Nat Rev Genet | 如果DNA序列能“说话”?深度学习S2E(序列2表达)模型正在听懂基因组的调控秘密!

–https://doi.org/10.1038/s41576-025-00841-2
Predicting gene expression from DNA sequence using deep learning models
留意更多内容:请关注VX–组学之心
研究团队和单位
Jeroen de Ridder–Oncode Institute, Utrecht, The Netherlands

Bas van Steensel–Oncode Institute, Utrecht, The Netherlands

综述简介
核心挑战
基因转录调控: 基因转录受启动子和增强子等DNA元件调控,其活性又受**转录因子(TFs)**控制。
高度复杂的组合逻辑: 调控网络涉及TFs和调控元件之间复杂的组合作用,使得仅从DNA序列预测基因活性的计算模型构建异常困难。
传统模型局限: 传统的机器学习方法在建模基因表达方面预测能力有限,即使结合了基因组3D折叠算法也未能完全克服,例如以下两篇文献提到的:
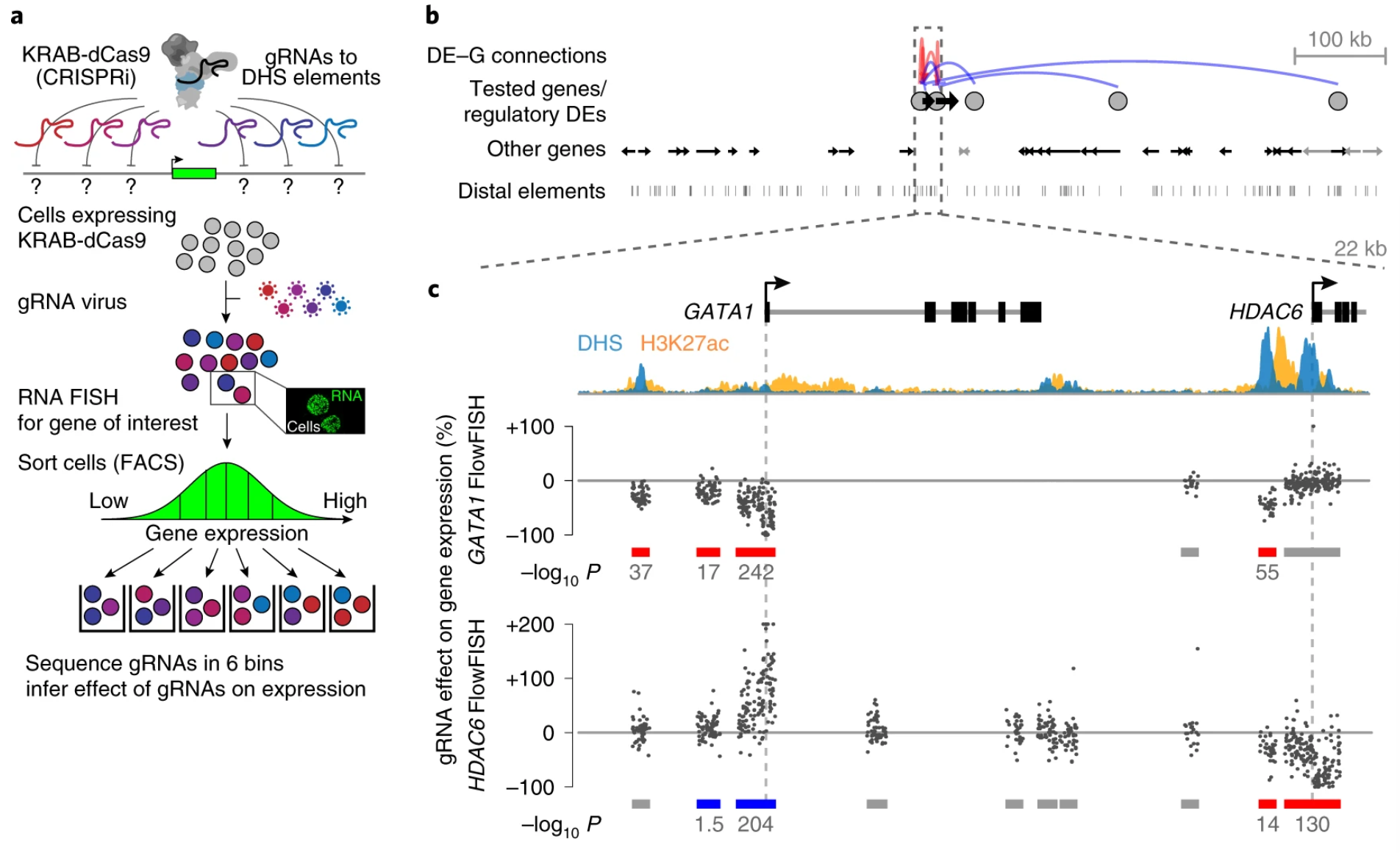
Activity-by-contact model of enhancer–promoter regulation from thousands of CRISPR perturbations. Nat Genet
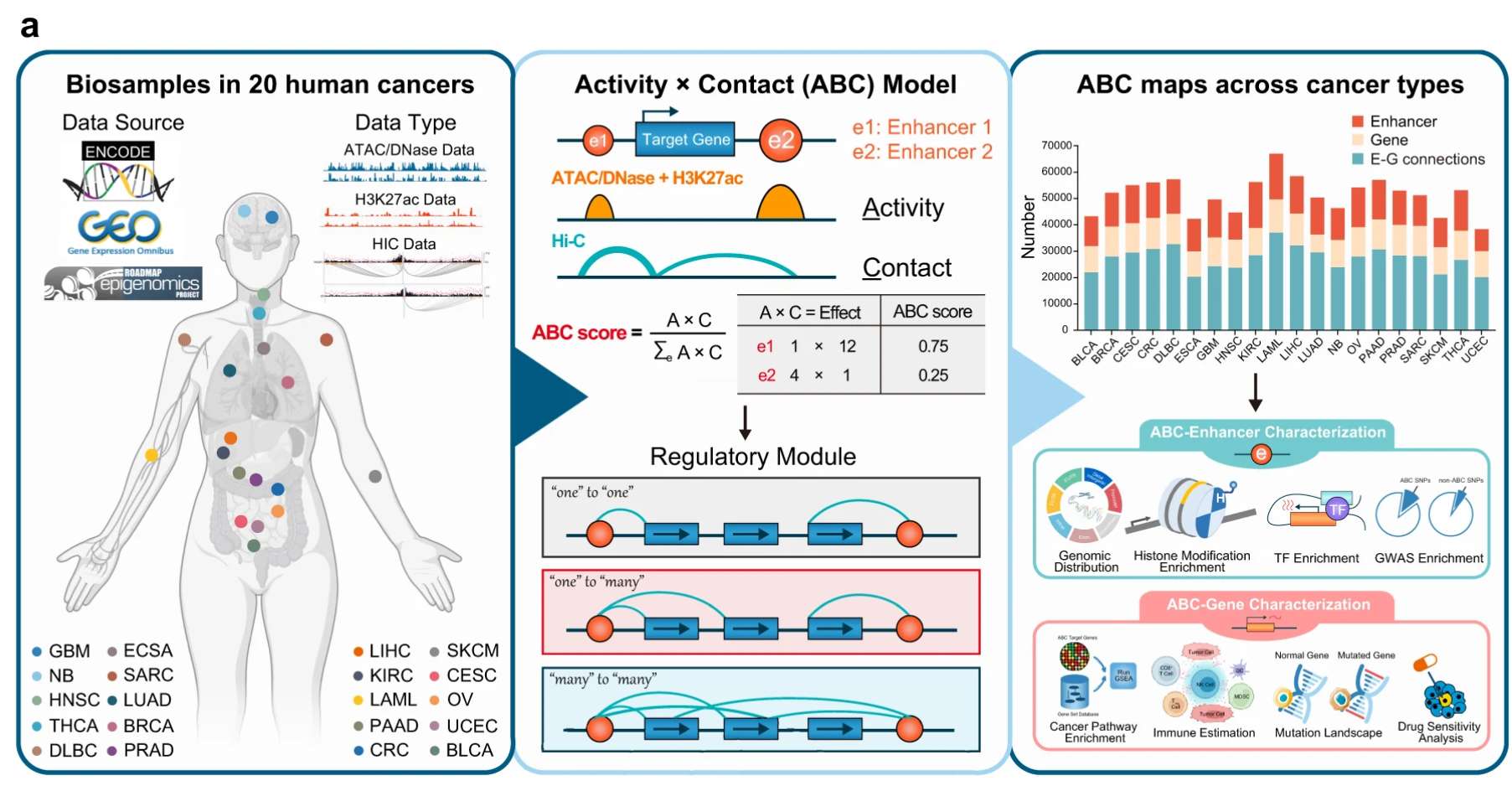
Genome-wide enhancer-gene regulatory maps link causal variants to target genes underlying human cancer risk. Nat Commun
深度学习的突破
S2E(sequence-to expression,序列到表达)模型: 深度学习的最新进展,特别是序列到表达(S2E)模型,能够仅从DNA序列预测基因表达水平,极大地推动了该领域的发展。
这些突破得益于表观基因组图谱和高通量基因组数据的应用。S2E模型能以惊人的准确性捕捉调控“语法”,并能外推到以前未见过的序列:
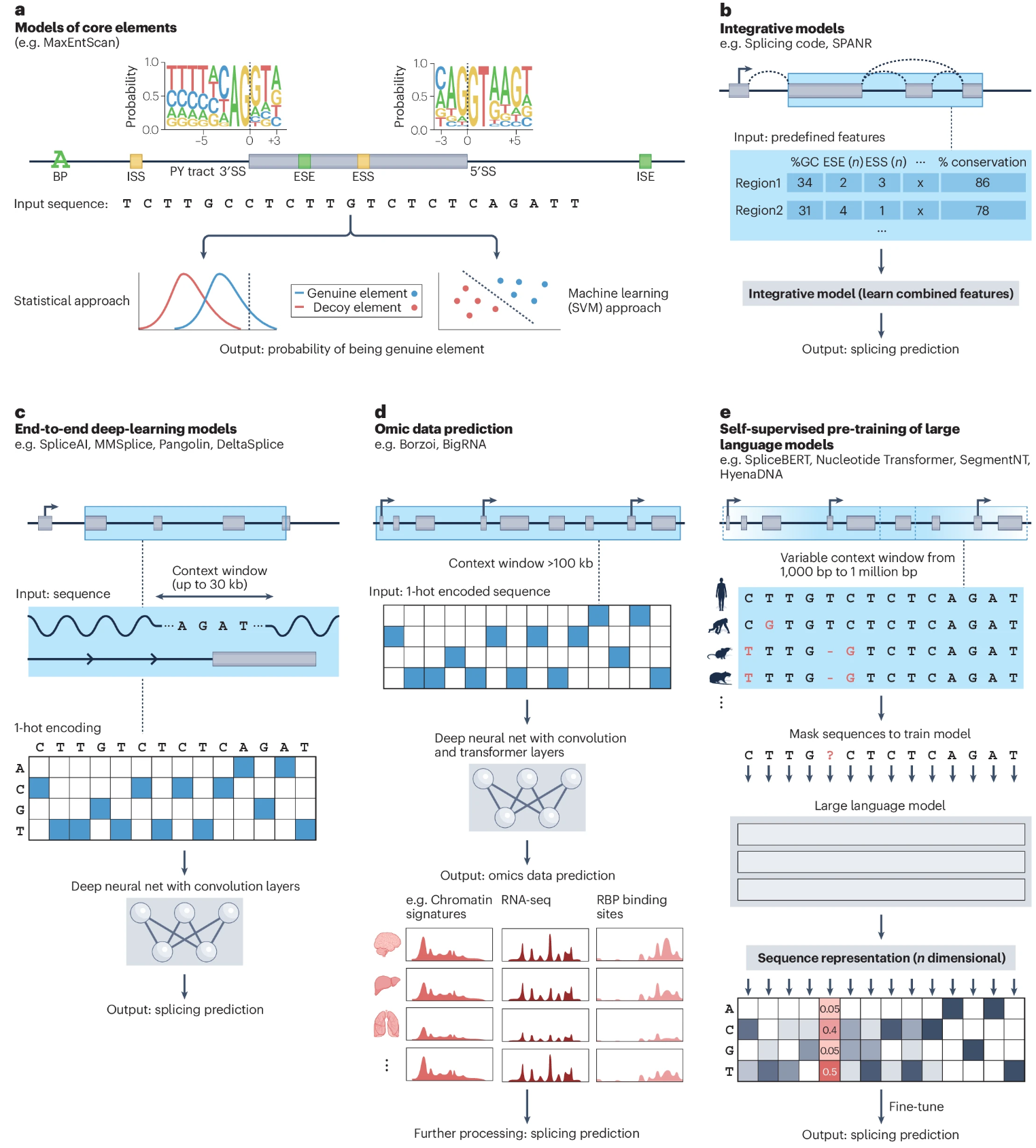
From computational models of the splicing code to regulatory mechanisms and therapeutic implications. Nat Rev Genet
早期模型构建序列motif来描述单个核心剪接元件的共识序列,例如剪接位点 (SS) 以及内含子和/或外显子增强子和沉默子。构建统计和机器学习模型来输出新序列作为核心剪接元件的概率。5′SS 和 3′SS 的序列标识由人类 hg38 RefSeq 注释生成。
随着我们对剪接机制理解的不断深入,后来选择的特征是从序列中提取出来的,并用于训练整合模型来预测剪接结果。
随着深度学习的出现,模型可以直接从原始序列输入中联合学习特征。但实际上使用最多 30 kb 的较小窗口,分辨率过大。
具有卷积层和 Transformer 层的监督模型,可生成多模态全基因组数据。这些模型使用更大的序列背景,可以预测包括 RNA 测序覆盖率在内的全基因组数据,这些数据可进一步处理以评估剪接。
通过学习如何重建多个物种中部分掩蔽的基因组序列,自监督掩蔽语言模型以非常通用和灵活的方式捕获进化上保守的序列元素及其功能背景。大型语言模型获得的信息丰富的数值表示可用于剪接预测任务。
深度学习模型的潜力与应用
-
预测非编码变异影响: 准确预测DNA序列变异(特别是非编码变异)对基因活性的影响。
-
揭示分子机制: 深入揭示基因调控的详细分子机制和序列语法。
-
设计合成调控元件: 为生物技术和基因治疗设计合成调控元件。
综述的重点
专注S2E模型与转录调控:与其他更广泛的综述不同,本文主要关注S2E模型及其在转录调控方面的应用。
将详细讨论深度学习建模的基本原理、用于训练基因表达模型的多样化数据类型、模型验证方法,以及各种方法的优缺点。
强调基于深度学习的S2E模型不再是“黑箱”,可以通过查询来揭示潜在的调控语法。
1.深度学习在基因调控中的应用
1.1 DL模型的原理与优势
处理长基因组序列
传统机器学习依赖预提取的DNA序列特征(如k-mer计数),但缺乏关键的位置信息,例如转录因子结合位点(TFBs)之间的距离。
深度学习通过多层操作直接处理长基因组序列,这种端到端的方法使DL模型能够捕获基因组序列数据中复杂、分层且非线性的模式,从而在序列到表达(S2E)建模中取得突破。
S2E模型仅以DNA序列作为输入,能预测多种转录活性测量值,包括直接预测基因表达水平测量(RNA-seq)或替代指标(如表观基因组图谱数据,如ChIP-seq、ATAC-seq)。模型通过调整参数来最小化预测与实验测量值之间的差异,这需要大量输入数据和数百万个参数拟合。
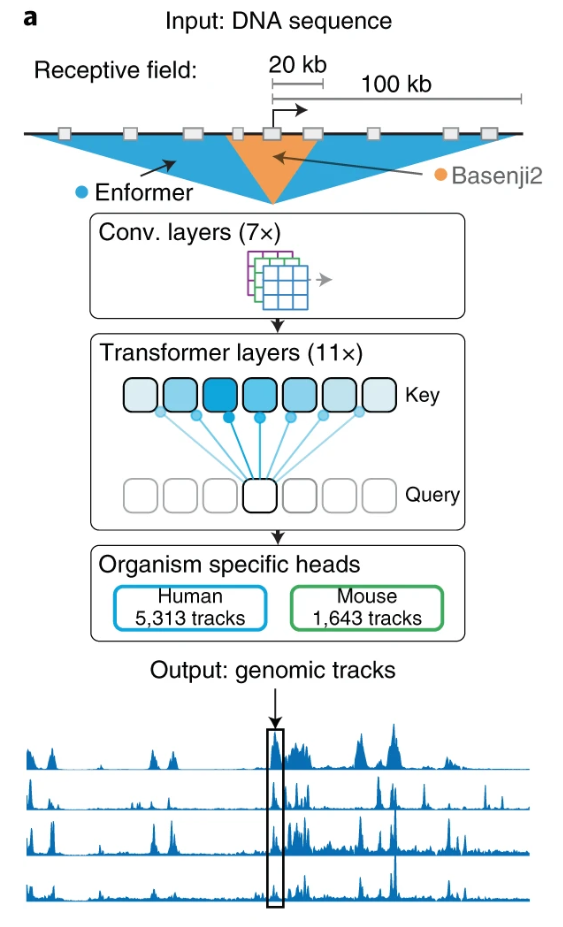
Effective gene expression prediction from sequence by integrating long-range interactions. Nat Methods
如何训练和内部评估模型
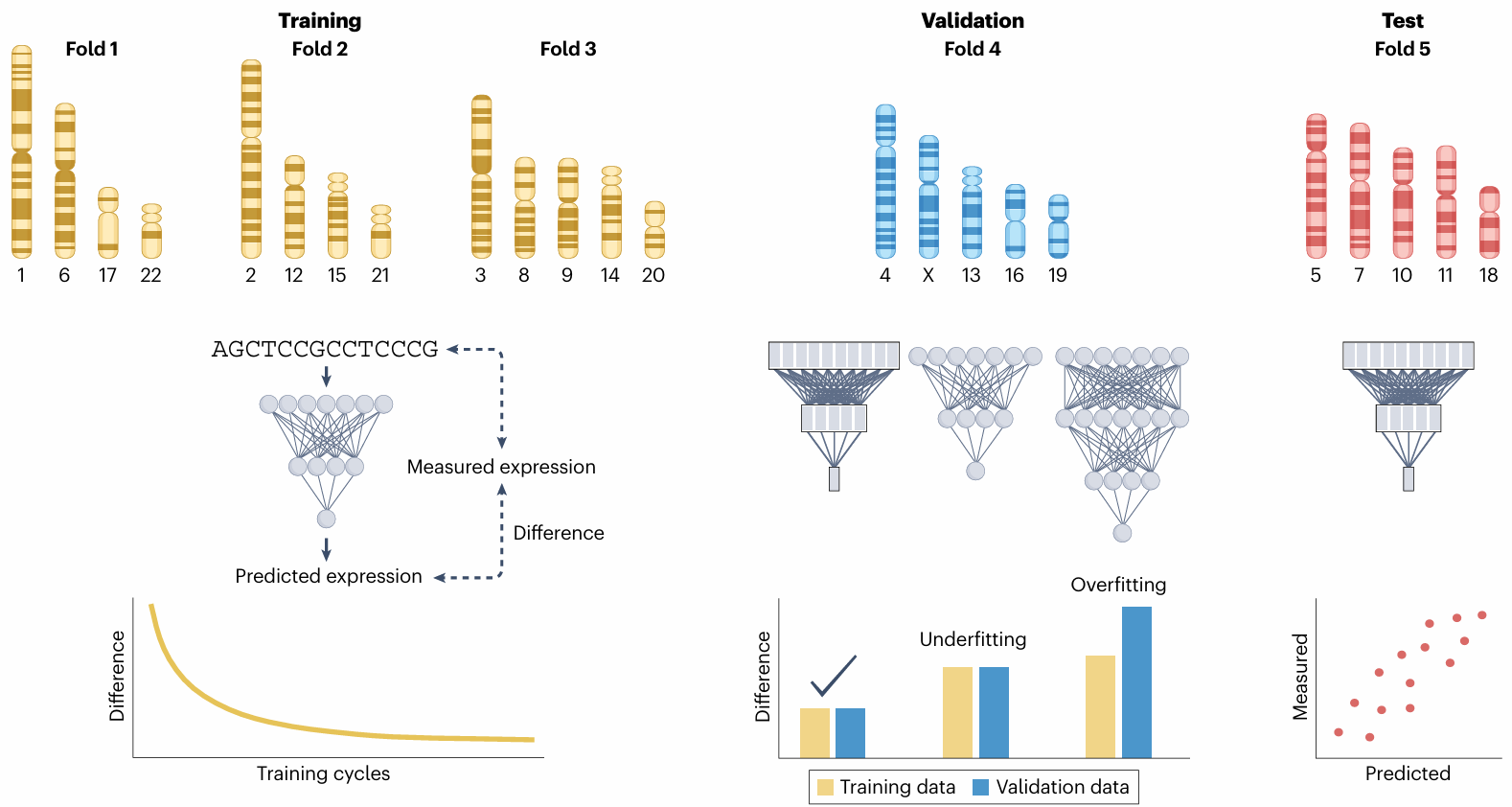
模型训练的核心原理
优化参数: 训练深度学习模型旨在优化其内部参数(权重),以使模型预测的输出与实际的实验测量值数据高度匹配。
损失函数: 优化过程由损失函数引导,量化模型预测值与实验测量值之间的差异。损失函数值越小,模型性能越好。
反向传播: 通过反向传播过程最小化损失函数。这涉及计算损失函数相对于网络权重的梯度,并据此调整参数,以逐步减少预测误差。
避免过拟合与数据划分
过拟合风险: 模型训练中常见挑战是过拟合,即模型过度记忆训练数据中的噪声和特定模式,而非学习普遍的预测规律,导致在未知数据上表现不佳。
标准数据划分: 为避免过拟合,原始数据集通常划分为至少三个不重叠的序列:
-
训练集: 用于学习模型的参数。
-
验证集: 用于在训练过程中评估模型性能,及时发现并阻止过拟合(当模型在训练集上表现优于验证集时)。此阶段也用于选择最佳的超参数(如模型架构或模型大小)。
-
测试集: 在模型参数和超参数确定后,用于对最终模型在未知数据上的性能进行无偏估计。
-
交叉验证: 当训练数据有限时,常使用交叉验证。数据集被分成 k 个部分,模型会训练 k 次,每次使用不同的部分作为验证集,其余作为训练集。
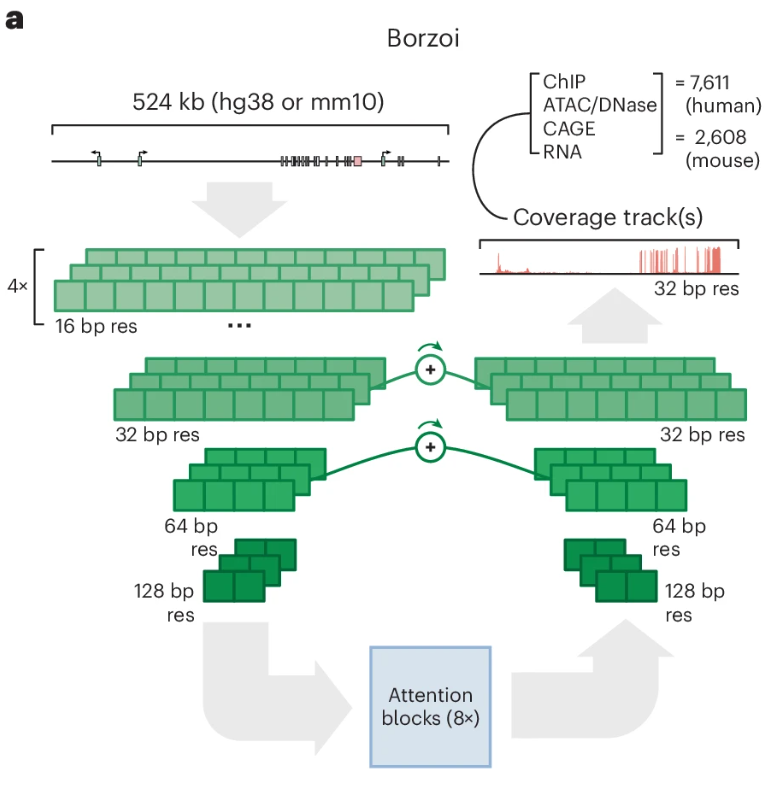
Predicting RNA-seq coverage from DNA sequence as a unifying model of gene regulation. Nat Genet
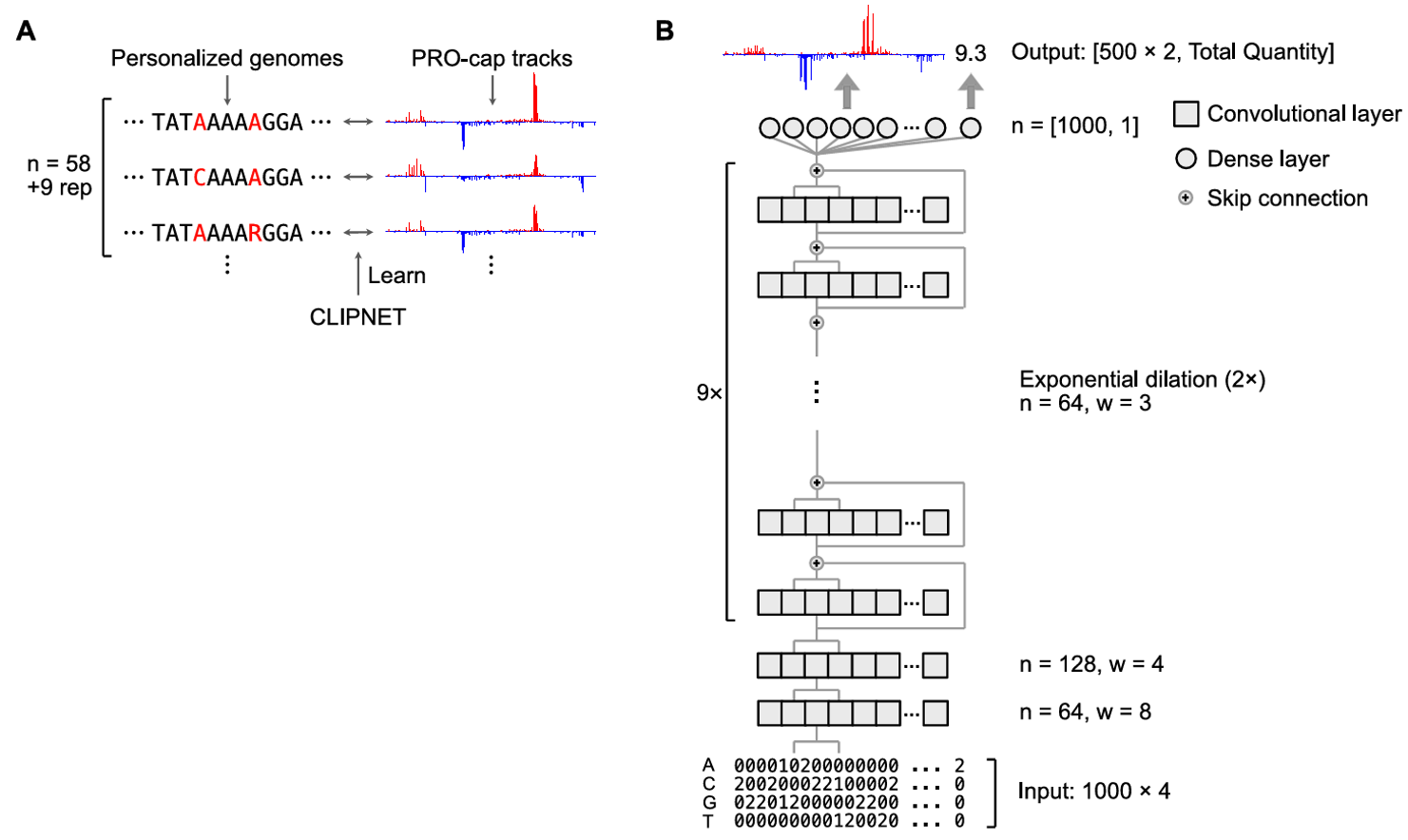
Dissection of core promoter syntax through single nucleotide resolution modeling of transcription initiation. bioRxiv
数据泄漏与同源性考量
在创建数据折叠时,必须确保不同折叠中的序列不与相同的基因组区域重叠,以避免数据泄漏。数据泄漏会导致模型性能的人为高估,因为它实际上是在重复学习已知信息,而非真正的泛化。
在序列到表达模型中,常见做法是将来自同一染色体的所有序列分组到同一折叠中,以防止训练、验证或测试折叠之间的数据泄漏。
有些模型会考虑同源性,将同源序列放在相同的折叠中。