Redis高级篇:在Nginx、Redis、Tomcat(JVM)各环节添加缓存以实现多级缓存
摘要:多级缓存通过在 Nginx、Redis、Tomcat(JVM)各环节添加缓存,解决传统缓存中 Tomcat 瓶颈与 Redis 失效冲击数据库问题。利用 Caffeine 实现 JVM 缓存,OpenResty 结合 Lua 处理 Nginx 层逻辑,通过 Redis 缓存预热,提升缓存命中率与系统性能。

1.什么是多级缓存
传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未命中则查询数据库,如图:
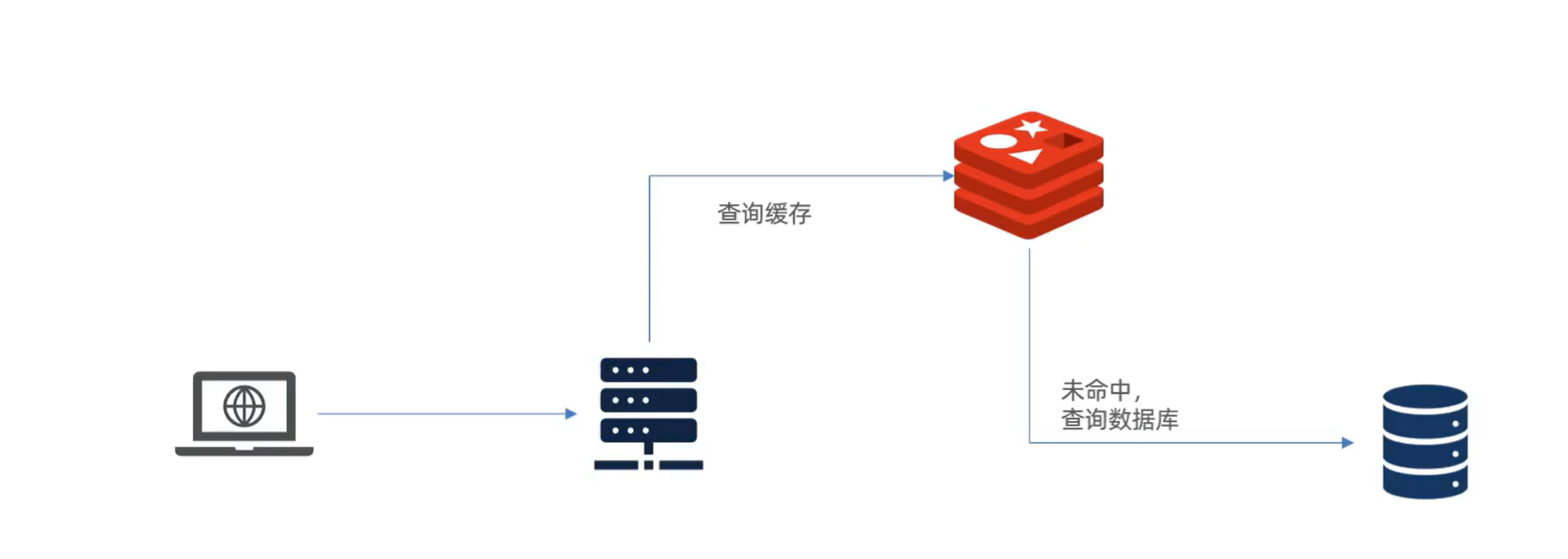
存在下面的问题:
1.请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈
2.Redis缓存失效时,会对数据库产生冲击
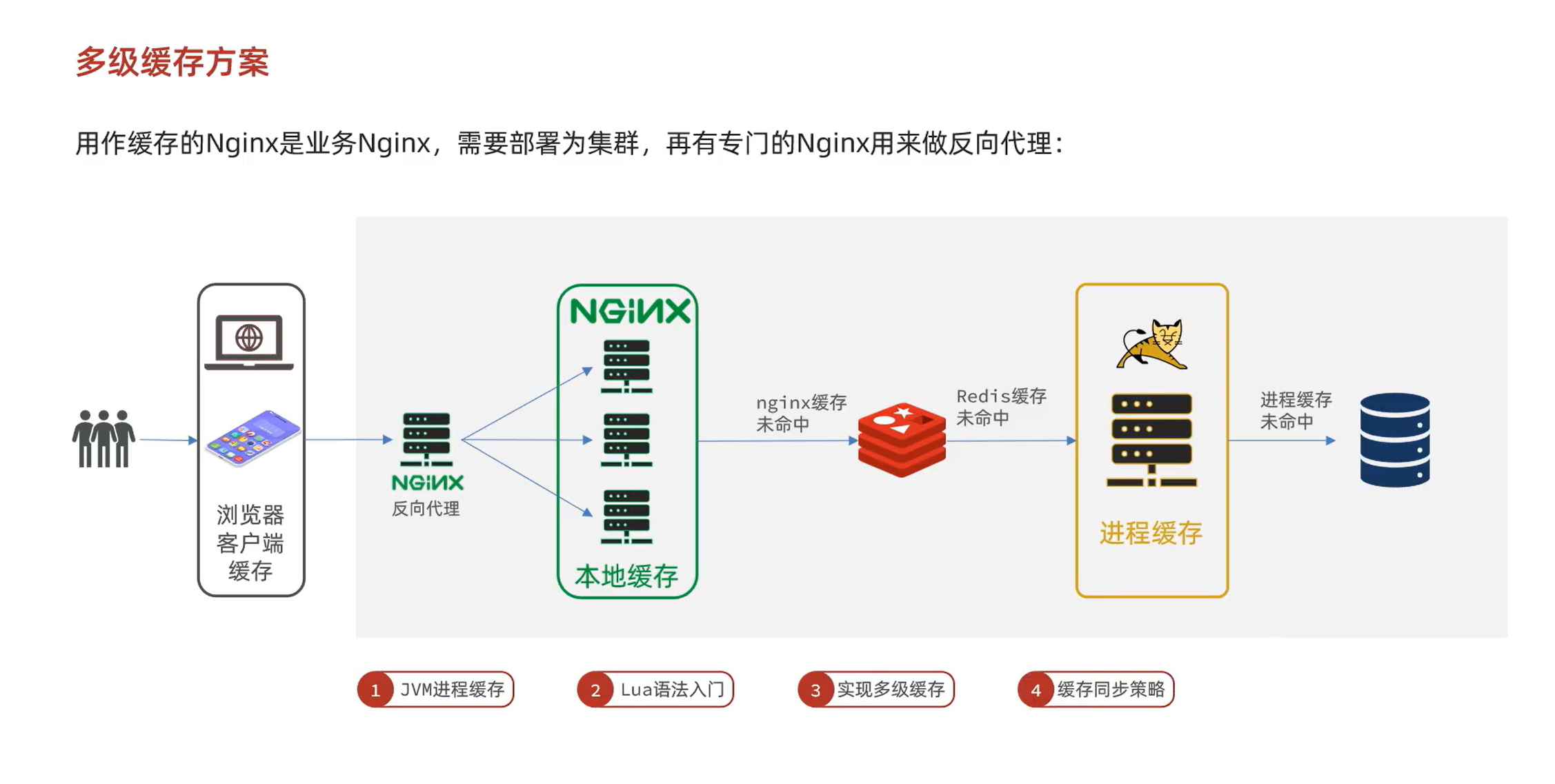
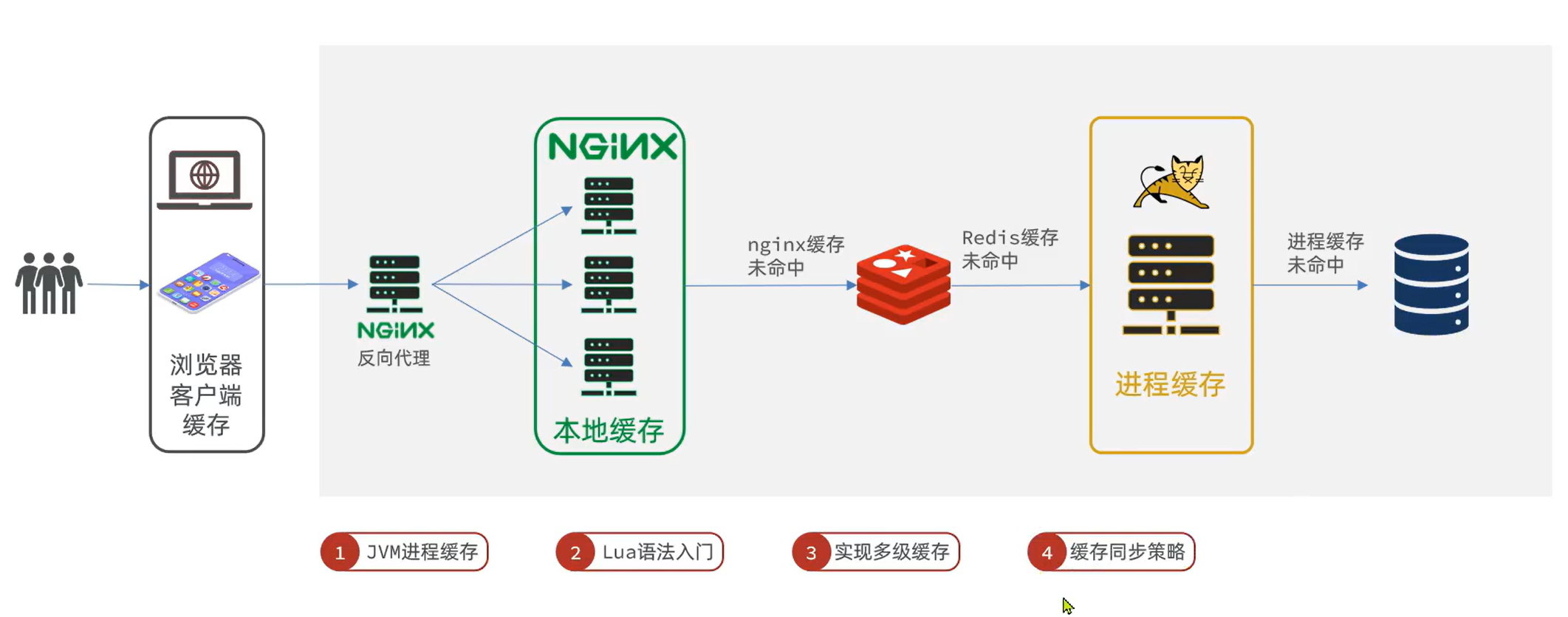
多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Tomcat压力,提升服务性能:
浏览器访问静态资源时,优先读取浏览器本地缓存
访问非静态资源(ajax查询数据)时,访问服务端
请求到达Nginx后,优先读取Nginx本地缓存
如果Nginx本地缓存未命中,则去直接查询Redis缓存
如果Redis查询未命中,则查询Tomcat
请求进入Tomcat后,优先查询JVM进程缓存
如果JVM进程缓存未命中,则查询数据库
在多级缓存架构中,Nginx内部需要编写本地缓存查询、Redis查询、Tomcat查询的业务逻辑,因此这样的nginx服务不再是一个反向代理服务器,而是一个编写业务的Web服务器了。
因此这样的业务Nginx服务也需要搭建集群来提高并发,再有专门的nginx服务来做反向代理:
而后端,主要注重下面的四大核心内容:
- JVM进程缓存
- Lua语法入门
- 实现多级缓存
- 缓存同步策略
2.JVM进程缓存
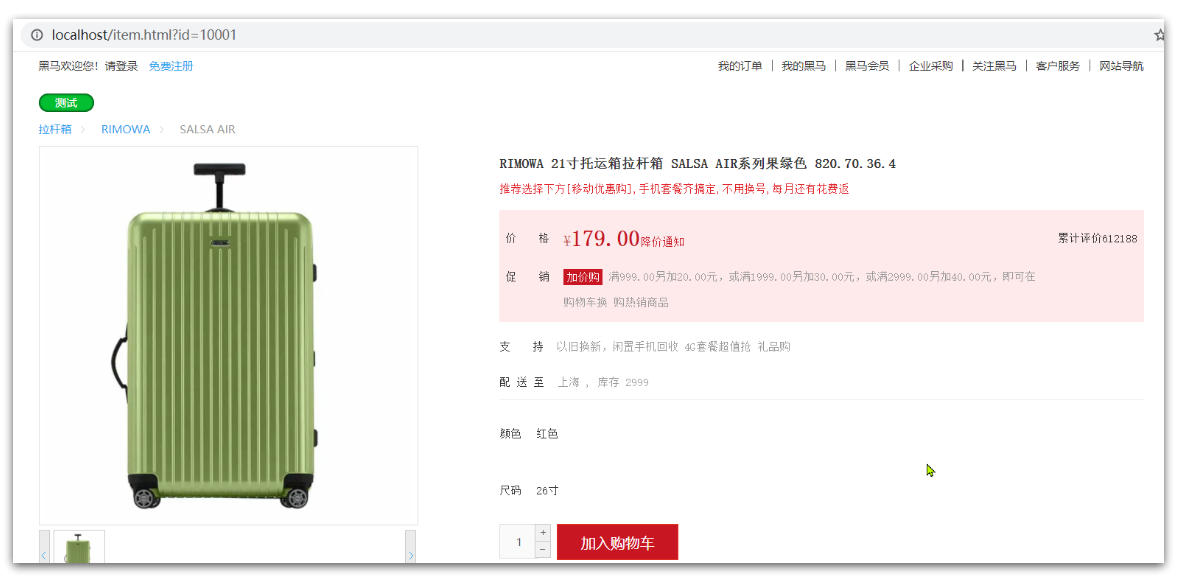
为了演示多级缓存的案例,我们先准备一个商品查询的业务。
2.1.导入案例
效果如图:
2.2.初识Caffeine
缓存在日常开发中启动至关重要的作用,由于是存储在内存中,数据的读取速度是非常快的,能大量减少对数据库的访问,减少数据库的压力。我们把缓存分为两类:
分布式缓存,例如Redis:
优点:存储容量更大、可靠性更好、可以在集群间共享
缺点:访问缓存有网络开销
场景:缓存数据量较大、可靠性要求较高、需要在集群间共享
进程本地缓存,例如 Caffeine、HashMap:
优点:读取本地内存,没有网络开销,速度更快
缺点:存储容量有限、可靠性较低、无法共享
场景:性能要求较高,缓存数据量较小
我们今天会利用Caffeine框架来实现JVM进程缓存。
Caffeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库。目前Spring内部的缓存使用的就是Caffeine。
Caffeine的性能非常好,下图是官方给出的性能对比:
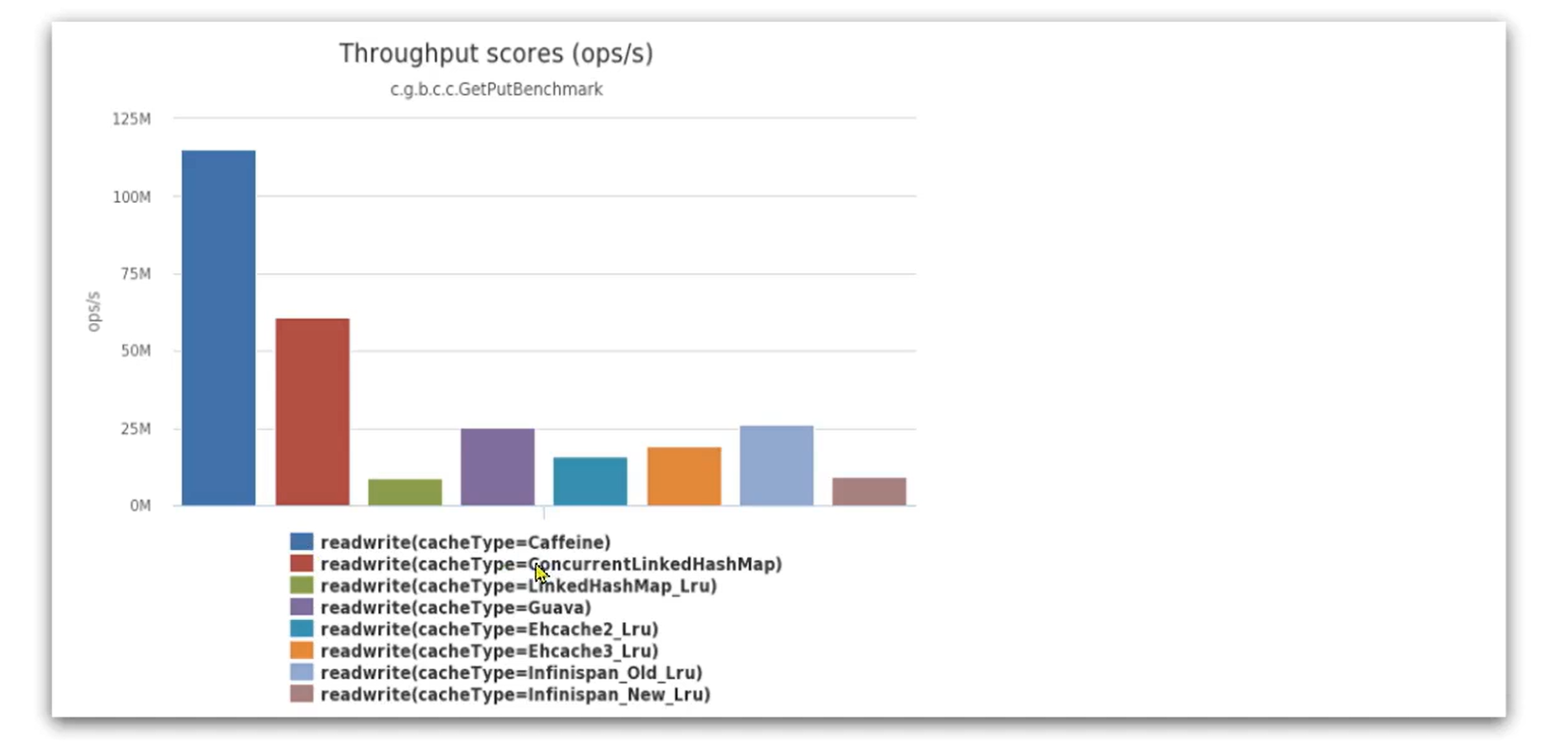
可以看到Caffeine的性能遥遥领先!
Caffeine的使用
引入Maven依赖:
<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><version>3.1.8</version>
</dependency>缓存使用的基本API:
@Test
void testBasicOps() {// 构建cache对象Cache<String, String> cache = Caffeine.newBuilder().build();
// 存数据cache.put("blogger", "Purse Wind");
// 取数据String bg = cache.getIfPresent("blogger");
// 取数据,包含两个参数:// 参数一:缓存的key// 参数二:Lambda表达式,表达式参数就是缓存的key,方法体是查询数据库的逻辑// 优先根据key查询JVM缓存,如果未命中,则执行参数二的Lambda表达式String defaultbg = cache.get("defaultbg", key -> {// 根据key去数据库查询数据return "张哈大";});
}Caffeine既然是缓存的一种,肯定需要有缓存的清除策略,不然的话内存总会有耗尽的时候。
Caffeine提供了三种缓存驱逐策略:
基于容量:设置缓存的数量上限
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder().maximumSize(1) // 设置缓存大小上限为 1.build();基于时间:设置缓存的有效时间
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()// 设置缓存有效期为 10 秒,从最后一次写入开始计时 .expireAfterWrite(Duration.ofSeconds(10)) .build();基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用。
注意:在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。
2.3.实现JVM进程缓存
2.3.1.需求
利用Caffeine实现下列需求:
给根据id查询商品的业务添加缓存,缓存未命中时查询数据库
给根据id查询商品库存的业务添加缓存,缓存未命中时查询数据库
缓存初始大小为100
缓存上限为10000
2.3.2.实现
首先,我们需要定义两个Caffeine的缓存对象,分别保存商品、库存的缓存数据。
在item-service的com.heima.item.config包下定义CaffeineConfig类:
@Configuration
public class CaffeineConfig {
@Beanpublic Cache<Long, Item> itemCache(){return Caffeine.newBuilder().initialCapacity(100).maximumSize(10_000).build();}
@Beanpublic Cache<Long, ItemStock> stockCache(){return Caffeine.newBuilder().initialCapacity(100).maximumSize(10_000).build();}
} 然后,修改item-service中的com.heima.item.web包下的ItemController类,添加缓存逻辑:
@RestController
@RequestMapping("item")
public class ItemController {
@Autowiredprivate IItemService itemService;@Autowiredprivate IItemStockService stockService;
@Autowiredprivate Cache<Long, Item> itemCache;@Autowiredprivate Cache<Long, ItemStock> stockCache;// ...其它略@GetMapping("/{id}")public Item findById(@PathVariable("id") Long id) {return itemCache.get(id, key -> itemService.query().ne("status", 3).eq("id", key).one());}
@GetMapping("/stock/{id}")public ItemStock findStockById(@PathVariable("id") Long id) {return stockCache.get(id, key -> stockService.getById(key));}
}3.Lua语法入门
Nginx编程需要用到Lua语言,因此我们必须先入门Lua的基本语法。
3.1.初识Lua
Lua 是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。

Lua经常嵌入到C语言开发的程序中,例如游戏开发、游戏插件等。
Nginx本身也是C语言开发,因此也允许基于Lua做拓展。
3.1.HelloWorld
CentOS7默认已经安装了Lua语言环境,所以可以直接运行Lua代码。
1)在Linux虚拟机的任意目录下,新建一个hello.lua文件

2)添加下面的内容
print("Hello World!") 3)运行

3.2.变量和循环
学习任何语言必然离不开变量,而变量的声明必须先知道数据的类型。
3.2.1.Lua的数据类型
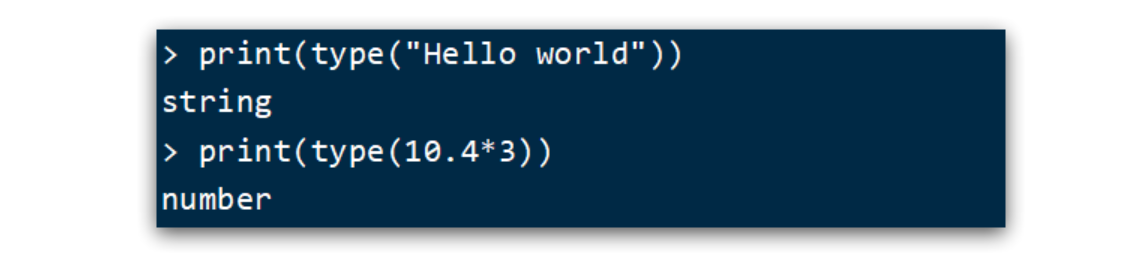
Lua中支持的常见数据类型包括:

另外,Lua提供了type()函数来判断一个变量的数据类型:
3.2.2.声明变量
Lua声明变量的时候无需指定数据类型,而是用local来声明变量为局部变量:
-- 声明字符串,可以用单引号或双引号,
local str = 'hello'
-- 字符串拼接可以使用 ..
local str2 = 'hello' .. 'world'
-- 声明数字
local num = 21
-- 声明布尔类型
local flag = trueLua中的table类型既可以作为数组,又可以作为Java中的map来使用。数组就是特殊的table,key是数组角标而已:
-- 声明数组 ,key为角标的 table
local arr = {'java', 'python', 'lua'}
-- 声明table,类似java的map
local map = {name='Jack', age=21}Lua中的数组角标是从1开始,访问的时候与Java中类似:
-- 访问数组,lua数组的角标从1开始
print(arr[1])Lua中的table可以用key来访问:
-- 访问table
print(map['name'])
print(map.name)3.2.3.循环
对于table,我们可以利用for循环来遍历。不过数组和普通table遍历略有差异。
遍历数组:
-- 声明数组 key为索引的 table
local arr = {'java', 'python', 'lua'}
-- 遍历数组
for index,value in ipairs(arr) doprint(index, value)
end遍历普通table
-- 声明map,也就是table
local map = {name='Jack', age=21}
-- 遍历table
for key,value in pairs(map) doprint(key, value)
end3.3.条件控制、函数
Lua中的条件控制和函数声明与Java类似。
3.3.1.函数
定义函数的语法:
function 函数名( argument1, argument2..., argumentn)-- 函数体return 返回值
end例如,定义一个函数,用来打印数组:
function printArr(arr)for index, value in ipairs(arr) doprint(value)end
end3.3.2.条件控制
类似Java的条件控制,例如if、else语法:
if(布尔表达式)
then--[ 布尔表达式为 true 时执行该语句块 --]
else--[ 布尔表达式为 false 时执行该语句块 --]
end与java不同,布尔表达式中的逻辑运算是基于英文单词:
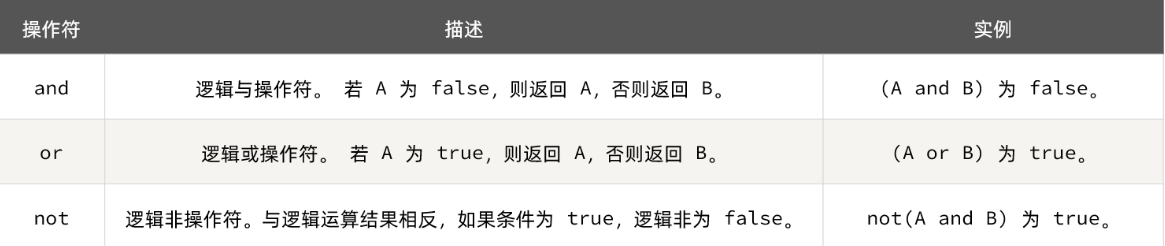
3.3.3.案例
需求:自定义一个函数,可以打印table,当参数为nil时,打印错误信息
function printArr(arr)if not arr thenprint('数组不能为空!')endfor index, value in ipairs(arr) doprint(value)end
end4.实现多级缓存
多级缓存的实现离不开Nginx编程,而Nginx编程又离不开OpenResty。
4.1.OpenResty简介
OpenResty® 是一个基于 Nginx的高性能 Web 平台,用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。具备下列特点:
具备Nginx的完整功能
基于Lua语言进行扩展,集成了大量精良的 Lua 库、第三方模块
允许使用Lua自定义业务逻辑、自定义库
4.2.OpenResty快速入门
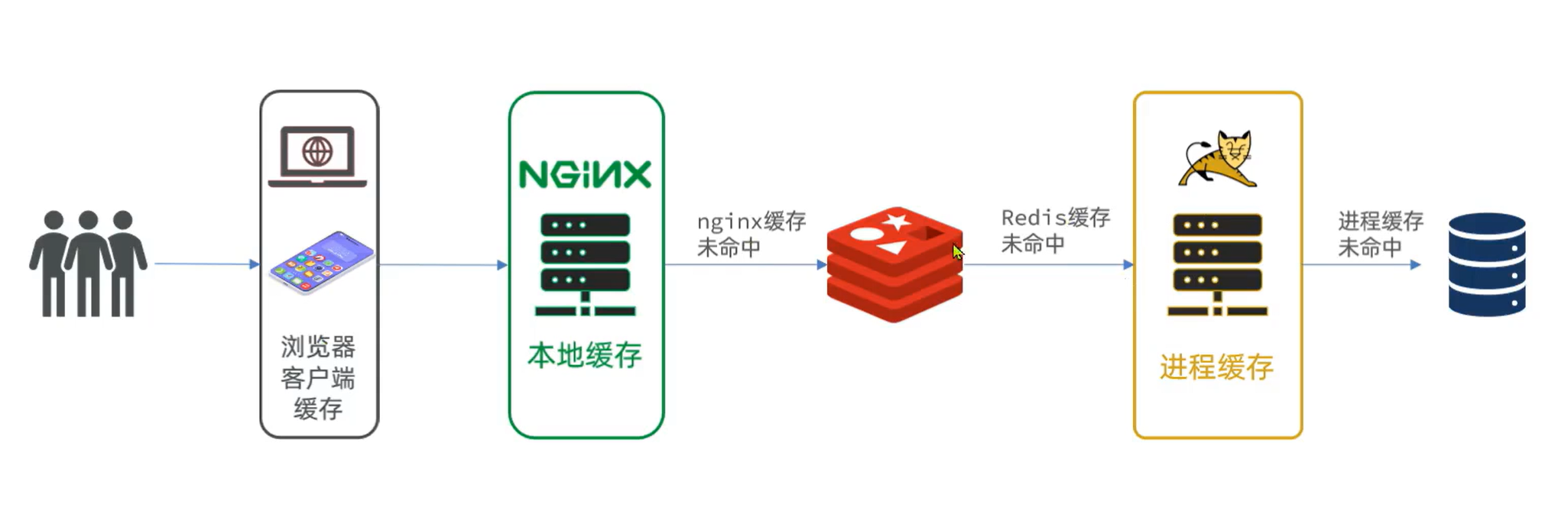
我们希望达到的多级缓存架构如图:
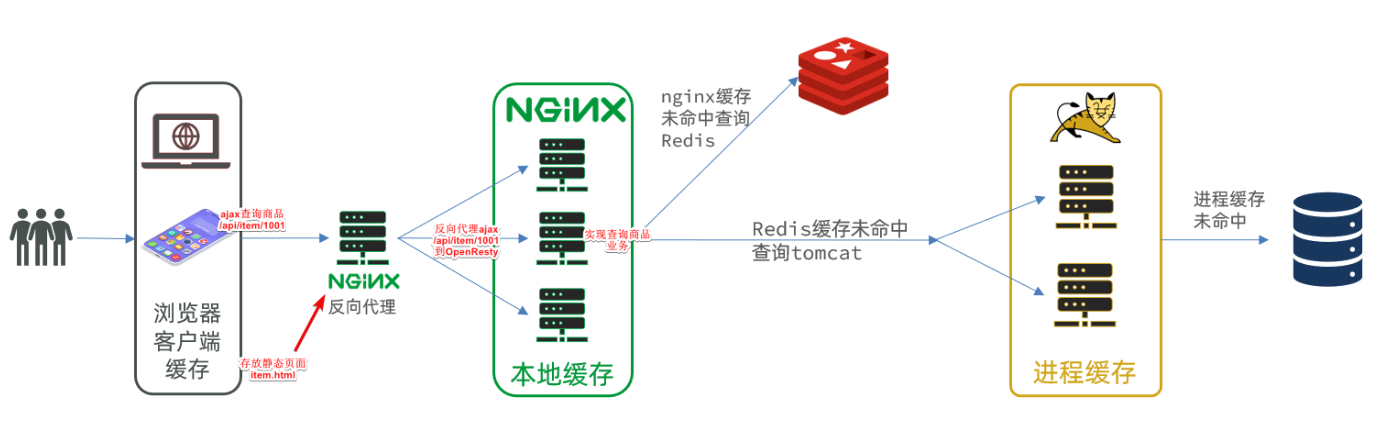
其中:
windows上的nginx用来做反向代理服务,将前端的查询商品的ajax请求代理到OpenResty集群
OpenResty集群用来编写多级缓存业务
4.2.1.反向代理流程
现在,商品详情页使用的是假的商品数据。不过在浏览器中,可以看到页面有发起ajax请求查询真实商品数据。
这个请求如下:

请求地址是localhost,端口是80,就被windows上安装的Nginx服务给接收到了。然后代理给了OpenResty集群:
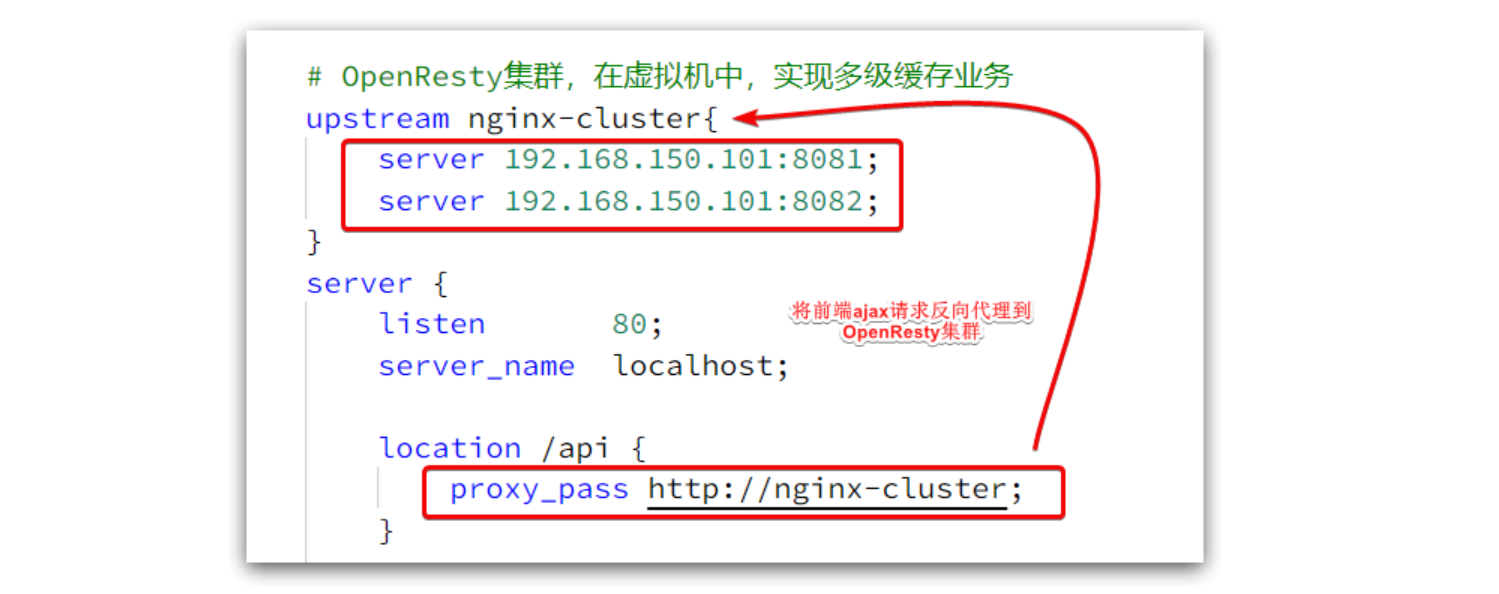
我们需要在OpenResty中编写业务,查询商品数据并返回到浏览器。
但是这次,我们先在OpenResty接收请求,返回假的商品数据。
4.2.2.OpenResty监听请求
OpenResty的很多功能都依赖于其目录下的Lua库,需要在nginx.conf中指定依赖库的目录,并导入依赖:
1)添加对OpenResty的Lua模块的加载
修改/usr/local/openresty/nginx/conf/nginx.conf文件,在其中的http下面,添加下面代码:
#lua 模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
#c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;"; 2)监听/api/item路径
修改/usr/local/openresty/nginx/conf/nginx.conf文件,在nginx.conf的server下面,添加对/api/item这个路径的监听:
location /api/item {# 默认的响应类型default_type application/json;# 响应结果由lua/item.lua文件来决定content_by_lua_file lua/item.lua;
}这个监听,就类似于SpringMVC中的@GetMapping("/api/item")做路径映射。
而content_by_lua_file lua/item.lua则相当于调用item.lua这个文件,执行其中的业务,把结果返回给用户。相当于java中调用service。
4.2.3.编写item.lua
1)在/usr/loca/openresty/nginx目录创建文件夹:lua

2)在/usr/loca/openresty/nginx/lua文件夹下,新建文件:item.lua

3)编写item.lua,返回假数据
item.lua中,利用ngx.say()函数返回数据到Response中
ngx.say('{"id":10001,"name":"SALSA AIR","title":"RIMOWA 21寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4","price":17900,"image":"https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp","category":"拉杆箱","brand":"RIMOWA","spec":"","status":1,"createTime":"2019-04-30T16:00:00.000+00:00","updateTime":"2019-04-30T16:00:00.000+00:00","stock":2999,"sold":31290}')4)重新加载配置
nginx -s reload4.3.请求参数处理
上一节中,我们在OpenResty接收前端请求,但是返回的是假数据。
要返回真实数据,必须根据前端传递来的商品id,查询商品信息才可以。
那么如何获取前端传递的商品参数呢?
4.3.1.获取参数的API
OpenResty中提供了一些API用来获取不同类型的前端请求参数:

4.3.2.获取参数并返回
在前端发起的ajax请求如图:
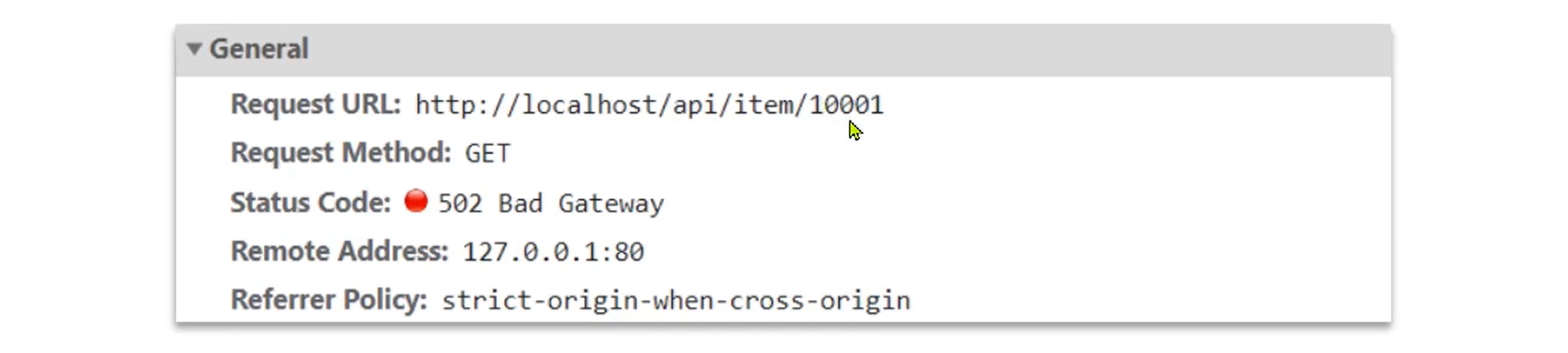
可以看到商品id是以路径占位符方式传递的,因此可以利用正则表达式匹配的方式来获取ID
1)获取商品id
修改/usr/loca/openresty/nginx/nginx.conf文件中监听/api/item的代码,利用正则表达式获取ID:
location ~ /api/item/(\d+) {# 默认的响应类型default_type application/json;# 响应结果由lua/item.lua文件来决定content_by_lua_file lua/item.lua;
}2)拼接ID并返回
修改/usr/loca/openresty/nginx/lua/item.lua文件,获取id并拼接到结果中返回:
-- 获取商品id
local id = ngx.var[1]
-- 拼接并返回
ngx.say('{"id":' .. id .. ',"name":"SALSA AIR","title":"RIMOWA 21寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4","price":17900,"image":"https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp","category":"拉杆箱","brand":"RIMOWA","spec":"","status":1,"createTime":"2019-04-30T16:00:00.000+00:00","updateTime":"2019-04-30T16:00:00.000+00:00","stock":2999,"sold":31290}')4.4.查询Tomcat
拿到商品ID后,本应去缓存中查询商品信息,不过目前我们还未建立nginx、redis缓存。因此,这里我们先根据商品id去tomcat查询商品信息。我们实现如图部分:
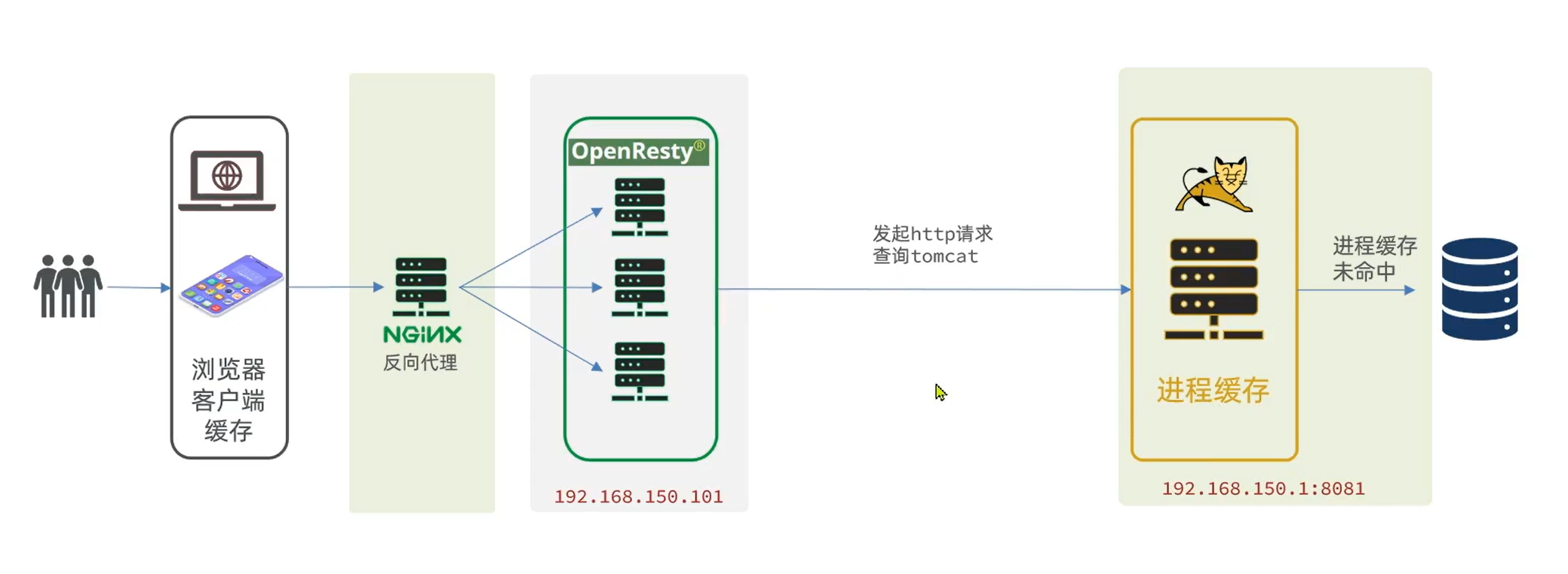
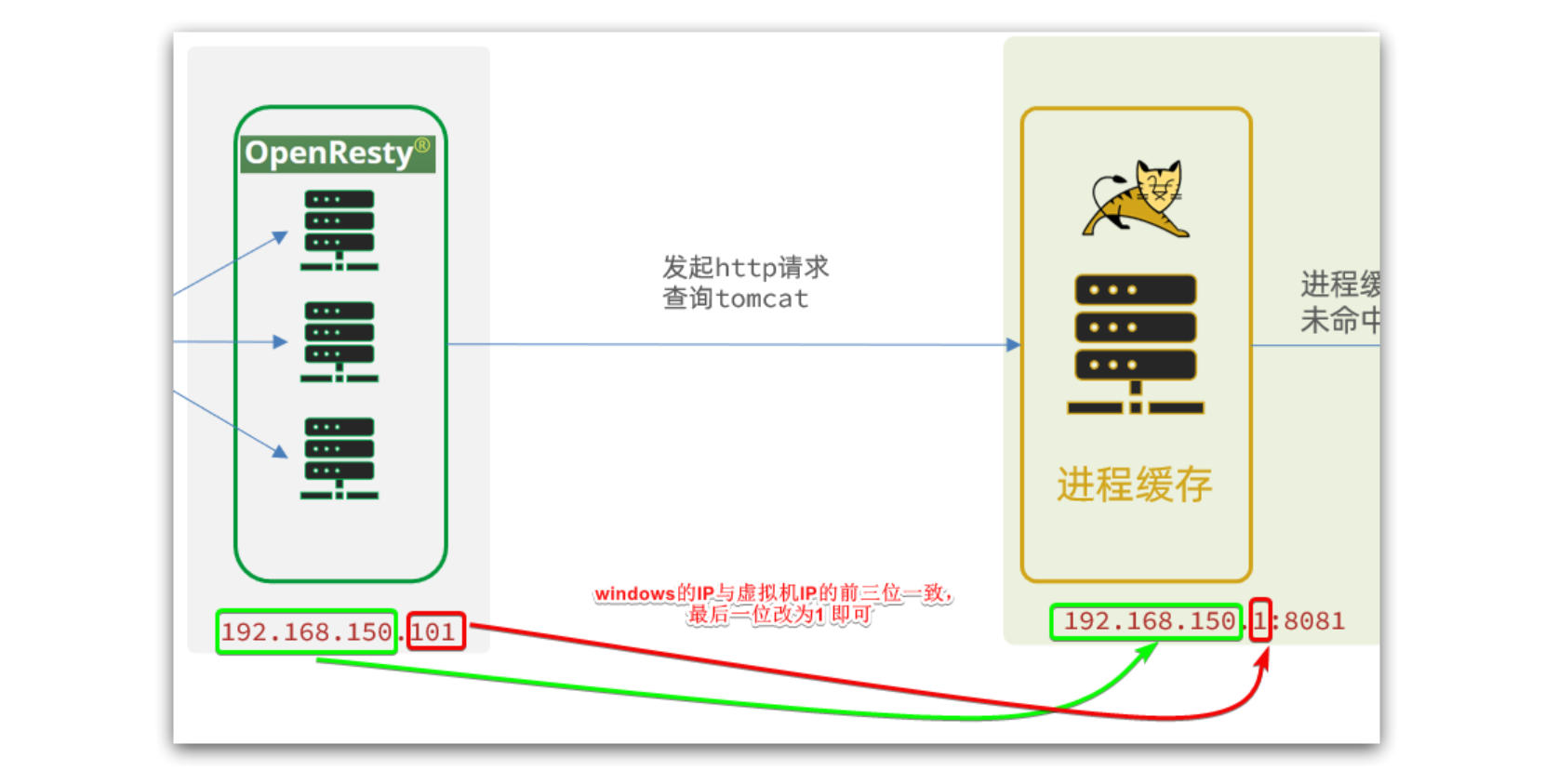
注意:我们的OpenResty是在虚拟机,Tomcat是在Windows电脑上。两者IP一定不要搞错了。
4.4.1.发送http请求的API
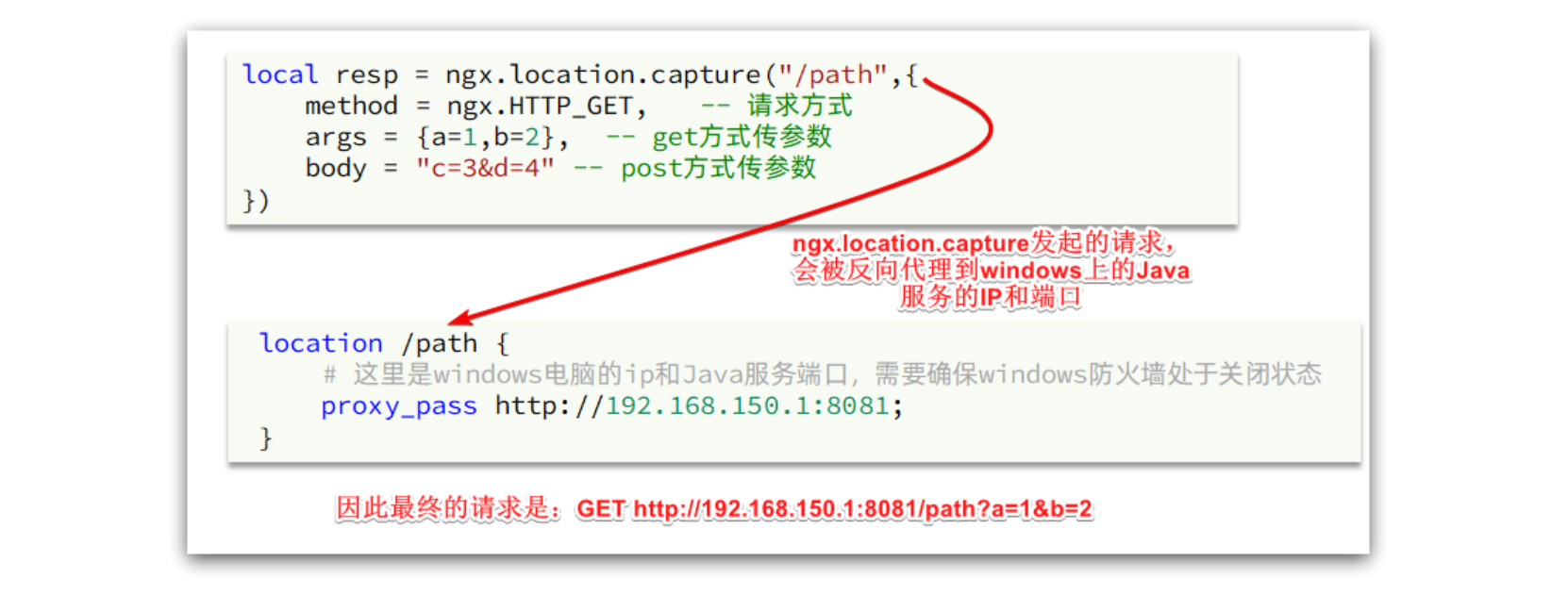
nginx提供了内部API用以发送http请求:
local resp = ngx.location.capture("/path",{method = ngx.HTTP_GET, -- 请求方式args = {a=1,b=2}, -- get方式传参数
})返回的响应内容包括:
resp.status:响应状态码
resp.header:响应头,是一个table
resp.body:响应体,就是响应数据
注意:这里的path是路径,并不包含IP和端口。这个请求会被nginx内部的server监听并处理。
但是我们希望这个请求发送到Tomcat服务器,所以还需编写一个server来对这个路径做反向代理:
location /path {# 这里是windows电脑的ip和Java服务端口,需要确保windows防火墙处于关闭状态proxy_pass http://192.168.150.1:8081; }原理如图:
4.4.2.封装http工具
下面,我们封装一个发送Http请求的工具,基于ngx.location.capture来实现查询tomcat。
1)添加反向代理,到windows的Java服务
因为item-service中的接口都是/item开头,所以我们监听/item路径,代理到windows上的tomcat服务。
修改 /usr/local/openresty/nginx/conf/nginx.conf文件,添加一个location:
location /item {proxy_pass http://192.168.150.1:8081;
}以后,只要我们调用ngx.location.capture("/item"),就一定能发送请求到windows的tomcat服务。
2)封装工具类
之前我们说过,OpenResty启动时会加载以下两个目录中的工具文件:

所以,自定义的http工具也需要放到这个目录下。
在/usr/local/openresty/lualib目录下,新建一个common.lua文件:
vi /usr/local/openresty/lualib/common.lua内容如下:
-- 封装函数,发送http请求,并解析响应
local function read_http(path, params)local resp = ngx.location.capture(path,{method = ngx.HTTP_GET,args = params,})if not resp then-- 记录错误信息,返回404ngx.log(ngx.ERR, "http请求查询失败, path: ", path , ", args: ", args)ngx.exit(404)endreturn resp.body
end
-- 将方法导出
local _M = { read_http = read_http
}
return _M这个工具将read_http函数封装到_M这个table类型的变量中,并且返回,这类似于导出。
使用的时候,可以利用require('common')来导入该函数库,这里的common是函数库的文件名。
3)实现商品查询
最后,我们修改/usr/local/openresty/lua/item.lua文件,利用封装的函数库实现对tomcat的查询:
-- 引入自定义common工具模块,返回值是common中返回的 _M
local common = require("common")
-- 从 common中获取read_http这个函数
local read_http = common.read_http
-- 获取路径参数
local id = ngx.var[1]
-- 根据id查询商品
local itemJSON = read_http("/item/".. id, nil)
-- 根据id查询商品库存
local itemStockJSON = read_http("/item/stock/".. id, nil)这里查询到的结果是json字符串,并且包含商品、库存两个json字符串,页面最终需要的是把两个json拼接为一个json:

这就需要我们先把JSON变为lua的table,完成数据整合后,再转为JSON。
4.4.3.CJSON工具类
OpenResty提供了一个cjson的模块用来处理JSON的序列化和反序列化。
1)引入cjson模块:
local cjson = require "cjson"2)序列化:
local obj = {name = 'jack',age = 21
}
-- 把 table 序列化为 json
local json = cjson.encode(obj)3)反序列化:
local json = '{"name": "jack", "age": 21}'
-- 反序列化 json为 table
local obj = cjson.decode(json);
print(obj.name)4.4.4.实现Tomcat查询
下面,我们修改之前的item.lua中的业务,添加json处理功能:
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
-- 导入cjson库
local cjson = require('cjson')-- 获取路径参数
local id = ngx.var[1]
-- 根据id查询商品
local itemJSON = read_http("/item/".. id, nil)
-- 根据id查询商品库存
local itemStockJSON = read_http("/item/stock/".. id, nil)-- JSON转化为lua的table
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)-- 组合数据
item.stock = stock.stock
item.sold = stock.sold-- 把item序列化为json 返回结果
ngx.say(cjson.encode(item))4.4.5.基于ID负载均衡
刚才的代码中,我们的tomcat是单机部署。而实际开发中,tomcat一定是集群模式:
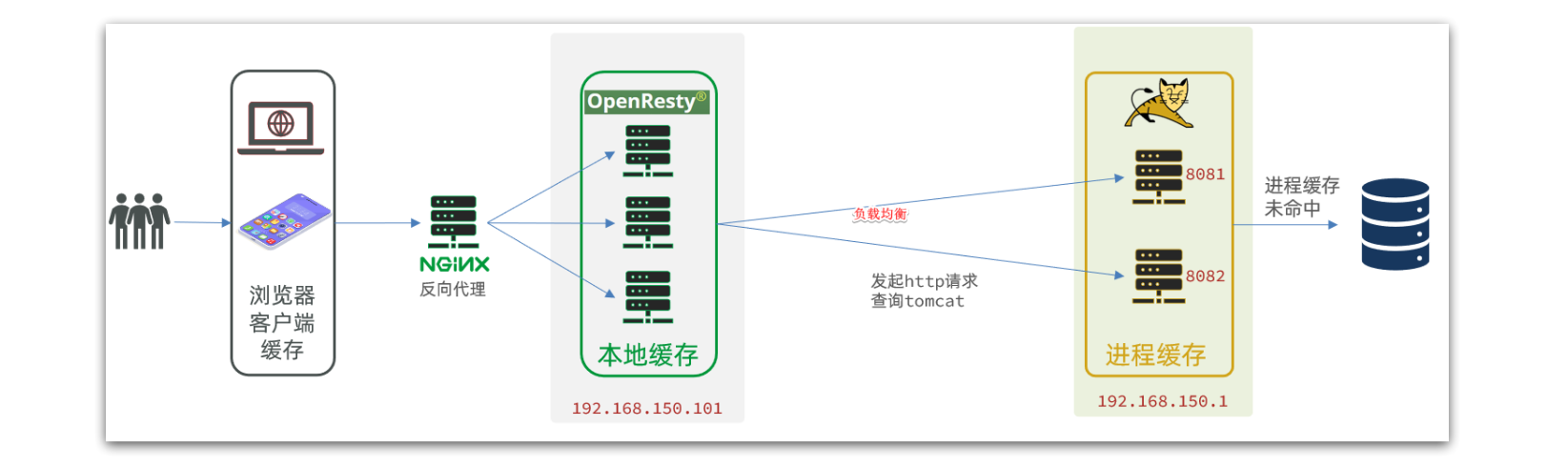
OpenResty 默认轮询负载均衡 Tomcat 集群,导致 JVM 缓存(进程内不可共享)命中率低 —— 如查询 /item/10001,首次访问 8081 生成缓存,下次轮询到 8082 仍需查库,缓存未复用。
方案:基于商品 ID(请求路径)做负载均衡,而非轮询。
1)原理
nginx提供了基于请求路径做负载均衡的算法:
- 利用 Nginx 路径 Hash 负载均衡算法:对请求路径(如 /item/10001)做 Hash 运算,结果对 Tomcat 节点数取余。
- 余数固定对应某一 Tomcat(如 2 台节点时,/item/10001 Hash 取余结果固定,始终指向同一节点),确保同一商品每次访问同一 Tomcat,JVM 缓存必生效。
2)实现
修改/usr/local/openresty/nginx/conf/nginx.conf文件,实现基于ID做负载均衡。
首先,定义tomcat集群,并设置基于路径做负载均衡:
upstream tomcat-cluster {hash $request_uri;server 192.168.150.1:8081;server 192.168.150.1:8082;
}然后,修改对tomcat服务的反向代理,目标指向tomcat集群:
location /item {proxy_pass http://tomcat-cluster;
}重新加载OpenResty
nginx -s reload4.5.Redis缓存预热
Redis缓存会面临冷启动问题:
冷启动:服务刚刚启动时,Redis中并没有缓存,如果所有商品数据都在第一次查询时添加缓存,可能会给数据库带来较大压力。
缓存预热:在实际开发中,我们可以利用大数据统计用户访问的热点数据,在项目启动时将这些热点数据提前查询并保存到Redis中。
我们数据量较少,并且没有数据统计相关功能,目前可以在启动时将所有数据都放入缓存中。
1)利用Docker安装Redis
docker run --name redis -p 6379:6379 -d redis redis-server --appendonly yes2)在item-service服务中引入Redis依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>3)配置Redis地址
spring:redis:host: 192.168.150.1014)编写初始化类
缓存预热需要在项目启动时完成,并且必须是拿到RedisTemplate之后。
这里我们利用InitializingBean接口来实现,因为InitializingBean可以在对象被Spring创建并且成员变量全部注入后执行。
@Component
public class RedisHandler implements InitializingBean {@Autowiredprivate StringRedisTemplate redisTemplate;@Autowiredprivate IItemService itemService;@Autowiredprivate IItemStockService stockService;private static final ObjectMapper MAPPER = new ObjectMapper();@Overridepublic void afterPropertiesSet() throws Exception {// 初始化缓存// 1.查询商品信息List<Item> itemList = itemService.list();// 2.放入缓存for (Item item : itemList) {// 2.1.item序列化为JSONString json = MAPPER.writeValueAsString(item);// 2.2.存入redisredisTemplate.opsForValue().set("item:id:" + item.getId(), json);}// 3.查询商品库存信息List<ItemStock> stockList = stockService.list();// 4.放入缓存for (ItemStock stock : stockList) {// 2.1.item序列化为JSONString json = MAPPER.writeValueAsString(stock);// 2.2.存入redisredisTemplate.opsForValue().set("item:stock:id:" + stock.getId(), json);}}
}4.6.查询Redis缓存
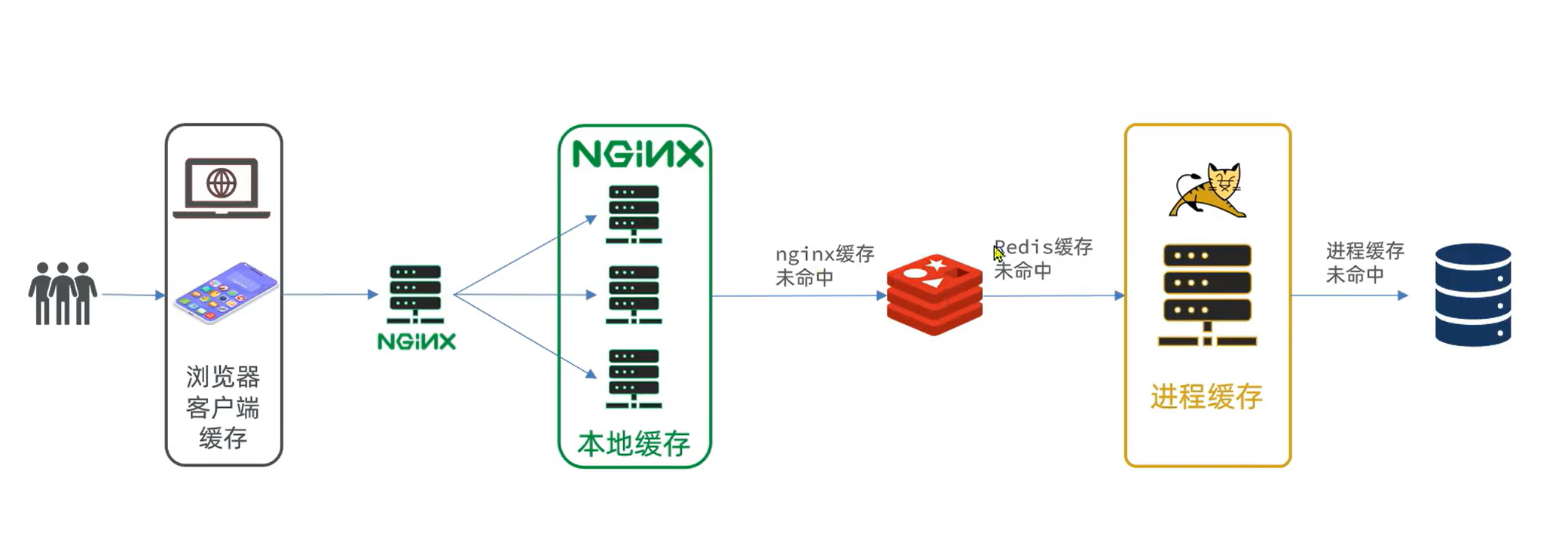
现在,Redis缓存已经准备就绪,我们可以在OpenResty中实现查询Redis的逻辑了。如红框所示:
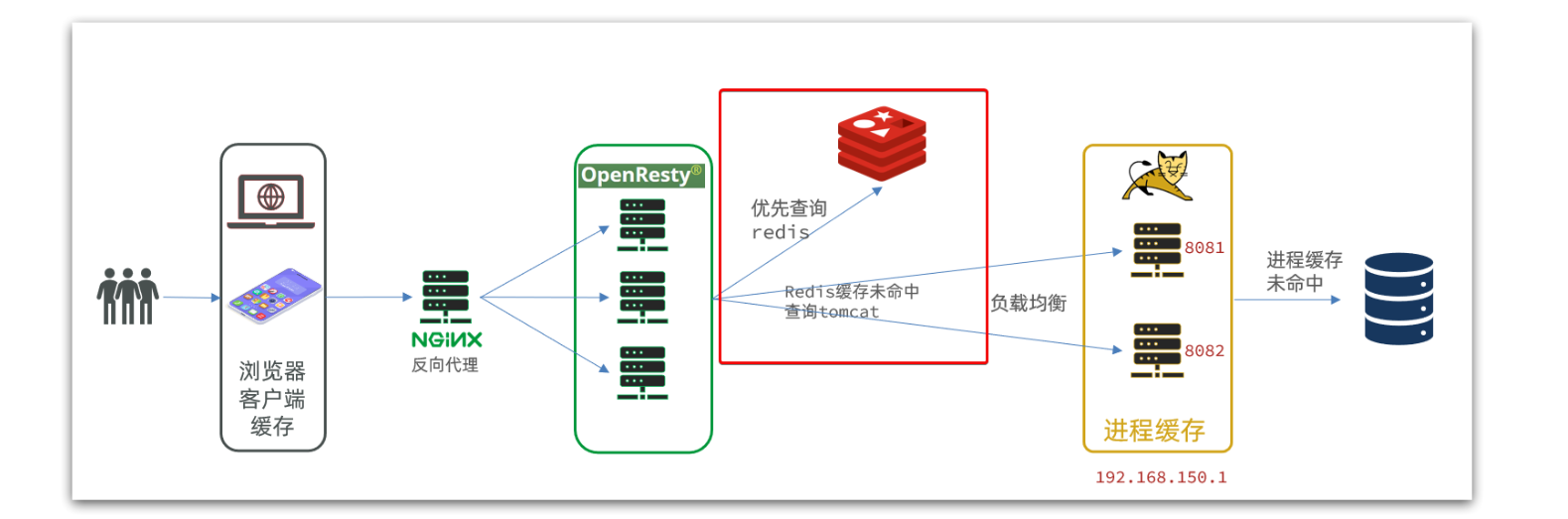
当请求进入OpenResty之后:
优先查询Redis缓存
如果Redis缓存未命中,再查询Tomcat
4.6.1.封装Redis工具
OpenResty提供了操作Redis的模块,我们只要引入该模块就能直接使用。但是为了方便,我们将Redis操作封装到之前的common.lua工具库中。
修改/usr/local/openresty/lualib/common.lua文件:
1)引入Redis模块,并初始化Redis对象
-- 导入redis
local redis = require('resty.redis')
-- 初始化redis
local red = redis:new()
red:set_timeouts(1000, 1000, 1000)2)封装函数,用来释放Redis连接,其实是放入连接池
-- 关闭redis连接的工具方法,其实是放入连接池
local function close_redis(red)local pool_max_idle_time = 10000 -- 连接的空闲时间,单位是毫秒local pool_size = 100 --连接池大小local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)if not ok thenngx.log(ngx.ERR, "放入redis连接池失败: ", err)end
end3)封装函数,根据key查询Redis数据
-- 查询redis的方法 ip和port是redis地址,key是查询的key
local function read_redis(ip, port, key)-- 获取一个连接local ok, err = red:connect(ip, port)if not ok thenngx.log(ngx.ERR, "连接redis失败 : ", err)return nilend-- 查询redislocal resp, err = red:get(key)-- 查询失败处理if not resp thenngx.log(ngx.ERR, "查询Redis失败: ", err, ", key = " , key)end--得到的数据为空处理if resp == ngx.null thenresp = nilngx.log(ngx.ERR, "查询Redis数据为空, key = ", key)endclose_redis(red)return resp
end4)导出
-- 将方法导出
local _M = { read_http = read_http,read_redis = read_redis
}
return _M4.6.2.实现Redis查询
接下来,我们就可以去修改item.lua文件,实现对Redis的查询了。
查询逻辑是:
根据id查询Redis
如果查询失败则继续查询Tomcat
将查询结果返回
代码实现:
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
local read_redis = common.read_redis
-- 导入cjson库
local cjson = require('cjson')-- 封装查询函数
function read_data(key, path, params)-- 查询本地缓存local val = read_redis("127.0.0.1", 6379, key)-- 判断查询结果if not val thenngx.log(ngx.ERR, "redis查询失败,尝试查询http, key: ", key)-- redis查询失败,去查询httpval = read_http(path, params)end-- 返回数据return val
end-- 获取路径参数
local id = ngx.var[1]-- 查询商品信息
local itemJSON = read_data("item:id:" .. id, "/item/" .. id, nil)
-- 查询库存信息
local stockJSON = read_data("item:stock:id:" .. id, "/item/stock/" .. id, nil)-- JSON转化为lua的table
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)
-- 组合数据
item.stock = stock.stock
item.sold = stock.sold-- 把item序列化为json 返回结果
ngx.say(cjson.encode(item))5.缓存同步
大多数情况下,浏览器查询到的都是缓存数据,如果缓存数据与数据库数据存在较大差异,可能会产生比较严重的后果。
所以我们必须保证数据库数据、缓存数据的一致性,这就是缓存与数据库的同步。
5.1.数据同步策略
缓存数据同步的常见方式有三种:
设置有效期:给缓存设置有效期,到期后自动删除。再次查询时更新
优势:简单、方便
缺点:时效性差,缓存过期之前可能不一致
场景:更新频率较低,时效性要求低的业务
同步双写:在修改数据库的同时,直接修改缓存
优势:时效性强,缓存与数据库强一致
缺点:有代码侵入,耦合度高;
场景:对一致性、时效性要求较高的缓存数据
异步通知:修改数据库时发送事件通知,相关服务监听到通知后修改缓存数据
优势:低耦合,可以同时通知多个缓存服务
缺点:时效性一般,可能存在中间不一致状态
场景:时效性要求一般,有多个服务需要同步