【AI】Ubuntu 22.04 evalscope 模型评测 Qwen3-4B-FP8
安装evalscope
mkdir evalscope
cd evalscope/
python3 -m venv venv
source venv/bin/activate
pip install 'evalscope[app,perf]' -U -i https://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.compip install tiktoken omegaconf -i https://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com下载通用评测数据集(暂时未用上)
pip install -U modelscopemodelscope download --dataset modelscope/mmlu --local_dir /data/ai/evalscope_data/mmlu
modelscope download --dataset modelscope/gsm8k --local_dir /data/ai/evalscope_data/gsm8k
modelscope download --dataset modelscope/human_eval --local_dir /data/ai/evalscope_data/human_eval
本地部署Qwen3-4B-FP8
modelscope download --model Qwen/Qwen3-4B-FP8
vllm serve /home/yeqiang/.cache/modelscope/hub/models/Qwen/Qwen3-4B-FP8 --served-model-name Qwen3-4B-FP8 --port 8000 --dtype auto --gpu-memory-utilization 0.8 --max-model-len 40960 --tensor-parallel-size 1编辑评测脚本(采用EvalScope-Qwen3-Test数据集)
eval_qwen3_mmlu.py
from evalscope import TaskConfig, run_task
task_cfg = TaskConfig(model='Qwen3-4B-FP8',api_url='http://localhost:8000/v1/chat/completions',eval_type='service',datasets=['data_collection',],dataset_args={'data_collection': {'dataset_id': 'modelscope/EvalScope-Qwen3-Test','filters': {'remove_until': '</think>'} # 过滤掉思考的内容}},eval_batch_size=128,generation_config={'max_tokens': 30000, # 最大生成token数,建议设置为较大值避免输出截断'temperature': 0.6, # 采样温度 (qwen 报告推荐值)'top_p': 0.95, # top-p采样 (qwen 报告推荐值)'top_k': 20, # top-k采样 (qwen 报告推荐值)'n': 1, # 每个请求产生的回复数量},timeout=60000, # 超时时间stream=True, # 是否使用流式输出limit=100, # 设置为100条数据进行测试
)run_task(task_cfg=task_cfg)
执行评测
(venv) yeqiang@yeqiang-Default-string:/data/ai/evalscope$ python eval_qwen3_mmlu.py
2025-05-06 22:44:04,363 - evalscope - INFO - Args: Task config is provided with TaskConfig type.
ANTLR runtime and generated code versions disagree: 4.9.3!=4.7.2
ANTLR runtime and generated code versions disagree: 4.9.3!=4.7.2
ANTLR runtime and generated code versions disagree: 4.9.3!=4.7.2
ANTLR runtime and generated code versions disagree: 4.9.3!=4.7.2
2025-05-06 22:44:06,473 - evalscope - INFO - Loading dataset from modelscope: > dataset_name: modelscope/EvalScope-Qwen3-Test
Downloading Dataset to directory: /home/yeqiang/.cache/modelscope/hub/datasets/modelscope/EvalScope-Qwen3-Test
2025-05-06 22:44:08,753 - evalscope - INFO - Dump task config to ./outputs/20250506_224404/configs/task_config_7d0e13.yaml
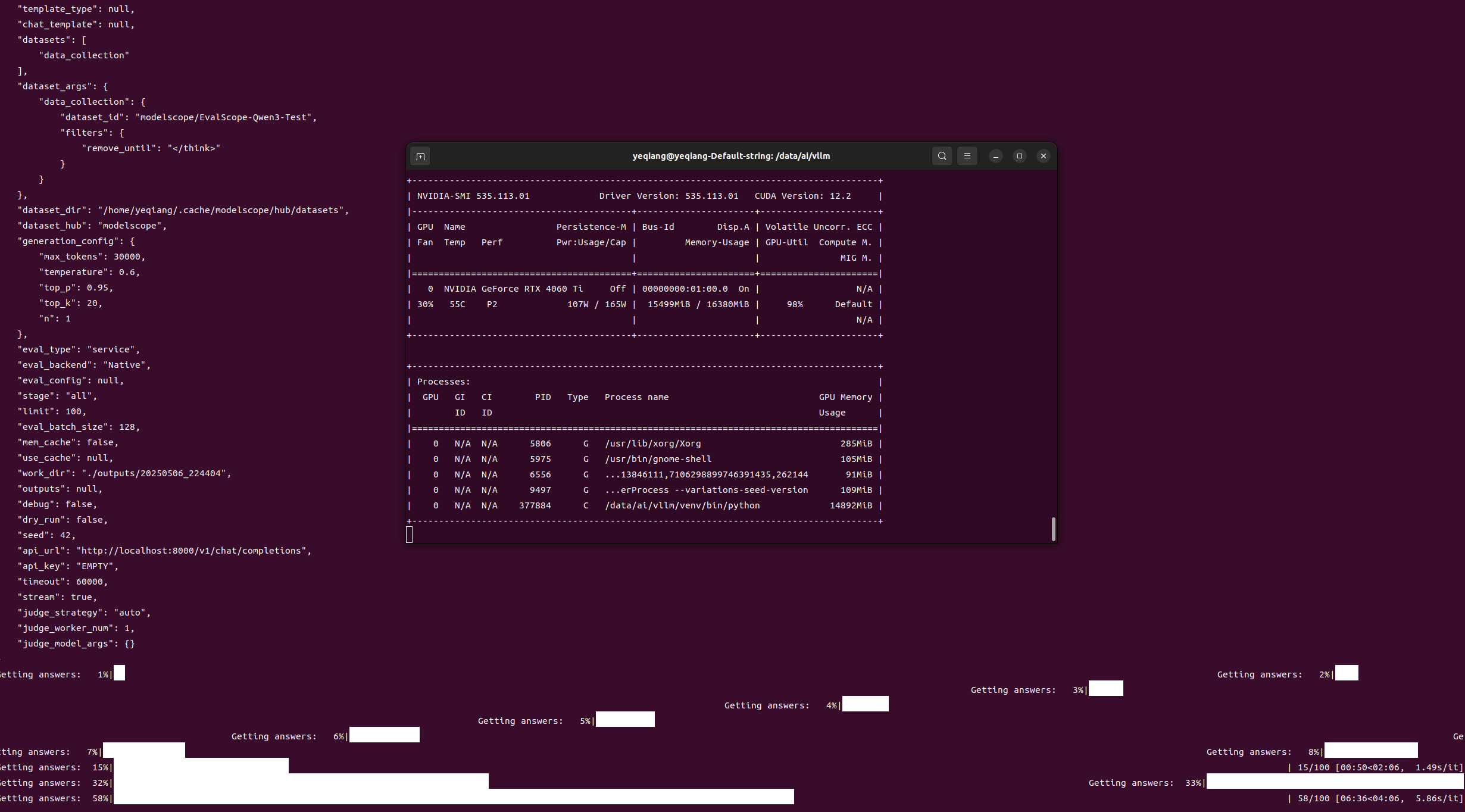
2025-05-06 22:44:08,755 - evalscope - INFO - {"model": "Qwen3-4B-FP8","model_id": "Qwen3-4B-FP8","model_args": {"revision": "master","precision": "torch.float16"},"model_task": "text_generation","template_type": null,"chat_template": null,"datasets": ["data_collection"],"dataset_args": {"data_collection": {"dataset_id": "modelscope/EvalScope-Qwen3-Test","filters": {"remove_until": "</think>"}}},"dataset_dir": "/home/yeqiang/.cache/modelscope/hub/datasets","dataset_hub": "modelscope","generation_config": {"max_tokens": 30000,"temperature": 0.6,"top_p": 0.95,"top_k": 20,"n": 1},"eval_type": "service","eval_backend": "Native","eval_config": null,"stage": "all","limit": 100,"eval_batch_size": 128,"mem_cache": false,"use_cache": null,"work_dir": "./outputs/20250506_224404","outputs": null,"debug": false,"dry_run": false,"seed": 42,"api_url": "http://localhost:8000/v1/chat/completions","api_key": "EMPTY","timeout": 60000,"stream": true,"judge_strategy": "auto","judge_worker_num": 1,"judge_model_args": {}
}Getting answers: 15%|████████████████████████████████▊ [00:50<02:06, 1.49s/it]
Getting answers: 32%|█████████████████████████████████████████████████████████████████████
Getting answers: 33%|█████████████████████████████████████████████████████████████████████| 33/100 [02:28<07:44, 6.93s/it]nvidia-smi
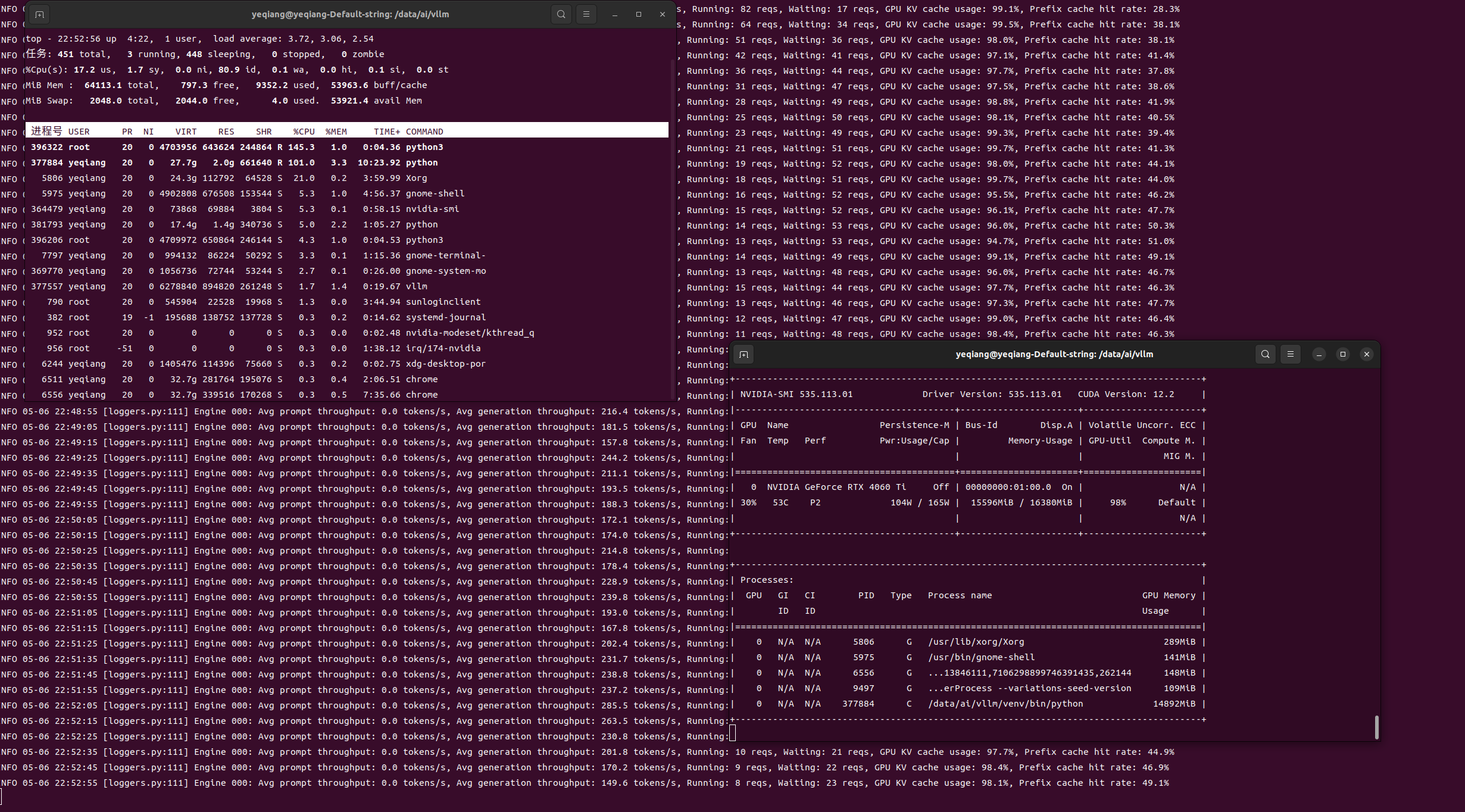
vllm服务状态
报告
2025-05-06 23:13:37,099 - evalscope - INFO - subset_level Report:
+-------------+-------------------------+-----------------+----------------------------+---------------+-------+
| task_type | metric | dataset_name | subset_name | average_score | count |
+-------------+-------------------------+-----------------+----------------------------+---------------+-------+
| exam | AverageAccuracy | mmlu_pro | health | 0.6667 | 9 |
| exam | AverageAccuracy | mmlu_pro | math | 1.0 | 7 |
| exam | AverageAccuracy | mmlu_pro | engineering | 0.6667 | 6 |
| exam | AverageAccuracy | mmlu_pro | chemistry | 0.5 | 6 |
| exam | AverageAccuracy | mmlu_pro | psychology | 0.6667 | 6 |
| exam | AverageAccuracy | mmlu_pro | biology | 0.8 | 5 |
| exam | AverageAccuracy | mmlu_pro | law | 0.2 | 5 |
| instruction | prompt_level_strict_acc | ifeval | default | 0.75 | 4 |
| instruction | inst_level_strict_acc | ifeval | default | 0.75 | 4 |
| exam | AverageAccuracy | mmlu_pro | physics | 0.75 | 4 |
| exam | AverageAccuracy | mmlu_pro | other | 0.5 | 4 |
| instruction | prompt_level_loose_acc | ifeval | default | 1.0 | 4 |
| exam | AverageAccuracy | mmlu_pro | computer science | 1.0 | 4 |
| instruction | inst_level_loose_acc | ifeval | default | 1.0 | 4 |
| exam | AverageAccuracy | mmlu_pro | business | 0.6667 | 3 |
| exam | AverageAccuracy | mmlu_pro | history | 0.6667 | 3 |
| exam | AverageAccuracy | mmlu_pro | philosophy | 0.6667 | 3 |
| exam | AverageAccuracy | mmlu_redux | prehistory | 1.0 | 2 |
| exam | AverageAccuracy | mmlu_pro | economics | 0.5 | 2 |
| exam | AverageAccuracy | ceval | education_science | 1.0 | 1 |
| exam | AverageAccuracy | ceval | law | 0.0 | 1 |
| exam | AverageAccuracy | ceval | tax_accountant | 0.0 | 1 |
| exam | AverageAccuracy | iquiz | EQ | 1.0 | 1 |
| exam | AverageAccuracy | ceval | high_school_biology | 1.0 | 1 |
| code | Pass@1 | live_code_bench | v5_v6 | 0.0 | 1 |
| exam | AverageAccuracy | ceval | basic_medicine | 1.0 | 1 |
| exam | AverageAccuracy | mmlu_redux | anatomy | 1.0 | 1 |
| exam | AverageAccuracy | mmlu_redux | college_computer_science | 1.0 | 1 |
| exam | AverageAccuracy | mmlu_redux | college_mathematics | 1.0 | 1 |
| exam | AverageAccuracy | mmlu_redux | abstract_algebra | 1.0 | 1 |
| exam | AverageAccuracy | mmlu_redux | high_school_mathematics | 1.0 | 1 |
| exam | AverageAccuracy | mmlu_redux | high_school_macroeconomics | 1.0 | 1 |
| exam | AverageAccuracy | mmlu_redux | high_school_chemistry | 0.0 | 1 |
| exam | AverageAccuracy | mmlu_redux | high_school_biology | 1.0 | 1 |
| exam | AverageAccuracy | mmlu_redux | conceptual_physics | 0.0 | 1 |
| exam | AverageAccuracy | mmlu_redux | high_school_world_history | 0.0 | 1 |
| exam | AverageAccuracy | mmlu_redux | miscellaneous | 1.0 | 1 |
| exam | AverageAccuracy | mmlu_redux | medical_genetics | 1.0 | 1 |
| exam | AverageAccuracy | mmlu_redux | virology | 0.0 | 1 |
| exam | AverageAccuracy | mmlu_redux | security_studies | 1.0 | 1 |
| exam | AverageAccuracy | mmlu_redux | professional_medicine | 0.0 | 1 |
| exam | AverageAccuracy | mmlu_redux | moral_scenarios | 1.0 | 1 |
| exam | AverageAccuracy | mmlu_redux | world_religions | 0.0 | 1 |
| knowledge | AveragePass@1 | gpqa | gpqa_diamond | 1.0 | 1 |
| math | AveragePass@1 | math_500 | Level 3 | 1.0 | 1 |
| math | AveragePass@1 | math_500 | Level 5 | 1.0 | 1 |
+-------------+-------------------------+-----------------+----------------------------+---------------+-------+
2025-05-06 23:13:37,099 - evalscope - INFO - dataset_level Report:
+-------------+-------------------------+-----------------+---------------+-------+
| task_type | metric | dataset_name | average_score | count |
+-------------+-------------------------+-----------------+---------------+-------+
| exam | AverageAccuracy | mmlu_pro | 0.6716 | 67 |
| exam | AverageAccuracy | mmlu_redux | 0.6842 | 19 |
| exam | AverageAccuracy | ceval | 0.6 | 5 |
| instruction | prompt_level_loose_acc | ifeval | 1.0 | 4 |
| instruction | prompt_level_strict_acc | ifeval | 0.75 | 4 |
| instruction | inst_level_loose_acc | ifeval | 1.0 | 4 |
| instruction | inst_level_strict_acc | ifeval | 0.75 | 4 |
| math | AveragePass@1 | math_500 | 1.0 | 2 |
| code | Pass@1 | live_code_bench | 0.0 | 1 |
| exam | AverageAccuracy | iquiz | 1.0 | 1 |
| knowledge | AveragePass@1 | gpqa | 1.0 | 1 |
+-------------+-------------------------+-----------------+---------------+-------+
2025-05-06 23:13:37,099 - evalscope - INFO - task_level Report:
+-------------+-------------------------+---------------+-------+
| task_type | metric | average_score | count |
+-------------+-------------------------+---------------+-------+
| exam | AverageAccuracy | 0.6739 | 92 |
| instruction | inst_level_loose_acc | 1.0 | 4 |
| instruction | inst_level_strict_acc | 0.75 | 4 |
| instruction | prompt_level_loose_acc | 1.0 | 4 |
| instruction | prompt_level_strict_acc | 0.75 | 4 |
| math | AveragePass@1 | 1.0 | 2 |
| code | Pass@1 | 0.0 | 1 |
| knowledge | AveragePass@1 | 1.0 | 1 |
+-------------+-------------------------+---------------+-------+
2025-05-06 23:13:37,100 - evalscope - INFO - tag_level Report:
+------+-------------------------+---------------+-------+
| tags | metric | average_score | count |
+------+-------------------------+---------------+-------+
| en | AverageAccuracy | 0.6744 | 86 |
| zh | AverageAccuracy | 0.6667 | 6 |
| en | inst_level_strict_acc | 0.75 | 4 |
| en | inst_level_loose_acc | 1.0 | 4 |
| en | prompt_level_loose_acc | 1.0 | 4 |
| en | prompt_level_strict_acc | 0.75 | 4 |
| en | AveragePass@1 | 1.0 | 3 |
| en | Pass@1 | 0.0 | 1 |
+------+-------------------------+---------------+-------+
2025-05-06 23:13:37,100 - evalscope - INFO - category_level Report:
+-----------+--------------+-------------------------+---------------+-------+
| category0 | category1 | metric | average_score | count |
+-----------+--------------+-------------------------+---------------+-------+
| Qwen3 | English | AverageAccuracy | 0.6744 | 86 |
| Qwen3 | Chinese | AverageAccuracy | 0.6667 | 6 |
| Qwen3 | English | inst_level_loose_acc | 1.0 | 4 |
| Qwen3 | English | inst_level_strict_acc | 0.75 | 4 |
| Qwen3 | English | prompt_level_strict_acc | 0.75 | 4 |
| Qwen3 | English | prompt_level_loose_acc | 1.0 | 4 |
| Qwen3 | Math&Science | AveragePass@1 | 1.0 | 3 |
| Qwen3 | Code | Pass@1 | 0.0 | 1 |
+-----------+--------------+-------------------------+---------------+-------+
参考
https://evalscope.readthedocs.io/zh-cn/latest/best_practice/qwen3.html