Linux内核内存管理深度解析
Linux内核内存管理深度解析
——从MMU原理到实战分配策略
📚 目录
- MMU架构与地址映射原理
- 内核内存空间划分
- 内存分配四大核心机制
- 设备寄存器映射技术
- 实战案例与性能优化
- 思维导图总结
1️⃣ MMU架构与地址映射原理
MMU核心作用:
- 地址翻译:将虚拟地址(VA)转换为物理地址(PA)
- 内存保护:隔离进程空间,防止非法访问
- 访问控制:设置页面的读写/执行权限
地址转换流程:
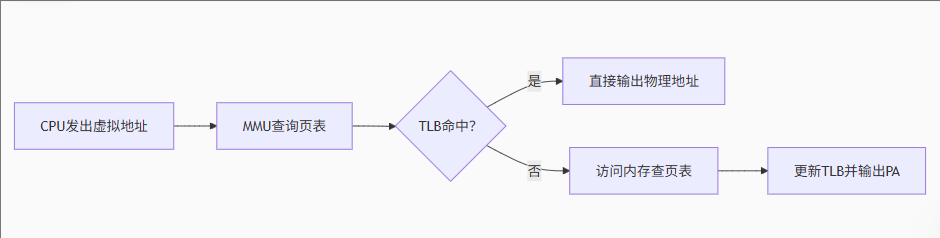
关键数据结构:
- 页表项(PTE):存储VA-PA映射关系和权限位
- TLB(快表):缓存常用地址映射,加速转换
⚠️ 开发注意:
嵌入式系统中TLB未命中可能导致5-10倍性能下降,需优化页表布局
2️⃣ 内核内存空间划分
32位系统典型布局:
0x00000000 - 0xBFFFFFFF (3GB) : 用户空间
0xC0000000 - 0xFFFFFFFF (1GB) : 内核空间├─ 0xC0000000 - 0xDFFFFFFF (896MB) : 低端内存(直接映射)└─ 0xE0000000 - 0xFFFFFFFF (128MB) : 高端内存(动态映射)
内存区域特性对比:
| 区域类型 | 地址范围 | 映射方式 | 连续性 | 适用场景 |
|---|---|---|---|---|
| 低端内存 | < 896MB | 固定映射 | 物理连续 | kmalloc, DMA |
| 高端内存 | ≥ 896MB | 动态映射 | 可能不连续 | vmalloc, 大内存分配 |
3️⃣ 内存分配四大核心机制
1. kmalloc - 小内存连续分配
#include <linux/slab.h>// 分配256字节对齐的内存
void *buf = kmalloc(256, GFP_KERNEL);
if (!buf) return -ENOMEM;// 使用后释放
kfree(buf);
特点:
- 分配物理连续内存
- 最大约4MB(依赖碎片情况)
- 标志位:
GFP_KERNEL(可休眠)/GFP_ATOMIC(原子操作)
2. vmalloc - 大内存非连续分配
#include <linux/vmalloc.h>// 分配1MB虚拟连续空间
void *mem = vmalloc(1024 * 1024);
if (!mem) return -ENOMEM;// 释放
vfree(mem);
特点:
- 虚拟地址连续,物理页不连续
- 适合大缓冲区(如视频帧处理)
- 访问速度低于kmalloc(需多次页表查询)
3. alloc_pages - 页级精确控制
#include <linux/gfp.h>// 申请2^2=4页物理内存
struct page *page = alloc_pages(GFP_KERNEL, 2);
if (!page) return -ENOMEM;// 转换为虚拟地址
void *vaddr = page_address(page);// 释放
__free_pages(page, 2);
页阶计算:
阶数0 → 1页(4KB)
阶数1 → 2页(8KB)
...
阶数10 → 1024页(4MB)
4. slab分配器 - 对象池优化
// 创建对象缓存
struct kmem_cache *cache = kmem_cache_create("my_cache", sizeof(struct my_obj),0, SLAB_HWCACHE_ALIGN, NULL);// 分配对象
struct my_obj *obj = kmem_cache_alloc(cache, GFP_KERNEL);// 释放对象
kmem_cache_free(cache, obj);// 销毁缓存
kmem_cache_destroy(cache);
适用场景:频繁创建销毁的小对象(如task_struct)
4️⃣ 设备寄存器映射技术
ioremap机制:
#include <asm/io.h>// 映射0x32b3015c开始的8字节寄存器区域
void __iomem *reg = ioremap(0x32b3015c, 8);
if (!reg) return -ENOMEM;// 读写寄存器
u32 val = ioread32(reg); // 读32位
iowrite32(0x12345678, reg); // 写32位// 解除映射
iounmap(reg);
访问函数族:
| 函数 | 位宽 | 用途 |
|---|---|---|
| ioread8/iowrite8 | 8位 | 字节寄存器访问 |
| ioread16/iowrite16 | 16位 | 半字寄存器访问 |
| ioread32/iowrite32 | 32位 | 字寄存器访问(最常用) |
⚠️ 重要提示:
- 禁止直接解引用
__iomem指针(必须使用专用函数)- ARM架构需处理字节序(
ioread32be大端访问)
5️⃣ 实战案例与性能优化
案例:DMA缓冲区分配
// 分配物理连续的DMA缓冲区
void *dma_buf = dma_alloc_coherent(dev, size, &dma_handle, GFP_KERNEL);// 使用后释放
dma_free_coherent(dev, size, dma_buf, dma_handle);
性能优化技巧:
-
kmalloc替代vmalloc:
// 优先使用kmalloc(性能提升30%+) if (size < 128 * 1024) buf = kmalloc(size, GFP_KERNEL); elsebuf = vmalloc(size); -
预分配内存池:
// 启动时预分配 static void *emergency_buf; module_init() {emergency_buf = kmalloc(1024, GFP_KERNEL); }// 关键路径使用 if (!buf) buf = emergency_buf; // 避免原子分配失败 -
高端内存优化:
// 按需映射大内存 struct page *page = alloc_pages(GFP_HIGHUSER, 5); // 分配128KB void *vaddr = vmap(&page, 32, VM_MAP, PAGE_KERNEL); // 虚拟连续映射
内存泄漏检测:
# 查看kmalloc分配统计
cat /proc/slabinfo | grep kmalloc# 跟踪内核分配
echo 1 > /proc/sys/vm/kmemleak
cat /sys/kernel/debug/kmemleak
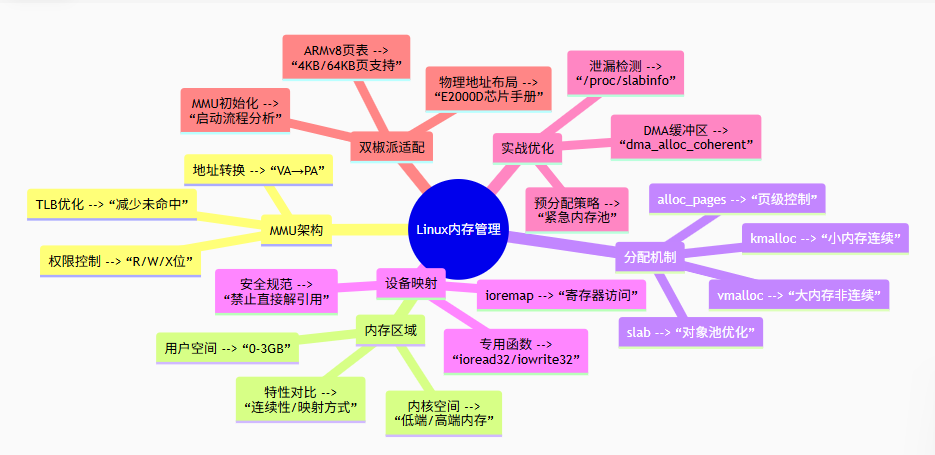
6️⃣ 思维导图总结
💡 最佳实践:
- 驱动开发:GPIO控制用
kmalloc,帧缓冲区用vmalloc- 安全规范:用户数据必须用
copy_from_user验证- 错误处理:所有分配后检查
NULL,添加__must_check属性- 性能监控:定期检查
/proc/meminfo的Slab/VmallocUsed
进阶技巧:
- CMA配置:为DMA预留连续物理内存(
dts中配置linux,cma) - HugeTLB:使用2MB大页减少TLB miss(
mmap时指定MAP_HUGETLB) - 内存热插拔:动态增减内存区域(
echo online > /sys/devices/system/memory/memoryX/state)
掌握内存管理技术,您将能:
✅ 开发高性能内核驱动 ✅ 规避内存碎片问题 ✅ 深度优化嵌入式系统
挑战任务:为双椒派E2000D的六轴陀螺仪设计零拷贝DMA驱动!欢迎分享实现方案~