高并发内存池------内存释放
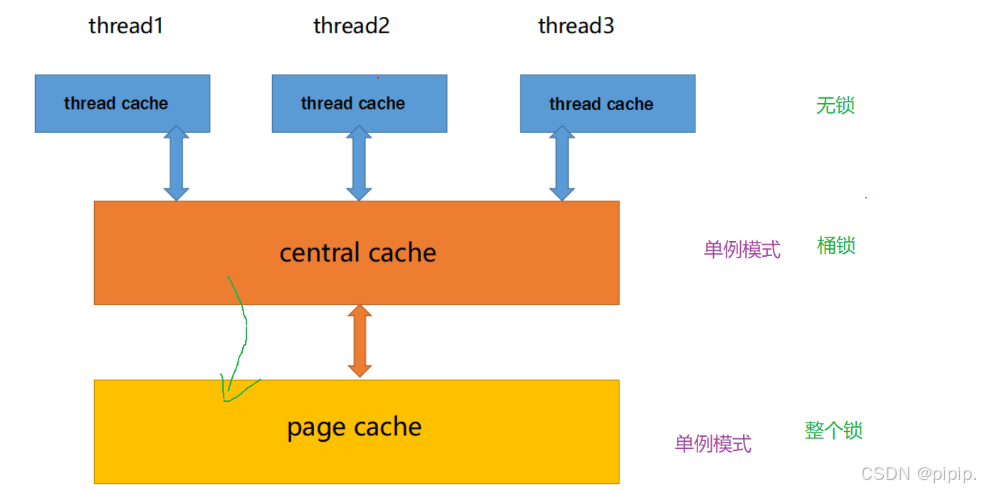
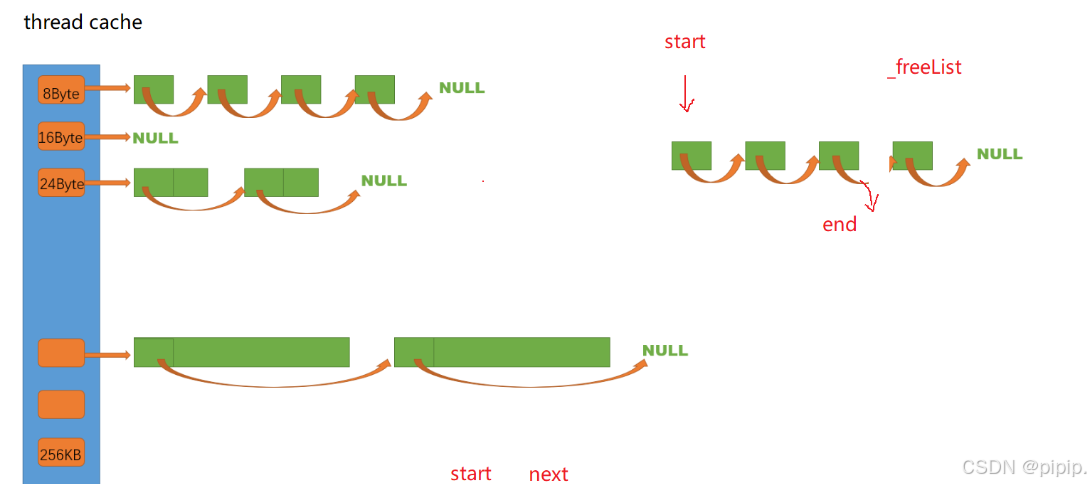
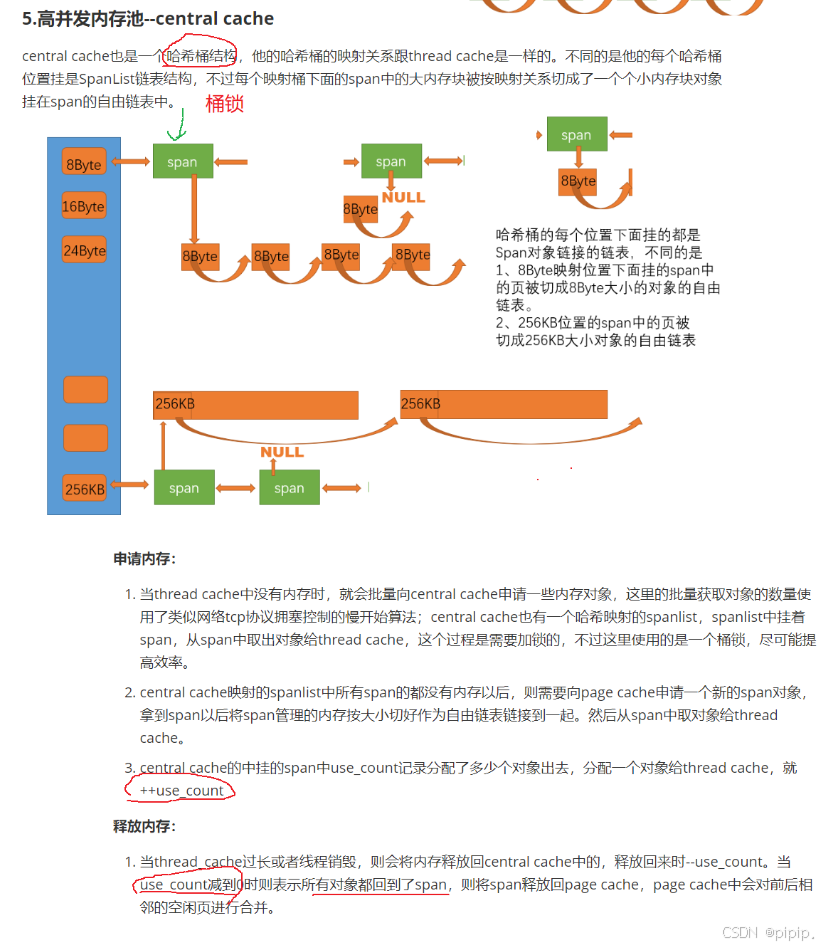
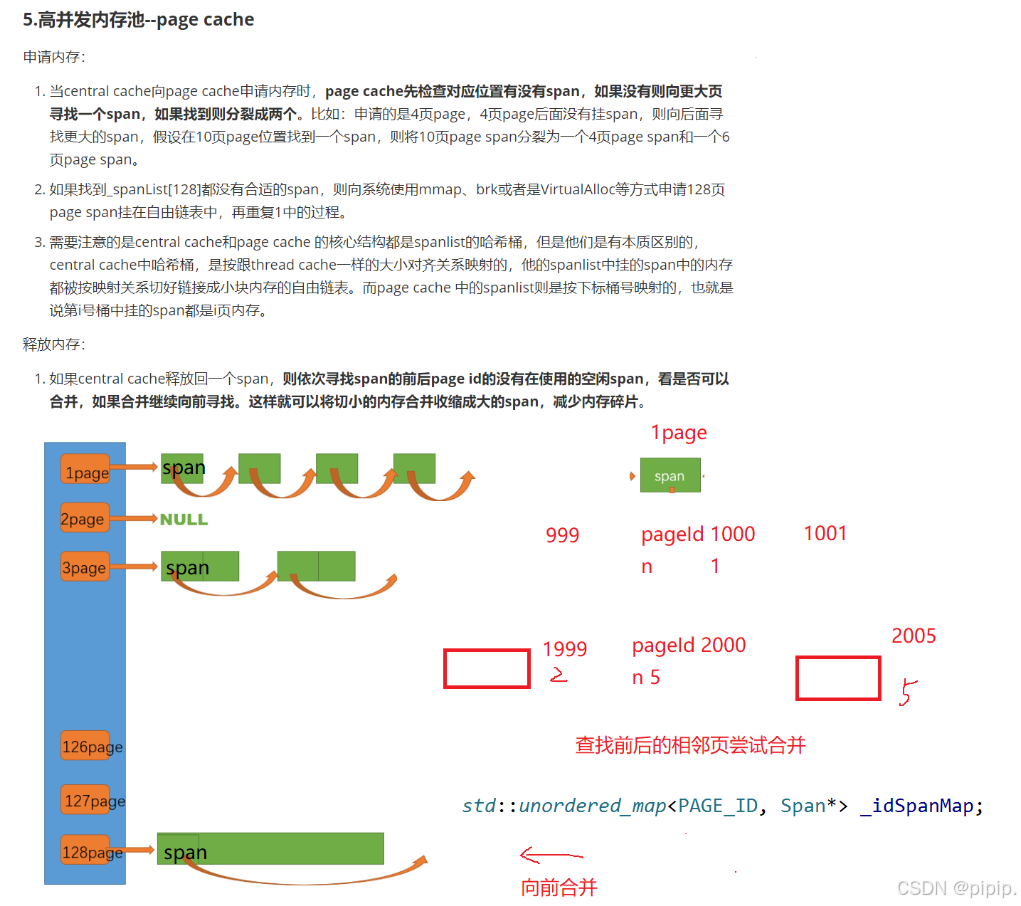
一、将一定数量的对象释放到span跨度
// 将一定数量的对象释放到span跨度void ReleaseListToSpans(void *start, size_t size){size_t index = Sizeclass::Index(size);_spanLists[index]._mtx.lock();while (start){void *next = NextObj(start);Span *span = PageCache::GetInstance()->MapObjectToSpan(start);NextObj(start) = span->_freeList;span->_freeList = start;span->_useCount--;// 说明span切分出去的小块内存都回来了// 这个span就可以再回收给pagecache,pagecache可以再尝试进行前后页的合并、if (span->_useCount == 0){_spanLists[index].Erase(span);span->_freeList = nullptr;span->_next = nullptr;span->_prev = nullptr;// 释放span给pagecache时,使用pagecache的锁就好了// 解掉桶锁_spanLists[index]._mtx.unlock();PageCache::GetInstance()->_pageMtx.lock();PageCache::GetInstance()->ReleaseSpanToPageCache(span);PageCache::GetInstance()->_pageMtx.unlock();_spanLists[index]._mtx.lock();}start = next;}_spanLists[index]._mtx.unlock();} 从代码来看,ReleaseListToSpans 函数的功能是将一定数量的对象释放到 Span 中,并且在 Span 的使用计数为 0 时,将 Span 释放回 PageCache。这个函数涉及多线程同步(通过锁)和资源管理。以下是对代码的分析和一些需要注意的地方:
1. 代码分析
1.1 锁的使用
-
_spanLists[index]._mtx.lock()和_spanLists[index]._mtx.unlock()用于保护_spanLists[index]的操作,确保线程安全。 -
PageCache::GetInstance()->_pageMtx.lock()和PageCache::GetInstance()->_pageMtx.unlock()用于保护PageCache的操作,确保线程安全。
1.2 对象释放逻辑
-
遍历对象链表,将每个对象加入到对应的
Span的_freeList中。 -
每次释放一个对象时,
span->_useCount减 1。 -
如果
span->_useCount为 0,说明该Span的所有对象都已释放,可以将Span释放回PageCache。
1.3 锁的嵌套
-
在释放
Span时,先解锁_spanLists[index]._mtx,然后加锁PageCache::GetInstance()->_pageMtx,最后再次加锁_spanLists[index]._mtx。 -
这种锁的嵌套需要特别小心,否则可能导致死锁或竞态条件。
2. 代码优化和改进建议
2.1 锁的优化
-
减少锁的持有时间:尽量减少锁的持有时间,以提高性能。
-
避免锁的嵌套:如果可能,尽量避免锁的嵌套。如果必须嵌套,确保嵌套顺序一致,避免死锁。
2.2 错误处理
-
空指针检查:在访问指针(如
span)之前,确保指针不为空。 -
异常安全:确保在发生异常时,锁能够正确释放。
2.3 代码可读性
-
注释:增加注释,解释每个步骤的目的。
-
函数拆分:将复杂的逻辑拆分成多个函数,提高代码可读性。
二、 释放对象时,链表过长时,回收内存回到中心缓存
// 释放对象时,链表过长时,回收内存回到中心缓存void ListTooLong(FreeList& list, size_t size){void* start = nullptr;void* end = nullptr;list.PopRange(start, end, list.MaxSize());CentralCache::GetInstance()->ReleaseListToSpans(start, size);}三、释放空闲span到pagecache,并合并相邻的span
//释放空闲span到pagecache,并合并相邻的spanvoid ReleaseSpanToPageCache(Span* span){//对span前后的页尝试进行合并,缓解内存碎片的问题while (1){PAGE_ID prevId = span->_pageId - 1;auto ret = _idSpanMap.find(prevId);//前面的页号没有,不合并if(ret == _idSpanMap.end()){break;}//前面相邻页的span在使用,不合并了Span* prevSpan = ret->second;if(prevSpan->_isUse == true){break;}//合并后超过128页的span没办法管理,不合并if(prevSpan->_n + span->_n > NPAGES - 1){break;}span->_pageId = prevSpan ->_pageId;span->_n += prevSpan->_n;_spanLists[prevSpan->_n].Erase(prevSpan);delete prevSpan;}//向后合并while(1){PAGE_ID nextId = span->_pageId + span->_n;auto ret = _idSpanMap.find(nextId);if(ret == _idSpanMap.end()){break;}Span* nextSpan = ret->second;if(nextSpan->_isUse == true){break;}if(nextSpan->_n + span->_n > NPAGES - 1){break;}span->_n += nextSpan->_n;_spanLists[nextSpan->_n].Erase(nextSpan);delete nextSpan;}_spanLists[span->_n].PushFront(span);span->_isUse = false;_idSpanMap[span->_pageId] = span;_idSpanMap[span->_pageId + span->_n - 1] = span;} 这段代码的功能是将一个空闲的 Span 释放到 PageCache 中,并尝试合并相邻的 Span,以减少内存碎片。以下是对代码的详细分析和改进建议。
1. 代码分析
1.1 向前合并逻辑
-
prevId:计算当前Span前一个页面的 ID。 -
_idSpanMap.find(prevId):查找前一个页面的Span。 -
合并条件:
-
如果前一个
Span未使用(prevSpan->_isUse == false)。 -
合并后的
Span大小不超过NPAGES - 1。
-
-
合并操作:
-
更新当前
Span的_pageId和_n。 -
从
_spanLists中移除前一个Span。 -
删除前一个
Span。
-
1.2 向后合并逻辑
-
nextId:计算当前Span后一个页面的 ID。 -
_idSpanMap.find(nextId):查找后一个页面的Span。 -
合并条件:
-
如果后一个
Span未使用(nextSpan->_isUse == false)。 -
合并后的
Span大小不超过NPAGES - 1。
-
-
合并操作:
-
更新当前
Span的_n。 -
从
_spanLists中移除后一个Span。 -
删除后一个
Span。
-
1.3 最终操作
-
将当前
Span插入到_spanLists中。 -
更新
_idSpanMap,确保当前Span的起始和结束页面 ID 都指向该Span。