python 爬虫,爬取某乎某个用户的全部内容 + 写个阅读 app,慢慢读。
其实最初的原因是:https://www.zhihu.com/people/kai-li-peng对这个用户,我想把她的全部内容都读一遍。但是由于知乎的页面,不是分页的,所以我每次都需要滚动很久才能找到上次阅读的地方。你能理解我的痛点吗?然后我爬取了此用户所有的内容,得到 json直接渲染为 html ,太麻烦!所以改为采用 文章的 url请结合这些信息,重新写文章。
https://aistudio.google.com/prompts/1fPXoc20E_nX5He6xxh9FWFC3qKiAvYPY
好的,这下需求背景更清晰了!知乎的无限滚动确实对“断点续读”不太友好。我们来围绕这个痛点重新组织这篇文章,让它更有针对性!
标题:告别知乎无限滚动噩梦!DIY一个让你“接着读”的神器
嘿,各位知乎深度用户,内容收藏家们!你们是否也曾遇到这样的“甜蜜烦恼”:关注了一位宝藏答主(比如本文灵感来源:凯莉彭老师!),想把TA的全部精彩文章通读一遍,结果……
(此处可插入一张图片:一个无限向下滚动的知乎页面截图,或者一个在屏幕前疯狂滚动鼠标的小人,表情痛苦)
知乎那“永无止境”的动态流,让你每次重新打开页面,都得像考古一样,费劲地滚动、再滚动,才能找到上次阅读的“断点”。这种感觉,就像在知识的海洋里丢了指南针,令人抓狂!
一、 “痛点”的呐喊:我只想安安静静地接着读!
我的初心很简单,就是想系统性地学习某位知乎大V的全部输出。但现实是:
- “滚动到地老天荒”: 每次打开,都得手动滑很久,才能勉强找到上次的进度。
- “我是谁,我在哪儿”: 滑着滑着就忘了之前看到哪儿,效率低下。
- “稍后阅读”=“永不阅读”: 知乎的收藏夹虽好,但对于“通读所有”这个目标,还是不够直接。
我需要一个工具,能帮我把这位大V的文章“摊开来”,让我能清晰地看到列表,从容地选择,最重要的是——能记住我上次看到了哪里(或者至少方便我快速定位)!
(此处可插入一张图片:一个哭笑不得的表情包,旁边配字“我太难了,只想读个文章而已”)
二、 曲线救国:从“直接渲染”到“聪明导航”
“自己动手,丰衣足食!” 既然官方体验不完美,那就自己造!
我的第一反应是:“爬下来,本地看!” 于是,我吭哧吭哧地把目标用户的所有内容爬取下来,得到了一堆JSON文件。
最初的想法很“莽”:把JSON里的HTML内容直接渲染成网页。但很快发现,这活儿太细致,图片处理、样式调整……简直是给自己挖了个新坑!如果只是为了“接着读”,这成本也太高了。
于是,灵光一闪:我真正需要的不是在本地复刻一个知乎,而是一个高效的“文章目录”和“传送门”!
三、 神器诞生:我的专属“知乎续读助手”!
想通了这一点,方案瞬间清晰:
- 数据瘦身,只取精华: 我不再关心完整的HTML内容,只从每个JSON文件中提取每篇文章的:
文章标题(一眼就知道是哪篇)发布时间(方便按时间排序和定位)原文URL(最重要的“传送门”地址)
- 两层导航,一目了然:
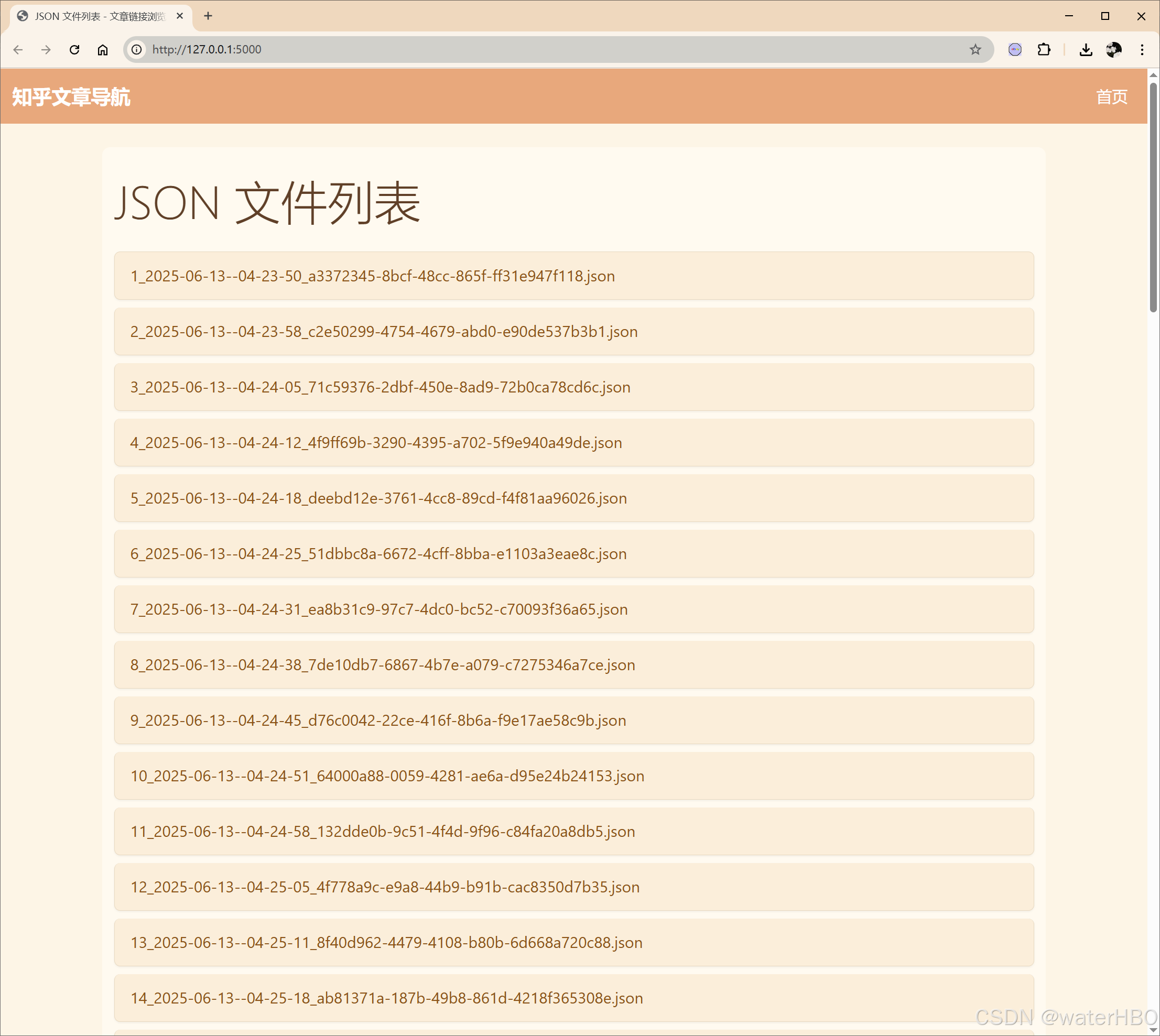
- 第一层 (首页):JSON文件集散地。 由于爬取的内容可能按批次或其他方式分成了多个JSON文件,首页就列出这些文件名。比如
凯莉彭文章_第一部分.json,凯莉彭文章_第二部分.json。想看哪个集子里的?点它!
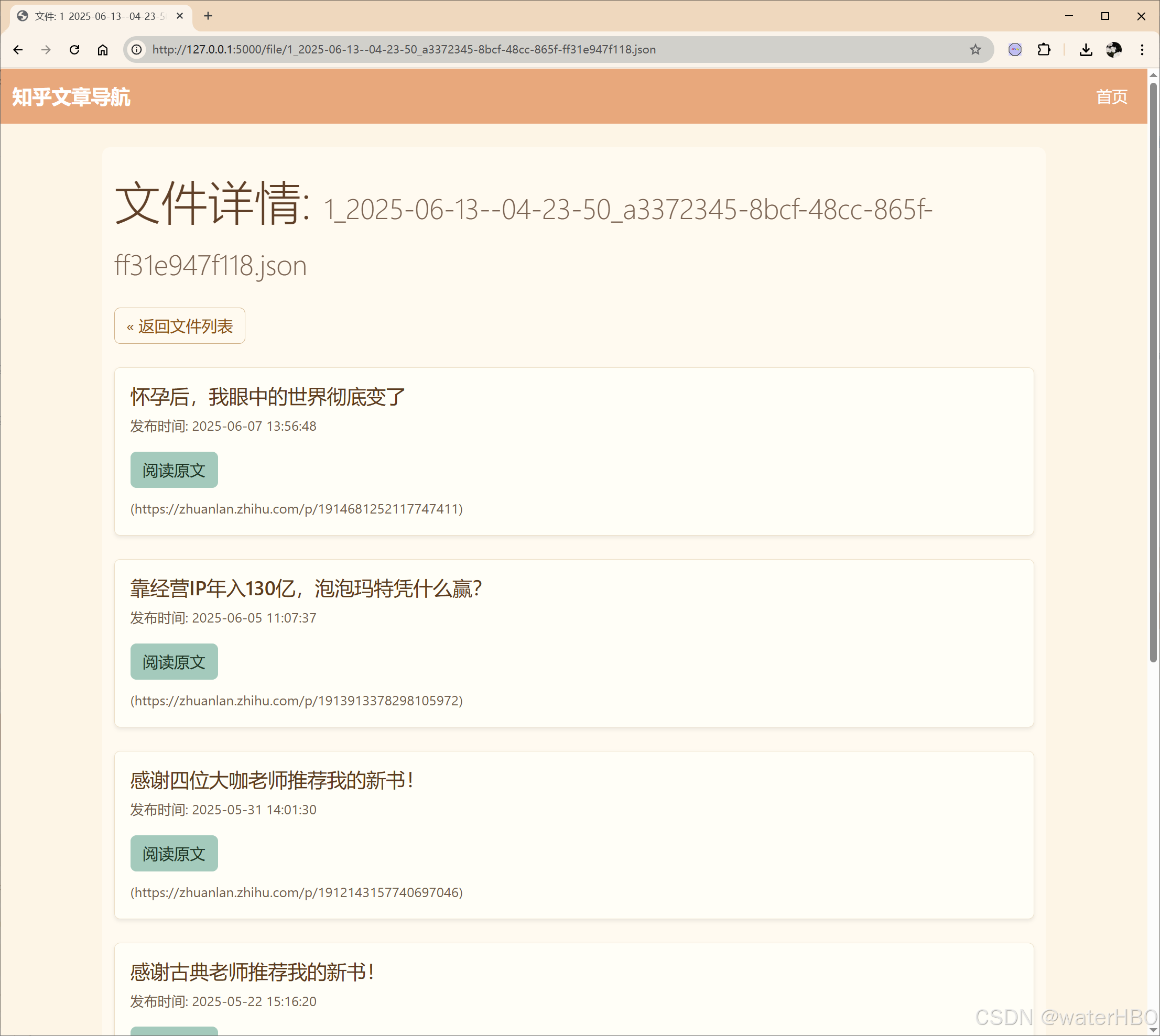
(此处可插入一张图片:一个简洁的列表,列着几个有意义的JSON文件名) - 第二层 (文件内文章列表):文章精确制导。 点击文件名后,页面会清晰地展示这个JSON文件里所有文章的
标题、格式化后的发布时间,以及一个直达知乎原文的“阅读原文”按钮。
(此处可插入一张图片:一个文章条目,包含标题、时间和一个明显的“阅读原文”按钮,按钮上可以有个知乎的小图标)
- 第一层 (首页):JSON文件集散地。 由于爬取的内容可能按批次或其他方式分成了多个JSON文件,首页就列出这些文件名。比如
最终成果的亮点,以及它如何解决我的痛点:
- 告别无限滚动: 所有文章(按文件分批)一目了然地列出,我可以快速浏览标题和发布时间。
- “断点”清晰可见: 虽然这个简单版没有做复杂的已读/未读标记,但因为文章是按时间排序的,我可以很容易地根据上次阅读文章的标题或发布时间,在列表中快速定位到“下一篇”。效率大大提升!
- 专注阅读: 点击“阅读原文”,直接跳转到知乎页面,享受原汁原味的阅读体验,不用在本地简陋的渲染效果里纠结。
- 轻量高效: 应用本身非常小巧,只做索引和跳转,不占用过多资源。
- 可扩展性: 如果未来还想“通读”其他答主,只需把新的JSON文件丢进
data/目录即可。
(此处可插入一张图片:一个用户坐在电脑前,轻松愉悦地点击着自制导航页面的链接,旁边有个“已解决”的标记)
给有同样“痛点”的你的实用秘笈:
- 正视痛点,寻找捷径: 当现有工具无法满足你时,别硬扛,想想有没有更聪明的办法。
- 明确核心价值: 你是为了“完美复现”还是为了“高效解决问题”?抓住核心,能省去很多不必要的麻烦。
- “够用就好”也是一种智慧: 尤其对于个人小工具,快速实现核心功能比追求面面俱到更重要。
- 技术服务于需求: 学习和使用技术的最终目的是解决实际问题,让生活(或学习)更美好。
所以,如果你也曾被知乎(或其他平台的)无限滚动折磨,如果你也想系统地“啃”完某位大神的全部精华,不妨试试这个思路。用一点点代码的魔法,就能为自己打造一个清爽、高效的专属“续读导航站”。从此,在知识的海洋里遨游,再也不怕迷路啦!
希望这个因“追更”而生的故事,能给你带来一些解决问题的灵感!
代码 1, 爬虫代码,使用的是 mitmproxy,本月重点研究的对象。
# save_json_filter.py
import os
import time
import uuid
from mitmproxy import http
from urllib.parse import urlparse, parse_qs# 定义保存 JSON 的目录
JSON_DIR = "json_data"# 确保目录存在
if not os.path.exists(JSON_DIR):os.makedirs(JSON_DIR)class SaveJSON:def response(self, flow: http.HTTPFlow) -> None:# 目标 URL 前缀target_url = "https://www.zhihu.com/api/v3/moments/kai-li-peng/activities"# 检查请求的 URL 是否以目标 URL 开头if flow.request.url.startswith(target_url):# 获取响应的 Content-Typecontent_type = flow.response.headers.get("Content-Type", "").lower()# 判断是否为 JSON 类型if "application/json" in content_type:# 打印完整的 URLprint(f"捕获到 JSON URL: {flow.request.url}")# 解析 URL 的查询参数parsed_url = urlparse(flow.request.url)query_params = parse_qs(parsed_url.query)# 生成时间戳timestamp = time.strftime("%Y-%m-%d--%H-%M-%S", time.localtime())# 生成 UUIDfile_uuid = str(uuid.uuid4())# 判断是否有 offset 和 page_numpage_num = query_params.get("page_num", [None])[0]offset = query_params.get("offset", [None])[0]if page_num and offset:# 有 page_num 和 offset,文件名用 (page_num+1)page = int(page_num) + 1filename = f"{page}_{timestamp}_{file_uuid}.json"else:# 没有 page_num 和 offset,默认为第一页filename = f"1_{timestamp}_{file_uuid}.json"# 保存 JSON 文件path = os.path.join(JSON_DIR, filename)with open(path, "wb") as f:f.write(flow.response.content)# 注册插件
addons = [SaveJSON()]"""
聊天:https://grok.com/chat/6ff2afc1-1859-4024-82a9-090faa090f97# 不要解析,就保存最原始的格式,json !!!# 开头是 https://www.zhihu.com/api/v3/moments/kai-li-peng/activities
"""# 运行命令:# --------------------- 使用 clash 代理链 -------------------
# 1. 先启动 mitmdump
# mitmdump -s s3_just_json.py --mode upstream:http://127.0.0.1:7897 --set console_eventlog_verbosity=warn
# mitmdump -s s3_just_json.py --mode upstream:http://127.0.0.1:7897 -q# 2. 再启动浏览器:
# start chrome --proxy-server="127.0.0.1:8080"本地 app 效果:
希望对大家有帮助。