序论文42 | patch+MLP用于长序列预测

论文标题:Unlocking the Power of Patch: Patch-Based MLP for Long-Term Time Series Forecasting
论文链接:https://arxiv.org/abs/2405.13575v3
代码链接:https://github.com/TangPeiwang/PatchMLP
(后台回复“交流”加入讨论群,回复“资源”获取2024年度论文讲解合集)
研究思路
看论文单位是讯飞,这还是第一次看见讯飞发时序的文章,但是这篇文章却问出了几个自己也曾思考过的问题,我觉得很有共鸣。先来概括研究背景,Transformer 和MLP 的表现一直是此消彼长的过程,patch TST出来之后,算是扳回一局。
但是这里就引出一个问题:Patch TST中,到底是因为patch这种处理方法,还是因为Transformer架构本身起作用?这个问题很关键,因为如果是patch这种数据处理方法起作用,那么我们也可以尝试把Patch和MLP方法结合。用朴素的控制变量思想,如果是Patch起作用的话,Patch+MLP也应该有一定的效果提升。这就是本文的一个出发点。
第二个问题:通道混合方法在多变量时间序列预测中真的无效吗?现行的sota模型似乎都用的通道独立,但是自变量之间存在关联影响也是可能的,为什么一定要通道独立呢?是方法论的问题吗?
第三个问题:简单地分解原始时间序列真的能更好地预测趋势和季节性成分吗?从结果来看,NLinear、DLinear、FITS都是这样的思路。
分析探索
为什么进行Patch后模型会更work?
从模型结构来看,Patch 能压缩数据、降低维度、减少冗余特征和平滑数据,有助于过滤噪声,保留稳定信息,增强序列局部信息,提升模型学习和捕捉局部特征的能力。但Patch 大小并非越大越好,受隐藏层大小影响,过大可能导致过度压缩;增加隐藏层维度虽能提升性能,但参数增多易引发过拟合 。这里有个很有意思的问题,iTransformer相当于整条序列做patch,那为什么模型会work?这也是一个值得探究的问题。
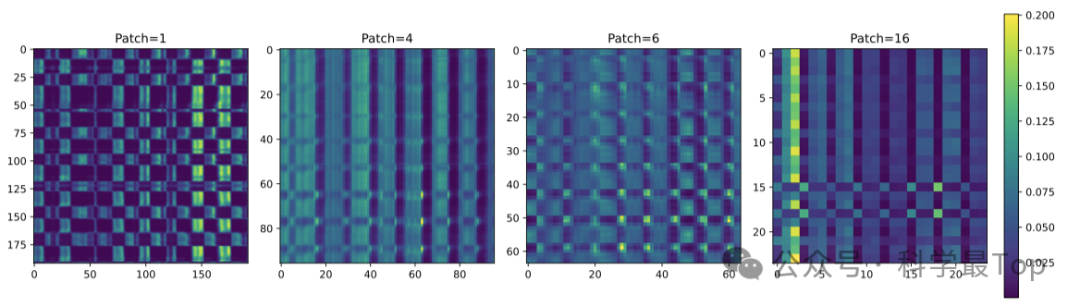
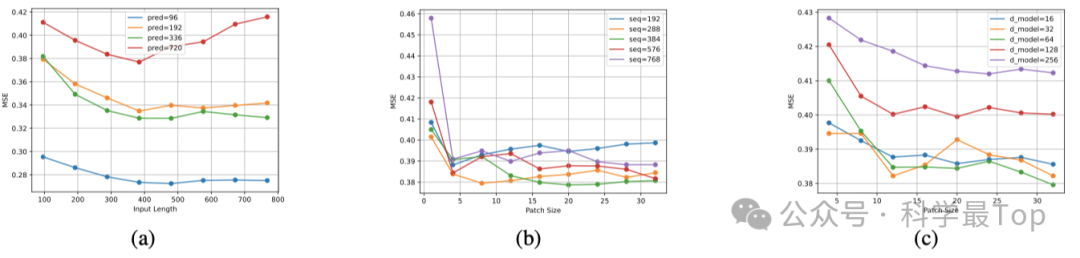
作者首先探索了Patch对Transformer的影响,将解码器层设置为一个简单的单层 MLP 。如图 2b 所示,可以看到,对于相同的输入长度,随着 Patch 大小的增加,模型的整体均方误差(MSE)呈现出先下降后上升,或者先下降后稳定的趋势。随着输入长度的增加,模型达到最佳性能所需的 Patch 大小也不断增大。
注意:在原始输入数据中,注意力机制的效果很差,核心是因为注意力机制无法有效消除噪声,而在MLP模型中大多采用了分解策略,起到了降噪作用。因此,作者认为 Transformer 的有效性并非源于注意力机制的作用,而是得益于 Patch 的存在。
本文模型
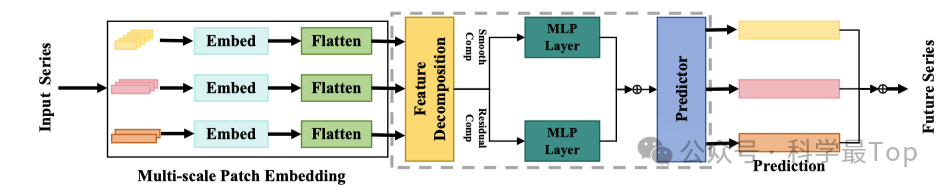
如上图所示,本文提出的PatchMLP由四个部分构成:多尺度Patch嵌入层、特征分解层、多层感知器(MLP)层和投影层。多尺度Patch嵌入层将多变量时间序列嵌入到潜在空间中。特征分解层把潜在向量分解为平滑分量和含噪残差,然后通过MLP层分别进行处理。最后,潜在向量通过投影层映射回特征空间,以获得未来序列。
-
多尺度 Patch 嵌入(Multi - Scale Patch Embedding):将多变量时间序列分解为单变量序列并处理。首先切分不同尺度的 Patch(P),得到 Patch 序列;随后用单层线性层对这些 Patch 进行嵌入;最后展开向量,获得最终输入模型的嵌入向量。
-
特征分解(Feature Decomposition):将多尺度Patch嵌入层得到的潜在向量进一步分解为平滑分量和含噪残差两部分。
-
多层感知器(MLP)层:承接特征分解层的输出,MLP层分别对平滑分量与含噪残差独立处理。进一步挖掘和提取平滑分量及含噪残差中的特征信息。
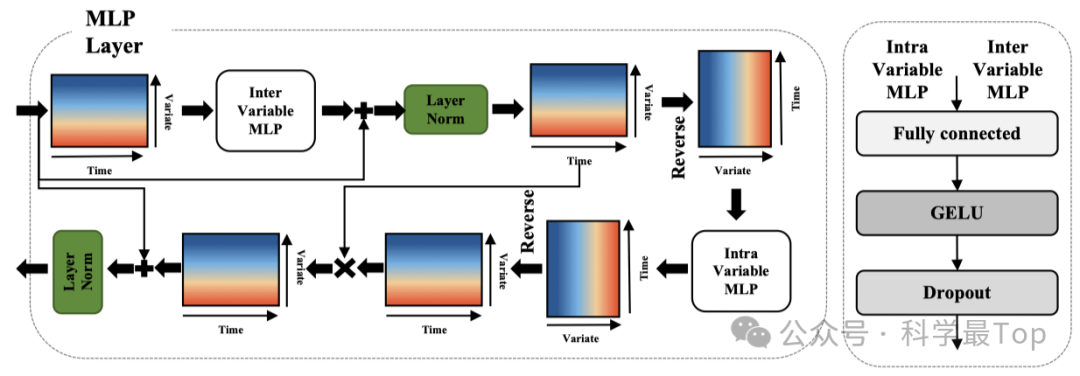
上图是多层感知器的(MLP)层的整体结构。嵌入向量首先通过变量内多层感知器(Intra-Variable MLP)与变量内部的时间信息进行交互。然后通过变量内多层感知器(Intra-Variable MLP)与变量之间的特征域信息进行交互。随后,使用点积的方法将它们与变量间多层感知器(Inter-Variable MLP)的输入相乘。最后,通过残差连接将它们与多层感知器(MLP)层的初始输入相加。
本文实验
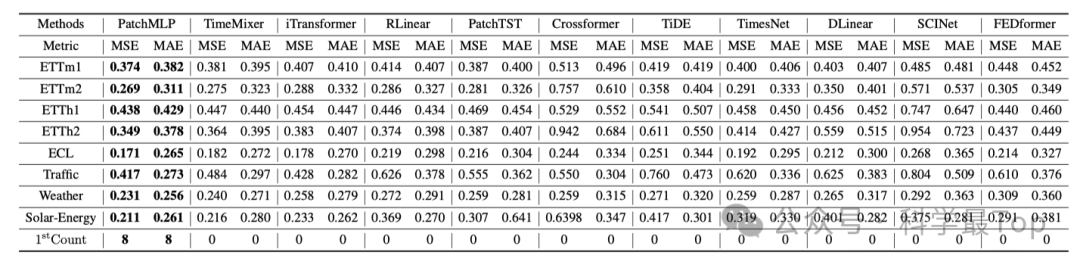
在所有数据集上,PatchMLP模型实现了100%的最优性能,超过了所有Transformer架构。这表明注意力机制可能不是LTSF任务的最佳选择。一些局限性是对输入序列长度的敏感性。
问题:在PatchMLP模型中,如何通过特征分解层分离出平滑分量和噪声残差?
平均池化:使用平均池化操作对嵌入向量进行平滑处理,公式如下:
X' = avgPool(X)
其中,X表示嵌入向量,
X'表示提取的平滑分量。残差计算:通过原始嵌入向量减去平滑分量,得到噪声残差:
Xr = X - Xs
大家可以关注我【科学最top】,第一时间follow时序高水平论文解读!!!,后台回复“交流”加入讨论群,回复“资源”获取2024年度论文讲解合集
