十二、基于大模型的在线搜索平台——信息抓取
基于大模型的在线搜索平台——信息抓取
- 排除无关网页
- 内容爬取
- question页面
- question/answer页面
- 专栏类页面
- 将上面爬取功能封装到函数中
准备工作做完之后,接下来就是信息抓取的实现,实现功能后可赋予大模型调用,实现搜索能力。
排除无关网页
分析知乎常见网页类型,大致包括一下页面
- zhihu.com/question页面
- zhihu.com/answer页面
- zhihu.com/topic页面
- zhihu.com/collecton页面
- zhihu.com/people页面
- zhihu.com/column页面
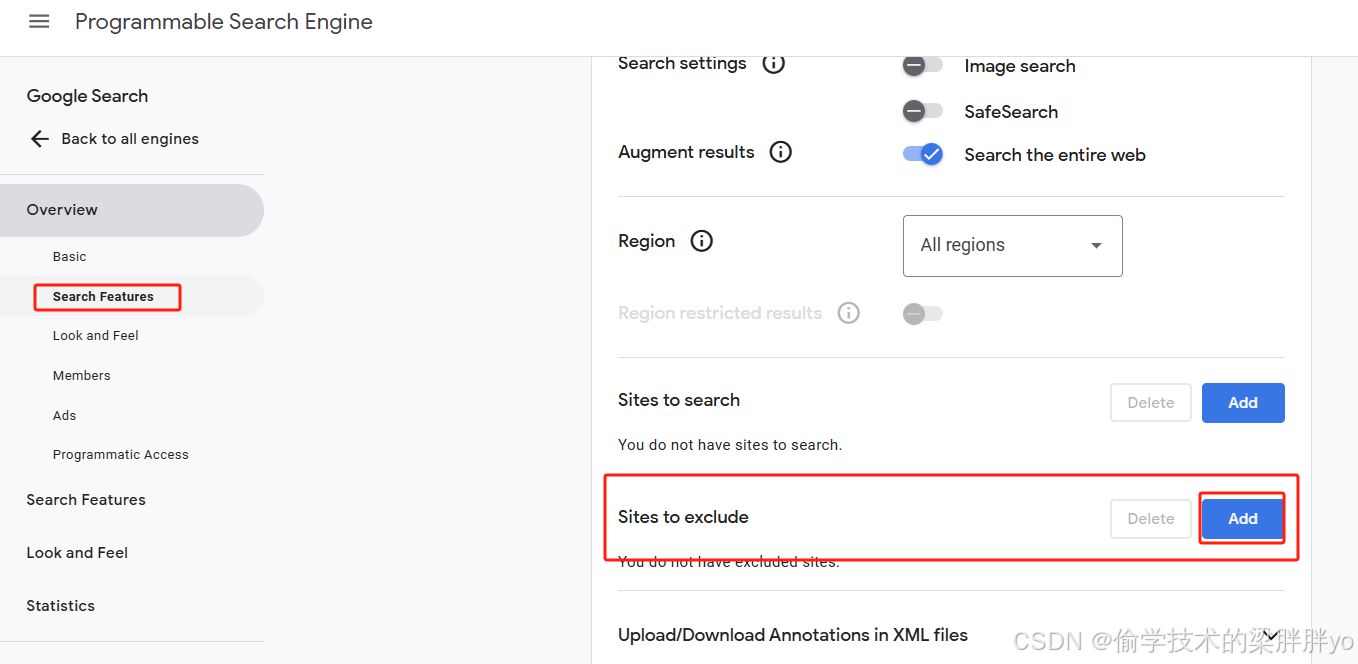
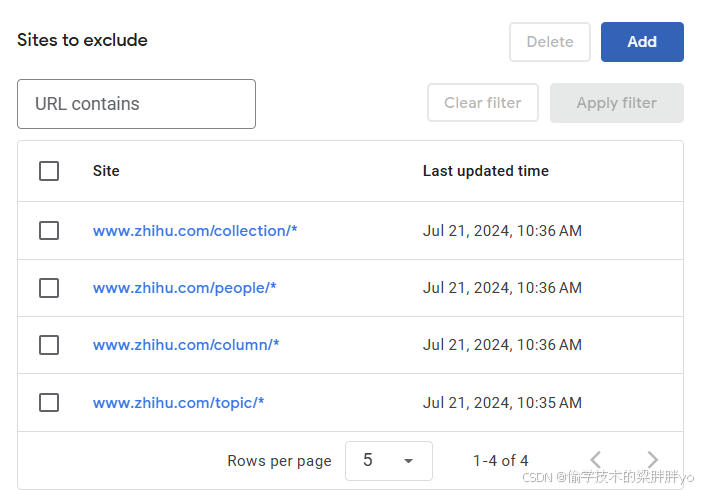
基于搜索问题的答案这个功能,主要涉及question和answer这两个页面,为了提高我们爬虫的准确率,可以将其他页面排除,也就是用前面提到的Google搜索引擎的排除url功能。地址:https://programmablesearchengine.google.com/
内容爬取
主要涉及知乎3类页面:第一类question页面、第二类answer页面、第三类专栏类页面。
question页面
cookie = "_zap=bd7c8e7a-6e5b-41fa-8905-45ebb71a24db; d_c0=AbAUg96PmhePTobFtt2wk8PsQPIv3RjcNow=|1698289470; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1720174518,1720513810,1721111871,1721527290; z_c0=2|1:0|10:1720513810|4:z_c0|80:MS4xQXdUeENBQUFBQUFtQUFBQVlBSlZUUkpEZW1mVUNPUXJ2RWROc2lCVmdTN1F4emRqX0V0OEtRPT0=|f5d43966101f52df7113d9f50e5f37a23b59ef2c736ff94c88d4e92d6156e645; _xsrf=MBLMaGi2bZuk6efUhnHGhgxfEJ67gx0r; __zse_ck=001_g3AcY+Sf/92TLQM2hJo=CGr1xNuT=txQyLuB+jd/dU5TMX7/Cc=pgRbAx2vMwM=rNKh9bYbgcNvqEILC1oNZNOObhlZHpZghPBCe7xdiMEimF58NgDtEtw7KRCBpBEZN; tst=r; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1721529497; HMACCOUNT=A36F3A7E9F90632C; BAIDU_SSP_lcr=https://www.baidu.com/link?url=Z_lJtfILG8WTHxqUS7VkII_bj9BndxVq7820EJqkO1u&wd=&eqid=9b4abe2f00695f2b00000002669c6bf1; BEC=6ff32b60f55255af78892ba1e551063a"
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0"headers = {'authority': 'www.zhihu.com','accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8','cache-control': 'max-age=0','cookie': cookie, # 需要手动获取cookie'upgrade-insecure-requests': '1','user-agent': user_agent, # user-agent选项
}url = "https://www.zhihu.com/question/55720139"res = requests.get(url, headers=headers).text
res
from lxml import etree
res_html = etree.HTML(res)
print(res_html)
# /html/body/div[1]/div/main/div/div/div[1]/div[2]/div/div[1]/div[1]/h1/
title = res_html.xpath('//div[1]/h1/text()')[0]
title
运行结果

content = res_html.xpath('string(//div[@class="RichContent-inner"]/div/span)')
content
运行结果

# 计算token数量
import tiktoken
encoding = tiktoken.encoding_for_model("gpt-4o-mini")
len(encoding.encode(content))
运行结果

定义一个数据格式,将爬取到的数据保存
# 定义一个数据格式,将爬取到的数据保存json_data = [{"link": url,"title": title,"content": content,"tokens": len(encoding.encode(content))}
]json_data
运行结果

# 将数据保存在文件中
import os
import jsonq = "Pytorch"
dir_path = f'data/auto_search/{q}'
if not os.path.exists(dir_path):# 如果目录不存在,则创建目录os.makedirs(dir_path)with open(f"data/auto_search/{q}/{title}", 'w') as f:json.dump(json_data, f)
with open(f"data/auto_search/{q}/{title}", 'r') as f:jd = json.load(f)
jd
运行结果

question/answer页面
url = 'https://www.zhihu.com/question/624723835/answer/3307112903'
res = requests.get(url, headers=headers).text
res_xpath = etree.HTML(res)
# /html/body/div[1]/div/main/div/div/div[1]/div[2]/div/div[1]/div[1]/h1
title = res_xpath.xpath('//div/div[1]/div[1]/h1/text()')[0]
title
运行结果

# /html/body/div[1]/div/main/div/div/div[3]/div[1]/div/div[2]/div/div/div/div[2]/span[1]/div/div/span
content = res_xpath.xpath('string(//div/div[2]/span[1]/div/div/span)')
content
运行结果

专栏类页面
url = 'https://zhuanlan.zhihu.com/p/548584568'
res = requests.get(url, headers=headers).text
res_xpath = etree.HTML(res)
# /html/body/div[1]/div/main/div/article/header/h1
title = res_xpath.xpath('//div/article/header/h1/text()')[0]
title
运行结果

# /html/body/div[1]/div/main/div/article/div[1]/div/div/div
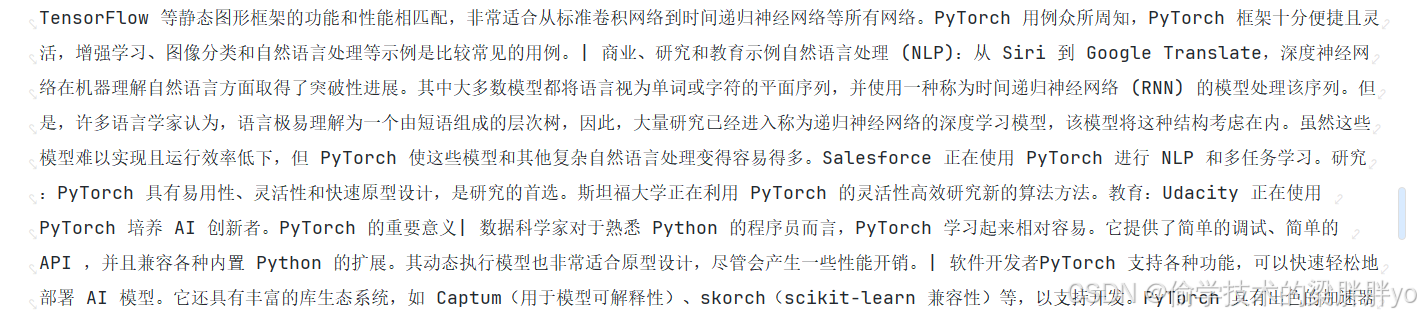
content = res_xpath.xpath('string(//div/article/div[1]/div/div/div)')
content
将上面爬取功能封装到函数中
主要包括通过url获取信息、按固定格式保存到文件中
def get_search_file(q, url):cookie = "_zap=bd7c8e7a-6e5b-41fa-8905-45ebb71a24db; d_c0=AbAUg96PmhePTobFtt2wk8PsQPIv3RjcNow=|1698289470; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1720174518,1720513810,1721111871,1721527290; z_c0=2|1:0|10:1720513810|4:z_c0|80:MS4xQXdUeENBQUFBQUFtQUFBQVlBSlZUUkpEZW1mVUNPUXJ2RWROc2lCVmdTN1F4emRqX0V0OEtRPT0=|f5d43966101f52df7113d9f50e5f37a23b59ef2c736ff94c88d4e92d6156e645; _xsrf=MBLMaGi2bZuk6efUhnHGhgxfEJ67gx0r; __zse_ck=001_g3AcY+Sf/92TLQM2hJo=CGr1xNuT=txQyLuB+jd/dU5TMX7/Cc=pgRbAx2vMwM=rNKh9bYbgcNvqEILC1oNZNOObhlZHpZghPBCe7xdiMEimF58NgDtEtw7KRCBpBEZN; tst=r; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1721529497; HMACCOUNT=A36F3A7E9F90632C; BAIDU_SSP_lcr=https://www.baidu.com/link?url=Z_lJtfILG8WTHxqUS7VkII_bj9BndxVq7820EJqkO1u&wd=&eqid=9b4abe2f00695f2b00000002669c6bf1; BEC=6ff32b60f55255af78892ba1e551063a"user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0"headers = {'authority': 'www.zhihu.com','accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8','cache-control': 'max-age=0','cookie': cookie, # 需要手动获取cookie'upgrade-insecure-requests': '1','user-agent': user_agent, # user-agent选项}# 普通问答地址if 'zhihu.com/question' in url:res = requests.get(url, headers=headers).textres_xpath = etree.HTML(res)title = res_html.xpath('//div[1]/h1/text()')[0]content = res_html.xpath('string(//div[@class="RichContent-inner"]/div/span)')# 专栏地址elif 'zhuanlan' in url:headers['authority'] = 'zhaunlan.zhihu.com'res = requests.get(url, headers=headers).textres_xpath = etree.HTML(res)title = res_xpath.xpath('//div/article/header/h1/text()')[0]content = res_xpath.xpath('string(//div/article/div[1]/div/div/div)') # 特定回答的问答网址elif 'answer' in url:res = requests.get(url, headers=headers).textres_xpath = etree.HTML(res)title = res_xpath.xpath('//div/div[1]/div[1]/h1/text()')[0]content = res_xpath.xpath('string(//div/div[2]/span[1]/div/div/span)')encoding = tiktoken.encoding_for_model("gpt-4o-mini") json_data = [{"link": url,"title": title,"content": content,"tokens": len(encoding.encode(content))}]dir_path = f'data/auto_search/{q}'if not os.path.exists(dir_path):# 如果目录不存在,则创建目录os.makedirs(dir_path)with open(f"data/auto_search/{q}/{title}", 'w') as f:json.dump(json_data, f)return title
测试验证
title = get_search_file('如何学习pytorch','https://www.zhihu.com/question/437199981/answer/3310028730')
title

# 读取文件
with open(f"data/auto_search/如何学习pytorch/新手如何入门pytorch?", 'r') as f:jd = json.load(f)
jd
