动手学深度学习12.1. 编译器和解释器-笔记练习(PyTorch)
以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。
本节课程地址:无
本节教材地址:12.1. 编译器和解释器 — 动手学深度学习 2.0.0 documentation
本节开源代码:...>d2l-zh>pytorch>chapter_optimization>hybridize.ipynb
编译器和解释器
目前为止,本书主要关注的是命令式编程(imperative programming)。 命令式编程使用诸如print、“+”和if之类的语句来更改程序的状态。 考虑下面这段简单的命令式程序:
def add(a, b):return a + bdef fancy_func(a, b, c, d):e = add(a, b)f = add(c, d)g = add(e, f)return gprint(fancy_func(1, 2, 3, 4))输出结果:
10
Python是一种解释型语言(interpreted language)。因此,当对上面的fancy_func函数求值时,它按顺序执行函数体的操作。也就是说,它将通过对e = add(a, b)求值,并将结果存储为变量e,从而更改程序的状态。接下来的两个语句f = add(c, d)和g = add(e, f)也将执行类似地操作,即执行加法计算并将结果存储为变量。 图12.1.1 说明了数据流。
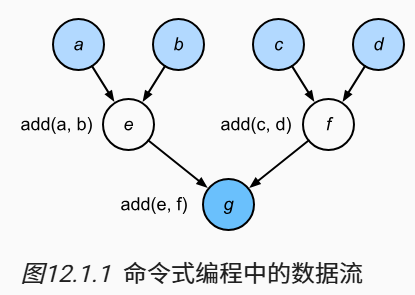
尽管命令式编程很方便,但可能效率不高。一方面原因,Python会单独执行这三个函数的调用,而没有考虑add函数在fancy_func中被重复调用。如果在一个GPU(甚至多个GPU)上执行这些命令,那么Python解释器产生的开销可能会非常大。此外,它需要保存e和f的变量值,直到fancy_func中的所有语句都执行完毕。这是因为程序不知道在执行语句e = add(a, b)和f = add(c, d)之后,其他部分是否会使用变量e和f。
符号式编程
考虑另一种选择符号式编程(symbolic programming),即代码通常只在完全定义了过程之后才执行计算。这个策略被多个深度学习框架使用,包括Theano和TensorFlow(后者已经获得了命令式编程的扩展)。一般包括以下步骤:
- 定义计算流程;
- 将流程编译成可执行的程序;
- 给定输入,调用编译好的程序执行。
这将允许进行大量的优化。首先,在大多数情况下,我们可以跳过Python解释器。从而消除因为多个更快的GPU与单个CPU上的单个Python线程搭配使用时产生的性能瓶颈。其次,编译器可以将上述代码优化和重写为print((1 + 2) + (3 + 4))甚至print(10)。因为编译器在将其转换为机器指令之前可以看到完整的代码,所以这种优化是可以实现的。例如,只要某个变量不再需要,编译器就可以释放内存(或者从不分配内存),或者将代码转换为一个完全等价的片段。下面,我们将通过模拟命令式编程来进一步了解符号式编程的概念。
def add_():return '''
def add(a, b):return a + b
'''def fancy_func_():return '''
def fancy_func(a, b, c, d):e = add(a, b)f = add(c, d)g = add(e, f)return g
'''def evoke_():return add_() + fancy_func_() + 'print(fancy_func(1, 2, 3, 4))'prog = evoke_()
print(prog)
# compile函数将字符串prog编译为代码对象
# 第一个参数是代码字符串,第二个参数是文件名(空字符串意味着代码不是从文件中读取的),
# 第三个参数是模式,'exec'表示代码是一个可执行的程序
y = compile(prog, '', 'exec')
# 用exec函数执行编译后的代码对象
exec(y)输出结果:
def add(a, b):
return a + b
def fancy_func(a, b, c, d):
e = add(a, b)
f = add(c, d)
g = add(e, f)
return g
print(fancy_func(1, 2, 3, 4))
10
命令式(解释型)编程和符号式编程的区别如下:
- 命令式编程更容易使用。在Python中,命令式编程的大部分代码都是简单易懂的。命令式编程也更容易调试,这是因为无论是获取和打印所有的中间变量值,或者使用Python的内置调试工具都更加简单;
- 符号式编程运行效率更高,更易于移植。符号式编程更容易在编译期间优化代码,同时还能够将程序移植到与Python无关的格式中,从而允许程序在非Python环境中运行,避免了任何潜在的与Python解释器相关的性能问题。
混合式编程
历史上,大部分深度学习框架都在命令式编程与符号式编程之间进行选择。例如,Theano、TensorFlow(灵感来自前者)、Keras和CNTK采用了符号式编程。相反地,Chainer和PyTorch采取了命令式编程。在后来的版本更新中,TensorFlow2.0和Keras增加了命令式编程。
如上所述,PyTorch是基于命令式编程并且使用动态计算图。为了能够利用符号式编程的可移植性和效率,开发人员思考能否将这两种编程模型的优点结合起来,于是就产生了torchscript。torchscript允许用户使用纯命令式编程进行开发和调试,同时能够将大多数程序转换为符号式程序,以便在需要产品级计算性能和部署时使用。
Sequential的混合式编程
要了解混合式编程的工作原理,最简单的方法是考虑具有多层的深层网络。按照惯例,Python解释器需要执行所有层的代码来生成一条指令,然后将该指令转发到CPU或GPU。对于单个的(快速的)计算设备,这不会导致任何重大问题。另一方面,如果我们使用先进的8-GPU服务器,比如AWS P3dn.24xlarge实例,Python将很难让所有的GPU都保持忙碌。在这里,瓶颈是单线程的Python解释器。让我们看看如何通过将Sequential替换为HybridSequential来解决代码中这个瓶颈。首先,我们定义一个简单的多层感知机。
import torch
from torch import nn
from d2l import torch as d2l# 生产网络的工厂模式
def get_net():net = nn.Sequential(nn.Linear(512, 256),nn.ReLU(),nn.Linear(256, 128),nn.ReLU(),nn.Linear(128, 2))return netx = torch.randn(size=(1, 512))
net = get_net()
net(x)输出结果:
tensor([[ 0.0913, -0.0081]], grad_fn=<AddmmBackward0>)
通过使用torch.jit.script函数来转换模型,我们就有能力编译和优化多层感知机中的计算,而模型的计算结果保持不变。
net = torch.jit.script(net)
net(x)输出结果:
tensor([[ 0.0913, -0.0081]], grad_fn=<AddmmBackward0>)
我们编写与之前相同的代码,再使用torch.jit.script简单地转换模型,当完成这些任务后,网络就将得到优化(我们将在下面对性能进行基准测试)。
通过混合式编程加速
为了证明通过编译获得了性能改进,我们比较了混合编程前后执行net(x)所需的时间。让我们先定义一个度量时间的类,它在本章中在衡量(和改进)模型性能时将非常有用。
#@save
class Benchmark:"""用于测量运行时间"""def __init__(self, description='Done'):self.description = descriptiondef __enter__(self):self.timer = d2l.Timer()return selfdef __exit__(self, *args):print(f'{self.description}: {self.timer.stop():.4f} sec')现在我们可以调用网络两次,一次使用torchscript,一次不使用torchscript。
net = get_net()
with Benchmark('无torchscript'):for i in range(1000): net(x)net = torch.jit.script(net)
with Benchmark('有torchscript'):for i in range(1000): net(x)输出结果:
无torchscript: 1.6907 sec
有torchscript: 1.6595 sec
如以上结果所示,在nn.Sequential的实例被函数torch.jit.script脚本化后,通过使用符号式编程提高了计算性能。
序列化
编译模型的好处之一是我们可以将模型及其参数序列化(保存)到磁盘。这允许这些训练好的模型部署到其他设备上,并且还能方便地使用其他前端编程语言。同时,通常编译模型的代码执行速度也比命令式编程更快。让我们看看save的实际功能。
net.save('my_mlp')
!ls -lh my_mlp*输出结果:
-rw-rw-r--. 1 huida SharedUsers 652K May 6 14:12 my_mlp
小结
- 命令式编程使得新模型的设计变得容易,因为可以依据控制流编写代码,并拥有相对成熟的Python软件生态。
- 符号式编程要求我们先定义并且编译程序,然后再执行程序,其好处是提高了计算性能。
练习
- 回顾前几章中感兴趣的模型,能提高它们的计算性能吗?
解:
以LeNet模型为例,使用torch.jit.script函数可以提高其网络计算性能。
代码如下:
# LeNet
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),nn.Linear(120, 84), nn.Sigmoid(),nn.Linear(84, 10))X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)with Benchmark('无torchscript'):for i in range(1000): net(X)net = torch.jit.script(net)
with Benchmark('有torchscript'):for i in range(1000): net(X)输出结果:
无torchscript: 3.2212 sec
有torchscript: 2.8837 sec