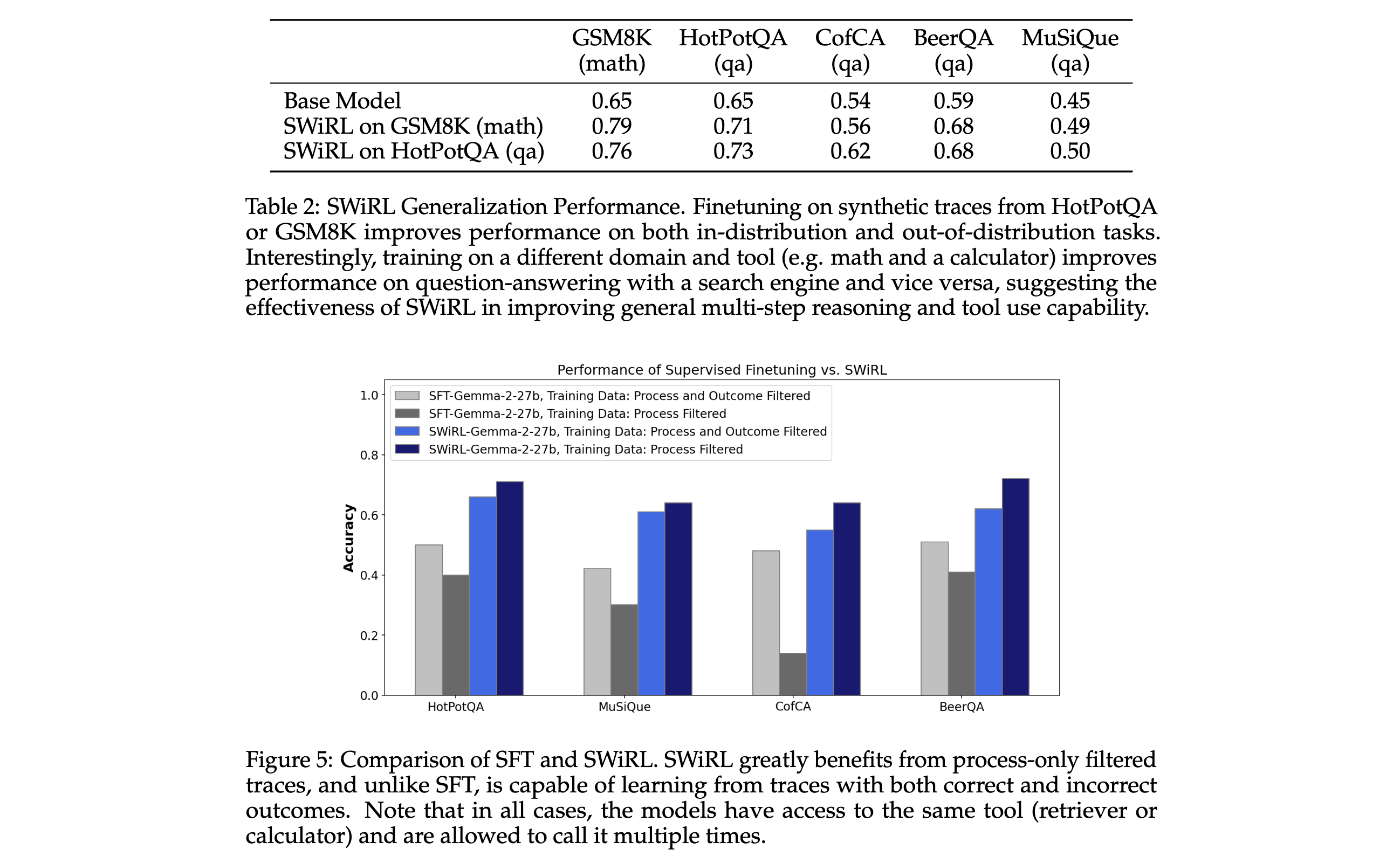
3. 数据过滤策略影响:通过对不同数据过滤策略的研究发现,仅进行过程过滤的数据能让模型达到最佳性能。虽然传统观点认为基于结果正确性过滤数据能提升性能,但实验表明,SWiRL从包含正确和错误最终答案的过程过滤数据中学习效果更好,而基于结果过滤的数据(除MuSiQue数据集外)反而降低了模型性能。
4. 数据集和模型大小的影响:实验发现,增加训练数据集规模能持续提升SWiRL模型性能。即使只有1000条轨迹,模型在多个数据集上也能取得显著进步。此外,较大模型(如Gemma-2-27b)在SWiRL训练下的泛化能力更强,而较小模型(Gemma-2-2b和9b)虽在域内有一定提升,但泛化能力相对较弱。