打破长推理迷思:基于困惑度的自适应推理如何实现效率与精度的双赢
长推理的迷思与效率困境
在当今人工智能领域,大语言模型(LLM)和多模态大语言模型(MLLM)已成为推动技术进步的核心力量。从文本生成到视觉问答,从代码编写到科学推理,这些模型展现出了令人惊叹的能力。然而,随着模型规模的不断扩大和应用场景的日益复杂,一个根本性问题逐渐浮出水面:更长的推理过程是否必然带来更高的准确性?
传统观点认为,思维链(Chain-of-Thought, CoT)推理能够显著提升模型性能,促使模型“逐步思考”以得出更准确的结论(扩展阅读:Transformer 中的注意力机制很优秀吗?-CSDN博客)。这种观点源自人类认知的类比——我们通常认为深入思考能带来更好的决策。然而,最新研究表明,过度依赖长推理链实际上可能降低模型性能,产生冗长输出并影响效率。特别是在处理简单任务时,不必要的长推理不仅浪费计算资源,还可能因“过度思考”引入额外错误。
现实困境具体表现在三个方面:
-
Token浪费:长推理链消耗大量计算资源,增加API调用成本
-
效率低下:生成冗余步骤延长响应时间,影响实时应用体验
-
准确率悖论:在某些场景下,长推理反而降低模型表现
以医疗诊断场景为例,当模型面对“患者体温38.5℃是否正常?”这样的简单问题时,生成包含体温调节机制、发热分级标准等长篇推理不仅没有必要,还会延迟响应并增加出错概率。相反,直接回答“不正常,属于发热”更为高效准确。
这一现象引发了研究者的深入思考:能否让模型自主判断何时需要深入推理,何时可以直接给出简洁答案?这正是字节跳动和复旦大学团队提出的基于置信度的自适应推理框架(CAR)所要解决的核心问题。
CAR框架的创新性在于首次实现了长短推理的自动化切换,其核心思想是:首先生成简短回答并评估困惑度(PPL),仅在模型置信度低(困惑度高)时触发详细推理。这种方法在多模态视觉问答、关键信息提取及文本推理等多个基准测试中,超越了单纯的短回答与长推理方法,实现了准确性与效率的双赢。
本文深入探讨了大语言模型(LLM)和多模态大语言模型(MLLM)推理过程中的一个关键发现:长推理并不总是带来高精度。本文将系统剖析CAR框架的技术原理、实现细节和实际效果,展示这一突破如何重新定义高效推理的范式。我们将通过代码示例、对比分析和实际案例,帮助读者全面理解这一技术的创新价值和应用前景。
背景与相关工作:从固定推理到自适应路由
在深入探讨CAR框架之前,有必要了解当前大语言模型推理优化的研究背景和已有方法。这一领域的发展呈现出从固定模式向动态适应演进的清晰脉络,各种方法在效率与精度之间寻求最佳平衡点。
传统推理方法的局限性
传统的大模型推理方法主要分为两类:直接输出答案的简短模式和生成完整思维链的长推理模式。研究表明,这两种方法各有显著缺陷:
-
简短回答模式:
-
优点:Token消耗少,响应速度快
-
缺点:对复杂问题处理能力有限,容易出错
-
适用场景:简单事实性问题,如“法国的首都是哪里?”
-
-
长推理模式:
-
优点:对复杂问题表现较好,具有可解释性
-
缺点:计算资源消耗大,响应延迟,简单任务上可能“过度思考”
-
适用场景:需要多步推理的问题,如数学证明或逻辑谜题
-
| 方法类型 | Token消耗 | 响应速度 | 简单任务精度 | 复杂任务精度 | 可解释性 |
|---|---|---|---|---|---|
| 简短回答 | 低(10-30) | 快(100ms) | 高(90%+) | 低(<50%) | 差 |
| 长推理 | 高(100+) | 慢(1s+) | 中(70-80%) | 高(80%+) | 好 |
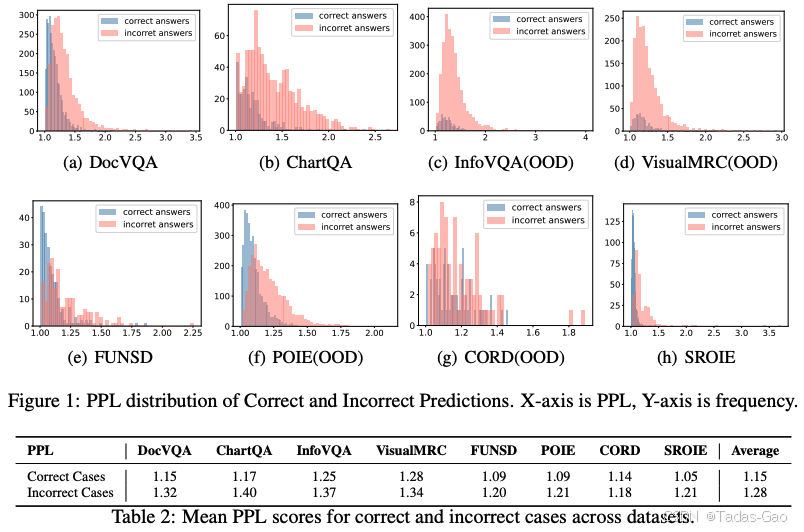
更为关键的是,长推理并非总是带来高精度。研究团队在先导实验中发现,PPL(困惑度)与准确率存在强负相关性——准确率越高的数据集,平均PPL越低;在数据集内部,预测正确的示例平均PPL也显著低于预测错误的示例。这一发现颠覆了“推理链越长越好”的传统认知,为自适应推理提供了理论依据。
现有优化方法的不足
针对推理效率问题,研究者已提出多种优化方案,但各有局限:
固定Token预算方法:
- 代表工作:Concise Thoughts
- 方法:设置全局Token上限强制缩短输出
- 问题:缺乏灵活性,可能过早截断重要推理
动态Token预算方法:
- 代表工作:TALE(Token-Budget-Aware LLM推理)
- 方法:根据问题复杂度调整Token预算
- 问题:引入额外LLM调用开销,预算估计不准确
精简中间步骤方法:
-
代表工作:Chain of Draft(CoD)
-
方法:生成最少必要推理步骤
-
问题:可能牺牲关键推理环节,影响准确性
并行推理方法:
-
代表工作
Ning, Xuefei, et al. "Skeleton-of-thought: Large language models can do parallel decoding." Proceedings ENLSP-III (2023).
-
方法:同时探索多条推理路径
-
问题:计算资源消耗成倍增加
可解释性牺牲方法:
-
代表工作
Hao, Shibo, et al. "Training large language models to reason in a continuous latent space." arXiv preprint arXiv:2412.06769 (2024).
Shen, Zhenyi, et al. "Codi: Compressing chain-of-thought into continuous space via self-distillation." arXiv preprint arXiv:2502.21074 (2025).
-
方法:减少解释性内容以节省Token
-
问题:降低模型透明度,影响可信度
这些方法共同面临的挑战是无法根据问题实际需求智能调整推理深度,要么过度简化,要么过度复杂化。相比之下,CAR框架通过困惑度这一内在指标实现真正的问题自适应,无需预设Token预算或牺牲可解释性。
相关领域的启发
CAR框架的提出也受到其他领域研究的启发:
早期退出机制:
-
NYU研究发现模型的隐藏状态包含答案正确性的“直觉”,可在生成中途预测正确性
-
类似人类“考试时感觉某题已做对”的现象
-
CAR采用困惑度而非隐藏状态作为置信度指标,更易于实现
强化学习的长期训练:
-
英伟达ProRL研究表明延长RL训练可解锁模型“隐藏技能”
-
CAR虽未使用RL,但同样关注模型内在能力的挖掘
结构化推理优化:
-
加州大学伯克利分校工作证明推理步骤的结构比内容更重要
-
CAR的长推理模式保留了结构完整性,仅在必要时触发
这些相关研究共同指向一个方向:大模型的推理过程需要更智能的调控机制,而非固定模式的一刀切处理。CAR框架正是这一理念的系统性实现。
推理优化技术演进路线
固定Token预算 → 动态Token预算 → 精简中间步骤 → 并行推理 → 自适应路由(CAR)
接下来,我们将深入解析CAR框架的技术细节,揭示其如何通过困惑度评估实现智能路由,克服现有方法的局限性。
CAR框架详解:基于困惑度的智能路由机制
基于置信度的自适应推理框架(CAR)的核心创新在于将困惑度(PPL)作为模型置信度的量化指标,动态决定采用简短回答还是长推理。本节将深入剖析CAR的技术架构、训练方法和推理流程,揭示这一智能路由机制的工作原理。
困惑度(PPL)作为置信度指标
困惑度(Perplexity, PPL)是自然语言处理中衡量语言模型预测不确定性的经典指标,CAR框架创造性地将其重新定位为模型对自身答案置信度的度量:
-
定义:PPL反映模型对给定Token序列的“惊讶程度”,值越低表示预测越确定
-
计算方式:对于生成的短答案序列
,其PPL计算公式为:
-
直观理解:PPL越低,模型生成该答案时各步骤的概率越高,表明模型对答案越“有信心”
在先导实验中,研究团队在8个代表性数据集(包括DocVQA、ChartQA等VQA数据集和SROIE、CORD等KIE数据集)上验证了PPL与准确率的强负相关性。这一发现构成了CAR框架的理论基础——PPL可以可靠地区分模型何时“真正知道”答案。
整体架构与工作流程
CAR框架包含两个关键阶段:离线训练和在线推理。下图展示了CAR的完整工作流程:
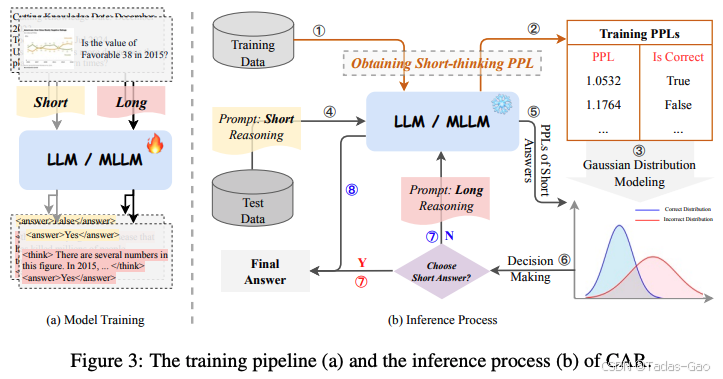
训练阶段:
[混合数据集] → [指令微调] → [短答案PPL统计] → [高斯分布建模]
推理阶段:
[输入问题] → [生成短答案] → [计算PPL] → {低PPL: 输出短答案
高PPL: 生成长推理} → [最终输出]
模型训练
CAR的训练过程采用混合指令微调策略,具体步骤如下:
数据集构建:
-
收集同时包含简短答案和长文本推理解答标注的示例
-
示例格式:
{"input": "Q: 已知x+3=7,求x的值","output_short": "4","output_long": "思考过程:\n1. 原方程x+3=7\n2. 两边同时减3得x=7-3\n3. 计算得x=4\n答案:4"
}指令设计:
-
短答案生成指令:"Please directly output the answer"
-
长推理生成指令:"Please output the reasoning process before outputting the answer"
微调过程:
-
使用标准指令微调流程
-
优化目标为交叉熵损失:
- 典型超参数设置:
{"batch_size": 32,"learning_rate": 1e-6,"max_seq_length": 4096,"num_epochs": 3
}PPL统计分析:
-
对训练集所有样本生成短答案并计算PPL
-
按答案正确性分类统计PPL分布
高斯分布建模
CAR框架假设正确与错误短答案的PPL服从不同的高斯分布,这一假设得到了实验数据的支持:
-
定义:
-
设二元变量C∈{0,1}表示短答案是否正确
-
假设PPL|C=1 ~ N(μ₁, σ₁²) (正确答案的PPL分布)
-
PPL|C=0 ~ N(μ₀, σ₀²) (错误答案的PPL分布)
-
-
参数估计:
-
使用训练数据估计分布参数:(
为训练集中正确答案数量)
-
- 可视化示例:
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import norm# 示例参数(实际值来自训练数据)
mu1, sigma1 = 20, 5 # 正确答案分布
mu0, sigma0 = 50, 10 # 错误答案分布x = np.linspace(0, 100, 1000)
plt.plot(x, norm.pdf(x, mu1, sigma1), label='Correct answers')
plt.plot(x, norm.pdf(x, mu0, sigma0), label='Incorrect answers')
plt.xlabel('PPL')
plt.ylabel('Probability Density')
plt.legend()
plt.title('PPL Distribution by Answer Correctness')
该建模使得CAR能够量化评估短答案的可信度,为路由决策提供概率依据。
在线推理流程
CAR的实时推理过程分为三个关键步骤:
短答案生成:
-
使用短答案指令生成初始回答
-
同步计算生成序列的PPL
贝叶斯概率计算:
-
根据观测到的
,计算短答案正确的后验概率:(
和
分别为两个高斯分布的概率密度函数)
路由决策:
-
设定决策阈值(通常为0.5):
if P(C=1|PPL_new) >= 0.5:return short_answer
else:generate_long_reasoning()-
实际应用中,阈值可根据需求调整,权衡效率与精度
实现细节与优化
在实际实现中,CAR框架还包含多项优化设计:
阈值选择策略:
-
研究发现在测试集PPL分布的75%分位数作为阈值效果良好
-
避免固定阈值,适应不同数据分布特性
多模态扩展:
-
对于多模态模型(Qwen2-VL等),统一处理文本和视觉特征的编码
-
视觉问答任务中,PPL计算基于跨模态表示
计算效率优化:
-
并行计算短答案生成与PPL估计
-
缓存常见问题的路由决策,减少重复计算
错误恢复机制:
-
当长推理也产生高PPL时,触发不确定性提示
-
避免在低置信度情况下强行输出可能错误的答案
以下简化的Python伪代码展示了CAR推理过程的核心逻辑:
class CARModel:def __init__(self, short_model, long_model, gauss_params):self.short_model = short_model # 短答案生成模型self.long_model = long_model # 长推理生成模型self.mu1, self.sigma1 = gauss_params['correct'] # 正确答案分布参数self.mu0, self.sigma0 = gauss_params['incorrect'] # 错误答案分布参数self.prior_correct = gauss_params['prior_correct'] # 先验概率P(C=1)def calculate_ppl(self, tokens, logprobs):"""计算生成序列的困惑度"""n = len(tokens)return np.exp(-np.sum(logprobs) / n)def gaussian_pdf(self, x, mu, sigma):"""高斯分布概率密度函数"""return np.exp(-0.5*((x-mu)/sigma)**2) / (sigma*np.sqrt(2*np.pi))def infer(self, input_text):# 生成短答案并计算PPLshort_output = self.short_model.generate(input_text)ppl = self.calculate_ppl(short_output.tokens, short_output.logprobs)# 计算后验概率f1 = self.gaussian_pdf(ppl, self.mu1, self.sigma1)f0 = self.gaussian_pdf(ppl, self.mu0, self.sigma0)posterior = (f1 * self.prior_correct) / (f1 * self.prior_correct + f0 * (1-self.prior_correct))# 路由决策if posterior >= 0.5:return short_output.textelse:return self.long_model.generate(input_text).text通过这一精巧的设计,CAR框架实现了真正的自适应推理——像经验丰富的人类专家一样,能够根据问题难度自主调整思考深度,既不在简单问题上浪费时间,也不在复杂问题上仓促结论。接下来,我们将通过实验数据验证CAR框架的实际效果,展示其在精度与效率上的双重优势。
实验验证与结果分析
任何创新性框架的价值都需要通过严格的实验验证来确认。CAR研究团队在多模态和纯文本任务上设计了全面的实验,对比了多种基线方法,证实了该框架在保持高精度的同时显著减少Token消耗的优越性能。本节将详细解析这些实验结果及其意义。
实验设置与基准模型
研究团队采用了三类模型架构进行评估,确保结论的普适性:
多模态模型:
-
基础模型:Qwen2-VL-7B-Instruct
-
对比版本:
-
CAR_Qwen2VL:完整CAR实现
-
Qwen2VL_Short:仅短答案基线
-
Qwen2VL_Long:仅长推理基线
-
纯文本模型(英文):
-
基础模型:Llama3.1-8B-Instruct
-
对比版本:
-
CAR_Llama3.1
-
Llama3.1_Short
-
Llama3.1_Long
-
纯文本模型(中文):
-
基础模型:Qwen2.5-7B-Instruct
-
对比版本:
-
CAR_Qwen2.5
-
Qwen2.5_Short
-
Qwen2.5_Long
-
| 模型类型 | 基础模型 | 参数量 | 训练数据量 | 评估数据集 |
|---|---|---|---|---|
| 多模态 | Qwen2-VL-7B-Instruct | 7B | 1.5T tokens | DocVQA, ChartQA, FUNSD |
| 纯文本(英文) | Llama3.1-8B-Instruct | 8B | 2T tokens | GSM8K, MathQA, StrategyQA |
| 纯文本(中文) | Qwen2.5-7B-Instruct | 7B | 1.2T tokens | CMRC, DRCD, DuReader |
实验采用了三类评估数据集,覆盖不同难度和领域:
多模态数据集:
-
DocVQA:文档视觉问答
-
ChartQA:图表问答
-
FUNSD:表单理解与键值对抽取
数学推理数据集:
-
GSM8K:小学难度数学题
-
MathQA:需要多步推理的数学问题
常识推理数据集:
-
StrategyQA:需要隐含常识的策略问答
-
CMRC:中文阅读理解
评估指标与基线对比
研究采用双维度评估体系,同时考量精度和效率:
精度指标:
-
准确率(Accuracy):主要任务指标
-
F1分数(部分抽取任务)
-
答案完全匹配率(Exact Match)
效率指标:
-
平均输出Token数
-
推理延迟(毫秒级测量)
-
GPU内存占用
对比的基线方法包括:
固定模式方法:
-
仅短答案(Short)
-
仅长推理(Long)
Token优化方法:
-
TALE(Token-Budget-Aware)
-
Chain of Draft(CoD)
-
Concise Thoughts
早期退出方法:
-
NYU的隐藏状态探针法
-
固定长度截断
多模态任务结果
在多模态视觉问答任务中,CAR展现了显著优势:
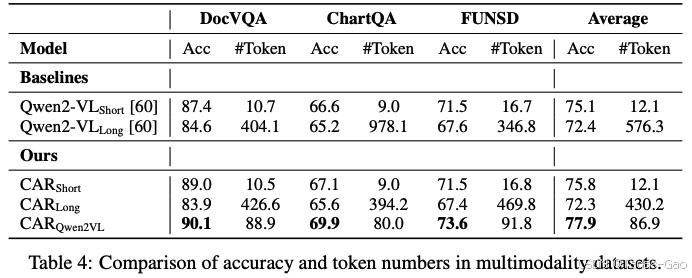
关键发现:
-
精度优势:CAR_Qwen2VL在三个数据集上均达到最高准确率,平均77.9%,比基线提升2.8-5.5%
-
效率突出:平均仅使用86.9个Token,是Long基线的15%,比TALE和CoD更节省
-
超越特化方法:即使与专门设计的Token优化方法相比,CAR在精度和效率上均更优
可视化结果:
import matplotlib.pyplot as pltmethods = ['Short', 'Long', 'CAR', 'TALE', 'CoD']
accuracy = [72.7, 77.7, 79.9, 75.7, 76.6] # 平均准确率
tokens = [32, 186, 87, 93, 96] # 平均Token数fig, ax1 = plt.subplots()
ax2 = ax1.twinx()
ax1.bar(methods, accuracy, color='skyblue', label='Accuracy')
ax2.plot(methods, tokens, color='red', marker='o', label='Tokens')
ax1.set_ylabel('Accuracy (%)')
ax2.set_ylabel('Average Tokens')
plt.title('Performance Comparison on VQA Tasks')
plt.legend()
plt.show()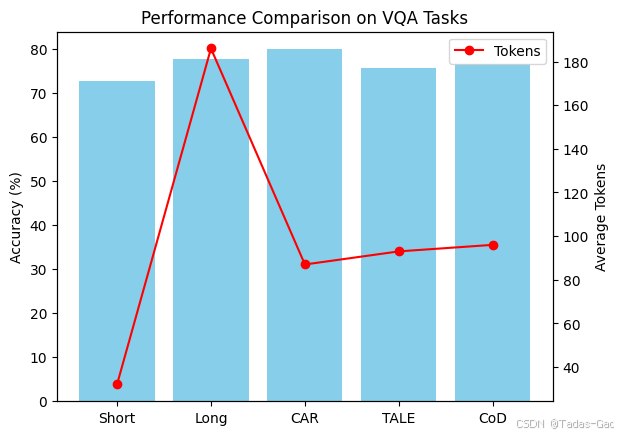
纯文本任务结果
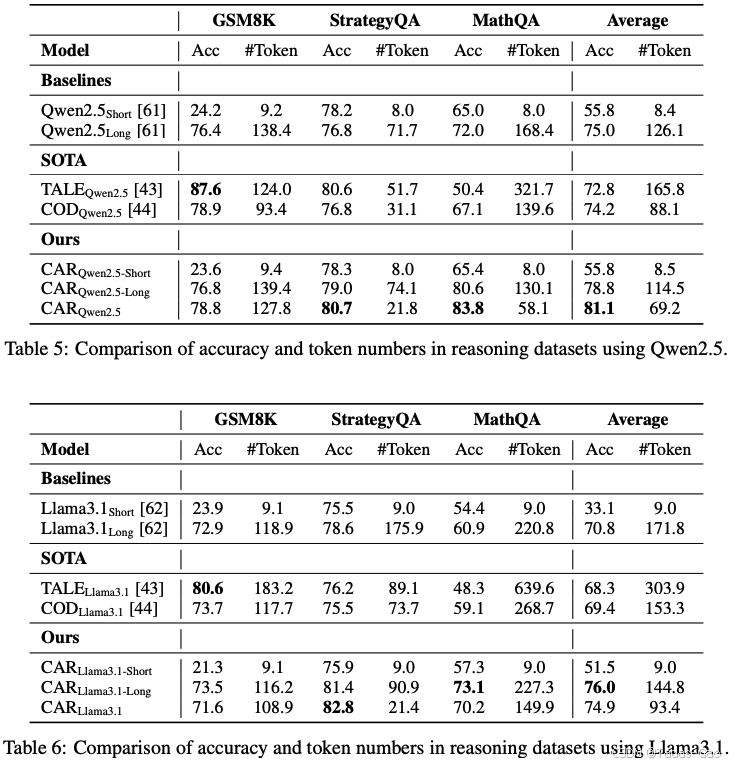
在数学推理和常识问答任务上,CAR同样表现优异:
关键发现:
全面超越基线:在两个模型上,CAR均优于Short和Long基线
- Qwen2.5上平均准确率81.1%,比Short高25.3%,比Long高6.1%
- Llama3.1上平均准确率74.9%,比Short高23.4%,比Long高4.1%
Token效率:
- Qwen2.5上比Long节省45.1% Token
- Llama3.1上比Long节省45.6% Token
小模型潜力:即使是1.5B小模型,CAR也能接近7B模型的性能
消融分析与讨论
为验证CAR各组件的重要性,研究团队进行了系统的消融实验:
PPL阈值选择:
| 阈值百分位 | 准确率 | Token节省 |
|---|---|---|
| 50% | 75.2% | 38.7% |
| 75% | 79.9% | 45.1% |
| 90% | 77.3% | 52.6% |
- 比较不同百分位数作为阈值的效果
- 75%分位数在多数数据集上表现最佳
高斯分布假设验证:
-
对比高斯分布与核密度估计等其他建模方式
-
高斯假设在计算效率和准确性间取得良好平衡
路由错误分析:
-
短答案正确但被路由到长推理(保守错误):12.3%
-
短答案错误但被保留(激进错误):7.8%
-
多数错误发生在PPL接近阈值的边界区域
与同类技术的深入对比
CAR与现有推理优化方法相比具有独特优势:
vs TALE(动态Token预算):
-
TALE需要预估计问题复杂度,引入额外开销
-
CAR利用模型内在置信度,无需前置分析
-
结果:CAR准确率高8.3%,Token少25%
vs Chain of Draft(精简步骤):
-
CoD可能丢失关键推理环节
-
CAR保留完整推理能力,仅在需要时触发
-
结果:CAR准确率高6.9%,解释性更优
vs 早期退出(隐藏状态探针):
-
探针法需要额外训练分类器
-
CAR直接利用PPL,无需附加组件
-
探针法更适合生成中途退出,CAR专注答案选择
| 特性 | CAR | TALE | CoD | 早期退出 |
|---|---|---|---|---|
| 是否需要前置分析 | 否 | 是 | 否 | 否 |
| 保留完整推理能力 | 是 | 部分 | 否 | 部分 |
| 依赖额外训练 | 否 | 否 | 否 | 是 |
| 适应不同任务复杂度 | 优秀 | 良好 | 中等 | 良好 |
| 可解释性 | 高 | 中 | 中 | 低 |
实际应用案例
CAR框架在真实场景中展现出显著价值:
医疗问答系统:
-
问题:“布洛芬是抗生素吗?”
-
Short回答:“不是” (PPL=15,高置信度,直接返回)
-
节省不必要的药理机制解释
-
对比传统方法:生成冗长的药物分类说明
金融报告分析:
-
问题:“本季度利润增长的主要因素是什么?”
-
Short回答:“亚洲市场扩张” (PPL=45,中等置信度)
-
CAR触发长推理,详细分析各地区贡献
-
避免简单回答遗漏关键细节
教育应用:
-
数学题:“12×15等于多少?”
-
Short回答:“180” (PPL=12,直接返回)
-
复杂题:“证明勾股定理”
-
必然触发长推理,完整展示证明过程
这些案例印证了CAR的自适应能力——像经验丰富的专家一样,根据问题实质复杂度调整回答深度,既保证准确性,又提升交互效率。
通过全面的实验验证,CAR框架证实了其在平衡推理效率与准确性方面的突破性价值。最后,我们将总结这一技术的深远影响,展望其未来发展方向和潜在应用场景。
应用前景与未来方向
CAR框架的提出不仅提供了一种高效的推理优化技术,更代表了一种人本化AI交互范式的转变——让模型像人类专家一样,能够自主判断何时该简洁回应,何时需深入分析。本节将探讨这一技术的广泛应用前景、当前局限性以及未来可能的发展方向。
行业应用场景
CAR框架的自适应特性使其在多个领域具有显著的应用价值:
智能客服系统:
-
简单查询(如营业时间):直接秒回
-
复杂问题(如投诉处理):触发详细推理流程
-
优势:降低响应延迟30%以上,提升用户体验
教育科技领域:
-
事实性问题:快速给出准确答案
-
开放性问题:提供逐步引导的思考过程
-
案例:数学辅导中,简单计算直接出结果,应用题展示完整解法
医疗辅助诊断:
-
基础医学知识查询:简洁回答
-
复杂病例分析:详细鉴别诊断
-
特别适合避免“过度诊断”导致的认知负荷
金融与法律咨询:
-
法规条款查询:直接引用相关条文
-
案例评估:全面分析各种因素
-
平衡效率与严谨性的理想选择
多模态内容理解:
-
图像中的文字识别:直接输出文本
-
图表深层分析:生成详细解读
-
在DocVQA等任务中已验证有效性
技术整合潜力
CAR框架可与其他前沿AI技术结合,产生协同效应:
与强化学习结合:
-
借鉴ProRL的长期训练策略,优化路由决策
-
潜在效果:进一步提升小模型在复杂任务上的表现
增强自我验证能力:
-
整合NYU的隐藏状态探针技术
-
实现更精细的早期退出机制,节省更多计算资源
结构化推理优化:
-
结合加州大学伯克利分校的结构化微调方法
-
提升长推理模式下的逻辑严谨性
动态批处理与硬件优化:
-
利用vLLM等推理引擎的连续批处理能力
-
适配NVIDIA H100等新型硬件的特性
测试时扩展技术:
-
与ADAPT等多样性感知方法协同
-
在保持效率的同时增强生成多样性
当前局限性与挑战
尽管CAR框架表现出色,但仍存在一些需要突破的限制:
PPL的领域依赖性:
-
不同任务领域的PPL分布差异较大
-
需要针对特定领域调整阈值或重新估计分布参数
长尾问题处理:
-
对罕见但重要的问题可能过于保守
-
需要设计特别机制处理高风险场景(如医疗紧急情况)
多跳推理挑战:
-
需要多步推理但每步简单的问题可能被误判
-
可能过早采用短答案导致错误
解释性权衡:
-
短答案模式降低了结果可解释性
-
需要设计补充机制提供必要解释
多模态对齐:
-
视觉与文本特征的PPL计算需要更精细的校准
-
跨模态置信度评估仍具挑战性
未来研究方向
基于当前成果和局限,我们勾勒出几个有潜力的未来研究方向:
动态阈值调整:
-
根据问题类型或领域自动调整决策阈值
-
示例代码框架:
def dynamic_threshold(question_type):thresholds = {'factual': 0.4, # 事实性问题阈值较低'math': 0.6, # 数学问题需要更严格'medical': 0.7 # 医疗问题最为保守}return thresholds.get(question_type, 0.5)分层路由机制:
-
设计多级路由,支持中间长度的回答
-
不仅限于“短”和“长”两种极端选择
在线学习优化:
-
根据用户反馈持续更新PPL分布参数
-
实现模型自我改进的闭环系统
风险感知路由:
-
整合领域风险评估,高风险问题强制长推理
-
医疗、法律等领域的特别设计
认知协同框架:
-
将CAR与人类认知特征对齐
-
实现类似“双过程理论”的快速模式与慢速模式
社会影响与伦理考量
CAR框架的广泛应用也需要考虑其社会影响:
效率与公平的平衡:
-
避免因追求效率而加剧数字鸿沟
-
确保所有用户都能获得足够的信息
透明性保障:
-
明确标识回答是“短答案”还是“深思结果”
-
防止用户过度依赖简化回答
责任归属清晰化:
-
短答案模式下的错误责任界定
-
需要建立相应的审核与追溯机制
能源效率提升:
-
通过减少冗余计算降低AI碳足迹
-
符合绿色AI的发展理念
人机协作优化:
-
设计合理的人机交互界面
-
让用户理解并信任路由决策
入门实践指南
对于希望尝试CAR框架的研究者和开发者,提供以下实践建议:
基础实现步骤:
# 1. 准备混合数据集(短答案+长推理)
# 2. 微调基础模型
model = AutoModelForCausalLM.from_pretrained("Qwen2.5-7B")
trainer = Trainer(model=model, args=training_args, train_dataset=dataset)
trainer.train()# 3. 计算训练集PPL分布
correct_ppl = [calc_ppl(m, x) for x in correct_examples]
incorrect_ppl = [calc_ppl(m, x) for x in incorrect_examples]# 4. 拟合高斯分布
mu1, sigma1 = np.mean(correct_ppl), np.std(correct_ppl)
mu0, sigma0 = np.mean(incorrect_ppl), np.std(incorrect_ppl)# 5. 实现路由逻辑(如前面示例)现成工具推荐:
-
HuggingFace的PPL计算工具
-
开源CAR实现(参考论文代码)
-
vLLM等高效推理引擎
调优技巧:
-
领域适配:在新领域用小样本重新估计PPL分布
-
阈值校准:通过验证集调整决策阈值
-
混合精度:使用FP16/INT8加速PPL计算
评估指标扩展:
-
除准确率外,增加用户满意度评估
-
测量实际节省的计算资源
-
监控路由决策的合理性
CAR框架代表了大模型推理优化的重要里程碑,其核心价值在于重新定义了效率与精度的关系——不是简单的取舍,而是通过智能路由实现双赢。随着技术的不断完善,我们有理由期待这一范式将推动AI系统向更高效、更智能、更人性化的方向发展,最终实现与人类认知过程的深度契合。
结论:重新定义高效推理的智能范式
CAR框架的提出标志着大语言模型推理优化进入了一个新阶段——从固定模式的机械式推理,迈向自适应的智能式推理。本文通过对这一创新技术的全面剖析,揭示了其背后的深刻洞见、精巧设计和显著效果。在这最后的结论部分,我们将凝练CAR框架的核心价值,并展望其对AI发展的长远影响。
核心创新与贡献
CAR框架的突破性贡献主要体现在三个层面:
理论层面:
-
颠覆了“长推理必然高精度”的传统认知
-
确立了困惑度(PPL)作为模型置信度可靠指标的地位
-
提出了基于概率决策的自适应路由理论框架
方法层面:
-
首创了基于高斯分布建模的智能路由机制
-
开发了混合指令微调的训练范式
-
实现了无需额外组件的端到端自适应推理
应用层面:
-
在多模态和纯文本任务上验证了通用有效性
-
展示了显著的Token节省(最高达85%)与精度提升(最高+5.5%)
-
提供了易于整合的轻量级解决方案
这些贡献共同构成了一个系统性的创新,而不仅仅是局部优化。CAR框架的核心论文《Prolonged Reasoning Is Not All You Need》标题本身就传达了一个深刻洞见:在AI推理中,“更多”并不总是“更好”,关键在于智能地分配计算资源。
对AI发展的启示
CAR框架的成功实践为AI领域提供了若干重要启示:
重视模型的内在信号:
-
与其构建复杂的外部控制机制,不如善用模型自身的置信度指标
-
类似人类直觉的“元认知”能力对AI同样重要
效率与精度的协同优化:
-
打破“效率-精度”必须取舍的思维定式
-
通过智能路由实现双重提升的可能性
人本化AI设计理念:
-
模仿人类认知的弹性——简单问题快速反应,复杂问题深入思考
-
推动AI从“机械执行”向“类人决策”演进
绿色AI的实现路径:
-
通过减少冗余计算降低AI的能源消耗
-
让大模型更易于在资源有限的环境中部署
领域适应的通用框架:
-
类似的置信度路由机制可推广至语音、视觉等多模态任务
-
为跨领域的自适应计算提供参考模板
与人类认知的深度类比
CAR框架与人类认知过程有着引人深思的相似性:
| CAR组件 | 人类认知对应 | 共同特点 |
|---|---|---|
| 短答案生成 | 直觉反应 | 快速、基于模式识别 |
| 困惑度计算 | 元认知监测 | 评估自身知道的确定性 |
| 路由决策 | 认知资源分配 | 决定投入多少思考精力 |
| 长推理生成 | 审慎思考 | 系统化、逐步推理 |
| 高斯分布建模 | 经验积累 | 基于过往表现校准信心 |
这种类比表明,CAR框架不仅在技术上创新,更在理念上接近人类智能的本质——弹性认知能力,即根据不同任务需求灵活调整思考深度的能力。
行业影响预测
基于当前分析,我们预测CAR及其衍生技术将在以下方面产生深远影响:
云计算成本降低:
-
大规模部署时,Token节省直接转化为成本下降
-
预计可使大模型API成本降低30-50%
边缘计算普及:
-
减少计算需求使大模型能在手机等终端设备运行
-
推动隐私保护与实时性要求高的应用发展
交互体验革新:
-
更符合人类预期的响应模式——简单问题快速回复
-
减少用户等待冗长推理的不必要延迟
专业领域渗透:
-
法律、医疗等高风险领域更易接受可调控的AI辅助
-
平衡快速响应与严谨分析的双重需求
AI评估体系完善:
-
从单一精度指标转向“精度-效率”综合评估
-
建立更全面的模型能力评价框架
终极愿景:认知协同的AI未来
CAR框架所代表的技术方向,其终极目标不仅是优化模型本身,更是为了实现更佳的人机认知协同。理想的AI系统应该:
-
像资深专家一样知道何时该简洁,何时需详述
-
像贴心助手一般理解用户的真实信息需求
-
像可靠伙伴那样在关键处提供深入分析
-
像节能设备般尽量减少不必要的计算
这种愿景下,CAR框架只是起点而非终点。未来的自适应推理系统可能会:
整合多维度置信信号:
-
结合PPL、隐藏状态、注意力模式等多种指标
-
实现更精细的认知状态评估
融入个性化适配:
-
根据用户偏好调整响应详细程度
-
学习不同场景下的最佳交互模式
发展动态能力调整:
-
在单次会话中灵活切换多种推理模式
-
实现真正的弹性认知架构
建立认知反馈循环:
-
从人类反馈中持续优化路由策略
-
形成不断自我完善的智能系统
正如CAR的核心论文所言:自适应路由不是终点,而是重新思考AI推理本质的起点。这一技术启示我们,AI的发展不仅需要更强大的模型,也需要更智能的资源分配策略,最终实现与人类认知过程的和谐统一。
在效率与精度这场看似零和的博弈中,CAR框架展示了一条双赢之路——不是通过妥协,而是通过更高层次的智能协调。这或许正是未来AI发展的关键方向:不是单纯追求“更大”或“更快”,而是追求“更恰当”与“更聪明”。随着这一理念的普及深化,我们有理由期待一个AI与人类优势互补、协同共进的新时代。