Linux下命名管道和共享内存
1.温故知新
我们在上一篇中讲了我们进程间通信的本质就是让我们不同的进程看到同一份资源就可以了,为了达到这个目的,父子间进程利用了它们的特性,我们子进程继承父进程文件描述符表的特性,我们直接把我们的匿名管道切断与磁盘的IO,因为进程间通信不需要与磁盘,只在内存间进行 数据传递,然后我们再让我们的子进程复制一份父进程的file,原来它们指向同一个file,现在复制一份出来,让它们的读端和写端不同。然后我们的管道是基于阻塞原理的,管道写端关闭,读端读到0,管道写端关闭,直接发信号,进程崩掉,这是我们具有血缘关系的进程间通信采用。
管道还有一些特性,是我们比较容易理解的,管道是单向通信的,信息是单向流动的,管道的生命周期随进程,进程崩掉,就没有进行进程间通信的必要了,下一个,匿名管道用于有血缘关系的进程,下一个,数据是在文件内核缓冲区中的,读写自动阻塞。
2.命名管道
匿名管道是我们用于具有血缘关系的进程间进行通信的,那我们如果想让没有血缘关系的进程间通信要怎么办呢?就是要请出命名管道的概念的。根据Linux一一切皆文件,我们知道命名管道也是一个特殊文件。
我们匿名管道的创建用pipe系统调用,我们的命名管道创建用到mkfifo。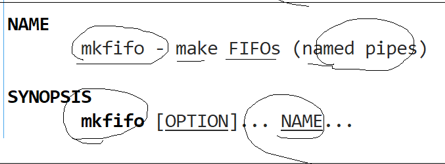
FIFO与pipe除了创建方式与打开方式不同,一旦这些工作完成之后,它们具有相同的语义。
进程A和进程B是不同的进程,它们可以通过访问命名管道进行进程间的通信。
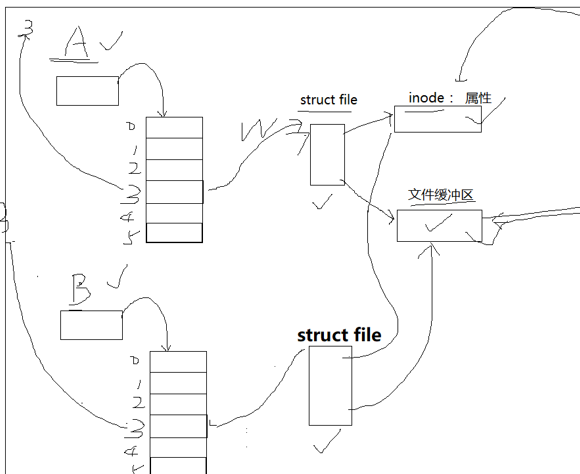
我们有一个问题:我们多进程可以打开同一个文件吗?
当然可以,不然我们不同的进程跑起来往一个显示器上打印,不就往一个显示器文件里打印吗?
操作系统不会重复加载文件的数据和内容。
那么我们创建一个命名管道我们不同的进程是怎么看到同一个命名管道的,是因为我们的路径是唯一的,路径唯一,inode对应的文件名就是唯一的。
为什么mkfifo是命名管道?因为我们创建一个特殊文件,文件本身就是有名字的。
一句话总结上述内容:命名管道,就是为了解决我们没有血缘关系的进程间通信提出的方案,统一不需要和磁盘进行IO,除了创建方式与匿名管道有所不同,其它特点都和我们的匿名管道相同。它的生命周期和进程也是相同的。

讲解完了进程间通信的两种方案:匿名管道和命名管道,我们下面再来认识一种方案叫做共享内存。
我们先对匿名管道和命名管道做一个总结吧,匿名管道用于有血缘关系的进程间通信,父子进程共享一个内核缓冲区,不和磁盘进行IO,提高我们的效率,它的生命周期和进程的生命周期相同.
下面给出我们的利用命名管道实现进程间通信的模范,一个客服端,一个服务端。
#include "common.hpp"
#include<string>#include <string.h>#include<iostream>using namespace std;
int main()
{//客户端int fd=open(fifoname.c_str(),O_WRONLY);//和服务端打开同一个文件if(fd<0){perror("open");return 1;}char buffer[1024]={0};while(true){buffer[0]='0';cout<<"请输入消息:";cin>>buffer;ssize_t n = write(fd,buffer,strlen(buffer));if(n<0){perror("write");break;}
}return 0;
}
#include <string.h>
#include<iostream>using namespace std;
#include "common.hpp"#include <sys/types.h>#include <sys/stat.h>#include <fcntl.h>
int main()
{//1.创建一个命名管道int n = mkfifo(fifoname.c_str(), mode);if (n == 0){std::cout << "mkfifo success" << std::endl;}else {cout<<"创建失败!!!";}//2.打开一个命名管道int fd=open(fifoname.c_str(),O_RDONLY);if(fd<0){perror("open");return 1;}//3.阻塞读取数据char buffer[1024]={0};while(true){ssize_t n=read(fd,buffer,sizeof(buffer)-1);//数组名是首元素地址if (n <= 0) {perror("read");break;}buffer[n] = '\0'; // 确保字符串终止cout << "client say: " << buffer << endl;}close(fd);unlink(fifoname.c_str());return 0;
}
3.共享内存
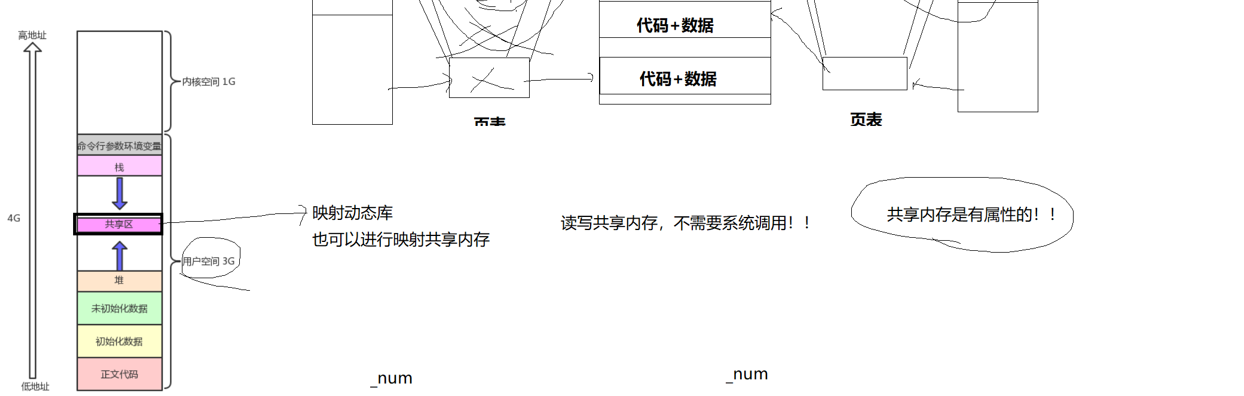
什么是共享内存?就是在让我们的不同进程的页表映射到相同的物理内存,我们不同的进程拿着虚拟地址访问同一块物理内存的空间,就是共享内存!
我们看下面的图,我们的进程A和进程B通过页表映射到物理内存的相同为止,这块在内存中被不同进程访问的内存块就是共享内存。
还是那句话,进程间通信的本质就是让不同的进程看到同一份资源,现在我们通过页表的映射不就让不同的进程看到同一份资源了吗?
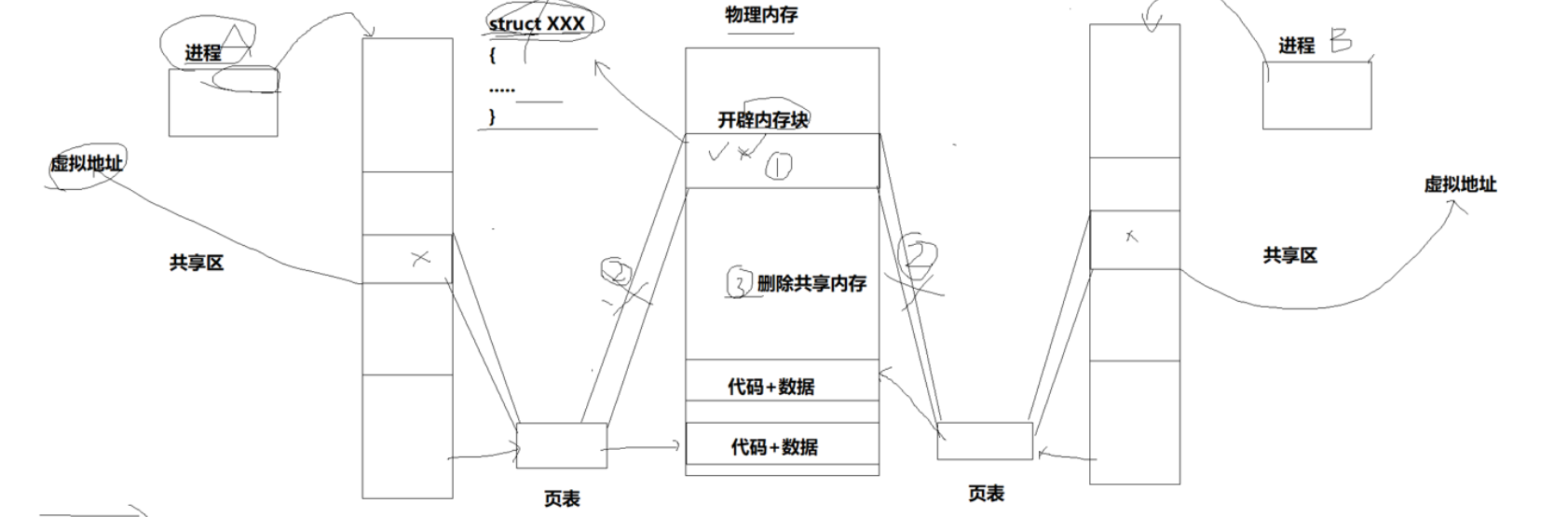

以上这些操作都是在内核里进行的,我们用户是无法创建页表,无法建立映射关系的,都是我们的操作系统帮助我们来完成这个工作的,所以我们操作系统在物理内存上建立一块共享内存空间,它会不会创建许多块共享内存空间呢?当然会,那么我们操作系统要不要把这些在内存上创建的内存块管理起来呢?当然要!怎么管理!先描述!再组织!
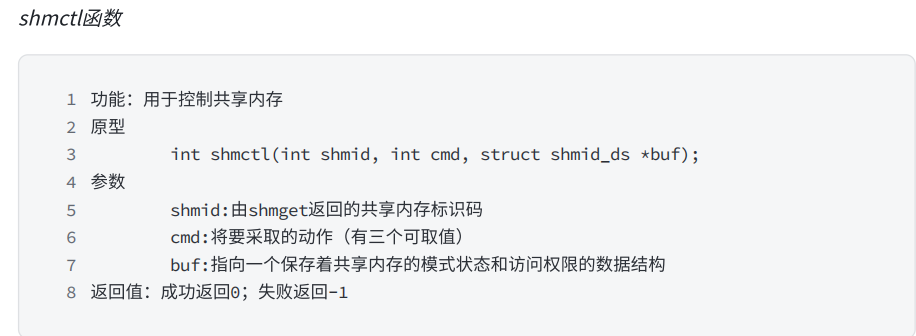
下面我们来了解一下我们创建共享内存块的系统调用接口:我们要对内存块的了解就是增删查改

我们shmget第一个参数是key,需要我们用户传入,是这个共享内存段的名字,我们的size是这个内存块的大小,建议是4096字节的整数倍,因为我们操作系统在内存中开辟空间是以4KB为单位的如果你创建了4097字节,它会开辟2个内存块供你使用,但是你只能用到4097个字节。为了避免资源浪费,我们建议开辟空间大小是4096字节的整数倍。
第三个参数是我们共享内存的权限,有不同的解释,我们看解释就可以了。
下面我们来解释一下第一个参数,它的key是用我们的ftok形成的。

这个key是全局变量,我们拿着这个key可以找到我们物理内存中 对应的物理内存块,那么我要问了,进程间通信的本质是让进程看到同一份资源,我们如果系统帮助我们创建key,我的问题是另一个通信的进程要怎么拿到这个key?

ipcs -m 可以看到我们内核中的共享内存,我们发现有这几个

我们的key是内核用的,用来标识共享内存的唯一性,而我们的shmid是给我们的用户使用的。
共享内存的生命周期是随内核的,也就是操作系统不关闭,我的共享内存不会自动释放。所以我们要注意内存泄漏的问题。

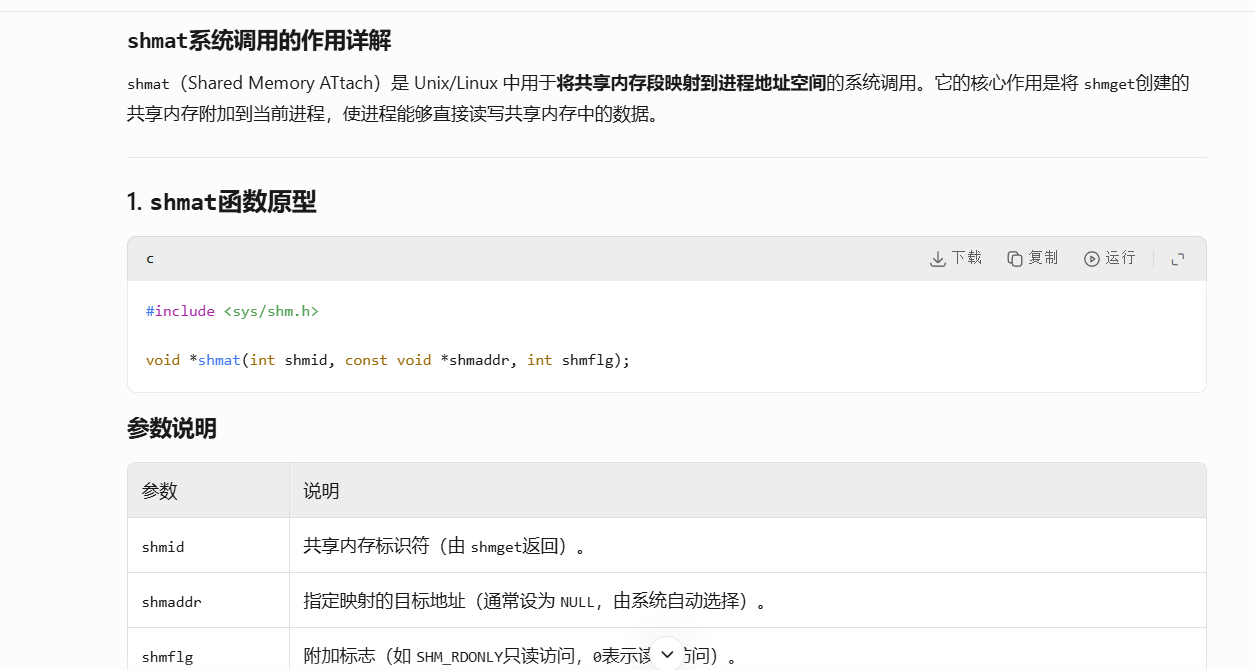
我们的共享内存从创建到使用的步骤是:先调用我们的shmget在物理内存创建一块共享内存,然后我们的shmat是建立我们物理内存和虚拟内存的映射关系,shmget成功返回一个共享内存的标识符也就是shmid,然后我们的shmat是创建虚拟与物理的映射关系,然后返回我们在进程的虚拟地址。
我们shmat返回我们的虚拟地址,我们拿着虚拟地址就可以访问我们的共享内存了。