Elasticsearch:如何使用 Qwen3 来做向量搜索
在这篇文章中,我们将使用 Qwen3 来针对数据进行向量搜索。我们将对数据使用 qwen3 嵌入模型来进行向量化,并使用 Qwen3 来对它进行推理。在阅读这篇文章之前,请阅读之前的文章 “如何使用 Ollama 在本地设置并运行 Qwen3”。
安装
Elasticsearch 及 Kibana
如果你还没有安装自己的 Elasticsearch 及 Kibana,那么请阅读这篇文章 “使用 start-local 脚本在本地运行 Elasticsearch” 来进行安装。在默认的情况下,他没有 SSL 的配置:
$ curl -fsSL https://elastic.co/start-local | sh______ _ _ _ | ____| | | | (_) | |__ | | __ _ ___| |_ _ ___ | __| | |/ _` / __| __| |/ __|| |____| | (_| \__ \ |_| | (__ |______|_|\__,_|___/\__|_|\___|
-------------------------------------------------
🚀 Run Elasticsearch and Kibana for local testing
-------------------------------------------------ℹ️ Do not use this script in a production environment⌛️ Setting up Elasticsearch and Kibana v9.1.2-arm64...- Generated random passwords
- Created the elastic-start-local folder containing the files:- .env, with settings- docker-compose.yml, for Docker services- start/stop/uninstall commands
- Running docker compose up --wait[+] Running 6/6✔ Network elastic-start-local_default Created 0.1s ✔ Volume "elastic-start-local_dev-kibana" Create... 0.0s ✔ Volume "elastic-start-local_dev-elasticsearch" Created 0.0s ✔ Container es-local-dev Healthy 22.0s ✔ Container kibana-local-settings Exited 21.9s ✔ Container kibana-local-dev Healthy 31.9s 🎉 Congrats, Elasticsearch and Kibana are installed and running in Docker!🌐 Open your browser at http://localhost:5601Username: elasticPassword: u06Imqiu🔌 Elasticsearch API endpoint: http://localhost:9200
🔑 API key: QzNJQnA1Z0JiSkRyN2UwaUk3VFQ6dXFrdkFvRkt1UXlJX2Z1bm5qblpndw==Learn more at https://github.com/elastic/start-local
在我安装完毕后,我得到的最新的 Elasticsearch 版本是 9.1.2。
写入数据到 Elasticsearch
我们使用如下的代码把数据写入到 Elasticsearch:
elasticsearch_qwen3.py
from langchain_community.vectorstores import ElasticsearchStore
from langchain_community.embeddings import OllamaEmbeddings# Replace with your actual Elasticsearch endpoint
ELASTICSEARCH_URL = "http://localhost:9200"
INDEX_NAME = "my_embeddings_index"# Initialize Ollama embeddings (you can specify model if needed)
embeddings = OllamaEmbeddings(model="qwen3")# Create ElasticsearchStore index
vectorstore = ElasticsearchStore(embedding=embeddings,es_url=ELASTICSEARCH_URL,index_name=INDEX_NAME,es_user = "elastic",es_password = "u06Imqiu"
)# Example: Add documents to the index
str1 = "阿里巴巴(中国)有限公司成立于2007年03月26日,法定代表人蒋芳"
str2 = "百度是拥有强大互联网基础的领先AI公司。百度愿景是:成为最懂用户,并能帮助人们成长的全球顶级高科技公司。于2000年1月1日在中关村创建了百度公司"docs = [ str1, str2 ]
vectorstore.add_texts(docs)print(f"Index '{INDEX_NAME}' created and documents added.")我们需要安装如下的 Python 包:
pip install langchain_community在上面,我们使用 qwen3 嵌入模型把输入的句子进行向量化。在这里,我们可以使用其它的任何嵌入模型。 运行以上的代码:
python3 elasticsearh_qwen3.py$ python3 elasticsearch_qwen3.py
Index 'my_embeddings_index' created and documents added.我们可以在 Kibana 中进行查看:
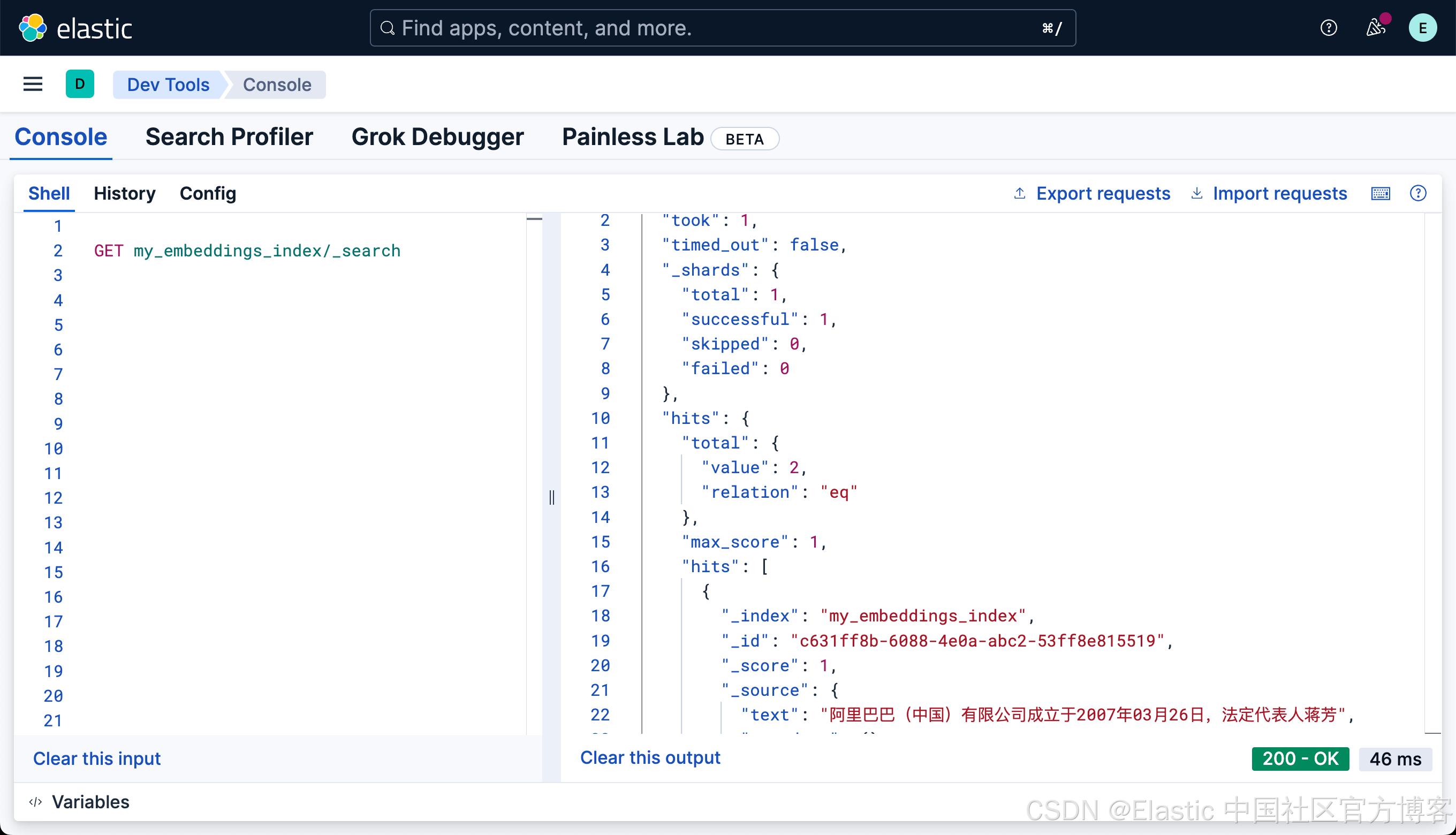
我们可以看到有两个文档被写入。
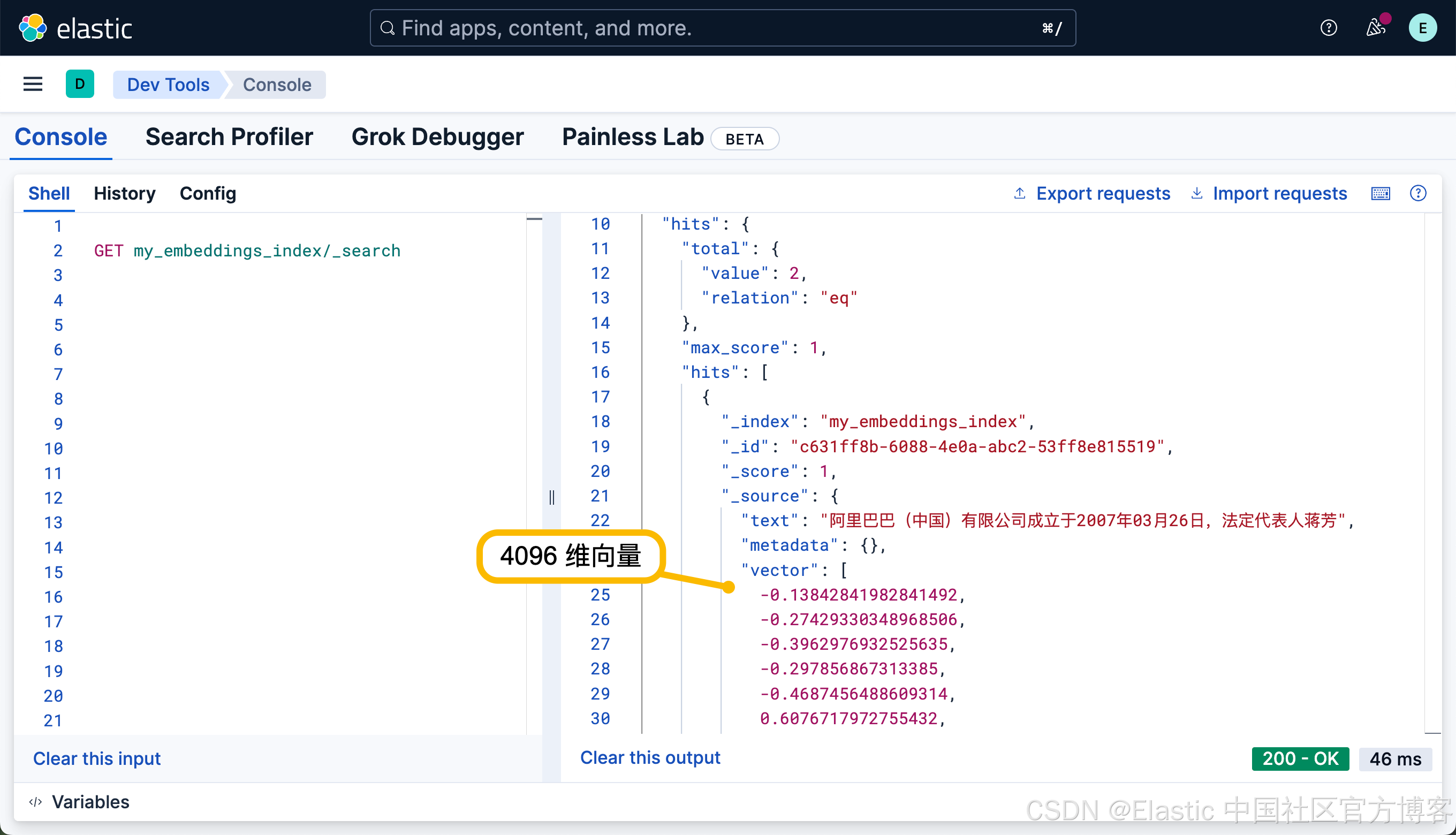
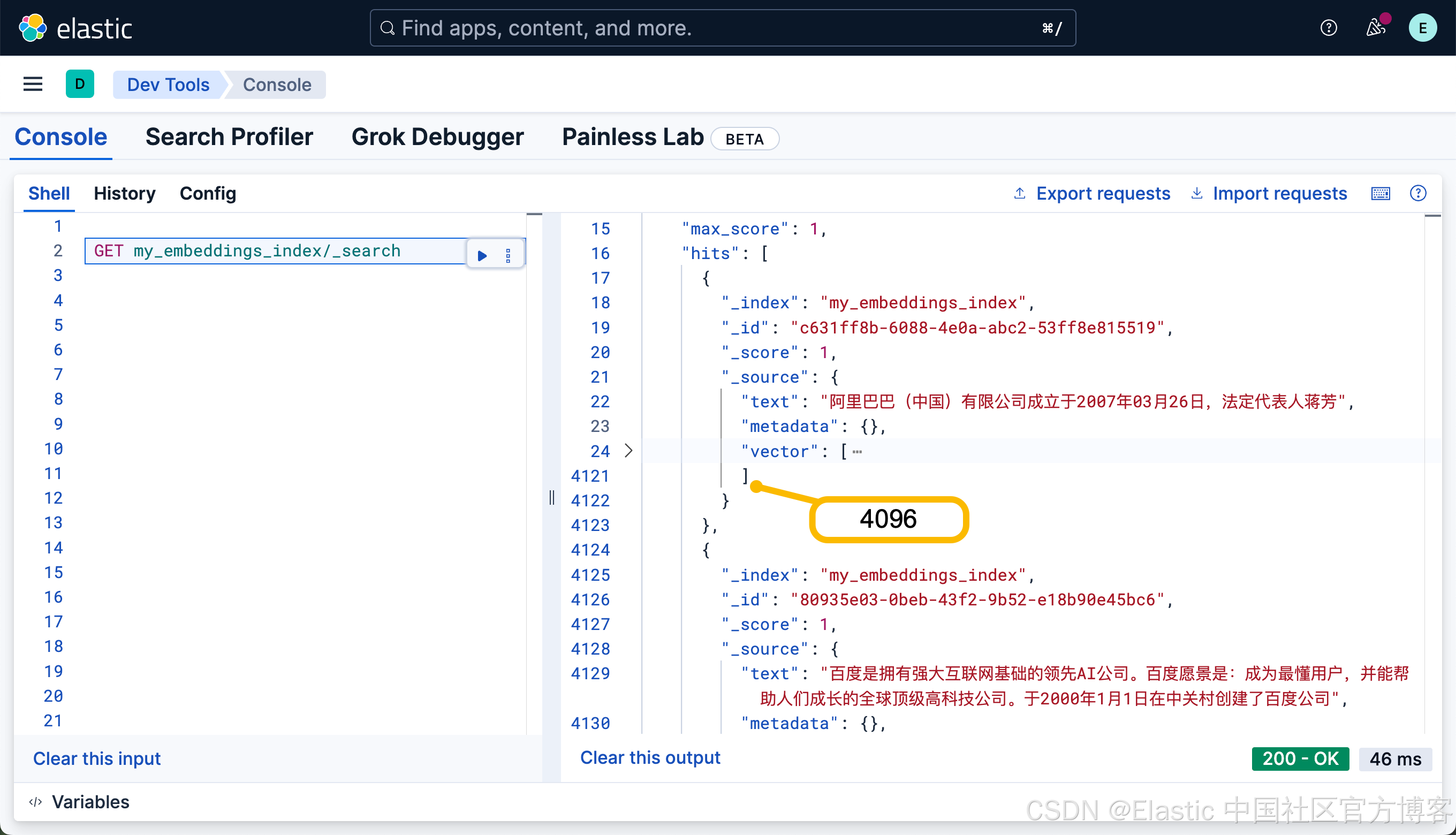
这个是因为我们的模型 qwen3:8b 是 4096 维的。
从上面我们也可以看出来所生成的向量。我们可以通过如下的命令来查看它的 mapping:
GET my_embeddings_index/_mapping{"my_embeddings_index": {"mappings": {"properties": {"metadata": {"type": "object"},"text": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"vector": {"type": "dense_vector","dims": 4096,"index": true,"similarity": "cosine","index_options": {"type": "bbq_hnsw","m": 16,"ef_construction": 100,"rescore_vector": {"oversample": 3}}}}}}
}我们可以看到有一个叫做 text 及 vector 的字段。
我们可以使用如下的命令来对它进行向量搜索:
elasticsearch_qwen3.py
from langchain_community.vectorstores import ElasticsearchStore
from langchain_community.embeddings import OllamaEmbeddings# Replace with your actual Elasticsearch endpoint
ELASTICSEARCH_URL = "http://localhost:9200"
INDEX_NAME = "my_embeddings_index"# Initialize Ollama embeddings (you can specify model if needed)
embeddings = OllamaEmbeddings(model="qwen3")# Create ElasticsearchStore index
vectorstore = ElasticsearchStore(embedding=embeddings,es_url=ELASTICSEARCH_URL,index_name=INDEX_NAME,es_user = "elastic",es_password = "u06Imqiu"
)if not vectorstore.client.indices.exists(index=INDEX_NAME):print(f"Index '{INDEX_NAME}' already exists.")# Example: Add documents to the indexstr1 = "阿里巴巴(中国)有限公司成立于2007年03月26日,法定代表人蒋芳"str2 = "百度是拥有强大互联网基础的领先AI公司。百度愿景是:成为最懂用户,并能帮助人们成长的全球顶级高科技公司。于2000年1月1日在中关村创建了百度公司"docs = [ str1, str2 ]vectorstore.add_texts(docs,bulk_kwargs={"chunk_size": 300,"max_chunk_bytes": 4096})print(f"Index '{INDEX_NAME}' created and documents added.")results = vectorstore.similarity_search(query=" alibaba法定代表人是谁"# k=1# filter=[{"term": {"metadata.source.keyword": "tweet"}}],
)# print(results, len(results))for res in results:print(f"* {res.page_content}")运行上面的代码:
$ python3 elasticsearch_qwen3.py
* 阿里巴巴(中国)有限公司成立于2007年03月26日,法定代表人蒋芳
* 百度是拥有强大互联网基础的领先AI公司。百度愿景是:成为最懂用户,并能帮助人们成长的全球顶级高科技公司。于2000年1月1日在中关村创建了百度公司我们把 query 改为:
results = vectorstore.similarity_search(query="中国的搜索引擎公司是哪个"# k=1# filter=[{"term": {"metadata.source.keyword": "tweet"}}],
)$ python3 elasticsearch_qwen3.py
* 百度是拥有强大互联网基础的领先AI公司。百度愿景是:成为最懂用户,并能帮助人们成长的全球顶级高科技公司。于2000年1月1日在中关村创建了百度公司
* 阿里巴巴(中国)有限公司成立于2007年03月26日,法定代表人蒋芳我们把搜索的 query 改为:
results = vectorstore.similarity_search(query="淘宝"# k=1# filter=[{"term": {"metadata.source.keyword": "tweet"}}],
)$ python3 elasticsearch_qwen3.py
* 阿里巴巴(中国)有限公司成立于2007年03月26日,法定代表人蒋芳
* 百度是拥有强大互联网基础的领先AI公司。百度愿景是:成为最懂用户,并能帮助人们成长的全球顶级高科技公司。于2000年1月1日在中关村创建了百度公司results = vectorstore.similarity_search(query="阿里巴巴的法人代表"# k=1# filter=[{"term": {"metadata.source.keyword": "tweet"}}],
)$ python3 elasticsearch_qwen3.py
* 阿里巴巴(中国)有限公司成立于2007年03月26日,法定代表人蒋芳
* 百度是拥有强大互联网基础的领先AI公司。百度愿景是:成为最懂用户,并能帮助人们成长的全球顶级高科技公司。于2000年1月1日在中关村创建了百度公司