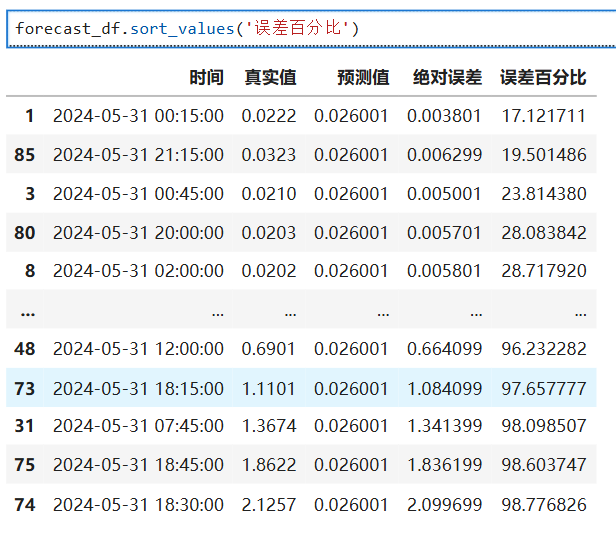
自适应移动平均(Adaptive Moving Average, AMA)
文章目录
- 1. 考夫曼自适应移动平均 (KAMA)算法推导及Python实现
- 2. 对 (KAMA)算法参数进行优化及实现
自适应移动平均(Adaptive Moving Average, AMA)由Perry Kaufman在其著作《Trading Systems and Methods》中提出,它通过动态调整平滑系数来适应不同的市场状况:
在趋势明显时,AMA更像快速移动平均线,紧跟价格变化
在震荡市场时,AMA更像慢速移动平均线,过滤噪音。
是一种动态调整平滑系数的移动平均方法,适用于非线性、非平稳的【时间序列数据预测场景】(如负荷受温度、节假日等因素影响),其核心是通过波动率或趋势指标自动调整权重,提高预测灵敏度。
在接触过程中记录一下。
1. 考夫曼自适应移动平均 (KAMA)算法推导及Python实现

import numpy as np
import pandas as pd
import matplotlib.pyplot as pltdef ama(close_prices, n=10, fast_sc=2, slow_sc=30):"""计算自适应移动平均线(AMA)参数:close_prices: 收盘价序列 (list, np.array或pd.Series)n: 计算效率比率(ER)的周期 (默认10)fast_sc: 快速平滑常数周期 (默认2)slow_sc: 慢速平滑常数周期 (默认30)返回:AMA值 (np.array)"""close = np.array(close_prices)length = len(close)ama_values = np.zeros(length)sc = np.zeros(length)er = np.zeros(length)fast_alpha = 2 / (fast_sc + 1)slow_alpha = 2 / (slow_sc + 1)# 初始AMA值为第一个收盘价ama_values[0] = close[0]for i in range(1, length):# 计算方向变化和波动总和direction = abs(close[i] - close[i - n if i >= n else 0])volatility = sum(abs(close[j] - close[j-1]) for j in range(max(1, i-n+1), i+1))# 计算效率比率(ER)er[i] = direction / volatility if volatility != 0 else 0# 计算平滑系数(SC)temp_sc = er[i] * (fast_alpha - slow_alpha) + slow_alphasc[i] = temp_sc * temp_sc # 平方使变化更平滑# 计算AMAama_values[i] = ama_values[i-1] + sc[i] * (close[i] - ama_values[i-1])return ama_values# 示例使用
if __name__ == "__main__":# 生成示例数据(正弦波+随机噪声)np.random.seed(42)x = np.linspace(0, 10, 200)prices = np.sin(x) * 10 + np.random.normal(0, 1, 200) + 20# 计算AMAama_values = ama(prices, n=2, fast_sc=2, slow_sc=30)# 绘图plt.figure(figsize=(12, 6))plt.plot(prices, label='Data', alpha=0.5)plt.plot(ama_values, label='AMA(2,2,30)', color='red', linewidth=2)plt.title("Adaptive Moving Average (AMA)")plt.legend()plt.grid()plt.show()
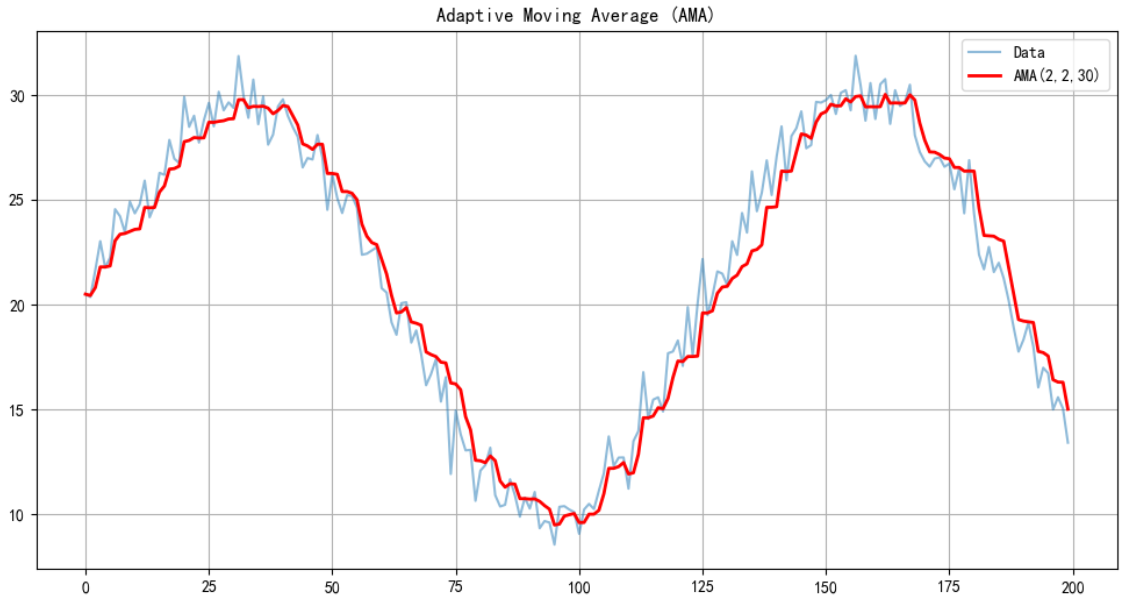
2. 对 (KAMA)算法参数进行优化及实现
## 基于上面方法的对参数进行优化
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_errordef ama(close_prices, n=10, fast_sc=2, slow_sc=30):"""计算自适应移动平均线(AMA)参数:close_prices: 收盘价序列 (list, np.array或pd.Series)n: 计算效率比率(ER)的周期 (默认10)fast_sc: 快速平滑常数周期 (默认2)slow_sc: 慢速平滑常数周期 (默认30)返回:AMA值 (np.array)"""close = np.array(close_prices)length = len(close)ama_values = np.zeros(length)sc = np.zeros(length)er = np.zeros(length)fast_alpha = 2 / (fast_sc + 1)slow_alpha = 2 / (slow_sc + 1)# 初始AMA值为第一个收盘价ama_values[0] = close[0]for i in range(1, length):# 计算方向变化和波动总和direction = abs(close[i] - close[i - n if i >= n else 0])volatility = sum(abs(close[j] - close[j-1]) for j in range(max(1, i-n+1), i+1))# 计算效率比率(ER)er[i] = direction / volatility if volatility != 0 else 0# 计算平滑系数(SC)temp_sc = er[i] * (fast_alpha - slow_alpha) + slow_alphasc[i] = temp_sc * temp_sc # 平方使变化更平滑# 计算AMAama_values[i] = ama_values[i-1] + sc[i] * (close[i] - ama_values[i-1])return ama_valuesdef optimize_ama(close_prices, n_range, fast_range, slow_range):best_params = {}min_mse = float('inf')for n in n_range:for fast in fast_range:for slow in slow_range:ama_vals = ama(close_prices, n, fast, slow)mse = mean_squared_error(close_prices[n:], ama_vals[n:])if mse < min_mse:min_mse = msebest_params = {'n': n, 'fast': fast, 'slow': slow}return best_paramsparams = optimize_ama(prices, n_range=range(2, 21, 3),fast_range=range(2, 6),slow_range=range(10, 31, 3))
print("最佳参数:", params)# 示例使用
if __name__ == "__main__":# 生成示例数据(正弦波+随机噪声)np.random.seed(42)x = np.linspace(0, 10, 200)prices = np.sin(x) * 10 + np.random.normal(0, 1, 200) + 20# 计算AMAn = params['n']fast_sc = params['fast']slow_sc = params['slow']ama_values = ama(prices, n= n, fast_sc =fast_sc , slow_sc=slow_sc)# 绘图plt.figure(figsize=(12, 6))plt.plot(prices, label='Data', alpha=0.5)plt.plot(ama_values, label=f'AMA({n},{fast_sc},{slow_sc})', color='red', linewidth=2)plt.title("Adaptive Moving Average (AMA)")plt.legend()plt.grid()plt.show()
## 方法2
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import ParameterGrid
from sklearn.metrics import mean_absolute_error, mean_squared_error
import logging
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 配置日志
logging.getLogger('prophet').setLevel(logging.WARNING)
logging.getLogger('cmdstanpy').setLevel(logging.WARNING)# =================================== 1. 模拟数据生成(若已有真实数据,可跳过此步) ====================
def data_row_column(hourly_loads): #将数据1*96转换成96*1# 计算时间戳(每15分钟一个点)hourly_loads["point_idx"] = hourly_loads["point"].str.extract("(\d+)").astype(int)hourly_loads["hour"] = (hourly_loads["point_idx"] - 1) // 4 # 计算小时(0-23)hourly_loads["minute"] = ((hourly_loads["point_idx"] - 1) % 4) * 15 # 计算分钟(0, 15, 30, 45)hourly_loads["timestamp"] = hourly_loads["amt_ym"] + pd.to_timedelta(hourly_loads["hour"], unit="h") + pd.to_timedelta(hourly_loads["minute"], unit="m")# 按时间戳排序hourly_loads = hourly_loads.sort_values("timestamp")ts_df = hourly_loads[["timestamp", "load"]].set_index("timestamp")return ts_dfRAWcus_df = pd.read_excel("D:\\data_example.xlsx",engine='openpyxl')
cus_df = RAWcus_df.copy()
cus_df['年月'] = cus_df['amt_ym'].dt.strftime('%Y-%m')
load_series1 = data_row_column(cus_df).squeeze()
train_data = load_series1[:-96] # 训练集(排除最后96点)
test_data = load_series1[-96:] # 测试集(最后96点)# =================================== 2. AMA模型实现 ====================
def ama_forecast(data, forecast_steps=96, window=24*4, alpha_min=0.05, alpha_max=0.95, initial_window=100):"""AMA模型预测(带动态平滑系数调整):param data: 历史负荷序列(Series):param forecast_steps: 预测步长:param window: 计算效率比率(ER)的窗口大小 =n:param alpha_min: 平滑系数下限 =s:param alpha_max: 平滑系数上限 =f:param initial_window: 初始化AMA的窗口( warm-up 阶段):return: 预测结果数组(numpy.ndarray)"""history = data.values.copy()n = len(history)ama = np.zeros(n + forecast_steps)ama[:n] = history# Warm-up阶段:用简单移动平均初始化AMAif initial_window > 0:ama[:initial_window] = np.convolve(history[:initial_window], np.ones(5)/5, mode='same')for t in range(n, n + forecast_steps):# 计算效率比率(ER)start_idx = max(0, t - window)direction = abs(ama[t-1] - ama[start_idx])volatility = sum(abs(ama[i] - ama[i-1]) for i in range(start_idx + 1, t))er = direction / (volatility + 1e-6) # 避免除零# 动态平滑系数alpha = er * (alpha_max - alpha_min) + alpha_minalpha = np.clip(alpha, alpha_min, alpha_max) # 限制在[min, max]范围内# 更新AMA(假设未来变化与最近变化相同)recent_change = ama[t-1] - ama[t-2] if t >= 2 else 0ama[t] = ama[t-1] + alpha * recent_changereturn ama[n:]# =================================== 3. 参数调优(网格搜索) ====================
def grid_search_ama(train_data, test_data, param_grid):"""网格搜索最优AMA参数"""best_params = Nonebest_mae = float('inf')results = []for params in ParameterGrid(param_grid):# 滚动预测验证forecasts = []for i in range(len(test_data)):history = pd.concat([train_data, test_data[:i]])pred = ama_forecast(history, forecast_steps=1, **params)forecasts.append(pred[0])# 计算指标mae = mean_absolute_error(test_data, forecasts)results.append({'params': params, 'MAE': mae})if mae < best_mae:best_mae = maebest_params = paramsreturn best_params, best_mae, pd.DataFrame(results)# 定义参数搜索空间
param_grid = {'window': [10,24*1, 24*2, 24*4,24*10,24*15], # 等效窗口大小 n: 1天、2天、4天窗口 'alpha_min': [0.01, 0.05, 0.1,0.5], # s'alpha_max': [0.8, 0.9, 0.95], # f'initial_window': [50, 100, 200]
}# 执行网格搜索(耗时操作,实际使用时建议缩小参数范围)
best_params, best_mae, search_results = grid_search_ama(train_data, test_data, param_grid)
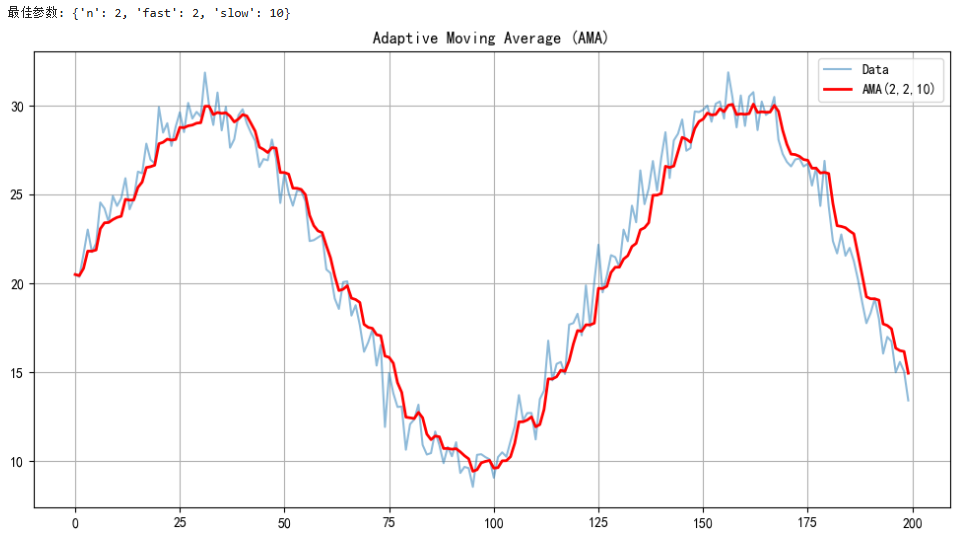
print(f"最佳参数: {best_params}, 最优MAE: {best_mae:.2f}")# =================================== 4. 使用最优参数预测 ====================
final_forecast = ama_forecast(train_data, forecast_steps=96, **best_params)# =================================== 5. 评估与可视化 ====================
# 计算指标
mae = mean_absolute_error(test_data, final_forecast)
rmse = np.sqrt(mean_squared_error(test_data, final_forecast))
print(f"测试集 MAE: {mae:.2f}, RMSE: {rmse:.2f}")# 绘图
plt.figure(figsize=(14, 6))
plt.plot(train_data.index[-200:], train_data.values[-200:], label="历史负荷", color="blue", alpha=0.7)
plt.plot(test_data.index, test_data.values, label="真实值", color="green", marker='o', markersize=3)
plt.plot(test_data.index, final_forecast, label="AMA预测", linestyle="--", color="red", linewidth=2)
plt.fill_between(test_data.index, final_forecast - rmse, final_forecast + rmse, color="red", alpha=0.1, label="±RMSE误差带")
plt.title(f"负荷预测 (AMA模型)\n最优参数: {best_params}, MAE: {mae:.2f}, RMSE: {rmse:.2f}")
plt.xlabel("时间")
plt.ylabel("负荷")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()# 保存预测结果
forecast_df = pd.DataFrame({"时间": test_data.index,"真实值": test_data.values,"预测值": final_forecast,"绝对误差": np.abs(test_data.values - final_forecast),"误差百分比":np.abs(test_data.values - final_forecast)/test_data.values*100
})
# forecast_df.to_csv("ama_load_forecast_results.csv", index=False)
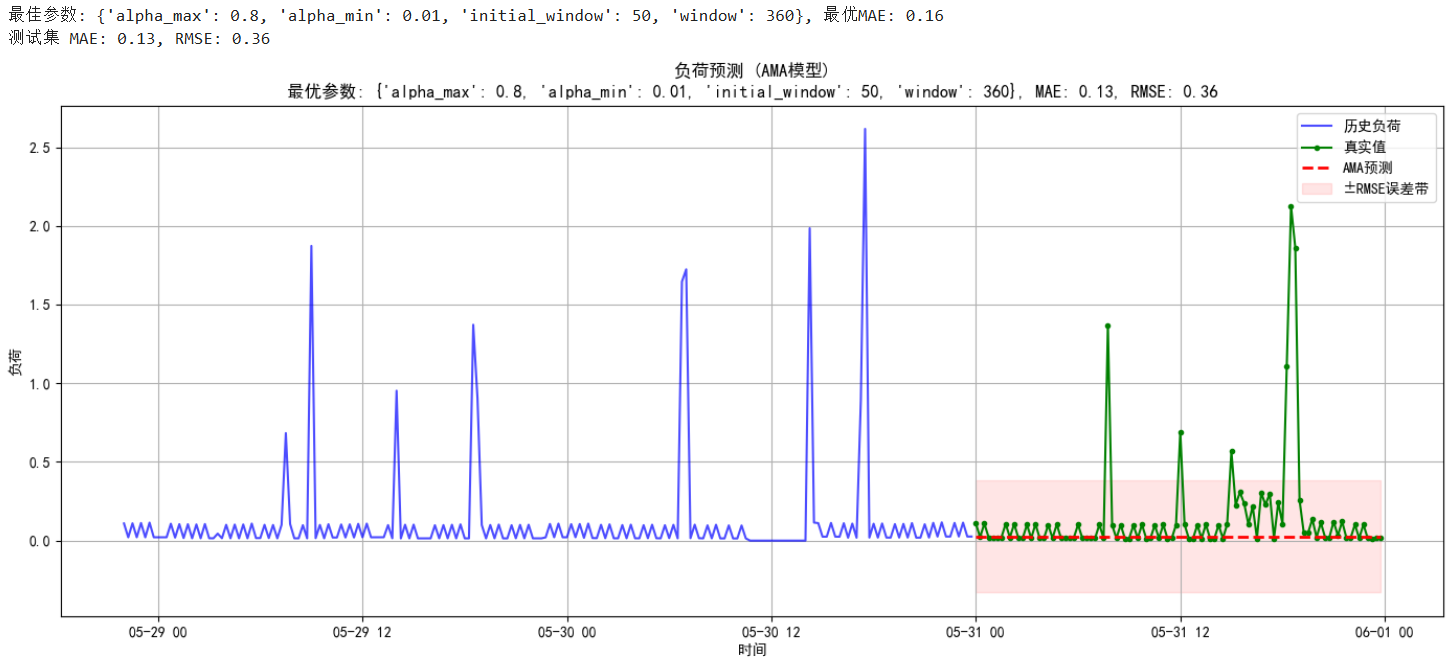
预测值与真实对比