Scrapy框架之Scrapyd部署及Gerapy分布式爬虫管理框架的使用
Scrapyd
Scrapyd 是一个用于部署和运行 Scrapy 爬虫的服务器。
1.安装
Scrapyd服务端:pip install scrapyd
Scrapyd客户端:pip install scrapyd-client
运行scrapyd
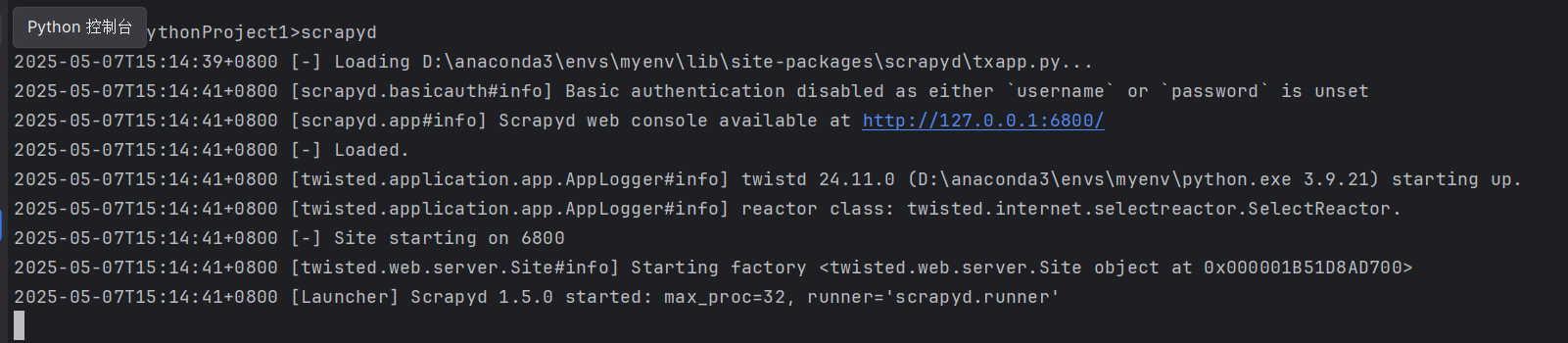
浏览器输入http://127.0.0.1:6800/
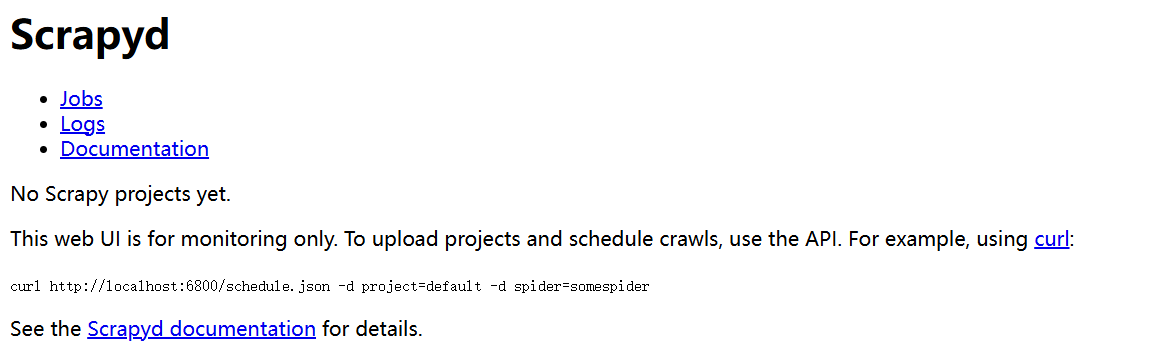
2.配置
安装完成后,需要对 Scrapyd 进行配置。通常需要创建一个scrapyd.conf配置文件,该文件用于设置 Scrapyd 的各种参数,如监听端口、日志文件路径、项目存储路径等。
官方配置文件:https://scrapyd.readthedocs.io/en/stable/config.html
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir =
jobs_to_keep = 5
dbs_dir = dbs
max_proc = 0
max_proc_per_cpu = 4
finished_to_keep = 100
poll_interval = 5.0
bind_address = 0.0.0.0
http_port = 6800
debug = off
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher
webroot = scrapyd.website.Root
在上述配置中,指定了项目 egg 文件存储目录、日志文件目录、绑定的 IP 地址和端口等信息。你可以根据实际需求对这些配置进行修改。
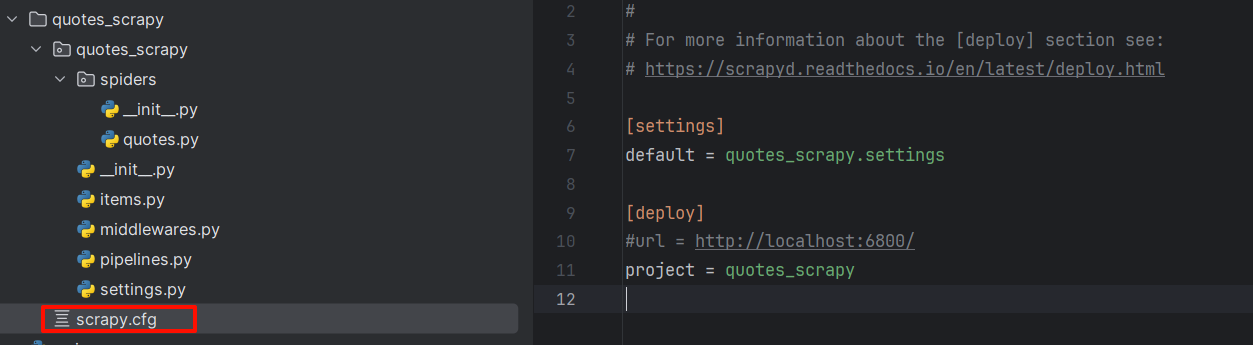
打开scrapy项目里面的scrapy.cfg,修改一下
[settings]
default = quotes_scrapy.settings[deploy:Quotes] # deploy冒号后面写部署名
url = http://localhost:6800/
project