深度学习·经典模型·VisionTransformer
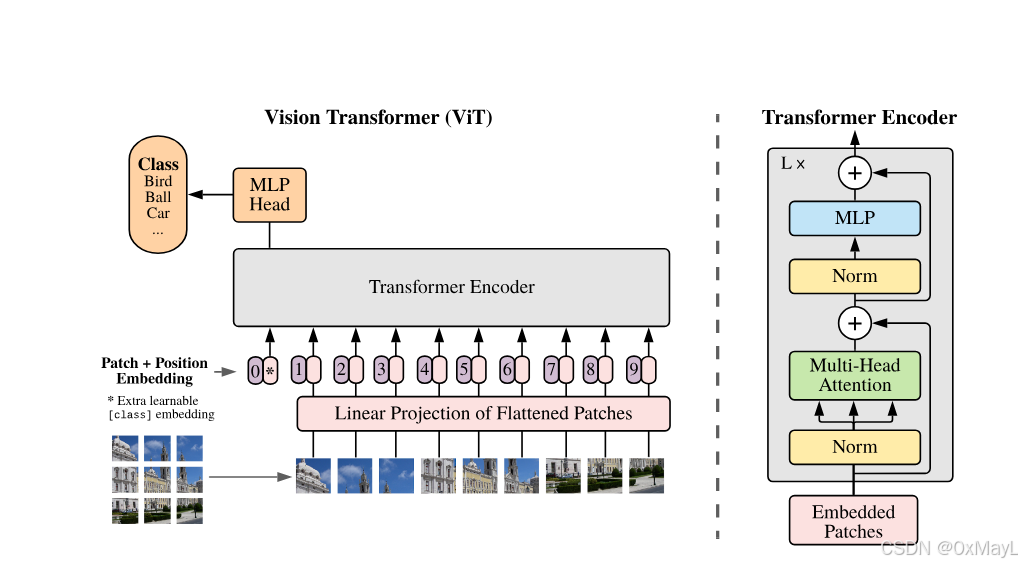
VIT
- embedding处理与标准的Transformer不同,其他基本一致
Embedding
- Graph: ( H , W , C ) (H,W,C) (H,W,C)
-
Patch: ( N , P 2 C ) (N,P^2C) (N,P2C),其中 N = H ∗ W P 2 N=\frac{H*W}{P^2} N=P2H∗W, P P P是patch的大小
- 注意的是,论文了保留与Bert的一致性,加上了
<class>这一个token,
例子
例如: ( 224 , 224 ) (224,224) (224,224)的图片,patch的大小为 ( 16 , 16 ) (16,16) (16,16),被embedding为 ( 196 = 224 ∗ 224 16 ∗ 16 , 768 = ( 16 ∗ 16 ∗ 3 ) ) (196=\frac{224*224}{16*16},768=(16*16*3)) (196=16∗16224∗224,768=(16∗16∗3))的图片,加上<class>变为 ( 197 , 768 ) (197,768) (197,768),然后经过模型输出结果。
其他结构与Transformer保持一致
- 不再赘述
特性分析
缺乏归纳偏置
- 归纳偏置:论文中指的是平移不变性,翻译相等性。这些是CNN特有的归纳性质,可以理解为一种先验知识,可以帮助模型更好的学习。
Inductive bias. We note that Vision Transformer has much less image-specific inductive bias than CNNs. In CNNs, locality, two-dimensional neighborhood structure, and translation equivariance are baked into each layer throughout the whole model. In ViT, only MLP layers are local and translationally equivariant, while the self-attention layers are global. The two-dimensional neighborhood structure is used very sparingly: in the beginning of the model by cutting the image into patches and at fine-tuning time for adjusting the position embeddings for images of different resolution (as described below). Other than that, the position embeddings at initialization time carry no information about the 2D positions of the patches and all spatial relations between the patches have to be learned from scratch.
🔤我们注意到 Vision Transformer 的图像特异性电感偏差比 CNN 小得多。在 CNN 中,局部性、二维邻域结构和平移等方差被烘焙到整个模型的每一层中🔤
位置编码的特殊性
- 图像是2D的,所以自然而然地考虑位置编码是否需要是2D的?
- 论文用实验证明:1D的位置编码足够VIT可以学习到图像这种特殊的位置关系。
数据集的偏好
- VIT相比CNN在小数据集上表现不佳:论文解释将原因归咎于缺乏归纳偏置。
- 大数据上VIT比CNN更好.
参考文献
@misc{dosovitskiyImageWorth16x162021,title = {An {{Image}} Is {{Worth}} 16x16 {{Words}}: {{Transformers}} for {{Image Recognition}} at {{Scale}}},shorttitle = {An {{Image}} Is {{Worth}} 16x16 {{Words}}},author = {Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},year = {2021},number = {arXiv:2010.11929},eprint = {2010.11929},primaryclass = {cs},publisher = {arXiv},doi = {10.48550/arXiv.2010.11929},archiveprefix = {arXiv}
}