【博客系统测试报告】---web界面自动化测试
目录
1、设计测试用例
2、自动化代码编写
common/Utils.py
cases/BlogLogin.py
cases/BlogList.py
cases/BlogDetail.py
cases/RunCases.py
1、设计测试用例
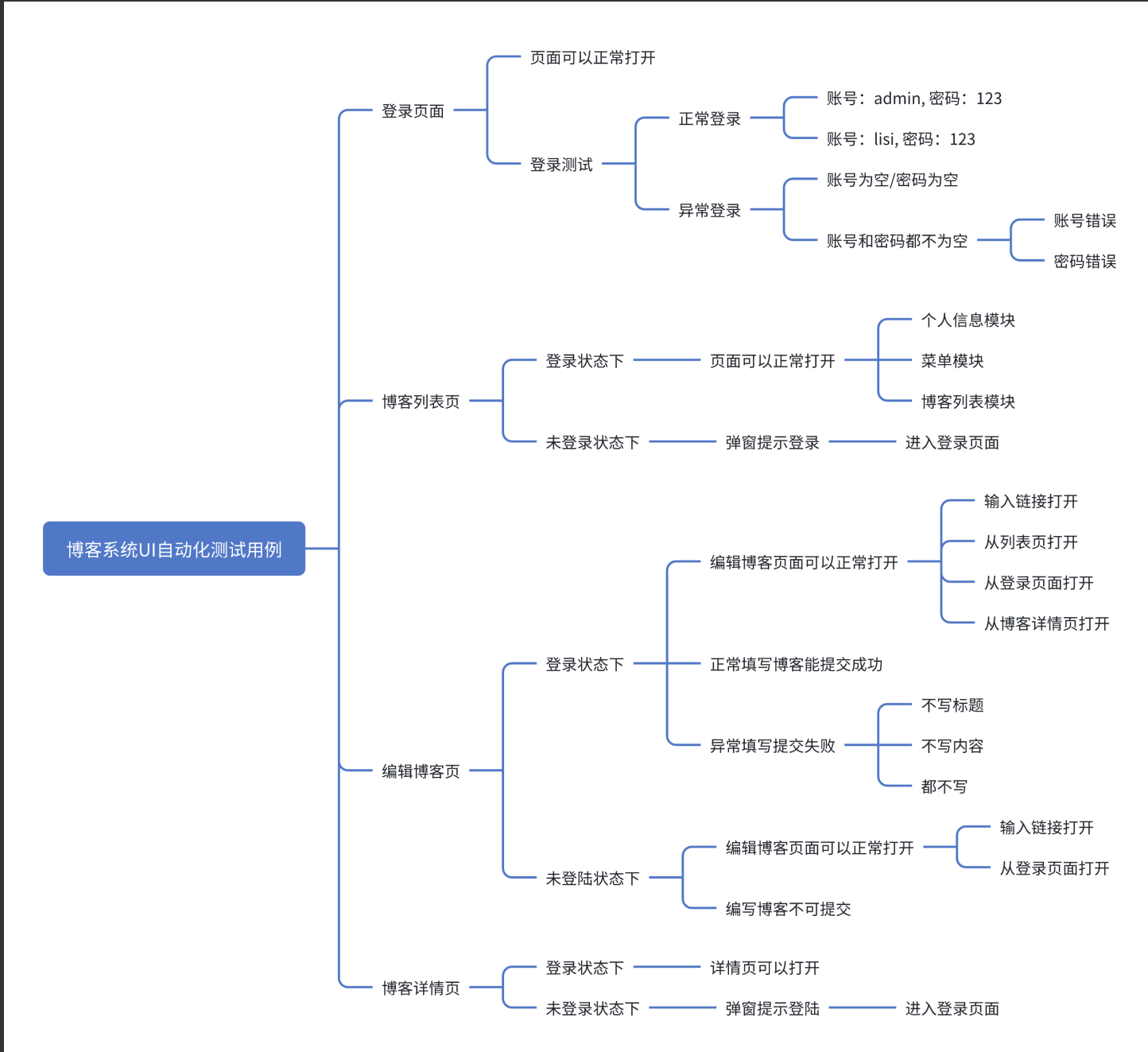
2、自动化代码编写
common/Utils.py
#创建驱动对象
# 注释:说明该模块的功能是创建Selenium的WebDriver驱动对象import datetime
# 导入datetime模块,用于处理日期和时间(主要用于截图文件名生成)import os.path
# 导入os.path模块,用于处理文件路径和目录存在性判断import sys
# 导入sys模块,用于获取调用栈信息(用于获取截图对应的方法名)from selenium import webdriver
# 从selenium库导入webdriver,用于创建浏览器驱动对象from selenium.webdriver.chrome.service import Service
# 导入Chrome驱动服务类,用于配置ChromeDriver的服务from webdriver_manager.chrome import ChromeDriverManager
# 导入ChromeDriverManager,用于自动管理ChromeDriver的安装和版本匹配class Driver:# 定义Driver类,封装浏览器驱动的创建和截图功能driver = ""# 类属性,用于存储浏览器驱动实例(初始化为空字符串)def __init__(self):# 类的初始化方法,创建浏览器驱动实例options = webdriver.ChromeOptions()# 创建Chrome浏览器的配置选项对象(可用于设置浏览器参数,如无头模式、窗口大小等)# options.page_load_strategy = 'eager'# 注释掉的代码:设置页面加载策略为'eager'(仅等待DOM加载完成,不等待资源加载),可根据需要启用self.driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()),options=options)# 创建Chrome浏览器驱动实例:# - 通过ChromeDriverManager().install()自动下载并安装匹配当前Chrome版本的驱动# - 使用Service类管理驱动服务# - 应用之前创建的配置选项options# - 将驱动实例赋值给实例属性self.driverdef getScreenShot(self):# 定义截图方法,用于在测试过程中捕获当前页面截图dirname = datetime.datetime.now().strftime('%Y-%m-%d')# 生成以当前日期(年-月-日)为名称的目录名,用于按日期分类存储截图if not os.path.exists("../images/" + dirname):# 判断截图目录是否存在(上级目录为../images,子目录为当前日期)os.mkdir("../images/" + dirname)# 若目录不存在,则创建该目录filename = sys._getframe().f_back.f_code.co_name + "-" + datetime.datetime.now().strftime('%Y-%m-%d-%H%M%S') + ".png"# 生成截图文件名:# - sys._getframe().f_back.f_code.co_name:获取调用当前方法的函数/方法名(便于定位截图对应的测试步骤)# - 拼接当前时间(年-月-日-时-分-秒)# - 以.png为后缀self.driver.save_screenshot(f'../images/{dirname}/' + filename)# 调用驱动的截图方法,将截图保存到指定路径(../images/日期/方法名-时间.png)BlogDriver = Driver()
# 创建Driver类的实例,命名为BlogDriver,供测试脚本直接使用cases/BlogLogin.py
import time
# 导入time模块,用于添加等待时间,确保页面元素加载完成from selenium.webdriver.common.by import By
# 从Selenium中导入By类,用于指定元素定位方式(如ID、CSS选择器等)from common.Utils import BlogDriver
# 从自定义的common.Utils模块中导入BlogDriver(之前创建的浏览器驱动实例)class BlogLogin:# 定义博客登录功能的测试类BlogLoginurl = ""# 类属性,用于存储登录页面的URL(初始为空)driver = ""# 类属性,用于存储浏览器驱动实例(初始为空)def __init__(self):# 类的初始化方法,用于设置登录页面URL、获取驱动并打开页面self.url = "http://192.168.47.135:8653/blog_system/blog_login.html"# 初始化实例属性url,设置登录页面的具体URLself.driver = BlogDriver.driver# 将实例属性driver赋值为全局的BlogDriver.driver(共享同一个浏览器驱动)self.driver.get(self.url)# 调用驱动的get方法,打开登录页面def loginSucTest(self):# 定义登录成功的测试方法time.sleep(2)# 强制等待2秒,确保页面元素加载完成(实际测试中可替换为显式等待)self.driver.find_element(By.CSS_SELECTOR, "#username").clear()# 通过CSS选择器定位用户名输入框,并清空内容self.driver.find_element(By.CSS_SELECTOR, "#password").clear()# 通过CSS选择器定位密码输入框,并清空内容self.driver.find_element(By.CSS_SELECTOR, "#username").send_keys("admin")# 在用户名输入框中输入"admin"self.driver.find_element(By.CSS_SELECTOR, "#password").send_keys("123")# 在密码输入框中输入"123"self.driver.find_element(By.CSS_SELECTOR, "#submit").click()# 通过CSS选择器定位登录按钮,并点击# 对登录结果进行检测,如果跳转到了博客列表页才算是登录成功了self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.left > div > img")# 通过定位博客列表页特有的元素(左侧区域的图片)来验证是否登录成功# 若元素不存在,会抛出NoSuchElementException,表明登录失败BlogDriver.getScreenShot()# 调用截图方法,保存登录成功后的页面截图self.driver.back()# 调用浏览器的后退功能,返回登录页面,为后续测试做准备def loginFailTest(self):# 定义登录失败的测试方法self.driver.find_element(By.CSS_SELECTOR, "#username").clear()# 清空用户名输入框self.driver.find_element(By.CSS_SELECTOR, "#password").clear()# 清空密码输入框self.driver.find_element(By.CSS_SELECTOR, "#username").send_keys("admin")# 输入用户名"admin"self.driver.find_element(By.CSS_SELECTOR, "#password").send_keys("111")# 输入错误的密码"111"(预期登录失败)self.driver.find_element(By.CSS_SELECTOR, "#submit").click()# 点击登录按钮# 等登录失败的结果进行检测,不能仅仅通过body来校验结果,因为登录成功的结果页也有body元素expect = "用户名或密码错误!"# 定义预期的错误提示信息actual = self.driver.find_element(By.CSS_SELECTOR, "body").text# 获取页面body元素的文本内容(实际错误提示)print(actual)# 打印实际错误提示,便于调试BlogDriver.getScreenShot()# 保存登录失败后的页面截图assert expect == actual# 断言预期提示与实际提示一致,验证登录失败场景的正确性self.driver.back()# 后退到登录页面,为后续测试做准备cases/BlogList.py
from selenium.webdriver.common.by import By
# 从Selenium导入By类,用于指定元素定位方式(如CSS选择器)from common.Utils import BlogDriver
# 从自定义模块导入全局浏览器驱动实例BlogDriverclass BlogList:# 定义博客列表页的测试类BlogListurl = ""# 类属性,用于存储博客列表页的URL(初始为空)driver = ""# 类属性,用于存储浏览器驱动实例(初始为空)def __init__(self):# 类的初始化方法,初始化驱动和页面URL并打开页面self.driver = BlogDriver.driver# 将实例属性driver赋值为全局的BlogDriver.driver(共享浏览器驱动)self.url = "http://192.168.47.135:8653/blog_system/blog_list.html"# 初始化实例属性url,设置博客列表页的具体URLself.driver.get(self.url)# 调用驱动的get方法,打开博客列表页# 前提:登陆状态下才能进⼊到列表⻚def ListTest(self):# 定义列表页的测试方法,验证列表页功能# 定位列表页左侧的图片元素(确认页面加载完成且处于登录状态)self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.left > div > img")# 定位列表页右侧的第一篇文章链接(验证文章列表存在)self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div:nth-child(1) > a")# 获取所有文章元素(通过CSS选择器定位右侧所有文章容器)articles = self.driver.find_elements(By.CSS_SELECTOR, "body > div.container > div.right > div")# 断言文章数量大于10(验证列表页有足够的文章数据)assert len(articles) > 10# 点击第一篇文章的链接self.driver.find_element(By.CSS_SELECTOR,"body > div.container > div.right > div:nth-child(1) > a").click()# 获取当前页面的标题title = self.driver.title# 断言页面标题为"博客详情⻚"(验证点击文章后成功跳转到详情页)assert title == "博客详情⻚"# 调用截图方法,保存跳转后的详情页截图BlogDriver.getScreenShot()cases/BlogDetail.py
from selenium.webdriver.common.by import By
# 从Selenium导入By类,用于指定元素定位方式(如CSS选择器)from common.Utils import BlogDriver
# 从自定义模块导入全局浏览器驱动实例BlogDriverclass BlogDetail:# 定义博客详情页的测试类BlogDetailurl = " "# 类属性,用于存储博客详情页的URL(初始为空格,后续会赋值)driver = ""# 类属性,用于存储浏览器驱动实例(初始为空)def __init__(self):# 类的初始化方法,处理详情页的访问逻辑self.url = "http://192.168.47.135:8653/blog_system/blog_detail.html?blogId=15"# 初始化实例属性url,设置具体的博客详情页URL(包含blogId参数,指定具体文章)self.driver = BlogDriver.driver# 将实例属性driver赋值为全局的BlogDriver.driver(共享浏览器驱动)title = self.driver.title# 获取当前浏览器页面的标题# 列表页已经跳过来了,无需再指定url跳转if not title == "博客列表⻚":# 判断当前页面是否不是博客列表页# (若从列表页点击文章跳转过来,当前页面已在详情页,无需重复跳转)self.driver.get(self.url)# 若当前不在列表页,则主动访问详情页URLdef DetailCheck(self):# 定义详情页检查方法,验证详情页元素是否正常显示BlogDriver.getScreenShot()# 调用截图方法,保存当前详情页的截图# 定位并检查详情页的标题元素(h3标签)self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div > h3")# 定位并检查详情页的日期元素(class为date的div)self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div > div.date")# 定位并检查详情页的内容元素(id为content的元素)self.driver.find_element(By.CSS_SELECTOR, "#content")cases/RunCases.py
from common.Utils import BlogDriver
# 从自定义的common.Utils模块中导入全局浏览器驱动实例BlogDriver
# (该实例封装了Chrome浏览器驱动,供所有测试类共享)from tests import BlogLogin
# 从tests模块中导入BlogLogin类(包含登录功能的测试方法)from tests import BlogList
# 从tests模块中导入BlogList类(包含博客列表页的测试方法)from tests import BlogDetail
# 从tests模块中导入BlogDetail类(包含博客详情页的测试方法)if __name__ == "__main__":# 主程序入口:当该脚本被直接运行时,执行以下测试流程BlogLogin.BlogLogin().loginSucTest()# 1. 执行登录成功的测试:# - 实例化BlogLogin类(会自动打开登录页面)# - 调用loginSucTest()方法,使用正确的账号密码完成登录BlogList.BlogList().ListTest()# 2. 执行博客列表页的测试:# - 实例化BlogList类(会自动打开列表页,依赖上一步的登录状态)# - 调用ListTest()方法,验证列表页元素、文章数量及跳转功能BlogDetail.BlogDetail().DetailCheck()# 3. 执行博客详情页的测试:# - 实例化BlogDetail类(基于列表页的跳转或直接访问详情页)# - 调用DetailCheck()方法,验证详情页的标题、日期、内容等核心元素BlogDriver.driver.quit()# 4. 测试流程结束后,关闭浏览器驱动,释放资源