torchsummary库中的summary()函数
torchsummary库中的summary()函数是PyTorch中用于可视化模型结构的核心工具,其作用类似于TensorFlow的model.summary()。它通过生成详细的表格输出,帮助开发者直观理解模型层次、参数分布和计算资源需求。以下是其核心功能详解:
📊 1. 核心功能
-
模型结构可视化
例如:
输出包含每一层的类型(如Conv2d、Linear)、名称、输出张量形状(Output Shape)和参数量(Param #)。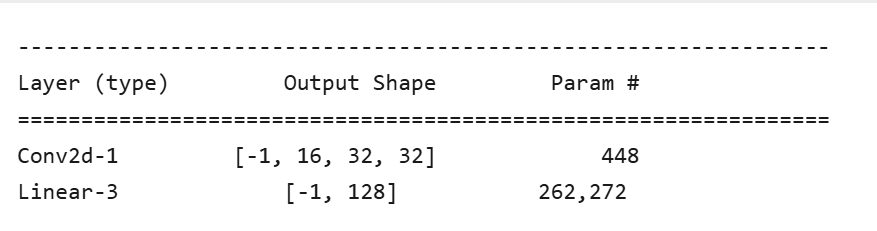
其中
Output Shape的-1表示动态的批量大小(batch size),后续维度为特征图或向量的形状。 -
参数量统计
汇总总参数量(Total params)、可训练参数(Trainable params)及不可训练参数(如冻结层)。 -
内存占用分析
计算模型的内存开销,包括:- 输入数据占用(
Input size (MB)) - 前向/反向传播中间变量占用(
Forward/backward pass size (MB)) - 参数存储占用(
Params size (MB)) - 预估总内存(
Estimated Total Size (MB))。
- 输入数据占用(
⚙️ 2. 使用方法
安装
pip install torchsummary -i https://mirrors.aliyun.com/pypi/simple/
代码示例
from torchsummary import summary
import torch.nn as nn# 定义模型
class SimpleModel(nn.Module):def __init__(self):super().__init__()self.conv = nn.Conv2d(3, 16, kernel_size=3)self.fc = nn.Linear(16 * 30 * 30, 10) # 假设输入32x32,卷积后尺寸为30x30def forward(self, x):x = self.conv(x)x = x.view(x.size(0), -1)x = self.fc(x)return x# 实例化并调用summary
model = SimpleModel()
summary(model, input_size=(3, 32, 32), device="cpu") # 指定输入尺寸和设备参数说明
model:继承nn.Module的PyTorch模型。input_size:输入张量形状(C, H, W),不含batch size(自动添加-1占位)。device:可选"cuda"或"cpu",必须与模型所在设备一致,否则报错(如RuntimeError: Input type and weight type should be the same)。batch_size:可选,控制输出形状中的批量占位符(默认为-1)。
🚨 3. 常见问题与注意事项
-
设备匹配
若模型在CPU上,需显式设置device="cpu",否则默认使用GPU(device="cuda")会引发类型错误。 -
输入尺寸要求
input_size需与模型实际输入一致。例如:- RGB图像:
(3, H, W) - 灰度图:
(1, H, W) - 全连接网络:
(input_dim,)(如(784,)对应MNIST展平后向量)。
- RGB图像:
-
动态结构支持
若模型前向传播包含条件分支或动态操作(如x.view()),需确保输入尺寸与view/flatten操作兼容,否则输出形状可能计算错误。 -
输出解读
Output Shape中的[-1, C, H, W]:卷积/池化层输出。[-1, D]:全连接层输出(D为特征维度)。
💡 4. 典型应用场景
- 模型调试:快速验证各层输出尺寸是否匹配,避免维度不匹配错误。
- 复杂度评估:通过参数量和内存占用优化模型结构(如减少冗余层)。
- 论文/报告展示:生成简洁的架构摘要表格。
🌰 输出示例解析

- 参数量计算:
卷积层:(3×3×3+1)*16 = 448(权重+偏置)
全连接层:(16×30×30+1)*10 = 144,010。 - 内存估算:帮助预判模型在边缘设备的部署可行性。
通过summary(),开发者无需逐层打印调试即可全局掌握模型结构,显著提升开发效率。尤其适合需要快速迭代模型或资源受限的场景。