边缘计算场景下的大模型落地:基于 Cherry Studio 的 DeepSeek-R1-0528 本地部署
前言
作为学生,我选择用 Cherry Studio 在本地调用 DeepSeek-R1-0528,完全是被它的实用性和 “性价比” 圈粉。最近在 GitHub 和 AI 社群里,大家都在热议 DeepSeek-R1-0528,尤其是它的数学解题和编程能力。像我在准备数学建模竞赛时,用它推导算法公式,居然能给出比参考答案更简洁的步骤;写 Python 爬虫作业,它甚至能直接帮我优化代码的运行效率,比我自己反复调试快多了。
但我不想把学习数据传到云端,毕竟论文思路、编程作业这些要是泄露,被判定为 “AI 代写” 就麻烦了。Cherry Studio 正好解决了这个痛点,装在我的旧笔记本电脑上都不卡,还能把 DeepSeek-R1-0528 稳稳运行起来。最方便的是,它整合了超多模型,平时写英语作文用翻译模型,期末复习用知识问答模型,切换起来超顺滑。
而且,通过本地部署,我还能把自己整理的错题集、笔记 “喂” 给模型,让它越来越懂我的学习薄弱点。现在它就像我专属的 AI 学习伙伴,既能帮我攻克难题,又不用担心隐私问题,这种安全感和高效学习体验,非常不错。
关于蓝耘api
这里我们调用使用到了蓝耘的api,有的同学就会有疑问了,蓝耘平台是啥,为什么会使用到蓝耘平台呢?我的回答是好用,非常好用。
Cherry Studio 通过集成蓝耘 API,能解锁一些本地部署难以实现的功能:
- 实时更新模型版本:蓝耘会第一时间同步 DeepSeek 官方的模型升级(比如后续可能推出的 R1-06XX 版本),无需我手动下载更新包,随时能用最新功能。
-
- 多模型融合调用:除了 DeepSeek-R1-0528,蓝耘 API 还支持其他大模型,如通义千问系列
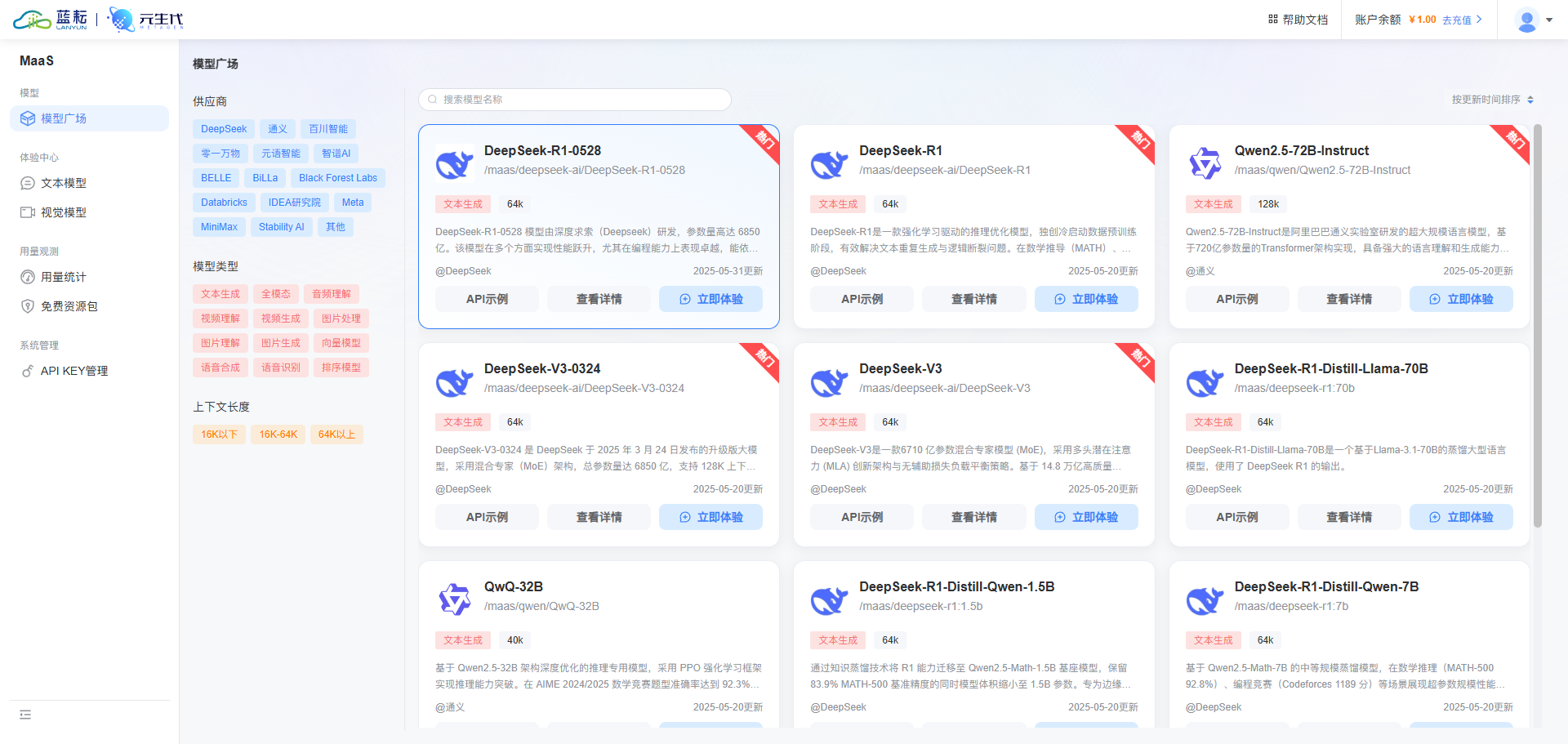
为助力开发者和用户使用,提供高额免费 token 资源包。如每位用户有 500 万 tokens 免费额度,像图中 DeepSeek - V3 资源包总额 5000000 token ,能在不额外付费情况下,尽情开展各类调用测试、开发应用等 。
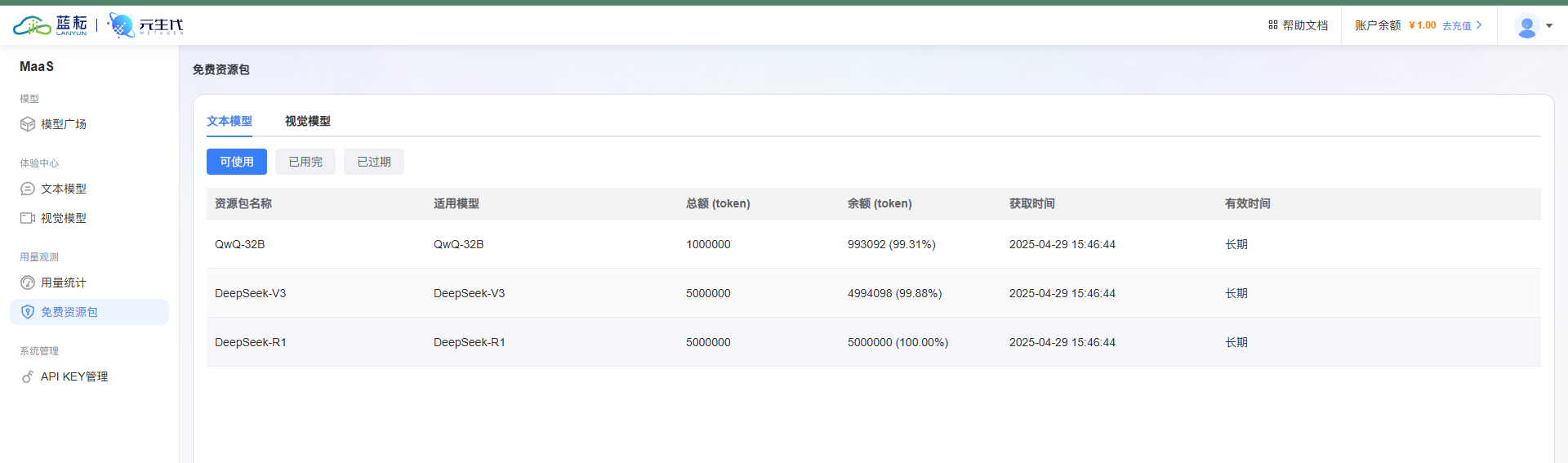
- 多模型融合调用:除了 DeepSeek-R1-0528,蓝耘 API 还支持其他大模型,如通义千问系列
涵盖文本、图像、音视频等多模态模型。如 DeepSeek 系列文生文模型,以及图像、视频生成相关模型,像用于视频生成的 I2V - 01、T2V - 01 等 ,满足多样化开发需求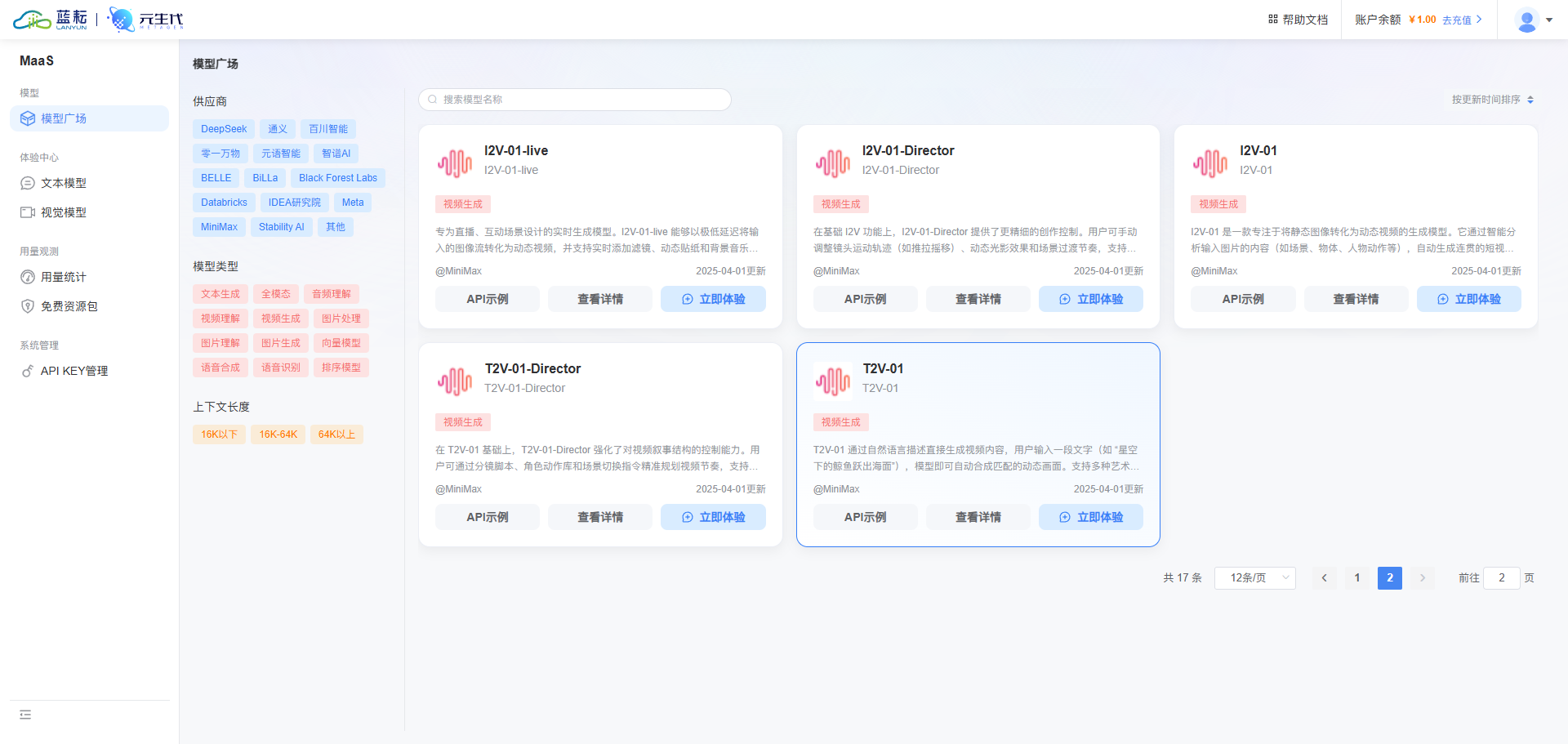
获取蓝耘智算平台接入api相关信息
首项我们需要先进行注册
点击链接进行注册
输入正确信息就可以进行登录操作了
注册好了之后,我们来到模型广场
挑选一款你喜欢的模型,我这里调用的就是最新的DeepSeek-R1-0528
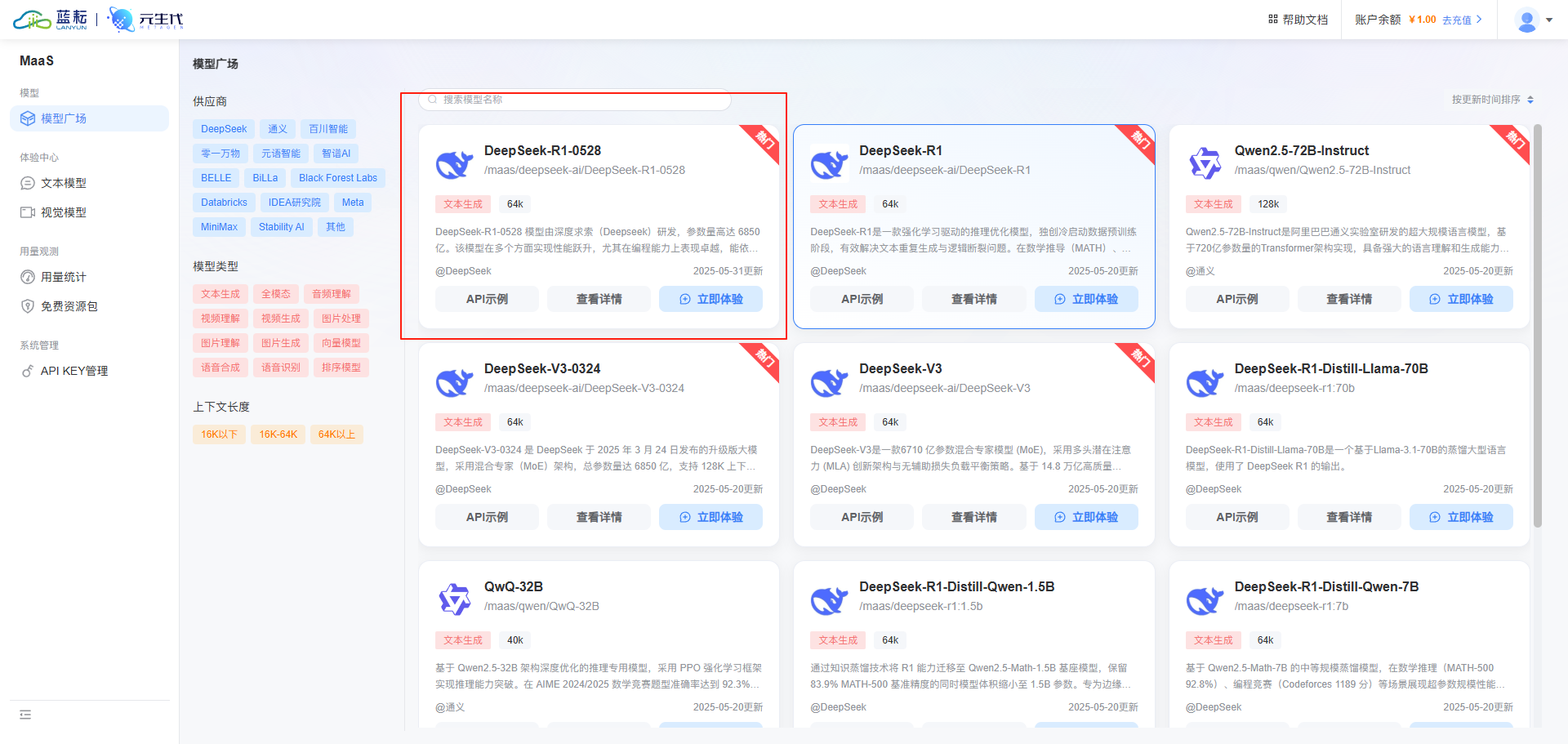
我们先点击将模型名称进行复制
/maas/deepseek-ai/DeepSeek-R1-0528
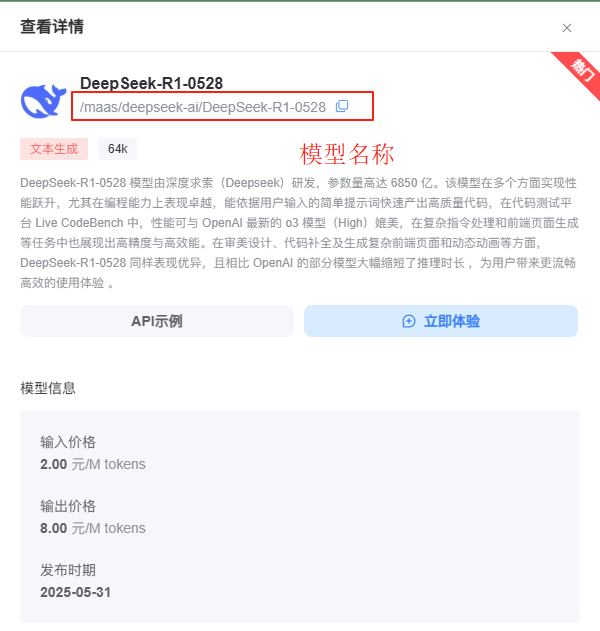
然后去申请api
点击创建API就行了
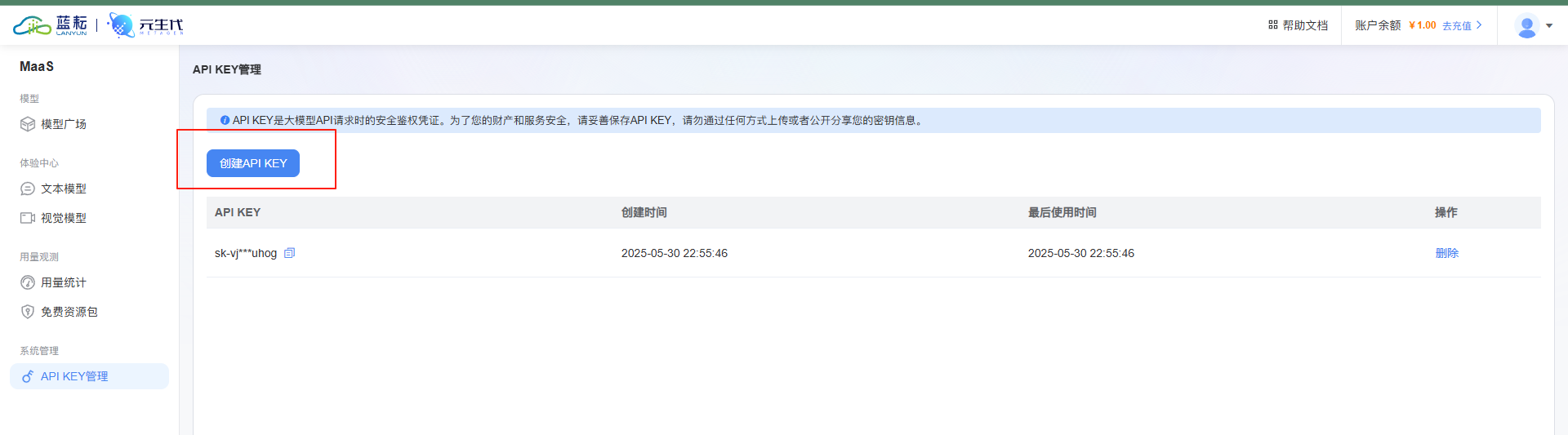
将api复制下来,需要获取的信息我们已经都搞定了,下面就是教大家如何使用Cherry Studio进行api链接
Cherry Studio的下载
我们点击Cherry Studio 官方网站 - 全能的AI助手进行本地应用的下载
登录上应用,一开始是下面这个样子的
点击左下角的小齿轮进行设置操作,我们就进入到模型服务的界面了,然后我们就进行蓝耘平台的添加操作就行了
点击添加
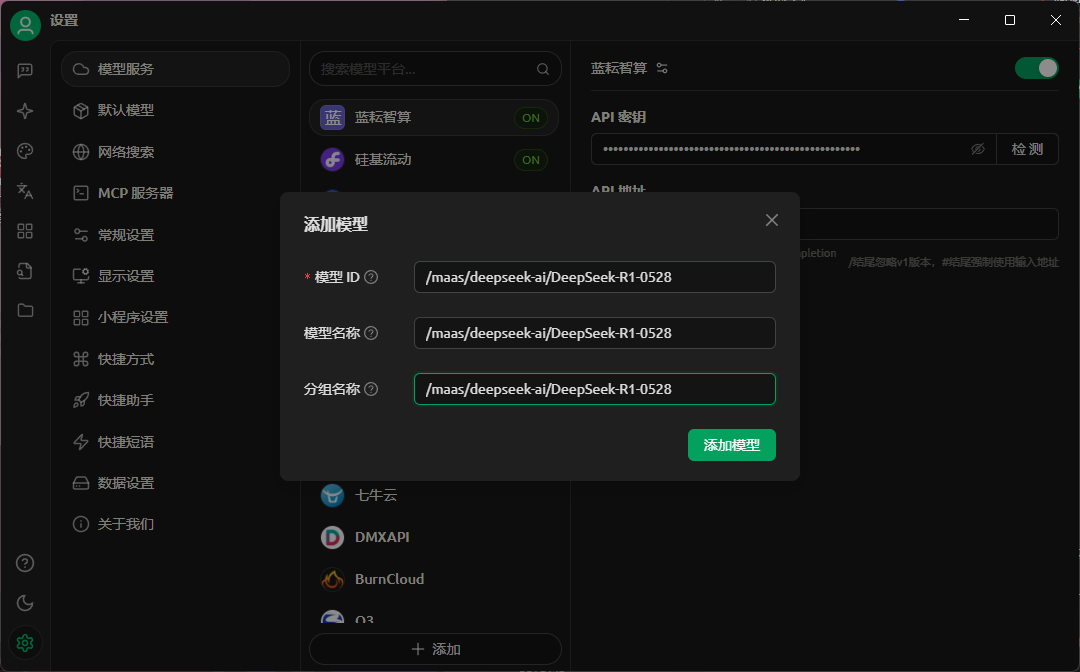
填写相关的信息
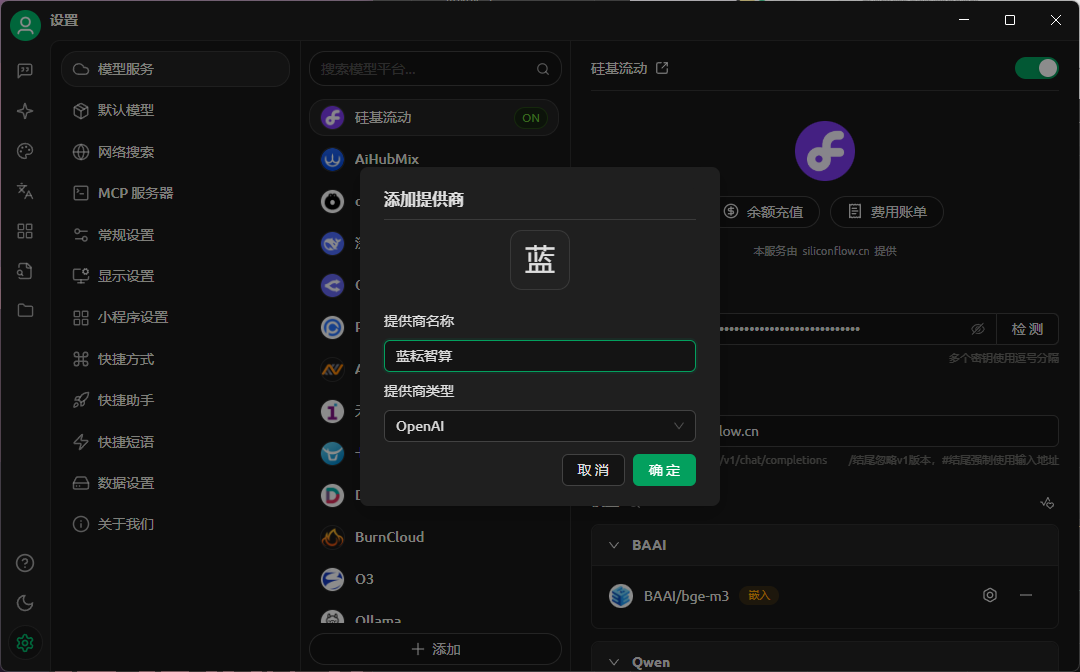
然后这里我们需要填写两个信息,一个是api一个是api访问地址
我们直接将刚刚创建的api填写到第一个空里面去
api地址的话我们就直接输入https://maas-api.lanyun.net就行了
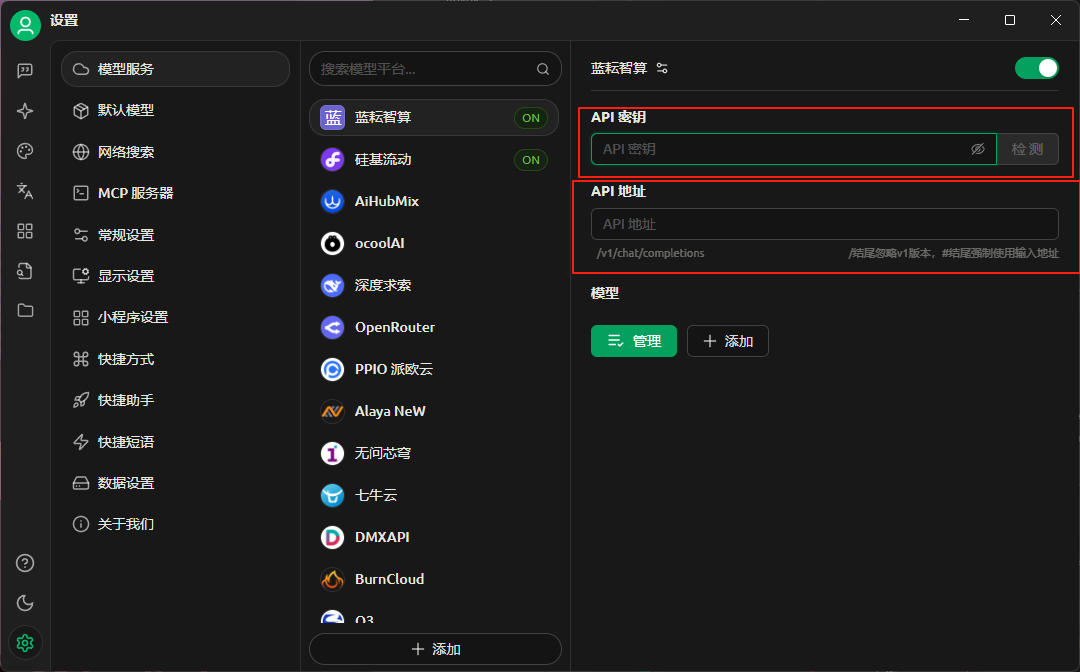
然后点击添加模型 /maas/deepseek-ai/DeepSeek-R1-0528
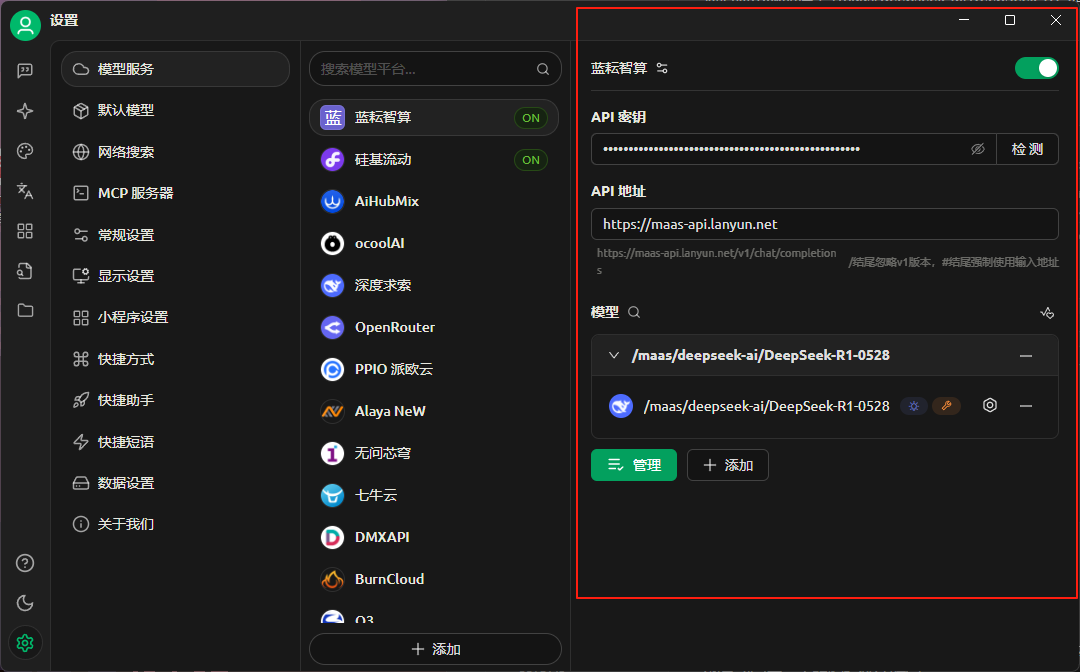
然后这里就可以显示的看到具体的信息了
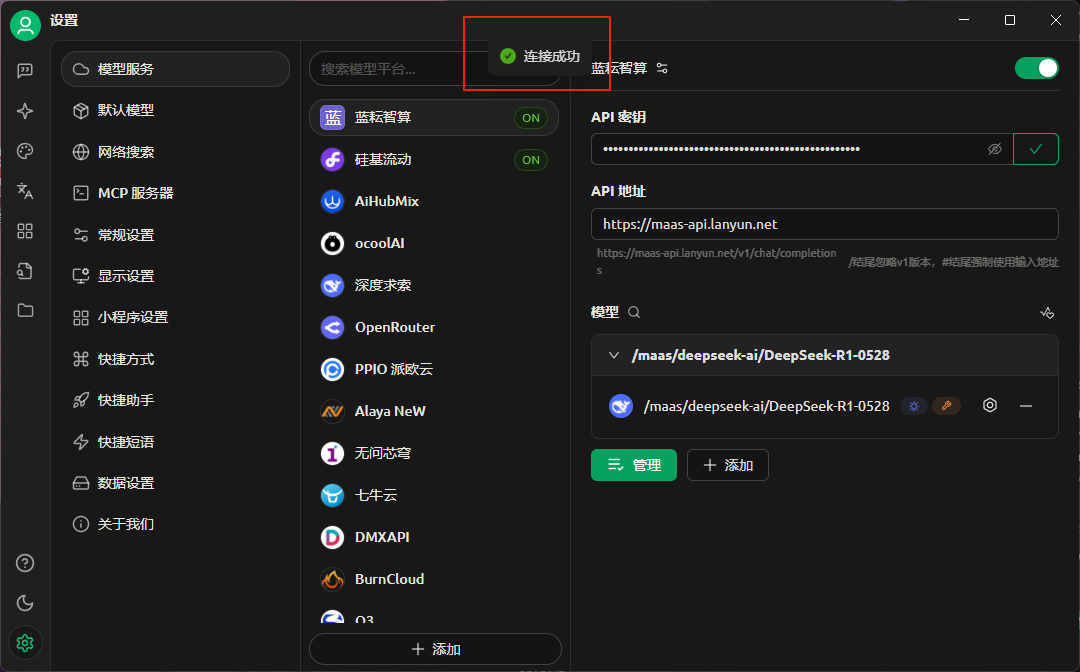
我们可以点击检测,看看是否能够成功调用
我这里显示连接成功
我们这里也是可以将其他的模型都添加进来的
然后我们回到主页,点击上方模型,选择我们的ai
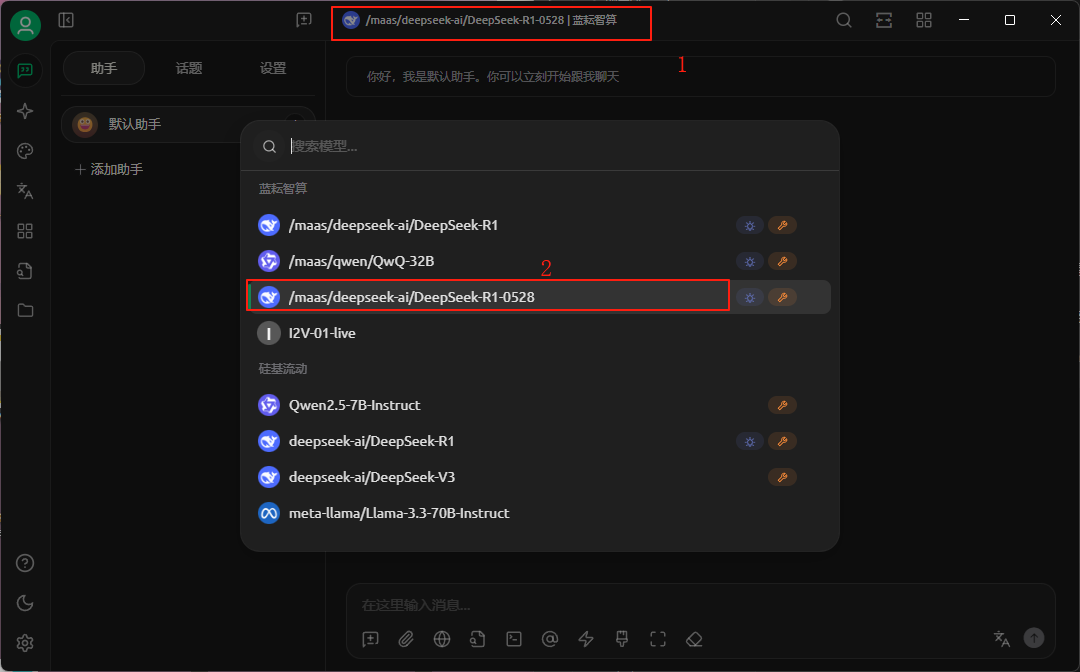
我们这里可以先试探性的询问下你是谁
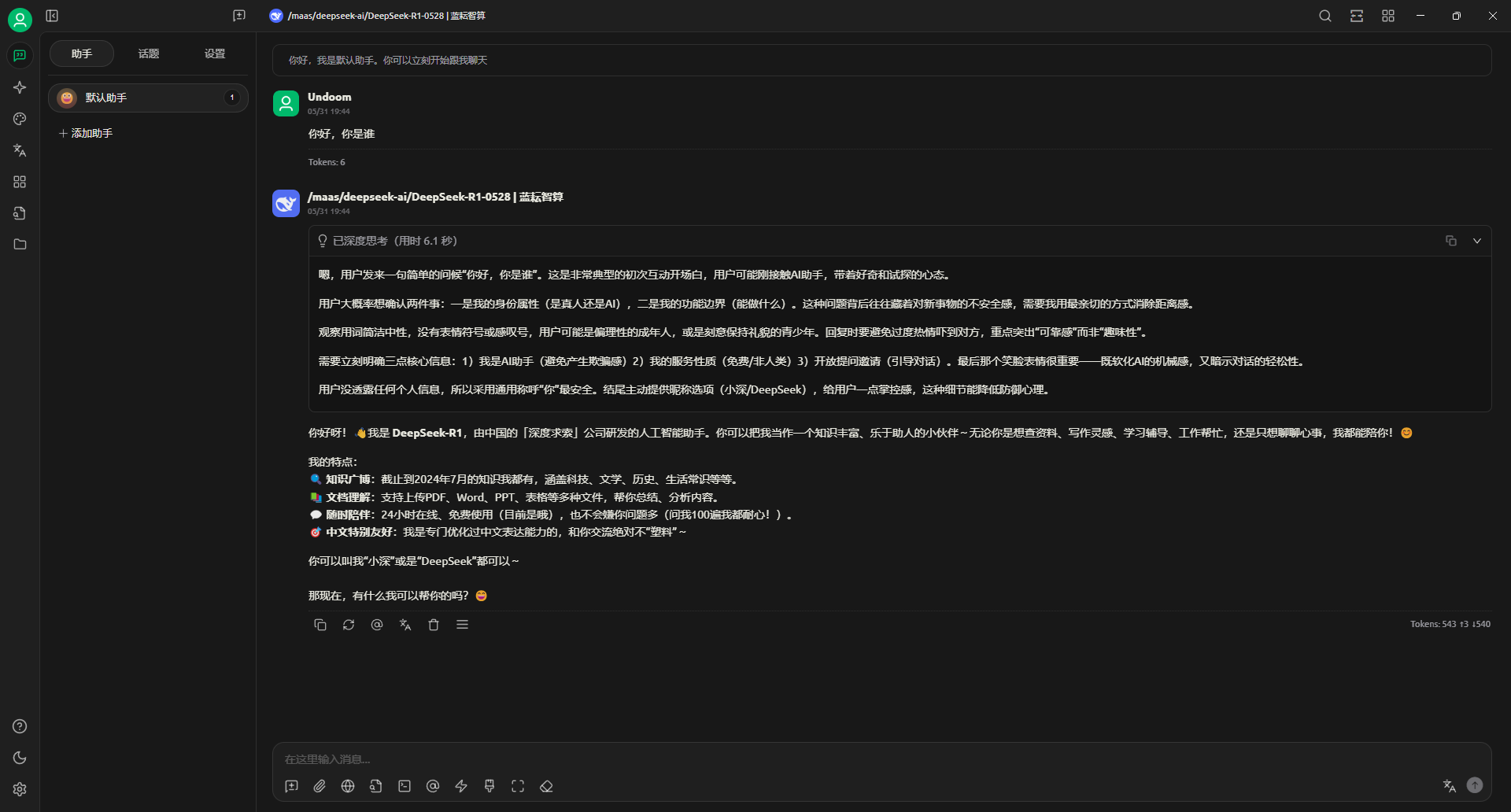
这里他的反应速度真的快,生成答案加上思考时间比原版本的R1快很多了
我接着询问你帮我生成一份对抗学习的代码
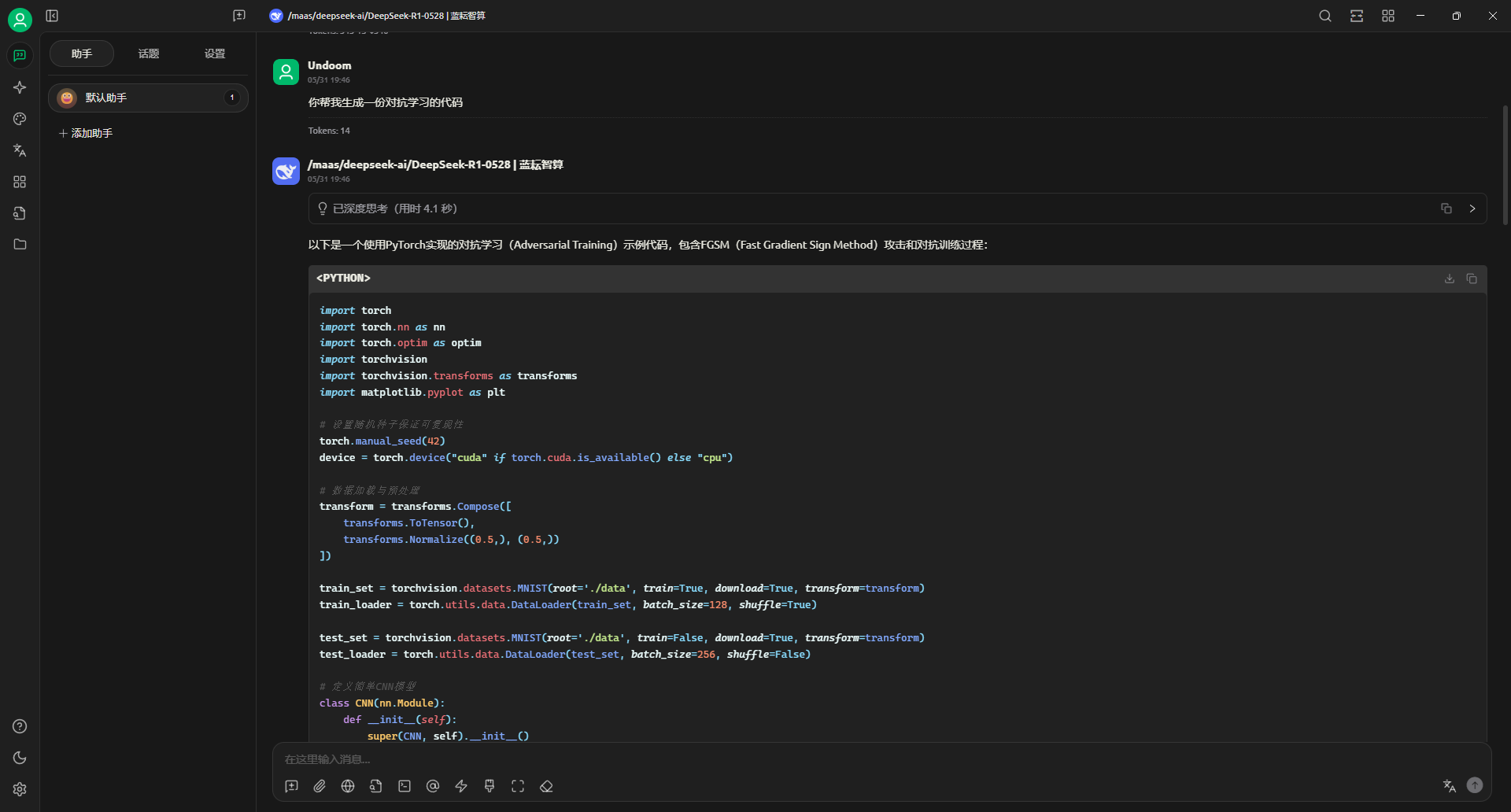
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt# 设置随机种子保证可复现性
torch.manual_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 数据加载与预处理
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))
])train_set = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=128, shuffle=True)test_set = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=256, shuffle=False)# 定义简单CNN模型
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.conv1 = nn.Conv2d(1, 32, 3, padding=1)self.conv2 = nn.Conv2d(32, 64, 3, padding=1)self.pool = nn.MaxPool2d(2, 2)self.fc1 = nn.Linear(64 * 7 * 7, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = self.pool(torch.relu(self.conv1(x)))x = self.pool(torch.relu(self.conv2(x)))x = x.view(-1, 64 * 7 * 7)x = torch.relu(self.fc1(x))x = self.fc2(x)return xmodel = CNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# FGSM攻击函数
def fgsm_attack(image, epsilon, data_grad):sign_data_grad = data_grad.sign()perturbed_image = image + epsilon * sign_data_gradperturbed_image = torch.clamp(perturbed_image, -1, 1) # 保持像素值在[-1,1]范围内return perturbed_image# 对抗训练函数
def adversarial_train(model, device, train_loader, optimizer, epoch, epsilon=0.3):model.train()total_loss = 0correct = 0for data, target in train_loader:data, target = data.to(device), target.to(device)data.requires_grad = True# 前向传播output = model(data)loss = criterion(output, target)# 反向传播获取梯度optimizer.zero_grad()loss.backward()data_grad = data.grad.data# 生成对抗样本perturbed_data = fgsm_attack(data, epsilon, data_grad)# 使用对抗样本重新训练optimizer.zero_grad()output_adv = model(perturbed_data)loss_adv = criterion(output_adv, target)loss_adv.backward()optimizer.step()total_loss += loss_adv.item()pred = output_adv.argmax(dim=1, keepdim=True)correct += pred.eq(target.view_as(pred)).sum().item()# 计算平均损失和准确率avg_loss = total_loss / len(train_loader.dataset)accuracy = 100. * correct / len(train_loader.dataset)print(f'Epoch: {epoch} | Train Loss: {avg_loss:.4f} | Accuracy: {accuracy:.2f}%')return avg_loss, accuracy# 测试函数(包含对抗样本测试)
def test(model, device, test_loader, epsilon=0.3):model.eval()test_loss = 0correct = 0adv_correct = 0for data, target in test_loader:data, target = data.to(device), target.to(device)# 正常测试output = model(data)test_loss += criterion(output, target).item()pred = output.argmax(dim=1, keepdim=True)correct += pred.eq(target.view_as(pred)).sum().item()# 生成对抗样本测试data.requires_grad = Trueoutput = model(data)loss = criterion(output, target)model.zero_grad()loss.backward()data_grad = data.grad.dataperturbed_data = fgsm_attack(data, epsilon, data_grad)# 在对抗样本上测试output_adv = model(perturbed_data)pred_adv = output_adv.argmax(dim=1, keepdim=True)adv_correct += pred_adv.eq(target.view_as(pred_adv)).sum().item()# 计算指标test_loss /= len(test_loader.dataset)accuracy = 100. * correct / len(test_loader.dataset)adv_accuracy = 100. * adv_correct / len(test_loader.dataset)print(f'Test set: Average loss: {test_loss:.4f}')print(f'Normal Accuracy: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%)')print(f'Adversarial Accuracy: {adv_correct}/{len(test_loader.dataset)} ({adv_accuracy:.2f}%)')return accuracy, adv_accuracy# 训练与测试
epochs = 10
train_losses = []
normal_accs = []
adv_accs = []for epoch in range(1, epochs + 1):print(f"\n--- Epoch {epoch} ---")loss, acc = adversarial_train(model, device, train_loader, optimizer, epoch)normal_acc, adv_acc = test(model, device, test_loader)train_losses.append(loss)normal_accs.append(normal_acc)adv_accs.append(adv_acc)# 绘制结果
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='Training Loss')
plt.title('Training Loss')
plt.xlabel('Epochs')
plt.legend()plt.subplot(1, 2, 2)
plt.plot(normal_accs, label='Normal Accuracy')
plt.plot(adv_accs, label='Adversarial Accuracy')
plt.title('Test Accuracy')
plt.xlabel('Epochs')
plt.legend()
plt.tight_layout()
plt.savefig('results.png')
plt.show()我们可以调用其他的模型让其他的模型分析下这个代码的专业性
我们这里就使用到了通义千问了
他这里也会进行思考操作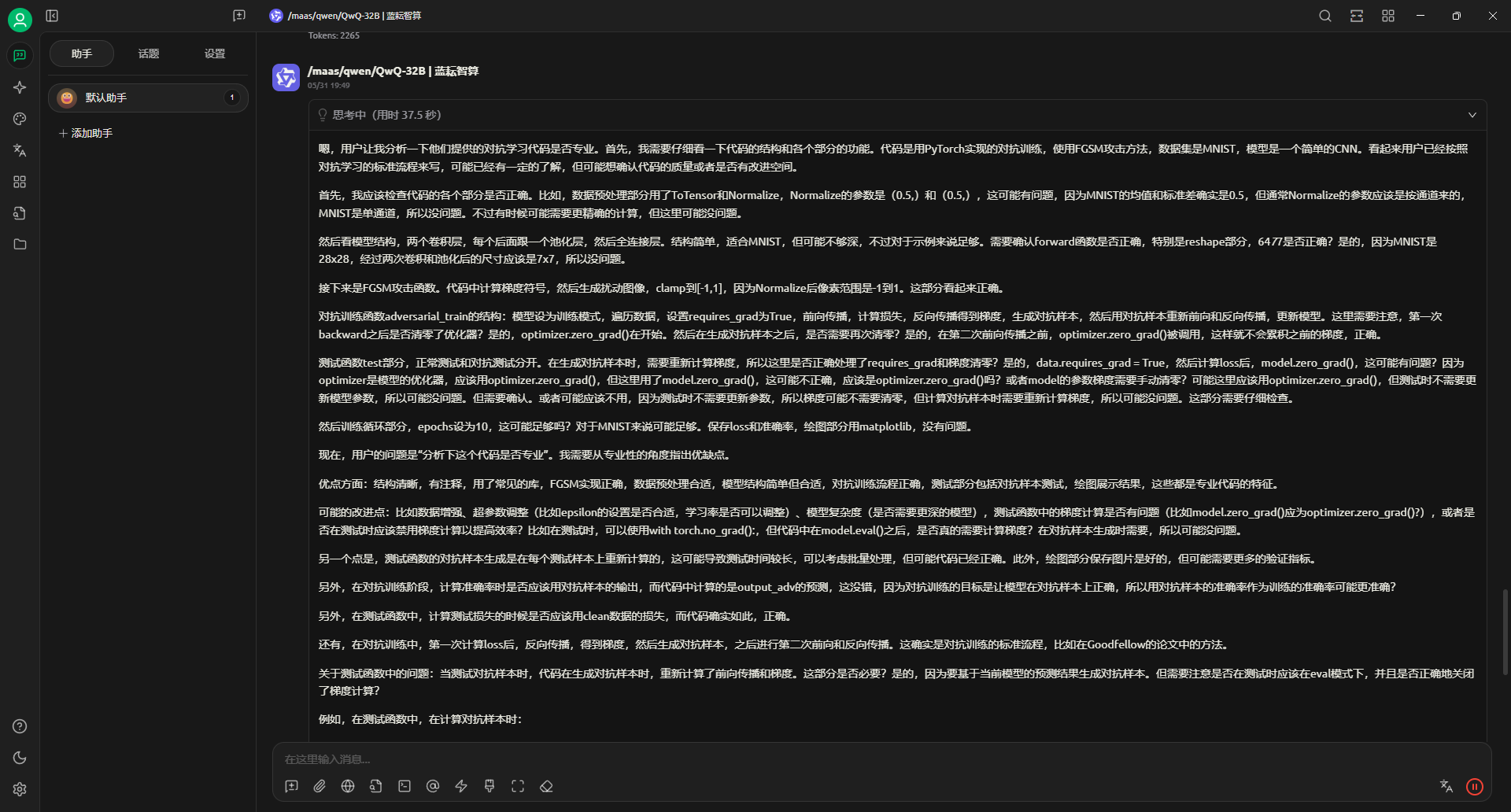

这个总结也是可以的。到这里我们的实验就结束了,你如果也想体验下deepseek的最新模型,你不妨去试试呢,确实挺不错的。
总结
在速度上,Cherry Studio 具备轻量级特性,运行流畅,搭配蓝耘 API 优化的底层架构、强劲算力及深度算法,能快速响应指令。无论是处理复杂文本生成,还是进行大规模数据推理,都能高效完成,大幅缩短等待时间。
如果你也感兴趣的话,不妨来试试呢下方链接注册就ok了
https://cloud.lanyun.net/#/registerPage?promoterCode=5663b8b127