训练数据集太小?你需要 SetFit
数据稀缺是许多数据科学家面临的一大问题。
这听起来可能很荒谬(“这难道不是大数据时代吗?”),但在许多领域,根本没有足够的标记训练数据来使用传统的机器学习方法训练高性能模型。
在分类任务中,解决这个问题的懒惰方法是“用人工智能来解决”:采用现成的预先训练好的法学硕士 (LLM),添加一个聪明的提示,然后一切就搞定了。
但法学硕士 (LLM) 并不总是完成工作的最佳工具。规模化的情况下,LLM 流程可能缓慢、昂贵且不可靠。
另一种选择是使用专为少量场景(训练数据很少)设计的微调/训练技术。
在本文中,我将向您介绍我最喜欢的一种技术:SetFit,这是一个微调框架,可以帮助您构建高性能的 NLP 分类器,每个类别只需 8 个标记样本。
我第一次了解 SetFit 是在我为金融行业客户提供的一个项目中
我们试图构建一个模型,用于对领域特定文本进行分类,这些文本之间只有细微的差异。遗憾的是,我们每个类别只有大约 10 个样本(而类别数量大约在 200 多个),而且我们现有的传统 NLP 工具(TF-IDF、BERT、DistilBERT、RoBERTa、OpenAI/Llama 3)也收效甚微。
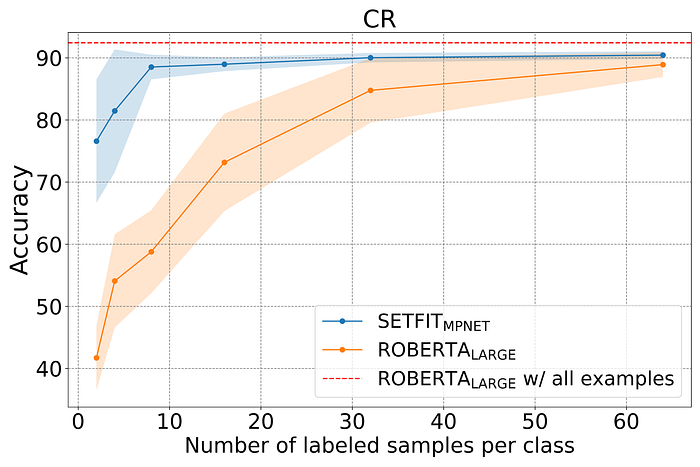
在寻找解决方案时,我偶然发现了 SetFit,并在看到这张非凡的图表后决定尝试一下,该图表显示了 SetFit 的原始创建者进行的实验的结果:
来源
在实验中,研究人员训练了一个 RoBERTa Large 模型来对客户评论的情绪进行分类。他们最初为每个类别/情绪仅设置 3 个样本的训练数据集,然后逐渐将训练数据集的大小增加到 3000 个样本,并记录每个样本的准确率。从图表(橙色线)中可以看出,RoBERTa 模型在大样本量下性能优异,但在小样本量下性能不佳。
接下来,研究人员使用 SetFit 框架(蓝线)训练了一系列模型。他们发现:
SetFit 训练的模型在小样本量的情况下轻松胜过 RoBERTa Large
这让我大吃一惊,但要了解为什么会发生这种情况,我们需要了解 SetFit 实际上是什么。
SetFit是一个用于对句子 Transformer(文本嵌入模型)进行少样本微调的框架。它由 HuggingFace 🤗 的研究人员开发,可以通过transformers和setfitPython 库完全免费使用。
什么是句子转换器?它只是一种用于编码/嵌入文本的特定类型的神经网络。它们是现代 NLP 工具包的重要组成部分,因为它们可以将文本转换为高维、密集的向量,从而捕捉文本的语义。反过来,这些向量表示可以用作训练预测模型(例如文本分类器)的特征。
所以 SetFit 是一个用于微调句子转换器的框架。但这意味着什么呢?
用简单的英语来说,这意味着它可以用来使用非常小的训练数据集创建定制的、微调的嵌入模型。
这分为两个阶段:
- 微调句子转换器(使用对比学习)
- 训练分类头(例如逻辑回归)

图片来自作者
什么是对比学习?为什么它在小型特定领域的数据集上效果如此好?
大多数嵌入模型/句子转换器都是通过查看共现模式来训练嵌入文本的——它们通过查看单词彼此靠近出现的频率来学习嵌入。
例如,在像维基百科这样的大型训练语料库中,“茶”和“咖啡”这两个词可能经常出现在同类文章、同类句子、同类词语附近:
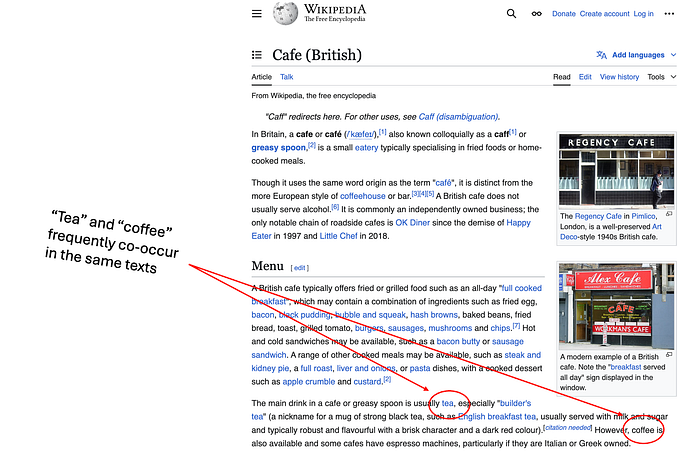
图片来自作者。维基百科截图。没错,我们英国人确实把咖啡馆称为“油腻的餐馆”。
因此,嵌入模型学习使用相似的嵌入来编码这些同时出现的词:
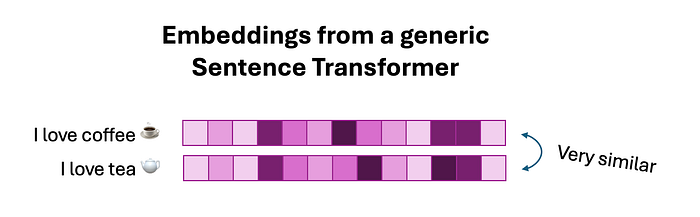
图片来自作者
这些嵌入对于通用语言模型非常有用(它使它们能够识别茶和咖啡适合相同的广泛语义空间 - 即它们都是热饮),但在我们需要构建细粒度分类器的背景下,它们并不是特别有用,可以识别这些类别之间的差异。
在对比学习中,嵌入器经过明确训练,可以生成特定于任务的嵌入,这些嵌入非常擅长区分不同的类别或种类(在本例中为茶与咖啡)。
这分为三个阶段:
- 创建句子对:SetFit 算法首先创建句子对。这些句子对要么被标记为正例(如果句子具有相同的标签),要么被标记为负例(如果句子具有不同的标签):

图片来自作者
2. 句子嵌入:每个句子经过预先训练的句子转换器,获得嵌入(向量表示)。这些嵌入捕捉了句子的语义。
3. 使用对比损失调整嵌入:使用余弦相似度损失或三重边际损失等损失函数(取决于您设置的配置),模型会调整嵌入,以便:
- 正对中的句子的嵌入在嵌入空间中被拉近。
- 否定对中的句子嵌入被推得更远。
例如:
- “我喜欢喝茶”和“这里的茶很难喝”的嵌入被调整得更接近,因为它们都是关于茶的(即,它们是一对“正”对)。
- “我喜欢咖啡”和“茶很棒”的嵌入被调整得更远,因为它们不是关于同一主题的。
最终结果是,模型主动学习在向量空间中分离来自不同类别的句子,确保来自同一类别的句子更相似,而来自不同类别的句子不太相似:
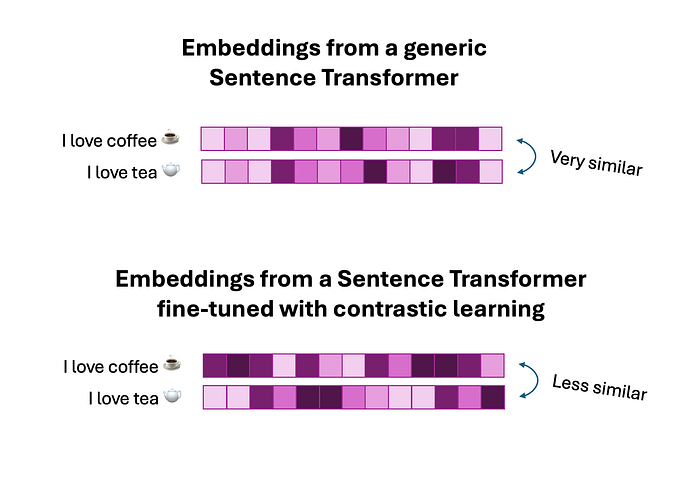
图片来自作者
这最大化了向量中包含的“信息”(从数学意义上来说),并可以帮助您使用很少的训练数据构建真正强大的分类器。
示例:对技术新闻文章进行分类
让我们看一个真实的例子,看看 SetFit 与其他方法的比较结果。我们将使用20 个新闻组数据集(CC BY 4.0 许可证)的一个子集,该数据集包含数千条新闻文章标题以及每篇文章对应的类别。
我们将从 5 个密切相关(但又不同)的计算类别中分别选取 20 篇文章作为样本:图形、Microsoft Windows、IBM、Mac 和 Windows X。
我们的目标是构建一个分类器,能够针对给定的技术文章识别出合适的类别。这些类别之间的语义相似性使得这项工作成为一个棘手的挑战:我们的分类器将如何表现?
首先,让pip install我们找到所需的包并导入所需的库:
!pip install setfit transformers==4.42.2 peft==0.10.0 scikit-learn nltk pandas
from datasets import Dataset
from setfit import SetFitModel, Trainer
from typing import Tuple
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
import re接下来,我们准备数据。
# Fetch data for all the "Science" categories
cats = ['comp.graphics', 'comp.os.ms-windows.misc', 'comp.sys.ibm.pc.hardware', 'comp.sys.mac.hardware','comp.windows.x']
train = fetch_20newsgroups(subset='train', categories=cats, remove=('headers', 'footers', 'quotes'))
test = fetch_20newsgroups(subset='test', categories=cats, remove=('headers', 'footers', 'quotes'))# Convert to DataFrame
train_df = pd.DataFrame({'text': train.data, 'label': train.target})
train_df['label'] = train_df['label'].apply(lambda x: train.target_names[x])
test_df = pd.DataFrame({'text': test.data, 'label': test.target})
test_df['label'] = test_df['label'].apply(lambda x: test.target_names[x])# Remove stopwords, lowercase, etc.
def preprocess_text(text):text = text.lower() # Lowercasetext = re.sub(r'[^a-zA-Z\s]', '', text) # Remove special characters and numberstokens = text.split()return ' '.join(tokens)train_df['text'] = train_df['text'].apply(lambda x: preprocess_text(x))
test_df['text'] = test_df['text'].apply(lambda x: preprocess_text(x))# Stratified sample in the training dataset: 20 samples per class
train_df = train_df.groupby('label', group_keys=False).apply(lambda x: x.sample(20, random_state=42))train_df # Preview
图片来自作者
在这些文本可用于训练分类器之前,我们需要嵌入它们(即,我们需要将它们编码为向量)。
使用 SetFit,我们可以对现成的句子转换器进行微调,使其适应文本的具体细微差别,然后适应逻辑回归分类头:
import os
os.environ["WANDB_DISABLED"] = "true" # If running in Google Colab# SetFit needs a Dataset class with two cols: `text` and `label`
train_dataset = Dataset.from_pandas(train_df)
val_dataset = Dataset.from_pandas(test_df)# A popular and performant sentence transformer from HuggingFace
model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2",)model.labels = train_dataset['label']trainer = Trainer(model=model,train_dataset=train_dataset,
)trainer.train()accuracy = trainer.evaluate(val_dataset)
y_pred = model.predict(val_dataset['text']) # Generate an array of predictions which we can insert into a `results` DataFrame laterresults = pd.DataFrame({'text': test_df.text,'label': test_df.label,'y_pred': y_pred
})print(f"Accuracy: {accuracy}")
# 0.63因此,SetFit 训练的模型在每类 20 个样本的情况下实现了 63% 的准确率。如果每类 40 个样本,准确率将上升至 68%。
这与其他方法相比如何?我们来看看 TF-IDF:
# TF-IDF vectorizer
tfidf = TfidfVectorizer(max_features=5000)
X_train_tfidf = tfidf.fit_transform(train_df['text'])
X_val_tfidf = tfidf.transform(test_df['text'])# Logistic Regression classifier
lr = LogisticRegression(max_iter=1000)
print("Training TF-IDF + Logistic Regression model...")
lr.fit(X_train_tfidf, train_df['label'])# Evaluate
tfidf_y_pred = lr.predict(X_val_tfidf)
tfidf_accuracy = accuracy_score(test_df['label'], tfidf_y_pred)results = pd.DataFrame({'accuracy': tfidf_accuracy,'predictions': tfidf_y_pred,
})print(f"TF-IDF Model Accuracy: {tfidf_accuracy:.4f}")
# 0.48准确率为 38%——低得多。
RoBERTa 模型表现更佳,但前提是使用更多数据。请看下图:
from transformers import RobertaTokenizer, RobertaForSequenceClassification, Trainer as HFTrainer, TrainingArguments
from torch.utils.data import Dataset as TorchDataset# Prepare the data for RoBERTa
class TextClassificationDataset(TorchDataset):def __init__(self, texts, labels, tokenizer, max_length=128):self.texts = textsself.labels = labelsself.tokenizer = tokenizerself.max_length = max_lengthdef __len__(self):return len(self.texts)def __getitem__(self, idx):text = self.texts[idx]label = self.labels[idx]encoding = self.tokenizer(text,max_length=self.max_length,padding="max_length",truncation=True,return_tensors="pt",)return {key: val.squeeze(0) for key, val in encoding.items()}, label# Tokenizer and model initialization
tokenizer = RobertaTokenizer.from_pretrained("roberta-base")
roberta_model = RobertaForSequenceClassification.from_pretrained("roberta-base", num_labels=len(set(train_df['label'])))train_dataset_roberta = TextClassificationDataset(train_df['text'].tolist(),train_df['label'].tolist(),tokenizer,
)val_dataset_roberta = TextClassificationDataset(test_df['text'].tolist(),test_df['label'].tolist(),tokenizer,
)# Training arguments for RoBERTa
training_args = TrainingArguments(output_dir="./roberta-results",evaluation_strategy="epoch",per_device_train_batch_size=8,per_device_eval_batch_size=8,num_train_epochs=3,save_steps=1000,logging_dir="./logs",logging_steps=10,
)hf_trainer = HFTrainer(model=roberta_model,args=training_args,train_dataset=train_dataset_roberta,eval_dataset=val_dataset_roberta,
)print("Training RoBERTa model...")
hf_trainer.train()# Evaluate RoBERTa Model
roberta_y_pred = hf_trainer.predict(val_dataset_roberta).predictions.argmax(axis=-1)
roberta_accuracy = accuracy_score(test_df['label'], roberta_y_pred)results_summary['RoBERTa'] = {'accuracy': roberta_accuracy,'predictions': roberta_y_pred,
}print(f"RoBERTa Model Accuracy: {roberta_accuracy:.4f}")当使用总共 3,000 个样本时,准确率为 74%。但当每个类别仅使用 20 个样本(即与 SetFit 和 TF-IDF 相同)运行该代码时,准确率仅为 4.7 %。这与SetFit原作者的发现相符:
与标准微调相比,SetFit 的采样效率更高,抗噪声能力更强。