机器学习day4-Knn+交叉验证api练习(预测facebook签到位置)
数据集:FackebookV : 预测
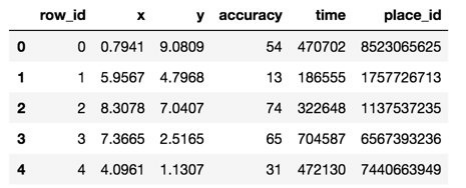
row id:签⼊事件的id
x y:坐标
accuracy: 准确度,定位精度
time: 时间戳
place_id: 签到的位置,需要预测的内容
具体步骤:
# 1.获取数据集
# 2.基本数据处理
# 2.1 缩⼩数据范围
# 2.2 选择时间特征
# 2.3 去掉签到较少的地⽅
# 2.4 确定特征值和⽬标值
# 2.5 分割数据集
# 3.特征工程 -- 特征预处理(标准化)
# 4.机器学习 -- knn+cv
# 5.模型评估代码如下:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV# 1.获取数据集
data = pd.read_csv('./train.csv/train.csv')
#print(data.shape)# 2.基本数据处理
# 2.1 缩⼩数据范围
data = data.query("x > 5.0 & x < 5.5 & y > 5.0 & y < 5.5")
#print(data.shape)# 2.2 选择时间特征
# 将时间戳转换为datetime
time = pd.to_datetime(data["time"], unit="s")
# 创建DatetimeIndex
time = pd.DatetimeIndex(time)
# 添加时间特征
data["day"] = time.day
data["hour"] = time.hour
data["weekday"] = time.weekday
#print(data.head())# 2.3 去掉签到较少的地⽅
place_count = data["place_id"].value_counts() # 统计每个place_id出现的次数
place_count = place_count[place_count > 3] # 只保留出现次数大于4的place_id
data = data[data["place_id"].isin(place_count.index)] # 只保留出现次数大于4的place_id
#print(data.shape)# 2.4 确定特征值和⽬标值
x = data[["x", "y", "accuracy", "day", "hour", "weekday"]]
y = data["place_id"]# 2.5 分割数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25, random_state=22)# 3.特征工程 -- 特征预处理(标准化)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)# 4.机器学习 -- knn+cv
estimator = KNeighborsClassifier()# 4.1 交叉验证,网格搜索
param_grid = {"n_neighbors": [1, 3, 5, 7, 9, 11]}
estimator = GridSearchCV(estimator, param_grid=param_grid, cv=4) # 交叉验证
estimator.fit(x_train, y_train)# 5.模型评估
# 5.1 准确率
score = estimator.score(x_test, y_test)
print("预测准确率:", score)
# 5.2 预测结果
y_pre = estimator.predict(x_test)
print('预测值是:', y_pre)
# 5.3 其他结果输出
print('最好的模型是:', estimator.best_estimator_)
print('最好的结果是:', estimator.best_score_)运行结果
(Pytorch) c:\Users\Wennight531\Desktop\机器学习\day4>cd c:/Users/Wennight531/Desktop/机器学习/day4(Pytorch) c:\Users\Wennight531\Desktop\机器学习\day4>D:/Anaconda/envs/Pytorch/python.exe c:/Users/Wennight531/Desktop/机器学习/day4/facebook_v.py
(73649, 9)
D:\Anaconda\envs\Pytorch\lib\site-packages\sklearn\model_selection\_split.py:725: UserWarning: The least populated class in y has only 1 members, which is less than n_splits=4.warnings.warn(
预测准确率: 0.35588986042469994
预测值是: [7030992969 8318971683 2682286453 ... 2766213441 9106759689 4774756673]
最好的模型是: KNeighborsClassifier(n_neighbors=7)
最好的结果是: 0.34459410529364903