【第三十九周】ViLT
ViLT
- 摘要
- Abstract
- 文章信息
- 介绍
- 提取视觉特征的方式的演变
- 模态融合的两种方式
- 四种不同的 VLP 模型
- Q&A
- 方法
- 模型结构
- 目标函数
- Whole Word Masking(WWM)
- 实验结果
- 总结
摘要
本篇博客介绍了ViLT(Vision-and-Language Transformer),这是一种简洁高效的视觉语言预训练模型,旨在解决传统 VLP 方法中过度依赖深度卷积网络和区域监督带来的计算开销高和表达受限等问题。该模型的核心思想是将图像与文本统一通过线性投影进行嵌入处理,并在共享的 Transformer 中进行深度跨模态融合,从而彻底移除视觉特定的 CNN 主干和目标检测器。ViLT 针对图像特征提取复杂、慢的问题,提出了基于 patch projection 的轻量级视觉嵌入方式,使视觉输入的处理成本降至最低,并结合 Masked Language Modeling(MLM)与 Image-Text Matching(ITM)等预训练任务提升下游性能。实验表明,ViLT 在多项视觉语言任务中以极低的计算资源达成与传统重模型相近甚至更优的效果。其优势在于结构极简、推理速度快、易于部署,但也存在对细粒度视觉语义建模能力不足的局限。
Abstract
This blog introduces ViLT (Vision-and-Language Transformer), a simple and efficient vision-language pretraining model designed to address the high computational cost and limited expressive power caused by the heavy reliance on deep convolutional networks and region-level supervision in traditional VLP methods. The core idea of ViLT is to unify image and text inputs through linear projection and perform deep cross-modal fusion within a shared Transformer, thereby completely removing the need for CNN-based visual backbones and object detectors. To tackle the complexity and latency of visual feature extraction, ViLT employs a lightweight patch projection-based embedding strategy that minimizes visual input processing overhead, while leveraging pretraining objectives such as Masked Language Modeling (MLM) and Image-Text Matching (ITM) to enhance downstream performance. Experiments show that ViLT achieves comparable or even better results than traditional heavy models on various vision-language tasks, with significantly lower computational cost. Its strengths lie in its minimal design, fast inference, and ease of deployment, although it has limitations in modeling fine-grained visual semantics.
文章信息
Title:ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
Author:Wonjae Kim, Bokyung Son, Ildoo Kim
Source:https://arxiv.org/abs/2102.03334
介绍
在ViLT的提出之前,视觉与语言预训练(VLP)在跨模态任务(如图文检索、视觉问答等)上取得了显著进展。然而,现有方法大多依赖计算量大的图像特征提取模块(如基于目标检测的区域特征或CNN提取的全局特征),这不仅降低了效率,还限制了模型的表达能力。本文介绍的 ViLT(Vision-and-Language Transformer)是一种极简的VLP模型,其核心创新是完全摒弃传统卷积或区域监督方法,改用类似文本处理的“无卷积”方式直接建模视觉输入。实验证明,ViLT 比之前的方法快数十倍,同时在下游任务上保持甚至超越SOTA性能。
提取视觉特征的方式的演变

之前的 VLP 模型的 text embedding 基本上都使用类 BERT 结构,但是 visual embedding 存在着差异。往往处理视觉特征的网络越复杂,模型效果就越好,所以提取视觉特征是现有 VLP 模型的瓶颈。如上图所示,获取visual embedding的方法总共有三大类:
- Region feture(区域特征):通常采用 Faster R-CNN 二阶段检测器提取区域性特征,这种方法的成本是最高的,比如图像经过ResNet101 backbone(一系列的卷积层用于提取图像的feature maps)提取特征,再经过RPN(Region Proposal Network,区域生成网络)得到一些RoI(Region of interest,感兴趣区域),然后使用NMS(Non-Maximum Suppression,非极大抑制)过滤冗余的RoI,最后经过RoI Head(在RPN生成的候选区域中,对候选区域进行分类和边界框回归的神经网络模块)得到一些一维的向量(Region Feature),也就是一个个bounding box。
- Grid Feature(网格特征):将CNN backbone得到的feature map,作为网格特征,大大降低了计算量。比如将ResNet50最后得到的7×7特征图拉直为一个序列,或者是上一层的14×14的特征图。
- Patch Projection(块投影):受ViT中patch projection层效果的启发,使用类似ViT模型中的patch projection层直接得到patch embeddings。ViLT是首个这么做的,第一,这种方法不需要使用额外的网络;其次,不需要缓存特征,Region feture和Grid feature都需要先使用预训练的模型提前抽取好图片特征,然后再训练。虽然这样训练还是比较轻量的,但在部署的时候是一个很大的局限性,因为真实场景里每时每刻都在生成新数据,都需要抽取新数据的特征,这时推理速度就是一大瓶颈。
在文本方面,这些模型都是基本一样的,通过一个Embedding矩阵,变成一个个的word token。得到了视觉的序列和文本的序列后输入到Modality Interaction(基本都是Transformer)进行模态之间的融合。
模态融合的两种方式
- Single-stream:单通路结构,文本特征和图像特征直接concat连接,然后输入一个transformer进行交互;
- Dual-stream:双通道结构,文本特征和图像特征分别过一个文本模型和图像模型,充分挖掘单模态特征,然后再经过一个transformer layer做融合。
这两种方法的效果相差不大,但 Dual-stream 的参数量和计算量更大,成本更高,所以在ViLT中作者采用了 Single-stream 的方式。
四种不同的 VLP 模型
作者总结了视觉-语言模型(Vision-and-Language Models)的 四种计算范式分类,通过比较视觉嵌入(VE)、文本嵌入(TE)和模态交互(MI) 三个模块的相对计算量(矩形高度表示),展示不同模型的设计差异。

- Visual Embedder (VE):图像特征提取(如CNN、区域检测器、线性投影)。
- Textual Embedder (TE):文本特征提取(如BERT、Word2Vec)。
- Modality Interaction (MI):跨模态交互(如Transformer注意力机制)。
(a)VE > TE > MI
视觉嵌入计算量最大,文本次之,模态交互最小。VSE/ SCAN等模型的做法,视觉特征的处理远大于文本特征,模态融合只使用了简单的点乘操作或很简单的浅层attention网络。
(b)VE = TE > MI
视觉和文本嵌入计算量相当,均大于模态交互。CLIP就是属于此种类别,每个模态单独使用transformer encoder,两者计算量相当,特征融合部分,只是简单的计算了一下图文特征的相似性。CLIP特别适合需要图文特征(GroupViT/GLIP等)或者是图文检索的任务,但做VQA或者visual reasoning(视觉推理,更难的VQA)这种需要视觉推理的任务时,会稍逊一筹。因为一个简单的不可学习的点乘,是没法做深层次的特征融合和分析的。
(c)VE > MI > TE
模态交互计算量显著增加,视觉/文本嵌入比重降低。比如ViLBERT、UNITER、Pixel-BERT等。
(d) MI > VE = TE
视觉嵌入极简(线性投影,VE耗时低),文本用标准BERT(TE),模态交互(MI)成为主要计算部分。ViLT 就是属于此种模型。
Q&A
对于文本侧,使用 Transformer 是最好的选择,但对于 VLP 来说,就必须将图像的像素转成带有语义性质的具有离散性的特征。这样才能与文本的 tokens 有效匹配,后续才能进行两种模态的融合。
那么为什么之前的 VLP 用目标检测器来处理图像特征?
- 图像的像素太多,Transformer 处理不了这么长的序列。
- 目标检测是一个离散化的过程,返回的是 bounding box,它代表一个个物体,有明确的语义信息(可类比文本中的token),而且还是离散化的。
- 当时的VLP 下游任务主要是VQA(Visual Question Answering)、Image Captioning、Image Retrieval 等,这些任务往往都跟物体有非常直接的联系,有非常强的对物体的依赖性。
方法
模型结构
下图展示了 ViLT(Vision-and-Language Transformer) 的核心架构,它是一种纯Transformer的多模态模型,完全摒弃了CNN和区域检测器,实现了高效的视觉-语言联合建模。
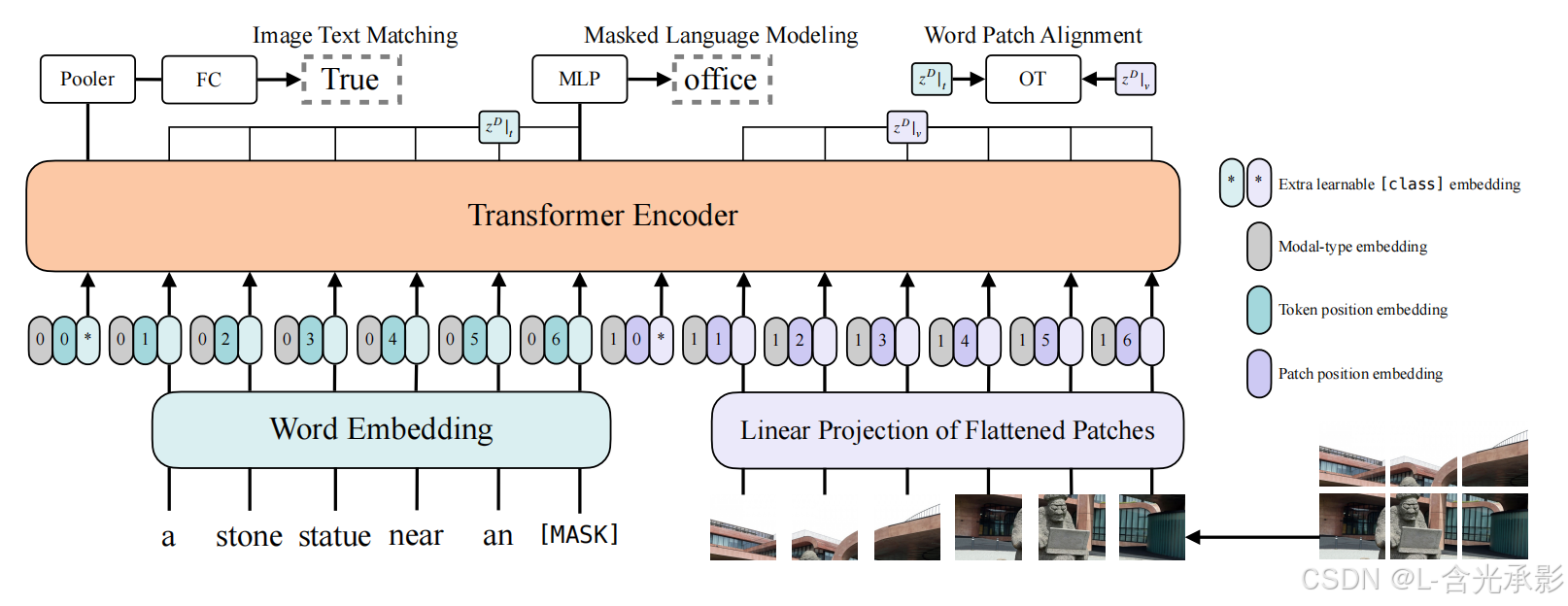
输入:
- 文本经过pre-trained BERT tokenizer得到word embedding(前面有CLS token,图中*表示);
- 图片经过ViT patch projection层得到patch embedding(也是用*表示CLS token);
- 文本特征+文本位置编码+模态嵌入得到最终的text embedding,图像这边也是类似的操作得到image embedding;二者concat拼接之后,一起输入transformer layer,然后做MSA交互(多头自注意力)
注意:在Single-stream模型中,图文特征是直接拼在一起输入一个transformer,为了区分两种不同的模态,需要加上模态嵌入。
下面结合论文中的公式介绍具体流程:

公式1: 文本输入嵌入
t class t_\text{class} tclass:文本模态的 [CLS] 向量; t i T t_i^T tiT:第 i i i 个 token 的词向量嵌入; T pos T^\text{pos} Tpos:文本的位置嵌入(position embeddings); [ ⋅ ; ⋅ ] [\cdot; \cdot] [⋅;⋅]:表示拼接操作。最终得到的是一组带有位置信息的文本 token 嵌入序列。
公式2: 图像输入嵌入
图像被划分为 N N N 个 patch,每个 patch 被展平后通过线性投影生成向量 v i V v_i^V viV; v class v_\text{class} vclass:图像模态的 [CLS] 向量; V pos V^\text{pos} Vpos:图像 patch 的位置嵌入。类似于文本嵌入,图像也被编码成带位置信息的序列。
公式3:拼接图文输入 + 模态类型嵌入
t type t^\text{type} ttype 和 v type v^\text{type} vtype:模态类型嵌入,用于标识每个 token 是来自文本还是图像;文本与图像嵌入分别加上类型标识后拼接,形成最终输入序列 z 0 z^0 z0; z 0 z^0 z0 是 Transformer 编码器的初始输入。
公式4、5: Transformer 编码器的每层前向传播
ViLT 使用标准的 ViT Transformer Block;每层包含 LayerNorm、Multi-head Self-Attention (MSA)、前馈网络(MLP)和残差连接;ViLT 使用 Pre-LN 架构,即 LayerNorm 在模块输入前; z d z^d zd 表示第 d d d 层的输出。
公式6: 多模态输出池化表示
z 0 D z^D_0 z0D:Transformer 最后一层第一个位置的输出向量(即 [CLS] token); W pool W^\text{pool} Wpool:可学习的线性投影矩阵; p p p 是最终的图文融合表示,用于分类或匹配任务。
目标函数
ViLT使用了一般VLP模型常用的目标函数,即图文匹配损失( ITM,image text matching)和 BERT的掩码学习损失(MLM,Masked Language Modeling)。另外,ViLT还使用了Word Patch Alignment(WPA),简单理解就是将文本和图像的输出都当做一个概率分布,然后使用最优运输理论计算一下两者的距离。
Whole Word Masking(WWM)
不按照token,而按整个词进行 Mask。在 VLP(视觉语言预训练)场景中,WWM 可以显著增强跨模态信息的利用。例如:如果只遮了 “gi” 和 “##fe”,模型可能只用剩下的 “##raf” 推断出 “giraffe”,这就使图像信息的作用变弱了。WWM 迫使模型必须依靠图像信息来预测整个词的语义,从而提升图文联合建模效果。
实验结果

如图所示,ViLT相比于region feature的方法速度快了60倍,相比于grid feature的方法快了4倍,而且下游任务表现出相似甚至更好的性能。

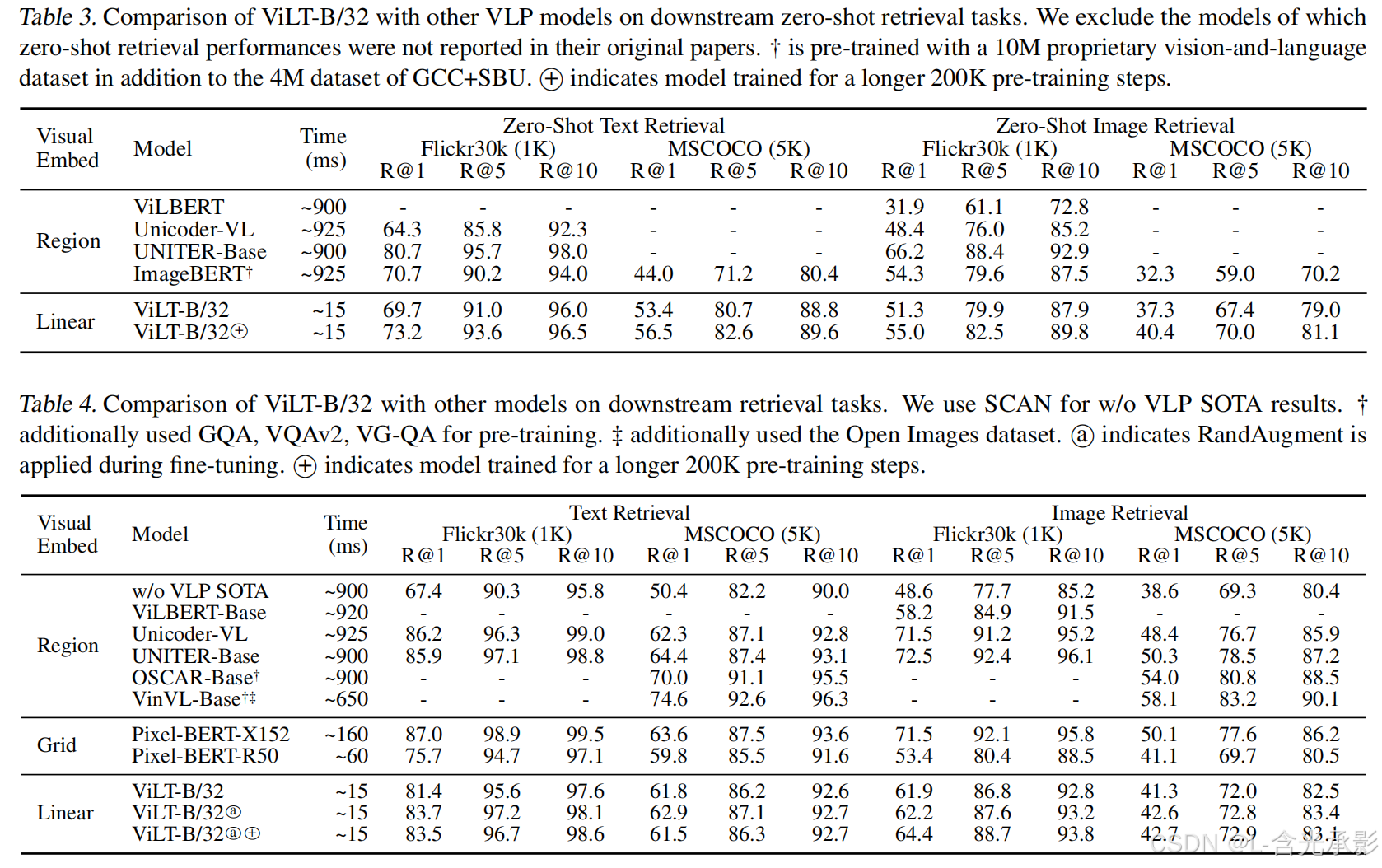
从table2、table3和table4中可以看出,相对于region和grid的方法,ViLT在下游任务表现出相似甚至更好的性能。

从上图的可视化结果可看出,ViLT学到了word和image patch之间的对应关系。
下面是HuggingFace Transformers实现的vilt模型:
import torch
from torch import nn
from transformers.models.vilt.configuration_vilt import ViltConfigclass ViltEmbeddings(nn.Module):"""构造图像 patch + 文本 token 的嵌入输入,模仿 ViT 和 BERT 的做法。"""def __init__(self, config: ViltConfig):super().__init__()# 文本词嵌入(等同于 BERT)self.text_embeddings = nn.Embedding(config.vocab_size, config.hidden_size)self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)# 图像 patch 嵌入(等同于 ViT)patch_size = config.patch_sizeself.patch_embed = nn.Conv2d(in_channels=config.num_channels,out_channels=config.hidden_size,kernel_size=patch_size,stride=patch_size)# 初始化 image [CLS] tokenself.cls_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))# 图像 patch 的位置嵌入num_patches = (config.image_size // patch_size) ** 2self.image_position_embeddings = nn.Parameter(torch.zeros(1, num_patches + 1, config.hidden_size))# 图像模态的 token type embeddingself.modality_type_embeddings = nn.Embedding(config.modality_type_vocab_size, config.hidden_size)def forward(self, input_ids, pixel_values):# 文本嵌入:token + position + token_typeseq_length = input_ids.size(1)positions = torch.arange(seq_length, device=input_ids.device).unsqueeze(0)x_text = self.text_embeddings(input_ids) + \self.position_embeddings(positions) + \self.token_type_embeddings(torch.zeros_like(input_ids))# 图像嵌入:Patch Projection + [CLS] token + position + modality typex_image = self.patch_embed(pixel_values) # [B, H, sqrtP, sqrtP]B, C, H, W = x_image.shapex_image = x_image.flatten(2).transpose(1, 2) # [B, num_patches, C]cls_tokens = self.cls_token.expand(B, -1, -1) # 图像专用 CLSx_image = torch.cat([cls_tokens, x_image], dim=1)x_image = x_image + self.image_position_embeddings + self.modality_type_embeddings(torch.ones(x_image.size()[:2], dtype=torch.long, device=x_image.device))# 合并文本与图像嵌入为单流输入x_text = x_text + self.modality_type_embeddings(torch.zeros(x_text.size()[:2], dtype=torch.long, device=x_text.device))return torch.cat([x_text, x_image], dim=1)class ViltModel(nn.Module):"""单流 Transformer 模型,用于融合文本和图像输入,输出跨模态特征。"""def __init__(self, config: ViltConfig):super().__init__()self.embeddings = ViltEmbeddings(config)self.encoder = nn.TransformerEncoder(nn.TransformerEncoderLayer(d_model=config.hidden_size,nhead=config.num_attention_heads,dim_feedforward=config.intermediate_size,dropout=config.hidden_dropout_prob,activation=config.hidden_act),num_layers=config.num_hidden_layers)self.pooler = nn.Linear(config.hidden_size, config.hidden_size)self.activation = nn.Tanh()def forward(self, input_ids, pixel_values):# 1. 构建输入嵌入embedding_output = self.embeddings(input_ids, pixel_values)# 2. 深度多层自注意力 Transformer 编码encoded_output = self.encoder(embedding_output.transpose(0, 1)).transpose(0, 1)# 3. 池化:取第一个 [CLS] token,用线性层 + tanh 变换cls_output = encoded_output[:, 0, :] # batch x hiddenpooled_output = self.activation(self.pooler(cls_output))return encoded_output, pooled_output源码:https://github.com/dandelin/vilt.
总结
ViLT 作为首个完全去除卷积网络和区域监督的视觉-语言预训练模型,提出了一种极简而高效的架构:其通过将图像划分为 patch 并进行线性投影,使图像和文本在输入阶段即被统一处理,再通过单流 Transformer 实现深层跨模态交互,最终利用 [CLS] 向量进行任务预测。相比传统依赖目标检测器或 CNN 视觉编码器的模型,ViLT 显著降低了计算开销,同时保持了主流任务上的竞争性能。其主要优势在于架构轻量、推理速度快、易于扩展,而劣势则在于去除区域信息后在精细对象级任务上略显不足。未来研究可进一步探索更有效的视觉掩码策略、增强跨模态对齐机制、以及在大规模数据或更大模型(如 ViLT-L/H)上的扩展能力,以实现兼顾效率与表达力的更强多模态预训练模型。