记录学习《手动学习深度学习》这本书的笔记(十)
因为最近在做《语音与语言理解综合处理》的实验,所以打算先看第14章:自然语言处理:预训练和第15章:自然语言处理:应用,之后再来看第13章:计算机视觉。
第十四章:自然语言处理:预训练
这一章主要讲的是预训练部分,也就是将词汇转化为向量的部分。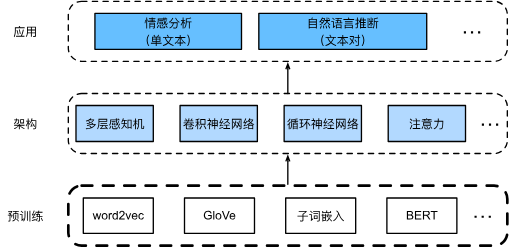
这时就不得不提到word2vec嵌入模型,注意将单词转化为向量也是个需要训练的模型,而不是简单的转换。
预训练后,每个词元都会对应一个向量,不管它们在不同句子中的意思是不是一样的,每个词元对应相同向量,比如“吃苹果”中的苹果和“苹果手机”中的苹果对应同一个向量,但是这显然不是我们想要的,所以较新的预训练模型会用不同的词向量表示相同的词,比如BERT就是这样。
另外,预训练层是单独训练的,不是和后面的架构层一起训练。
14.1 词嵌入(word2vec)
在之前的章节中,我们使用独热向量表示词,这不是一个好的选择,它不能反应单词间的相似度之类的隐藏关系。
比如说经常使用的余弦相似度:,如果使用独热向量,那么任意两个向量间的余弦相似度就都为0。
因此,独热向量固然简单,但还是自监督的词嵌入更合适,它将每个单词映射为固定长度的向量,这些向量能够更好的反映词与词之间的相似度和类别关系。
word2vec工具包含两个模型:跳元模型(skip-gram)和连续词袋模型(CBOW)。
需要注意的是,两种模型都是不带数据标签的自监督模型。
下面一一介绍这两种模型和其训练方法:
1. 跳元模型
跳元模型中,每一个词都由两个向量表示,一个当这个词做中心词用,一个当这个词做上下文词用。
对于一个中心词 ,可以对它和它周围的上下文词
做softmax操作:
代表 上下文出现
的概率。
目标就是将两个向量 u 和 v 训练成如果俩词相关性很高,那么俩向量的乘积就越大。
于是对于上下文窗口 m ,可以列出对于它的似然函数:
代表在概率 P 下,中心词 和周围上下文词
同时出现的概率,为了方便计算,可以取对数变成对数似然。
所以损失函数的选取也有了着落:
目标就是让对数似然最大也就是损失函数最小。
比如使用随机梯度下降优化器,每次迭代就会随机取一个子序列计算上面的损失函数,然后计算梯度,更新参数。
经过一系列计算,损失函数的梯度为: 。
可以看出计算损失函数需要 词典中以 为中心词的所有词的条件概率。
训练完之后,所有单词都有两个词向量,(作为中心词)和
(作为上下文词)。
跳元模型一般采用中心词向量 作为词表式。
2. 连续词袋模型
其实大体上和跳元模型差不多,只不过是根据上下文词汇出现的情况下这些词汇出现的概率,并且要利用连续的多个上下文词汇。
需要注意,连续词袋模型和跳元模型使用的词向量符合想法,连续词袋模型中两个词向量 (作为上下文词),
(作为中心词)。
相当于一个句子中将每一个上下文词与中心词一同出现的概率相加,再求平均。
那么似然函数则是:
和跳元模型相似,取对数后加负号就变成了损失函数:
求梯度就是:
跳元模型一般采用上下文向量 作为词表式。
14.2 近似训练
上面的两种方法虽好,但是面对词元数量非常多的词库,计算量就会非常大。
本节介绍两种近似训练方法:负采样和层序softmax。
以跳元模型为例,用两种近似方法优化模型。
1. 负采样
之前的跳元模型,似然函数为:
但是这个函数只考虑那些正样本,只有所有词向量为无穷大时它才为1,为了使它更有意义,可以考虑添加从预定义分布中采用的负样本。于是考虑取一些噪声词 (表示 k 个噪声词,
、
、……
),这些词不来自中心词的上下文窗口。
而来自中心词上下文窗口的词,就只取一个 。
相当于似然函数是 在中心词上下文的概率还要乘上
、
、……
不在窗口内的概率。
所以对数损失就为:
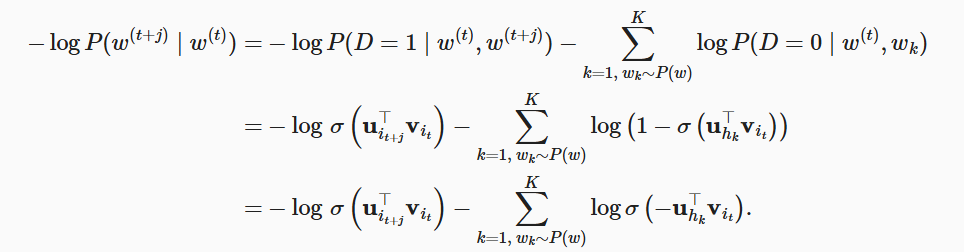
( D = 0 意思是词元不存在在中心词上下文中)
因为只取一个在上下文窗口的词元,所以每个训练步的计算成本与窗口大小无关,只与噪声词数量 k 有关。
2. 层序softmax
这种方法使用二叉树,每个叶子节点代表一个词。
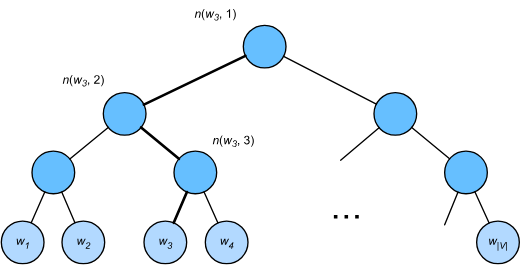
我们定义L(w)表示单词节点 w 到根节点的距离,n(w, j)表示这个路径的第 j 个节点,其上下文单词向量为 。
然后更改条件概率,单词 出现在这个位置的概率为:
是sigmoid的意思,
意思是节点 n 的左节点, x 为真时
,否则
。
可以看到这么做只要取路径上的词向量和中心词的匹配度了,并且可以体现出位置关系(-1和1),距离更远的就更加不重要,可以统统归纳成根节点。
比如图上的节点 ,原本要取 |V| 个单词的概率,现在只需要取到根节点路径上的三个节点,因为从根节点开始到
需要向左向右向左遍历,所以
存在于此的概率是:
而因为,所以每对左右节点的概率加起来可以消掉它们的根节点那项,二叉树中所有词元叶子节点的概率加起来就为 1 。
这样做大大降低了计算成本,因为只需要考虑词元节点到根节点经过的节点的向量,计算成本只需词表大小取对数。
14.3 用于预训练词嵌入的数据集
这一节主要通过代码实例实现前面学习的方法。
使用了华尔街日报数据集,先使用之前章节的方法构建词表,按单词划分:
划分句子:
#@save
d2l.DATA_HUB['ptb'] = (d2l.DATA_URL + 'ptb.zip','319d85e578af0cdc590547f26231e4e31cdf1e42')#@save
def read_ptb():"""将PTB数据集加载到文本行的列表中"""data_dir = d2l.download_extract('ptb')# Readthetrainingset.with open(os.path.join(data_dir, 'ptb.train.txt')) as f:raw_text = f.read()return [line.split() for line in raw_text.split('\n')]sentences = read_ptb()
f'# sentences数: {len(sentences)}'![]()
构建词表:
vocab = d2l.Vocab(sentences, min_freq=10)
f'vocab size: {len(vocab)}'![]()
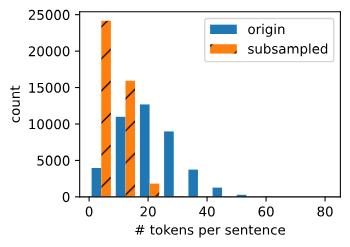
考虑到有些单词出现频率太多,但是却对句子意思没有实际意义,比如连接词、冠词,而且会加大计算量,所以要将它们适当剔除。
每个单词 剔除概率为:
其中 t 是超参数,超过这个频率的单词就有概率被剔除。
#@save
def subsample(sentences, vocab):"""下采样高频词"""# 排除未知词元'<unk>'sentences = [[token for token in line if vocab[token] != vocab.unk]for line in sentences]counter = d2l.count_corpus(sentences)num_tokens = sum(counter.values())# 如果在下采样期间保留词元,则返回Truedef keep(token):return(random.uniform(0, 1) <math.sqrt(1e-4 / counter[token] * num_tokens))return ([[token for token in line if keep(token)] for line in sentences],counter)subsampled, counter = subsample(sentences, vocab)画出丢弃前后的直方图:
接着提取中心词和上下文词:
#@save
def get_centers_and_contexts(corpus, max_window_size):"""返回跳元模型中的中心词和上下文词"""centers, contexts = [], []for line in corpus:# 要形成“中心词-上下文词”对,每个句子至少需要有2个词if len(line) < 2:continuecenters += linefor i in range(len(line)): # 上下文窗口中间iwindow_size = random.randint(1, max_window_size)indices = list(range(max(0, i - window_size),min(len(line), i + 1 + window_size)))# 从上下文词中排除中心词indices.remove(i)contexts.append([line[idx] for idx in indices])return centers, contexts返回的centers和context分别是中心词列表和对应的上下文词列表。
接着进行负采样进行近似训练。
这是一个采用函数:
#@save
class RandomGenerator:"""根据n个采样权重在{1,...,n}中随机抽取"""def __init__(self, sampling_weights):# Excludeself.population = list(range(1, len(sampling_weights) + 1))self.sampling_weights = sampling_weightsself.candidates = []self.i = 0def draw(self):if self.i == len(self.candidates):# 缓存k个随机采样结果self.candidates = random.choices(self.population, self.sampling_weights, k=10000)self.i = 0self.i += 1return self.candidates[self.i - 1]输入权重列表为相对概率,列表长度为取数范围。
在取噪声词的时候,就可以将相对概率设为单词出现频率的 0.75 次方。
#@save
def get_negatives(all_contexts, vocab, counter, K):"""返回负采样中的噪声词"""# 索引为1、2、...(索引0是词表中排除的未知标记)sampling_weights = [counter[vocab.to_tokens(i)]**0.75for i in range(1, len(vocab))]all_negatives, generator = [], RandomGenerator(sampling_weights)for contexts in all_contexts:negatives = []while len(negatives) < len(contexts) * K:neg = generator.draw()# 噪声词不能是上下文词if neg not in contexts:negatives.append(neg)all_negatives.append(negatives)return all_negativesall_negatives = get_negatives(all_contexts, vocab, counter, 5)这段代码大致是,先算出词表内各单词权重,然后初始化取随机数的类,对于每个中心词-上下文样本对,每次取随机数作为噪声词汇直到数量大于【上下文词数 * K】(之前说过,负采样随机下降时每次取一个上下文词和 K 个噪声词),这样每个词汇对就对应一组大小为【上下文词数 * K】的噪声词汇。
接着转换小批量,在训练过程中迭代加载。
由于每个单词上下文词汇数量不同,噪声词汇也不同,所以要设置填充,并且设置掩码masks遮住填充的部分,此外还要设置标签labels区分是上下文词汇还是噪声。
#@save
def batchify(data):"""返回带有负采样的跳元模型的小批量样本"""max_len = max(len(c) + len(n) for _, c, n in data)centers, contexts_negatives, masks, labels = [], [], [], []for center, context, negative in data:cur_len = len(context) + len(negative)centers += [center]contexts_negatives += \[context + negative + [0] * (max_len - cur_len)]masks += [[1] * cur_len + [0] * (max_len - cur_len)]labels += [[1] * len(context) + [0] * (max_len - len(context))]return (np.array(centers).reshape((-1, 1)), np.array(contexts_negatives), np.array(masks), np.array(labels))输入data代表 { 中心词、上下文词汇、噪声词 } 组合(可能有很多组)。
这段代码实现了:设置上下文词和噪声词的最大长度,对于每组,检查长度,若小于最大长度则填充到最大长度,并且填充部分掩码设为 0 ,再为每个词汇打上标签……
最终输出四个组合:中心词组、上下文-噪声组、掩码组、标签组。
代码作用是将数据变成批量的样子(整合批量中的中心词、上下文-噪声)。
最后整合上述所有代码即可。。
#@save
def load_data_ptb(batch_size, max_window_size, num_noise_words):"""下载PTB数据集,然后将其加载到内存中"""num_workers = d2l.get_dataloader_workers()sentences = read_ptb()vocab = d2l.Vocab(sentences, min_freq=10)subsampled, counter = subsample(sentences, vocab)corpus = [vocab[line] for line in subsampled]all_centers, all_contexts = get_centers_and_contexts(corpus, max_window_size)all_negatives = get_negatives(all_contexts, vocab, counter, num_noise_words)class PTBDataset(torch.utils.data.Dataset):def __init__(self, centers, contexts, negatives):assert len(centers) == len(contexts) == len(negatives)self.centers = centersself.contexts = contextsself.negatives = negativesdef __getitem__(self, index):return (self.centers[index], self.contexts[index],self.negatives[index])def __len__(self):return len(self.centers)dataset = PTBDataset(all_centers, all_contexts, all_negatives)data_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True,collate_fn=batchify, num_workers=num_workers)return data_iter, vocab大体步骤:传入参数批量大小、上下文窗口大小、噪声词数量 -> 加载数据(按句子切分),生成词典 -> 下采样数据,输入句子和词表,输出下采样后的句子和词汇计数器 -> 根据下采样后的句子和词表生成每个句子的词汇列表 -> 根据句子词汇列表和上下文窗口大小构建中心词-上下文词两个一一对应的列表 -> 根据上下文词、词汇表、计数器、噪声词数量生成噪声词列表 -> 将中心词列表、上下文词列表、噪声词列表整合在一起构成数据集 -> 使用pytorch的API生成迭代器
14.4 预训练word2vec
在嵌入层中,词元被映射到特征向量。
这里联想到pytorch的embedding层,这是一个将词汇转化为向量的层,可以利用它来构建word2vec层。(分别将词元映射为中心词向量和上下文-噪声词向量)
embedding层作用是将词元转化为向量,在这里要将中心词转化为中心词向量 v ,将上下文和噪声转化为上下文向量 u ,将中心词与每一个上下文-噪声点乘后就可以得到需要的东西:
embed = nn.Embedding(num_embeddings=20, embedding_dim=4)
# 将每个词元转化为维度为 4 的向量def skip_gram(center, contexts_and_negatives, embed_v, embed_u):v = embed_v(center)u = embed_u(contexts_and_negatives)pred = torch.bmm(v, u.permute(0, 2, 1))return pred回想一下负采样大致的流程,相当于是一个二分类问题,标签代表是上下文还是噪声,也就可以看作二分类的类别,于是我们可以直接用二分类的交叉熵损失函数定义这个问题的损失函数:
class SigmoidBCELoss(nn.Module):# 带掩码的二元交叉熵损失def __init__(self):super().__init__()def forward(self, inputs, target, mask=None):out = nn.functional.binary_cross_entropy_with_logits(inputs, target, weight=mask, reduction="none")return out.mean(dim=1)loss = SigmoidBCELoss()inputs代表匹配度计算结果(也就是中心词向量和上下文向量的积),target代表实际值。之后还要通过之前的损失函数计算inputs。
这个函数nn.functional.binary_cross_entropy_with_logits的内部结构是取inputs中有效的元素根据target计算sigmoid,就是算损失值。
模型中定义两个嵌入层,长度是词表大小,设置维度为 100 :
embed_size = 100
net = nn.Sequential(nn.Embedding(num_embeddings=len(vocab),embedding_dim=embed_size),nn.Embedding(num_embeddings=len(vocab),embedding_dim=embed_size))最后整合代码构建train函数:
def train(net, data_iter, lr, num_epochs, device=d2l.try_gpu()):def init_weights(m):if type(m) == nn.Embedding:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)net = net.to(device)optimizer = torch.optim.Adam(net.parameters(), lr=lr)animator = d2l.Animator(xlabel='epoch', ylabel='loss',xlim=[1, num_epochs])# 规范化的损失之和,规范化的损失数metric = d2l.Accumulator(2)for epoch in range(num_epochs):timer, num_batches = d2l.Timer(), len(data_iter)for i, batch in enumerate(data_iter):optimizer.zero_grad()center, context_negative, mask, label = [data.to(device) for data in batch]pred = skip_gram(center, context_negative, net[0], net[1])l = (loss(pred.reshape(label.shape).float(), label.float(), mask)/ mask.sum(axis=1) * mask.shape[1])l.sum().backward()optimizer.step()metric.add(l.sum(), l.numel())if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(metric[0] / metric[1],))print(f'loss {metric[0] / metric[1]:.3f}, 'f'{metric[1] / timer.stop():.1f} tokens/sec on {str(device)}')skip_gram是前向传播函数,计算每一批量中心词向量与上下文-噪声向量乘积,loss函数计算损失。
训练好之后就可以尝试找与中心词最匹配的词验证准确性了:
def get_similar_tokens(query_token, k, embed):W = embed.weight.datax = W[vocab[query_token]]# 计算余弦相似性。增加1e-9以获得数值稳定性cos = torch.mv(W, x) / torch.sqrt(torch.sum(W * W, dim=1) *torch.sum(x * x) + 1e-9)topk = torch.topk(cos, k=k+1)[1].cpu().numpy().astype('int32')for i in topk[1:]: # 删除输入词print(f'cosine sim={float(cos[i]):.3f}: {vocab.to_tokens(i)}')其中torch.topk意思是找出cos中最大的 k+1 个元素并转化为数组。
14.5 全局向量的词嵌入(GloVe)
GloVe的思路是将中心词的所有上下文单词合并在一起。
考虑到中心词所有上下文单词对它的意义都相同,所以可以将某个中心词所有上下文合并,重复的单词重复计算。
将预测的中心词 周围有上下文词
的概率记为
,则
。
对于中心词的上下文单词,我们将其在中心词的上下文出现的次数成为【重数】,记为 。
损失函数就可以记为: 。(在Word2vec中就是这样计算的)
也可以将中心词 出现的重数记作
,将
周围有上下文词
的实际概率记作
,则损失函数也可以写作:
。
仔细一看这个和交叉熵损失函数非常像:![]() ,都有实际概率乘以预测概率的对数,我们的损失函数相当于交叉熵损失乘以了权重
,都有实际概率乘以预测概率的对数,我们的损失函数相当于交叉熵损失乘以了权重 。
但是,考虑到交叉熵损失还有不少缺点:① 运算量过大,计算 需要对整个词表的数值求和;② 一些罕见事件往往也会被考虑进去,从而赋予过大的权重。
所以GloVe对Word2vec做了一些修改:
(一) 将 p 和 q 改为 、
,不需要计算所有词表的求和,这样一来平方损失为
(预测概率 - 真实概率),而不再利用交叉熵损失 。
说人话就是将 的意义定为预测
和
同时出现的次数,然后损失函数是两者均方误差。
(二)设置偏置项 和
,分别代表中心词和上下文偏置。
(三)将损失函数中权重 替换为权重函数
。
总之,GloVe的损失函数为: 。
对照一下Word2vec的损失函数: 。
再对照一下均方误差:![]() 。
。
对于权重函数 ,建议是当
小于某个数 c 时缓慢增长(
,α = 0.75),当
大于 c 时保持不变(
)。
由于 ,省略
的损失项。
在小批量随机梯度下降时,每次随机取非零的 计算损失和梯度更新模型参数,如何取非零的
呢?就要构建全局语料库了。
所以GloVe模型被称为全局向量。
注意GloVe模型还有个和Word2vec模型不同的点,那就是GloVe中 ,而Word2vec中
,所以GloVe中,
和
相当于是等价的,只是实际中由于初始化的值不同,最后结果也可能不同。
GloVe一般采用中心词向量和上下文向量的和 作为词表式。
还可以用另一种角度理解GloVe模型中 。
原本的 为
上下文词为
的实际条件概率,那么假设一个中心词
和两个上下文词
和
,
就是两个上下文词与中心词一起出现的概率之比。
需要设计一个代表 的
函数使得
且
。
刚好 就满足。
于是 ,两边取对数:
。
那么预测(左式)和实际(右式)的差则是 。
是不是很熟悉?GloVe的损失函数 (请把 i 看成 k 因为两个式子用的字母不一样)。
意思就是用 拟合了
。
好吧我觉得有点难懂,还不如将 视为预测
和
组合出现的次数……
总结来说就是word2vec可以用词与词共同出现的语料库解释,GloVe可以用词与词共同出现的概率的比值解释。
对于大型语料库,还是GloVe更合适一点。
14.6 子词嵌入
在英语中,很多单词都有变形,比如过去时加ed,现在时加ing,考虑到单词及其变形有很大关联,fastText模型提出一种子词嵌入的方法。
在fastText模型中,每个单词有若干个子词。
比如设置最小词元为3,首先,对于where这个单词,在词的开头和末尾添加特殊字符“<”和“>”,以将前缀和后缀与其他子词区分开来;
这样n=3时,我们将获得长度为3的所有子词: “<wh”“whe”“her”“ere”“re>”和特殊子词“<where>”。
然后n=4、5,获取所有词元。将这个单词的n-gram集合设为 。
跳元模型中,这个单词作为中心词的向量就是其子词向量之和。
其他地方和跳元模型相同。
接着我们提出另一种字节对编码的子词嵌入模型,这种更常用一点。
这种方法是基于贪心算法。
首先初始化词表为所有英文小写字母、符号 ' _ ' 、和其他特殊字符 ' [UNK] ' 。
import collectionssymbols = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm','n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z','_', '[UNK]'](字符 ' _ ' 是被加到每一个单词后,用于区分单词边界的。)
后面会往其中加入频率高的字符串,所以字典中不一定只有单个字母。为了方便,我之后将在这个词典中的所有字符和字符串都称作【字母】。
之后的思路是,每次选取单词中总结出来出现频率最高的单词对加入词典中。
接着,将输入的词汇字母间隔一个空格(代表初始切分,之后会按照频率合并):
raw_token_freqs = {'fast_': 4, 'faster_': 3, 'tall_': 5, 'taller_': 4}
token_freqs = {}
for token, freq in raw_token_freqs.items():token_freqs[' '.join(list(token))] = raw_token_freqs[token]
token_freqs![]()
定义一个函数,返回词内出现最频繁的连续符号对。
def get_max_freq_pair(token_freqs):pairs = collections.defaultdict(int)for token, freq in token_freqs.items():symbols = token.split()for i in range(len(symbols) - 1):# “pairs”的键是两个连续符号的元组pairs[symbols[i], symbols[i + 1]] += freqreturn max(pairs, key=pairs.get) # 具有最大值的“pairs”键这个函数传入字符和其频率的列表,对每个单词,每次取相邻两个【字母】,将这对【字母】频率加这个单词出现的频率,最后返回【字母】对频率表中频率最大的那对。
然后再定义一个合并【字母】的函数,每次取频率最大的字母合并:
def merge_symbols(max_freq_pair, token_freqs, symbols):symbols.append(''.join(max_freq_pair))new_token_freqs = dict()for token, freq in token_freqs.items():new_token = token.replace(' '.join(max_freq_pair),''.join(max_freq_pair))new_token_freqs[new_token] = token_freqs[token]return new_token_freqs传入的max_freq_pair是目前频率最大的【字母】对,每次按照这个合并,在token_freqs查找max_freq_pair,若有则将【字母】对的空格去掉,返回去掉所有这些空格的new_token_freqs。
尝试使用这两个函数,合并10次:
num_merges = 10
for i in range(num_merges):max_freq_pair = get_max_freq_pair(token_freqs)token_freqs = merge_symbols(max_freq_pair, token_freqs, symbols)print(f'合并# {i+1}:',max_freq_pair)
查看一下划分情况:
print(list(token_freqs.keys()))![]()
并且这样的划分中,取最高频用的数据集和最后用来划分的数据集不一定要一样。
试着将上面“训练”出来的词典symbols用在其他单词上,先写一个划分函数:
def segment_BPE(tokens, symbols):outputs = []for token in tokens:start, end = 0, len(token)cur_output = []# 具有符号中可能最长子字的词元段while start < len(token) and start < end:if token[start: end] in symbols:cur_output.append(token[start: end])start = endend = len(token)else:end -= 1if start < len(token):cur_output.append('[UNK]')outputs.append(' '.join(cur_output))return outputs这个函数传入symbols词典和一些需要划分的单词,对每个单词,找寻具有单词中最长词元的词元段。
设置start和end双指针,一开始分别指向首尾字母,利用贪心思想,每次检查其中的串有没有在字典里,如果没有则end-1,如果有则将这串放入结果列表,start指向end,继续查找。
尝试划分一下其他单词:
tokens = ['tallest_', 'fatter_']
print(segment_BPE(tokens, symbols))![]()
14.7 词的相似度和类比任务
本节介绍如何导入训练好的预训练模型。
比如加载有名的维度为50、100、200的预训练GloVe嵌入:
#@save
d2l.DATA_HUB['glove.6b.50d'] = (d2l.DATA_URL + 'glove.6B.50d.zip','0b8703943ccdb6eb788e6f091b8946e82231bc4d')#@save
d2l.DATA_HUB['glove.6b.100d'] = (d2l.DATA_URL + 'glove.6B.100d.zip','cd43bfb07e44e6f27cbcc7bc9ae3d80284fdaf5a')#@save
d2l.DATA_HUB['glove.42b.300d'] = (d2l.DATA_URL + 'glove.42B.300d.zip','b5116e234e9eb9076672cfeabf5469f3eec904fa')创建一个类方便取出模型:
#@save
class TokenEmbedding:"""GloVe嵌入"""def __init__(self, embedding_name):self.idx_to_token, self.idx_to_vec = self._load_embedding(embedding_name)self.unknown_idx = 0self.token_to_idx = {token: idx for idx, token inenumerate(self.idx_to_token)}def _load_embedding(self, embedding_name):idx_to_token, idx_to_vec = ['<unk>'], []data_dir = d2l.download_extract(embedding_name)# GloVe网站:https://nlp.stanford.edu/projects/glove/# fastText网站:https://fasttext.cc/with open(os.path.join(data_dir, 'vec.txt'), 'r') as f:for line in f:elems = line.rstrip().split(' ')token, elems = elems[0], [float(elem) for elem in elems[1:]]# 跳过标题信息,例如fastText中的首行if len(elems) > 1:idx_to_token.append(token)idx_to_vec.append(elems)idx_to_vec = [[0] * len(idx_to_vec[0])] + idx_to_vecreturn idx_to_token, torch.tensor(idx_to_vec)def __getitem__(self, tokens):indices = [self.token_to_idx.get(token, self.unknown_idx)for token in tokens]vecs = self.idx_to_vec[torch.tensor(indices)]return vecsdef __len__(self):return len(self.idx_to_token)这个类中创建了两个对应的列表,一个是所有词,一个是对应向量,还创建了方便查找序号的字典token_to_idx,存放每一个单词和索引。
初始化时将预训练模型的词和对应向量放入列表,并添加未知词语UNK和对应全零向量。
比如可以通过调用token_to_idx和idx_to_token,通过单词查找序号或通过序号查找单词。
glove_6b50d.token_to_idx['beautiful'], glove_6b50d.idx_to_token[3367]![]()
注意,字典idx_to_token中序号是从1开始,它不包含UNK;而列表token_to_idx中序号是从0开始,第0位表示UNK。
然后我们可以验证这些向量的合理性。
之前我们使用余弦相似度展示词语的语义,可以使用knn(k近邻函数)列出和目标单词向量 x 余弦相似度最接近的单词向量。
def knn(W, x, k):# 增加1e-9以获得数值稳定性cos = torch.mv(W, x.reshape(-1,)) / (torch.sqrt(torch.sum(W * W, axis=1) + 1e-9) *torch.sqrt((x * x).sum()))_, topk = torch.topk(cos, k=k)return topk, [cos[int(i)] for i in topk]这个函数传入的 W 包含了所有单词向量, x 则是目标向量, k 是选取前 k 个余弦相似度最大的元素。
将 W 和 x 直接做余弦相似度计算,最后用 torch.topk 查询前 k 大的元素,返回其索引和对应余弦相似度。
设置函数分别将输入单词转化为向量、将输出结果转化为单词:
def get_similar_tokens(query_token, k, embed):topk, cos = knn(embed.idx_to_vec, embed[[query_token]], k + 1)for i, c in zip(topk[1:], cos[1:]): # 排除输入词print(f'{embed.idx_to_token[int(i)]}:cosine相似度={float(c):.3f}')尝试:
get_similar_tokens('chip', 3, glove_6b50d)
两个单词的查询完成,接下来可以尝试四个单词的查询,也叫做词类比。
给出单词a和单词b,这两者存在一些特殊关系,接着给出单词c,查找对应的单词d,使a与b之间的关系和c与d相似,比如父与子、母与女;长与宽、胖与瘦。
用代码实现的方法就是将 b-a+c 设置为一个词向量,查找与之最接近的词(通过余弦相似度)。
def get_analogy(token_a, token_b, token_c, embed):vecs = embed[[token_a, token_b, token_c]]x = vecs[1] - vecs[0] + vecs[2]topk, cos = knn(embed.idx_to_vec, x, 1)return embed.idx_to_token[int(topk[0])] # 删除未知词尝试:
get_analogy('man', 'woman', 'son', glove_6b50d)![]()
或者比较贴近实用的,查找过去式:
get_analogy('do', 'did', 'go', glove_6b50d)![]()
总之,有了这些预训练,我们可以很方便的使用,将这些词向量用到下游任务中。
14.8 来自Transformer的双向编码器表示(BERT)
虽然之前提到过同一个词可能有两种不同意思,但前面我们的模型都忽视了这种一词多义性,都是一个词对应一个词向量,简称“上下文无关”(意思是对每一个词的不同含义上下文无关,就是前面学的那种)。
对此,我们提出一种“上下文敏感”词表式。上下文敏感的方法有TagLM(语言模型增强的序列标记器)、CoVe(上下文向量)、ELMo(来自语言模型的嵌入),可以将这些方法用在原有模型上。
比如ELMo使用双向LSTM模型,一开始使用“上下文无关”模型(如GloVe)生成词向量,然后将LSTM模型为每个单词生成的中间层(可能有多层,它们融合了上下文信息)与原本的嵌入层结合,生成最后的嵌入层。
这样做需要注意两点:一是在使用ELMo时需要冻结这个双向LSTM层的权重,防止在后续训练时更新嵌入层;二是它需要专门为给定任务定制,不同任务需要的最佳模型不同,不同任务可能不能使用同一个训练好的模型。
如果需要将它泛化到各自任务,就需要生成式预训练(GPT),它建立在transformer解码器的基础上,预训练一个用于表示文本序列的语言模型。
它使用一个线性输出层预测任务的标签,进行有监督训练,所以达到可以用到不可知任务的目的。(训练让其分类任务)
与ELMo需要冻结预训练模型的参数不同,GPT在学习下游任务时可以边训练边微调预训练参数。
虽然GPT模型在很多任务上都性能显著,但由于语言的自回归特性(根据前面的词预测下一个词),它只能从左向右看。
所以这里就引出了标题BERT,它是基于前两种方法(ELMo和GPT)结合而诞生的。
它结合了两种的优点,ELMo的双向性和GPT的多任务性。
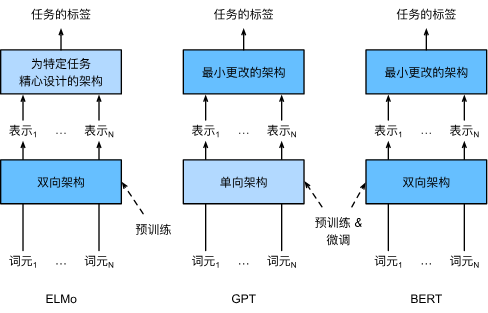
BERT使用双向transformer编码器表示架构生成词表式,然后和GPT一样后接一个任务标签分类模型,这样既结合了ELMo的双向编码,又结合了GPT的transformer微调和分类任务的线性输出层。
在自然语言处理中,有一些任务需要单个文本(情感识别),一些任务需要一对文本(翻译)。
所以我们可以设置既能传入一个文本又能传入一个文本对的方式。
方法就是设置标记<cls>和<sep>,如图,<cls>表示第一个句子的开头,<sep>表示第二个句子的开始和结束。

嵌入模型如上图所示,分为词元嵌入、段嵌入、位置嵌入。
- 词元嵌入是每一个词对应一个词向量,和之前的“上下文无关”差不多。
- 段嵌入只要对第一句和第二句嵌入,一对文本只需要两个嵌入结果。
- 位置嵌入是对每一个位置进行嵌入,需要结合上下文语境,区分一词多义。
三者相加就是最终嵌入。
模型代码:
#@save
class BERTEncoder(nn.Block):"""BERT编码器"""def __init__(self, vocab_size, num_hiddens, ffn_num_hiddens, num_heads,num_layers, dropout, max_len=1000, **kwargs):super(BERTEncoder, self).__init__(**kwargs)self.token_embedding = nn.Embedding(vocab_size, num_hiddens)self.segment_embedding = nn.Embedding(2, num_hiddens)self.blks = nn.Sequential()for _ in range(num_layers):self.blks.add(d2l.EncoderBlock(num_hiddens, ffn_num_hiddens, num_heads, dropout, True))# 在BERT中,位置嵌入是可学习的,因此我们创建一个足够长的位置嵌入参数self.pos_embedding = self.params.get('pos_embedding',shape=(1, max_len, num_hiddens))def forward(self, tokens, segments, valid_lens):# 在以下代码段中,X的形状保持不变:(批量大小,最大序列长度,num_hiddens)X = self.token_embedding(tokens) + self.segment_embedding(segments)X = X + self.pos_embedding.data(ctx=X.ctx)[:, :X.shape[1], :]for blk in self.blks:X = blk(X, valid_lens)return X可以直观的看到三个嵌入层:第一个嵌入层token_embedding是词元嵌入,一个词对应一个向量;第二个嵌入层segment_embedding是段嵌入,一句文本对应一个向量;第三个嵌入层pos_embedding是位置嵌入,依靠多层自注意力机制的编码器架构,架构包含多头自注意力、基于位置的前馈网络。
接下来进行预训练,包括两个任务:掩蔽语言模型、对下一句预测。
(这里不需要进行人工掩蔽和标注,有预训练语料库可以直接获取到,并且原始的BERT已经在大型数据库上进行了预训练)
1. 掩蔽语言模型
之前章节学习的掩蔽语言模型大都是掩蔽后面的词汇,根据前面的词预测,现在为了实现双向编码,需要随机掩蔽中间的词汇,根据上下文以自监督的方式预测。
因此,我们每次随机选取15%的词进行掩蔽,对这15%的词,可以简单的使用人造词元'<mask>'进行替换(只能在预训练中这样做,微调不能这么做,因为微调是将一个标注好的数据集用到特定任务上,不需要预测掩蔽词)。
在预测任务中对这15%的词可以:
- 80%将其替换为'<mask>'词元。
- 10%将其替换为随机词元。
- 10%不变。
替换为随机词元的目的是鼓励双向上下文编码不那么偏向于'<mask>'词元。
用代码实现掩蔽就是:
#@save
class MaskLM(nn.Block):"""BERT的掩蔽语言模型任务"""def __init__(self, vocab_size, num_hiddens, **kwargs):super(MaskLM, self).__init__(**kwargs)self.mlp = nn.Sequential()self.mlp.add(nn.Dense(num_hiddens, flatten=False, activation='relu'))self.mlp.add(nn.LayerNorm())self.mlp.add(nn.Dense(vocab_size, flatten=False))def forward(self, X, pred_positions):num_pred_positions = pred_positions.shape[1]pred_positions = pred_positions.reshape(-1)batch_size = X.shape[0]batch_idx = np.arange(0, batch_size)# 假设batch_size=2,num_pred_positions=3# 那么batch_idx是np.array([0,0,0,1,1,1])batch_idx = np.repeat(batch_idx, num_pred_positions)masked_X = X[batch_idx, pred_positions]masked_X = masked_X.reshape((batch_size, num_pred_positions, -1))mlm_Y_hat = self.mlp(masked_X)return mlm_Y_hat输入是文本的编码结果和需要预测的词元位置( [ 批量大小, 预测数量 ] ),输出是需要预测的位置的预测结果,使用一个多层感知机进行预测。
最后根据预测值和真实值的差距进行反向传播。
2. 预测下一句
之前说过,一些需要使用文本对的任务需要俩文本间的关系,这时候就要预测下一句。
这里使用比较简单的二分类模型,有一半句子的对应句子会被替换为其他随机句子,并标记“假”,剩下的句子不变,被标记为“真”。
实现代码也很简单,就是一个二分类模型。
#@save
class NextSentencePred(nn.Module):"""BERT的下一句预测任务"""def __init__(self, num_inputs, **kwargs):super(NextSentencePred, self).__init__(**kwargs)self.output = nn.Linear(num_inputs, 2)def forward(self, X):# X的形状:(batchsize,num_hiddens)return self.output(X)(我也不知道这里为什么不用softmax,而是每个句子用两个输出分别代表真和假)
总之:
encoded_X = torch.flatten(encoded_X, start_dim=1)
# NSP的输入形状:(batchsize,num_hiddens)
nsp = NextSentencePred(encoded_X.shape[-1])
nsp_Y_hat = nsp(encoded_X)
nsp_Y_hat.shape将编码后的句子展平为 [ 批量大小, 隐藏层大小*序列长度 ] ,之后再用模型预测输出真假,最后输出大小是 [ 2, 2 ] (分别代表批量大小和真假权重)
最后计算损失是这样(假设原本两个句子一假一真):
nsp_y = torch.tensor([0, 1])
nsp_l = loss(nsp_Y_hat, nsp_y)
nsp_l.shape最终将这一节的代码结合起来,包括三个东西:BERT编码器、mask模型、预测下一句模型。(计算损失是后两者的损失相加)
#@save
class BERTModel(nn.Module):"""BERT模型"""def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,ffn_num_hiddens, num_heads, num_layers, dropout,max_len=1000, key_size=768, query_size=768, value_size=768,hid_in_features=768, mlm_in_features=768,nsp_in_features=768):super(BERTModel, self).__init__()self.encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape,ffn_num_input, ffn_num_hiddens, num_heads, num_layers,dropout, max_len=max_len, key_size=key_size,query_size=query_size, value_size=value_size)self.hidden = nn.Sequential(nn.Linear(hid_in_features, num_hiddens),nn.Tanh())self.mlm = MaskLM(vocab_size, num_hiddens, mlm_in_features)self.nsp = NextSentencePred(nsp_in_features)def forward(self, tokens, segments, valid_lens=None,pred_positions=None):encoded_X = self.encoder(tokens, segments, valid_lens)if pred_positions is not None:mlm_Y_hat = self.mlm(encoded_X, pred_positions)else:mlm_Y_hat = None# 用于下一句预测的多层感知机分类器的隐藏层,0是“<cls>”标记的索引nsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0, :]))return encoded_X, mlm_Y_hat, nsp_Y_hat这段代码将三个模型拼起来了。
总之,BERT模型先使用双向架构(BERTEncoder)通过将三种嵌入相加获得词表式,再通过掩蔽语言模型和预测下一句结合不同任务需求,训练这些嵌入,提高模型在不同下游任务的适应能力。
14.9 用于预训练BERT的数据集
生成用于训练的数据集,需要两种数据集分别对应两种任务。
step1 导入数据集
首先导入数据集,选择了一个较小的语料库WikiText,对其进行预处理:
#@save
d2l.DATA_HUB['wikitext-2'] = ('https://s3.amazonaws.com/research.metamind.io/wikitext/''wikitext-2-v1.zip', '3c914d17d80b1459be871a5039ac23e752a53cbe')#@save
def _read_wiki(data_dir):file_name = os.path.join(data_dir, 'wiki.train.tokens')with open(file_name, 'r') as f:lines = f.readlines()# 大写字母转换为小写字母paragraphs = [line.strip().lower().split(' . ')for line in lines if len(line.split(' . ')) >= 2]random.shuffle(paragraphs)return paragraphs这个数据集有多行,每一行是一些句子,因为要进行下一句预测,所以保留至少有两句的行,并将单词转化为小写,并转化为列表。
step2 为两个预训练任务实现函数
1. 预测下一句的任务:
#@save
def _get_next_sentence(sentence, next_sentence, paragraphs):if random.random() < 0.5:is_next = Trueelse:# paragraphs是三重列表的嵌套next_sentence = random.choice(random.choice(paragraphs))is_next = Falsereturn sentence, next_sentence, is_next将50%的文本对下一个文本替换为随机段落的随机句子,并设置标签为false。
#@save
def _get_nsp_data_from_paragraph(paragraph, paragraphs, vocab, max_len):nsp_data_from_paragraph = []for i in range(len(paragraph) - 1):tokens_a, tokens_b, is_next = _get_next_sentence(paragraph[i], paragraph[i + 1], paragraphs)# 考虑1个'<cls>'词元和2个'<sep>'词元if len(tokens_a) + len(tokens_b) + 3 > max_len:continuetokens, segments = d2l.get_tokens_and_segments(tokens_a, tokens_b)nsp_data_from_paragraph.append((tokens, segments, is_next))return nsp_data_from_paragraph遍历每一个句子,相邻两个句子变成文本对并送入随机替换的函数中50%概率替换为随机句子(若句子对长度过长则舍去),最后返回的列表中每一个元素包含拼接在一起的句子、标签(是前一句还是后一句)、标签(是否是相邻句子)。
2. 掩蔽语言模型任务
#@save
def _replace_mlm_tokens(tokens, candidate_pred_positions, num_mlm_preds,vocab):# 为遮蔽语言模型的输入创建新的词元副本,其中输入可能包含替换的“<mask>”或随机词元mlm_input_tokens = [token for token in tokens]pred_positions_and_labels = []# 打乱后用于在遮蔽语言模型任务中获取15%的随机词元进行预测random.shuffle(candidate_pred_positions)for mlm_pred_position in candidate_pred_positions:if len(pred_positions_and_labels) >= num_mlm_preds:breakmasked_token = None# 80%的时间:将词替换为“<mask>”词元if random.random() < 0.8:masked_token = '<mask>'else:# 10%的时间:保持词不变if random.random() < 0.5:masked_token = tokens[mlm_pred_position]# 10%的时间:用随机词替换该词else:masked_token = random.choice(vocab.idx_to_token)mlm_input_tokens[mlm_pred_position] = masked_tokenpred_positions_and_labels.append((mlm_pred_position, tokens[mlm_pred_position]))return mlm_input_tokens, pred_positions_and_labels先构建一个将80%词元替换为掩码,剩下的20%中50%替换为随机其他词元,50%不变。
传入的是所有文本,只要对其中的15%执行上述操作,所以还要传入candidate_pred_positions代表可能需要进行操作的词元索引,打乱取前num_mlm_preds个单词进行操作,num_mlm_preds代表预测数量(15%的原文本单词数)。
#@save
def _get_mlm_data_from_tokens(tokens, vocab):candidate_pred_positions = []# tokens是一个字符串列表for i, token in enumerate(tokens):# 在遮蔽语言模型任务中不会预测特殊词元if token in ['<cls>', '<sep>']:continuecandidate_pred_positions.append(i)# 遮蔽语言模型任务中预测15%的随机词元num_mlm_preds = max(1, round(len(tokens) * 0.15))mlm_input_tokens, pred_positions_and_labels = _replace_mlm_tokens(tokens, candidate_pred_positions, num_mlm_preds, vocab)pred_positions_and_labels = sorted(pred_positions_and_labels,key=lambda x: x[0])pred_positions = [v[0] for v in pred_positions_and_labels]mlm_pred_labels = [v[1] for v in pred_positions_and_labels]return vocab[mlm_input_tokens], pred_positions, vocab[mlm_pred_labels]接着实现取15%的部分,输入的是一个单词列表,将单词列表中不是特殊词元<cls>、<sep>的加入候选列表中,调用函数进行掩蔽操作,将掩蔽位置按前后排序,最后返回掩蔽后的单词列表、掩蔽位置的序号、掩蔽位置原本的单词。
step3 将文本转化为预训练数据集
接下来还是定义辅助函数,目的是将<mask>词元附加到输入,使所有句子等长。
简单来说就是将上面实现的两个任务数据集的输出组合在一起,输入到这个函数中。
#@save
def _pad_bert_inputs(examples, max_len, vocab):max_num_mlm_preds = round(max_len * 0.15)all_token_ids, all_segments, valid_lens, = [], [], []all_pred_positions, all_mlm_weights, all_mlm_labels = [], [], []nsp_labels = []for (token_ids, pred_positions, mlm_pred_label_ids, segments,is_next) in examples:all_token_ids.append(torch.tensor(token_ids + [vocab['<pad>']] * (max_len - len(token_ids)), dtype=torch.long))all_segments.append(torch.tensor(segments + [0] * (max_len - len(segments)), dtype=torch.long))# valid_lens不包括'<pad>'的计数valid_lens.append(torch.tensor(len(token_ids), dtype=torch.float32))all_pred_positions.append(torch.tensor(pred_positions + [0] * (max_num_mlm_preds - len(pred_positions)), dtype=torch.long))# 填充词元的预测将通过乘以0权重在损失中过滤掉all_mlm_weights.append(torch.tensor([1.0] * len(mlm_pred_label_ids) + [0.0] * (max_num_mlm_preds - len(pred_positions)),dtype=torch.float32))all_mlm_labels.append(torch.tensor(mlm_pred_label_ids + [0] * (max_num_mlm_preds - len(mlm_pred_label_ids)), dtype=torch.long))nsp_labels.append(torch.tensor(is_next, dtype=torch.long))return (all_token_ids, all_segments, valid_lens, all_pred_positions,all_mlm_weights, all_mlm_labels, nsp_labels)输入examples是从两个任务数据集的输出,每个元素包含:
token_ids(输入样本的ID), 【掩蔽语言模型任务中】pred_positions(被掩蔽的位置), mlm_pred_label_ids(被掩盖位置的真实词元ID),【预测下一句任务中】 segments(标记单词属于前一句还是后一句), is_next(是否是相邻句子)。
上面的函数就是往这些后面接填充<mask>到最大长度,比如ID后添<pad>,pred_positions、mlm_pred_label_ids、segments后添 0 。
最后返回被填充的这些,还有每个文本的原始长度、被统计在一起的is_next列表。
接下来定义一个类将本节所有辅助函数结合起来:
#@save
class _WikiTextDataset(torch.utils.data.Dataset):def __init__(self, paragraphs, max_len):# 输入paragraphs[i]是代表段落的句子字符串列表;# 而输出paragraphs[i]是代表段落的句子列表,其中每个句子都是词元列表paragraphs = [d2l.tokenize(paragraph, token='word') for paragraph in paragraphs]sentences = [sentence for paragraph in paragraphsfor sentence in paragraph]self.vocab = d2l.Vocab(sentences, min_freq=5, reserved_tokens=['<pad>', '<mask>', '<cls>', '<sep>'])# 获取下一句子预测任务的数据examples = []for paragraph in paragraphs:examples.extend(_get_nsp_data_from_paragraph(paragraph, paragraphs, self.vocab, max_len))# 获取遮蔽语言模型任务的数据examples = [(_get_mlm_data_from_tokens(tokens, self.vocab)+ (segments, is_next))for tokens, segments, is_next in examples]# 填充输入(self.all_token_ids, self.all_segments, self.valid_lens,self.all_pred_positions, self.all_mlm_weights,self.all_mlm_labels, self.nsp_labels) = _pad_bert_inputs(examples, max_len, self.vocab)def __getitem__(self, idx):return (self.all_token_ids[idx], self.all_segments[idx],self.valid_lens[idx], self.all_pred_positions[idx],self.all_mlm_weights[idx], self.all_mlm_labels[idx],self.nsp_labels[idx])def __len__(self):return len(self.all_token_ids)初始化将输入段落列表转化为句子列表,生成词典,获取预测下一句数据集、掩蔽语言数据集,填充输入。
通过id可以查询对应句子信息,通过len可以查询所有句子数量。
最后设置加载数据集的函数:
#@save
def load_data_wiki(batch_size, max_len):"""加载WikiText-2数据集"""num_workers = d2l.get_dataloader_workers()data_dir = d2l.download_extract('wikitext-2', 'wikitext-2')paragraphs = _read_wiki(data_dir)train_set = _WikiTextDataset(paragraphs, max_len)train_iter = torch.utils.data.DataLoader(train_set, batch_size,shuffle=True, num_workers=num_workers)return train_iter, train_set.vocab就大功告成了。
14.10 预训练BERT
这一节利用上面写好的模型训练。
首先设置批次大小和文本长度,加载wiki数据集:
batch_size, max_len = 512, 64
train_iter, vocab = d2l.load_data_wiki(batch_size, max_len)定义模型,设置各种参数,定义损失函数:
net = d2l.BERTModel(len(vocab), num_hiddens=128, norm_shape=[128],ffn_num_input=128, ffn_num_hiddens=256, num_heads=2,num_layers=2, dropout=0.2, key_size=128, query_size=128,value_size=128, hid_in_features=128, mlm_in_features=128,nsp_in_features=128)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss()定义计算损失的辅助函数:
#@save
def _get_batch_loss_bert(net, loss, vocab_size, tokens_X,segments_X, valid_lens_x,pred_positions_X, mlm_weights_X,mlm_Y, nsp_y):# 前向传播_, mlm_Y_hat, nsp_Y_hat = net(tokens_X, segments_X,valid_lens_x.reshape(-1),pred_positions_X)# 计算遮蔽语言模型损失mlm_l = loss(mlm_Y_hat.reshape(-1, vocab_size), mlm_Y.reshape(-1)) *\mlm_weights_X.reshape(-1, 1)mlm_l = mlm_l.sum() / (mlm_weights_X.sum() + 1e-8)# 计算下一句子预测任务的损失nsp_l = loss(nsp_Y_hat, nsp_y)l = mlm_l + nsp_lreturn mlm_l, nsp_l, l前向传播只需要取后两个参数(即两个任务的结果),和真实值进行对比分别计算损失,最后相加返回。
最后定义训练函数:
def train_bert(train_iter, net, loss, vocab_size, devices, num_steps):net = nn.DataParallel(net, device_ids=devices).to(devices[0])trainer = torch.optim.Adam(net.parameters(), lr=0.01)step, timer = 0, d2l.Timer()animator = d2l.Animator(xlabel='step', ylabel='loss',xlim=[1, num_steps], legend=['mlm', 'nsp'])# 遮蔽语言模型损失的和,下一句预测任务损失的和,句子对的数量,计数metric = d2l.Accumulator(4)num_steps_reached = Falsewhile step < num_steps and not num_steps_reached:for tokens_X, segments_X, valid_lens_x, pred_positions_X,\mlm_weights_X, mlm_Y, nsp_y in train_iter:tokens_X = tokens_X.to(devices[0])segments_X = segments_X.to(devices[0])valid_lens_x = valid_lens_x.to(devices[0])pred_positions_X = pred_positions_X.to(devices[0])mlm_weights_X = mlm_weights_X.to(devices[0])mlm_Y, nsp_y = mlm_Y.to(devices[0]), nsp_y.to(devices[0])trainer.zero_grad()timer.start()mlm_l, nsp_l, l = _get_batch_loss_bert(net, loss, vocab_size, tokens_X, segments_X, valid_lens_x,pred_positions_X, mlm_weights_X, mlm_Y, nsp_y)l.backward()trainer.step()metric.add(mlm_l, nsp_l, tokens_X.shape[0], 1)timer.stop()animator.add(step + 1,(metric[0] / metric[3], metric[1] / metric[3]))step += 1if step == num_steps:num_steps_reached = Truebreakprint(f'MLM loss {metric[0] / metric[3]:.3f}, 'f'NSP loss {metric[1] / metric[3]:.3f}')print(f'{metric[2] / timer.sum():.1f} sentence pairs/sec on 'f'{str(devices)}')调用这个函数进行训练:
train_bert(train_iter, net, loss, len(vocab), devices, 50)可以分别观察两个任务的损失:
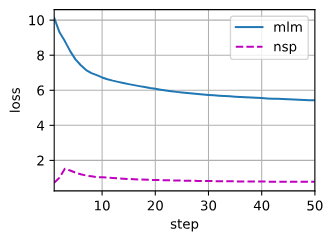
训练结束就可以用训练好的模型表示文本啦。
依旧构建一个辅助函数,用于输出传入文本对应的词表式:
def get_bert_encoding(net, tokens_a, tokens_b=None):tokens, segments = d2l.get_tokens_and_segments(tokens_a, tokens_b)token_ids = torch.tensor(vocab[tokens], device=devices[0]).unsqueeze(0)segments = torch.tensor(segments, device=devices[0]).unsqueeze(0)valid_len = torch.tensor(len(tokens), device=devices[0]).unsqueeze(0)encoded_X, _, _ = net(token_ids, segments, valid_len)return encoded_X举个例子:
tokens_a = ['a', 'crane', 'is', 'flying']
encoded_text = get_bert_encoding(net, tokens_a)
# 词元:'<cls>','a','crane','is','flying','<sep>'
encoded_text_cls = encoded_text[:, 0, :]
encoded_text_crane = encoded_text[:, 2, :]
encoded_text.shape, encoded_text_cls.shape, encoded_text_crane[0][:3]
再举一个例子:
tokens_a, tokens_b = ['a', 'crane', 'driver', 'came'], ['he', 'just', 'left']
encoded_pair = get_bert_encoding(net, tokens_a, tokens_b)
# 词元:'<cls>','a','crane','driver','came','<sep>','he','just',
# 'left','<sep>'
encoded_pair_cls = encoded_pair[:, 0, :]
encoded_pair_crane = encoded_pair[:, 2, :]
encoded_pair.shape, encoded_pair_cls.shape, encoded_pair_crane[0][:3]
两个句子中的单词crane的含义不同,结果显示这个单词对应的向量不同。
这说明BERT是“上下文敏感”的。