Ollama大模型 本地部署+使用教程
一、Ollama安装步骤
1. 点击下方链接进入Ollama官方下载页面
Download Ollama on Windows
2. 选择自己的操作系统后,点击Download下载,然后点击exe文件的安装包,点击Install
3. 任务栏有Ollama图标代表安装成功
4. 进入Ollama官网,选择大模型
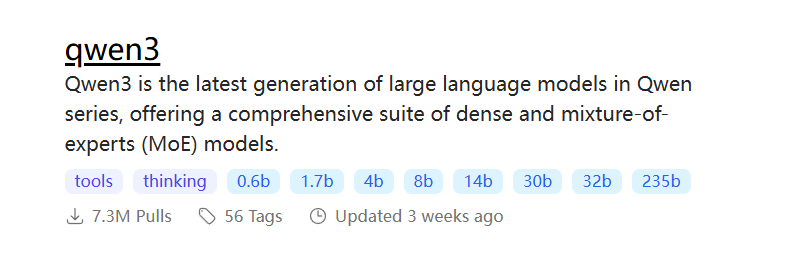
5. 选择一个想要本地部署的大模型和版本(版本自己根据需求选)
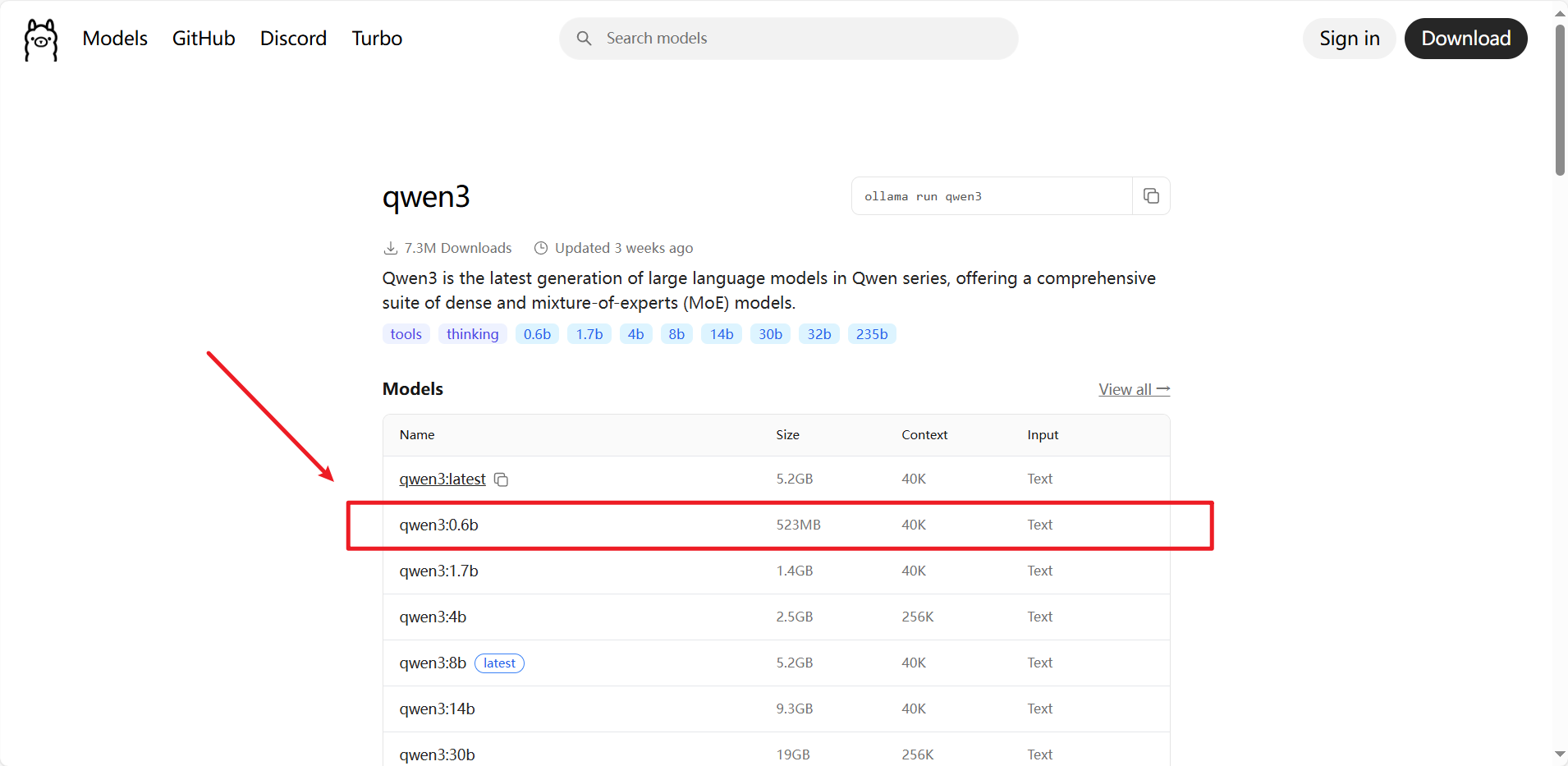
6. 然后复制命令
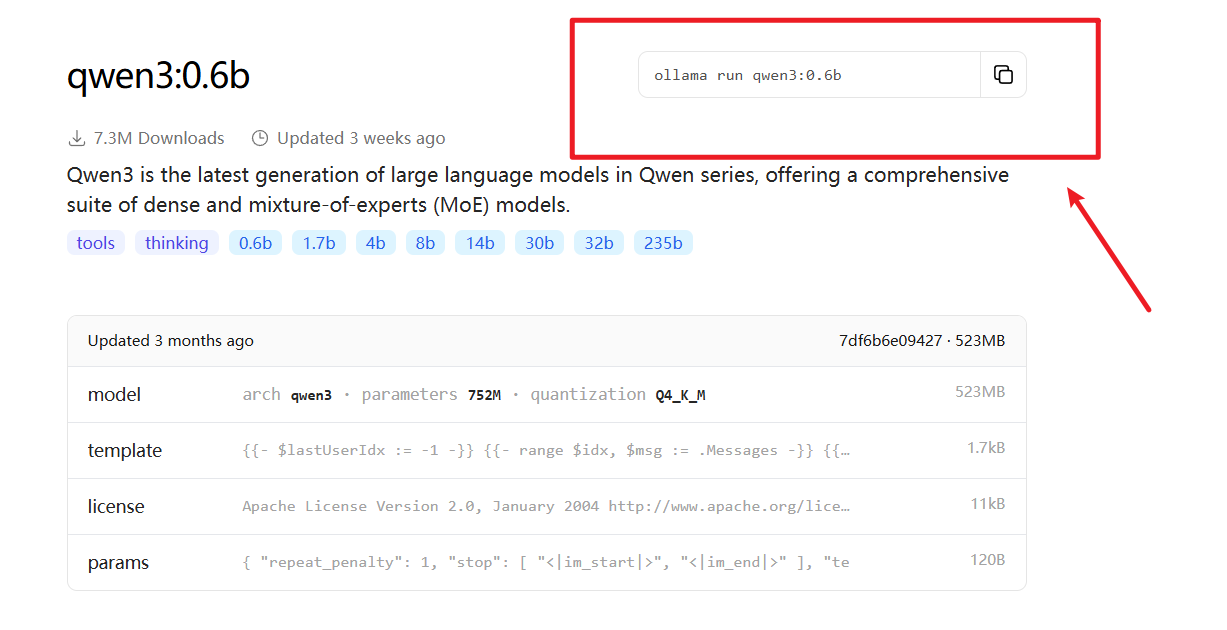
7. 点开运行终端,输入命令开始安装
8. 回车进入聊天模式
9. 输入 /bye 退出聊天模式
10. 重新启动:继续输入上面的 ollama run XXX 命令
二、通过Http方式调用
1.打开Apifox或Postman
2.打开Ollama官网查找本地模型的接口路径
(1)点击Blog
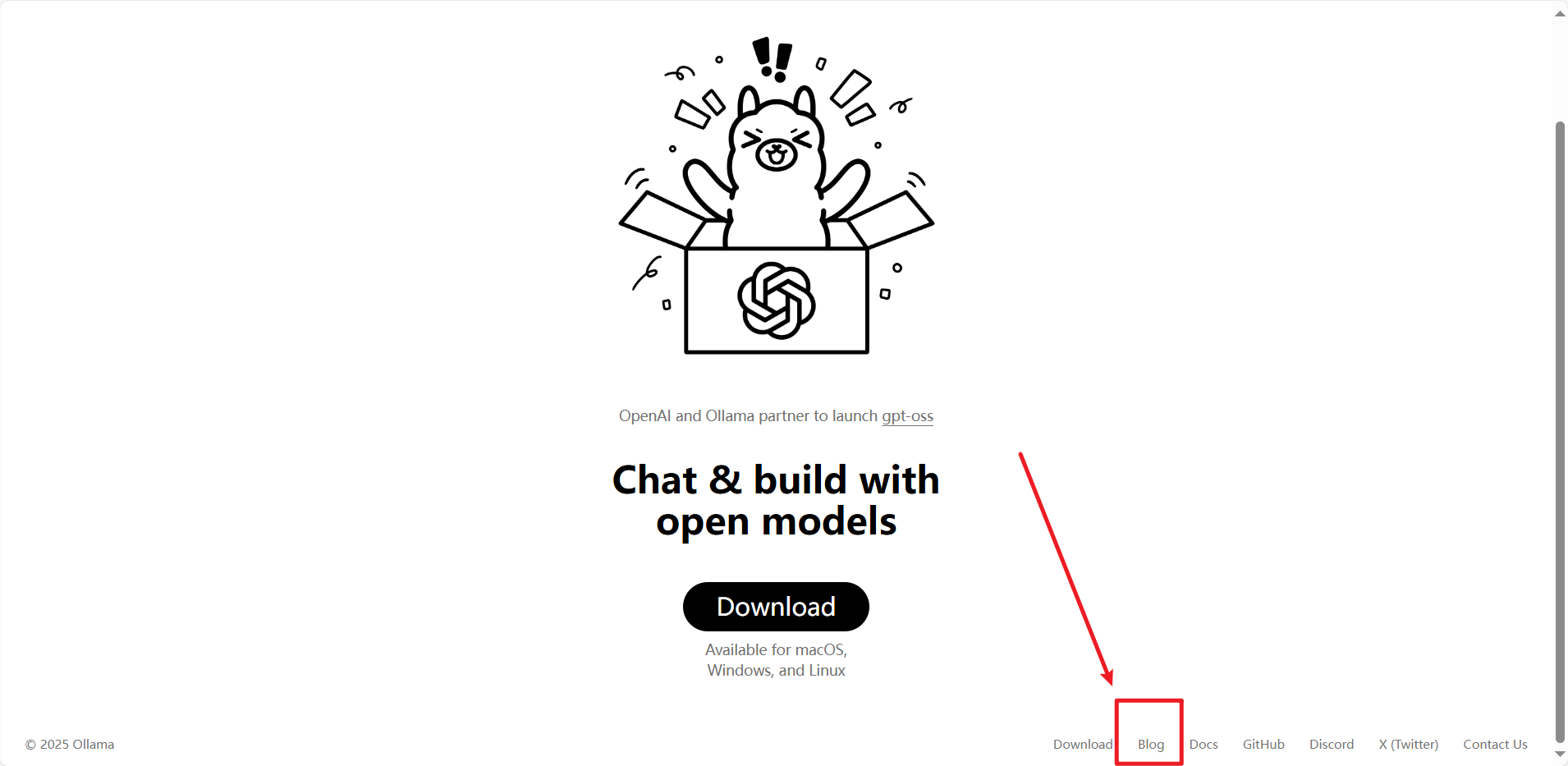
(2)点击Thinking

(3)下滑找到Example
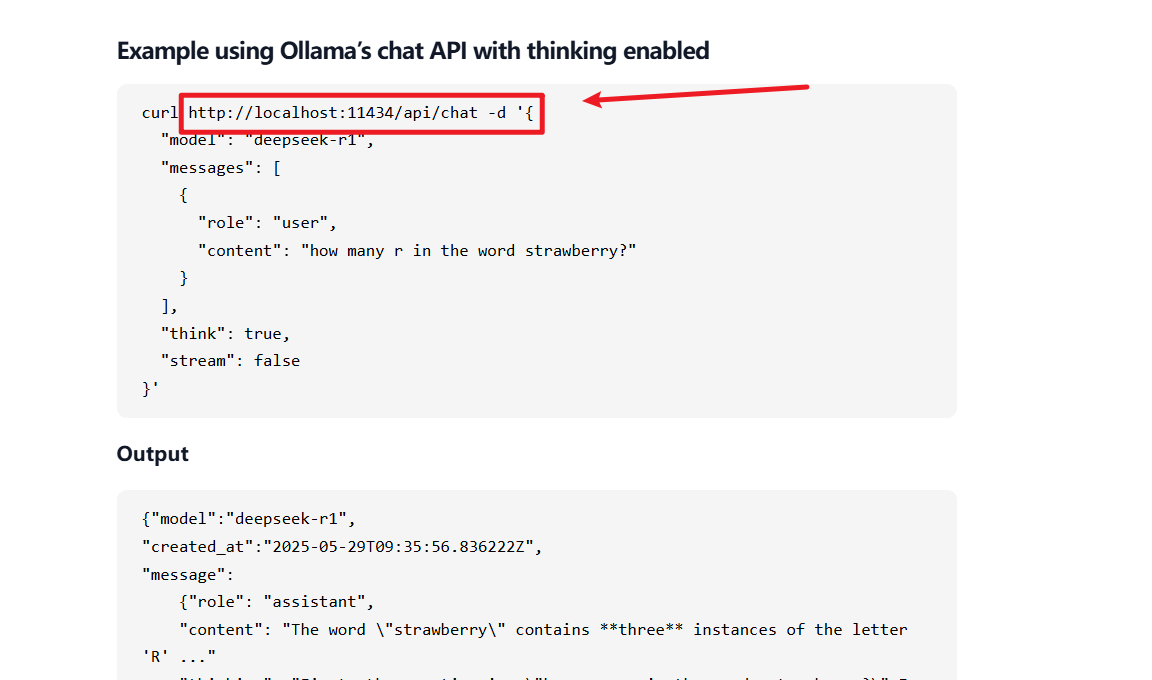
(4)复制地址到Apifox或Postman中,发送方式改为Post
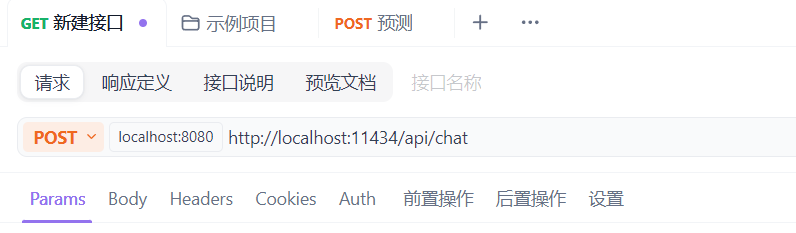
(5)复制Json格式的请求体
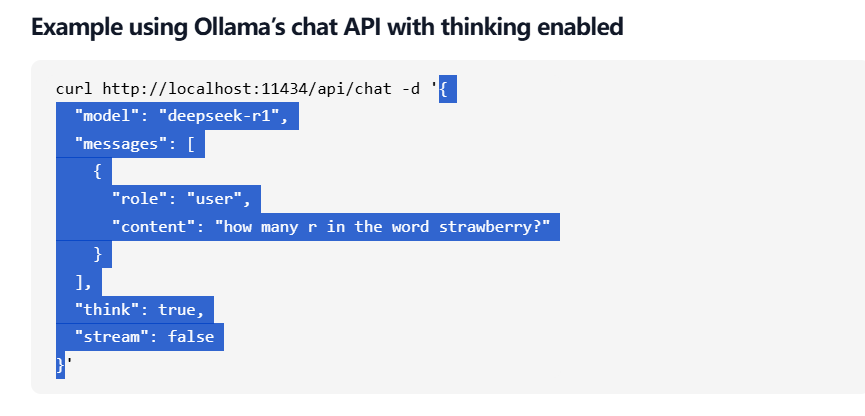
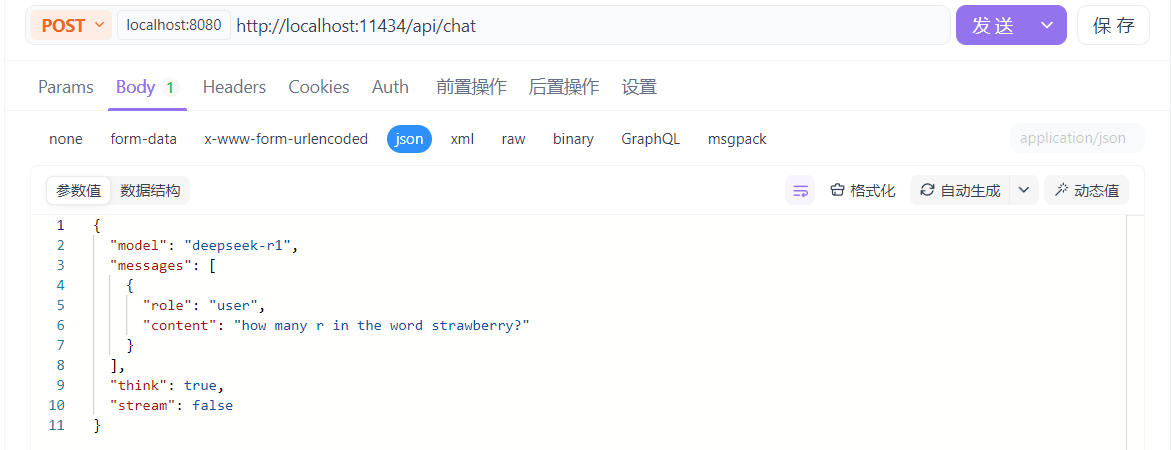
(6)粘贴到Body里的Json中
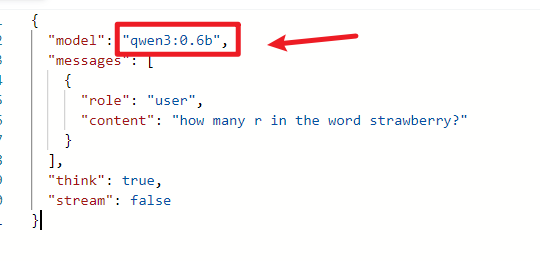
(7) model的值要改为本地部署的模型名称
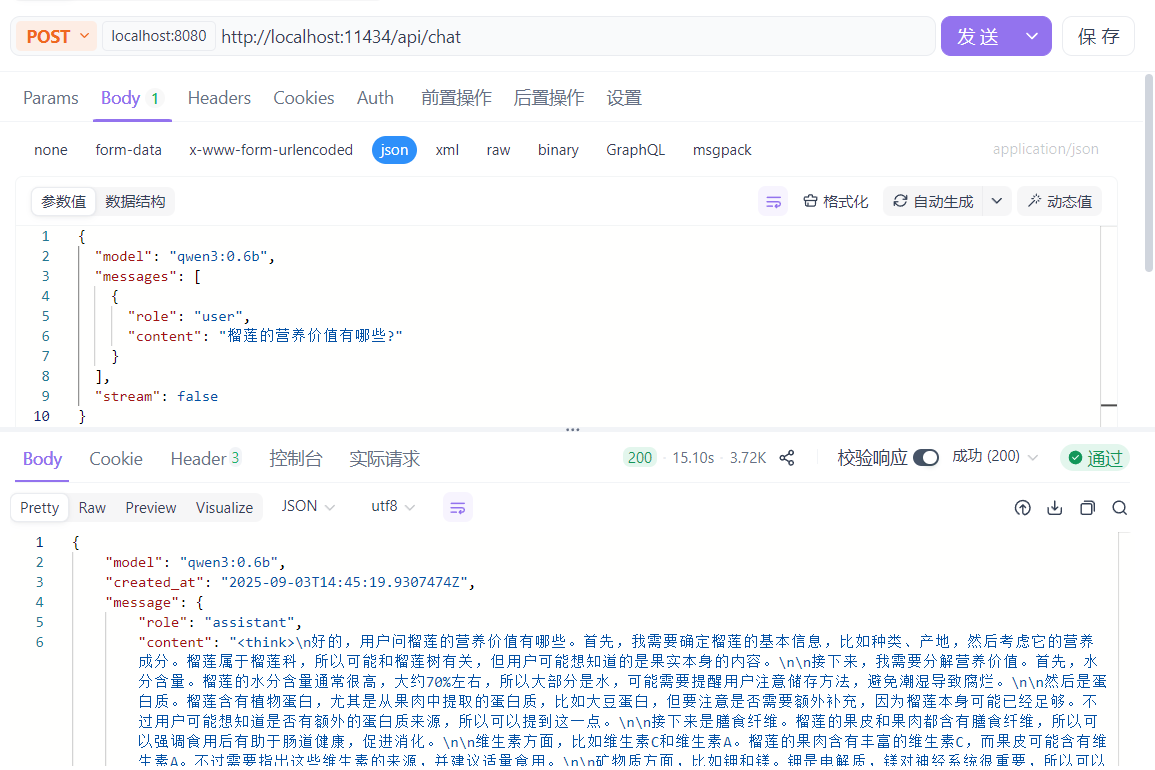
(8) 修改content里的消息内容,点击发送,得到正确响应
三、常见调用参数
1.model
{
"参数名": "model",
"作用": "指定调用的大模型版本",
"数据类型": "字符串",
"示例": ""model": "gpt-4""
}
2.prompt
{
"参数名": "prompt",
"作用": "核心输入指令,定义模型任务",
"数据类型": "字符串 / 数组",
"示例": ""prompt": "用 2 句话解释区块链的核心特点""
}
3.temperature
{
"参数名": "temperature",
"作用": "控制生成随机性(0-2),值越高越发散,越低越严谨",
"数据类型": "浮点数",
"示例": ""temperature": 0.2" // 适合事实性回答,如知识问答
}
4.max_tokens
{
"参数名": "max_tokens",
"作用": "限制生成内容总长度(含 prompt 和响应)",
"数据类型": "整数",
"示例": ""max_tokens": 800"
}
5.top_p
{
"参数名": "top_p",
"作用": "控制词汇选择的累计概率(0-1),与 temperature 二选一",
"数据类型": "浮点数",
"示例": ""top_p": 0.1" // 仅从概率前 10% 的词中选择,生成更精准
}
6.n
{
"参数名": "n",
"作用": "控制返回的候选响应数量",
"数据类型": "整数",
"示例": ""n": 2" // 针对同一 prompt 生成 2 个不同回答
}
7.stop
{
"参数名": "stop",
"作用": "设定终止符,模型遇到时停止生成",
"数据类型": "字符串 / 数组",
"示例": ""stop": [";", "。"]" // 遇到分号或句号停止
}
8.stream
{
"参数名": "stream",
"作用": "控制是否流式返回(边生成边输出)",
"数据类型": "布尔值",
"示例": ""stream": true" // 适合聊天界面,减少等待感
}
四、常见响应数据
(JSON 格式示例)
{
"id": "chatcmpl-9XYZ7890ABCD1234", // 本次调用唯一标识,用于追溯
"object": "chat.completion", // 响应类型,单次完整响应(流式为 chat.completion.chunk)
"created": 1717888888, // Unix 时间戳(秒),调用发起时间
"model": "gpt-4-0613", // 实际调用的模型版本
"choices": [
{
"index": 0, // 结果序号(n=2 时会有 index:0 和 index:1)
"message": {
"role": "assistant", // 角色(assistant = 模型,user = 用户,system = 系统)
"content": "区块链核心是去中心化存储,数据由多节点共同维护;同时具有不可篡改性,一旦记录便无法随意修改,保障数据安全。" // 模型生成的核心内容
},
"finish_reason": "stop" // 终止原因(stop = 触发终止符,length = 达 max_tokens,content_filter = 触发过滤)
}
],
"usage": {
"prompt_tokens": 25, // 输入 prompt 消耗的 token 数
"completion_tokens": 68, // 模型输出内容消耗的 token 数
"total_tokens": 93 // 总消耗 token 数(用于计费)
},
"error": null // 调用失败时返回错误信息,成功时为 null,示例:{"message":"Invalid API key","type":"invalid_request_error"}
}
}
}五、Ollama常用命令
-
模型运行与交互
-
运行模型并进入交互模式:
ollama run <模型名>
示例:ollama run llama3(启动 Llama 3 模型并开始对话) -
非交互模式运行单次查询:
echo "<问题>" | ollama run <模型名>
示例:echo "什么是人工智能?" | ollama run qwen
-
-
模型管理
-
拉取模型(从官方库):
ollama pull <模型名[:版本]>
示例:ollama pull mistral:7b(拉取 7B 参数的 Mistral 模型) -
查看本地已安装模型:
ollama list
输出示例:NAME ID SIZE MODIFIED llama3:latest 78e26419b446 3.8 GB 2 days ago -
删除本地模型:
ollama rm <模型名>
示例:ollama rm llama2:13b -
创建自定义模型(基于 Modelfile):
ollama create <自定义名> -f <Modelfile路径>
示例:ollama create my-llama -f ./Modelfile
-
-
服务控制
-
启动 Ollama 服务:
ollama serve(后台运行时可配合 nohup 等工具) -
查看 Ollama 版本:
ollama version
输出示例:ollama version 0.1.30
-
-
模型信息与配置
-
查看模型详情:
ollama show <模型名>
示例:ollama show gemma:2b(显示模型参数、描述等信息) -
复制模型(重命名):
ollama cp <源模型> <目标模型>
示例:ollama cp llama3:latest my-llama3
-
六、核心特点
-
本地化运行
无需依赖云端服务,模型直接在本地设备运行,数据隐私性更强,适合对数据安全敏感的场景(如企业内部使用、个人隐私保护)。 -
极简部署流程
安装后通过简单的命令即可拉取、运行模型,无需手动配置依赖(如 CUDA、Python 环境等),对新手友好。 -
支持主流开源模型
内置支持 Llama 3、Mistral、Gemma、Qwen(通义千问)、Yi 等多种热门开源大模型,且持续更新模型库。 -
跨平台兼容
支持 Windows、macOS(包括 M 系列芯片)、Linux 系统,适配 CPU 和 GPU 运行(GPU 需支持 CUDA 或 Metal 加速)。 -
轻量化设计
核心程序体积小,资源占用可控,部分小参数模型(如 7B、3B)可在普通个人电脑上流畅运行。 -
可扩展性
支持通过 Modelfile 自定义模型(如添加系统提示词、微调模型),并提供 API 接口供程序调用。
