2025数字中国创新大赛-数字安全赛道数据安全产业积分争夺赛决赛Writeup
文章目录
- 综合场景赛-模型环境安全-3
- 综合场景赛-数据识别与审计-1
- 综合场景赛-数据识别与审计-2
- 综合场景赛-数据识别与审计-3
有需要题目附件的师傅,可以联系我发送
综合场景赛-模型环境安全-3

upload文件嵌套了多个png图片字节数据,使用foremost直接分离,得到500张图片。
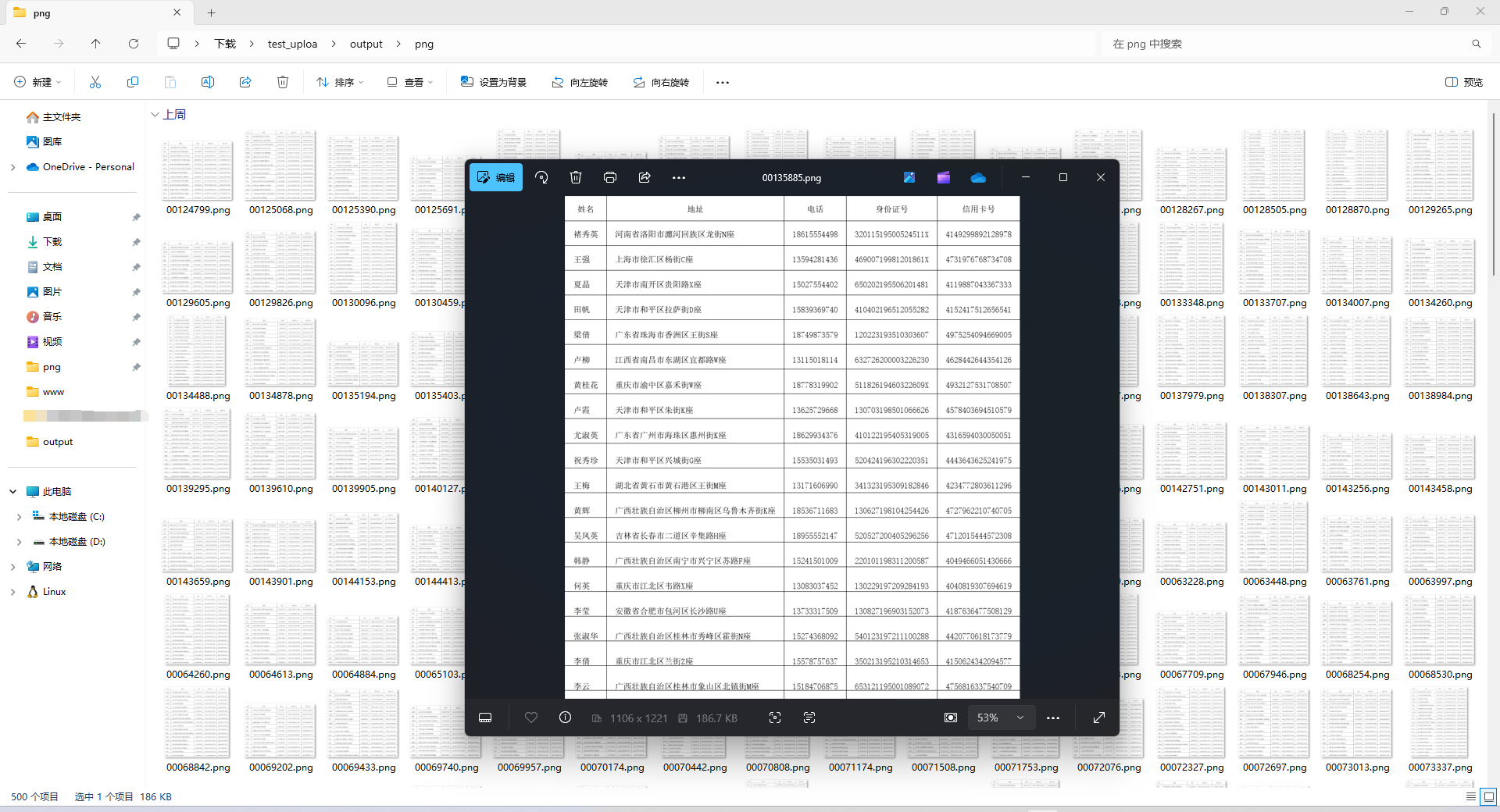
根据这些图片的规律,发现隐私条数和图片高度有关系,且图片高度有规律,尝试统计所有图片高度并去重
from PIL import Image
import osheight_list = []
filename_list = os.listdir('./png')
for filename in filename_list:filename_path = './png/' + filenamewith Image.open(filename_path) as img:img_height = img.size[1]height_list.append(img_height)
print("[+]img height count: {}".format(len(height_list)))
deduplication_height = set(height_list)
print("[+]img height deduplication count: {}".format(len(deduplication_height)))
print(deduplication_height)

发现只有11种高度,且成逐渐增长趋势对应条数也在增加。
{672, 1282, 1221, 1160, 1099, 1038, 977, 916, 855, 794, 733}
672 10条
733 11条
794 12条
855 13条
916 14条
以此类推....
1221 19条
1282 20条
直接按照这个高度对应的隐私数据条数统计
from PIL import Image
import oscount_num = 0
filename_list = os.listdir('./png')
hieght_to_num = {"672":10, "733":11, "794":12, "855":13, "916":14, "977":15, "1038":16, "1099":17, "1160":18, "1221":19, "1282":20}
for filename in filename_list:filename_path = './png/' + filenamewith Image.open(filename_path) as img:img_height = img.size[1]count_num += hieght_to_num[str(img_height)]
print(count_num)

最终答案为:7374
综合场景赛-数据识别与审计-1

按照请求包和响应包,主要提取两部分内容
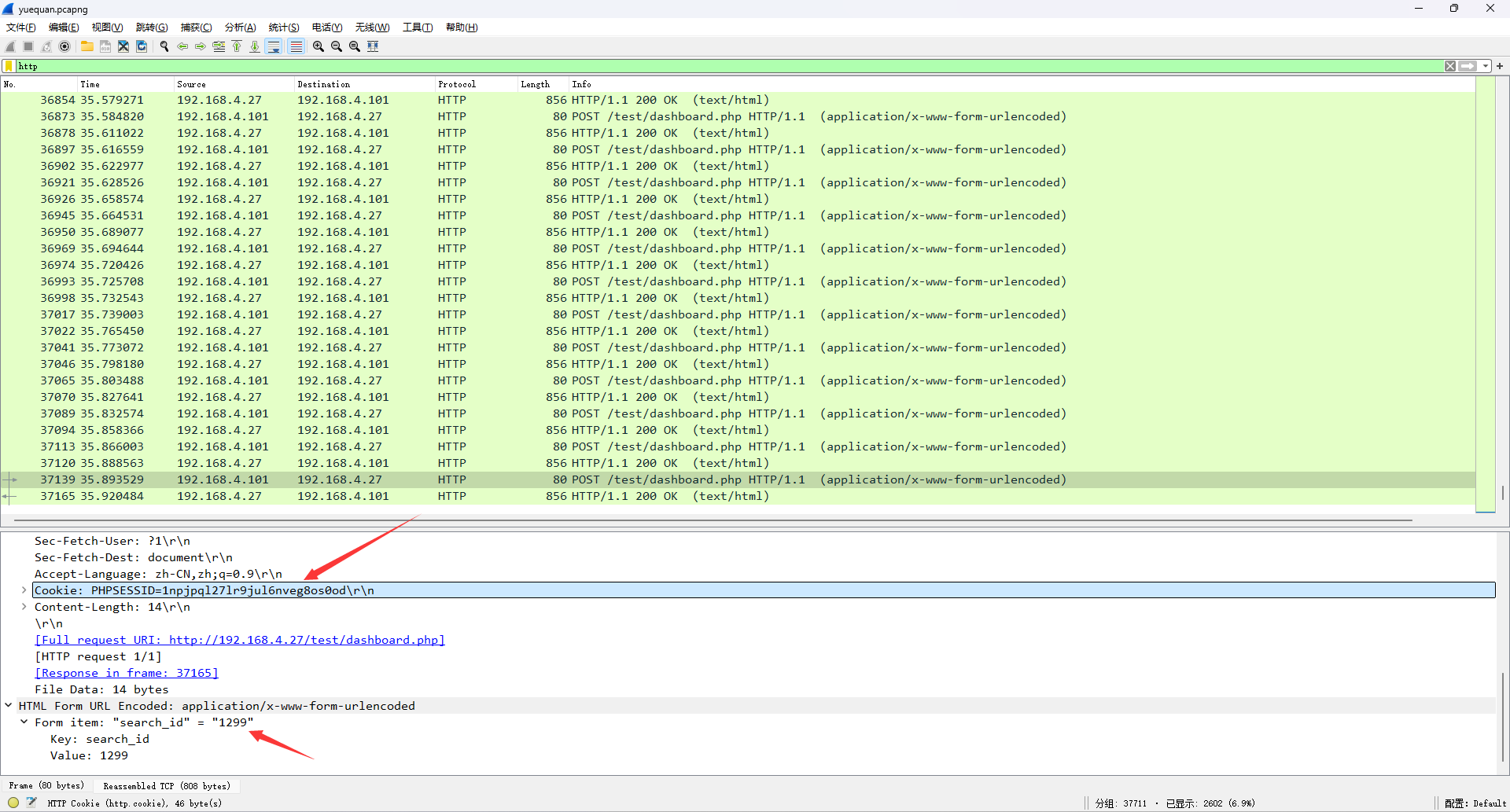
请求包提取PHPSESSIONID、search_id
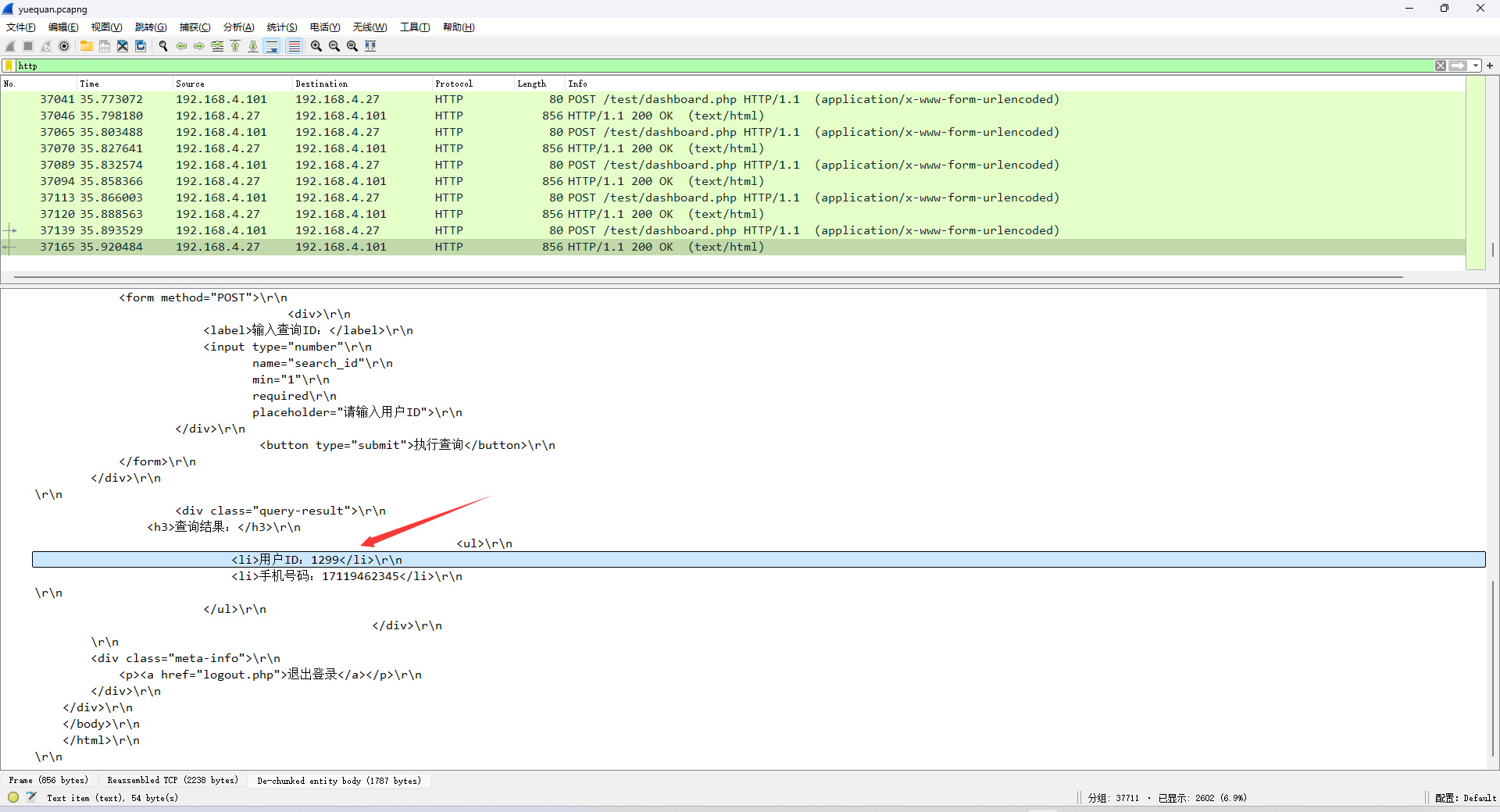
响应包提取用户ID的内容
CMD命令行下,使用tshark提取这三个字段:
D:\Wireshark\tshark.exe -r .\yuequan.pcapng -T fields -Y "http" -e "http.cookie" -e "text" -e "data-text-lines" > data1.txt
请求包的两个字段在一行,随后的下一行为响应包的内容。直接按照这个格式进行数据处理
with open('data1.txt', 'r', encoding="utf-8") as f:lines = f.readlines()for i in range(0, len(lines), 2):req_text = lines[i].strip()resp_text = lines[i+1].strip()search_id = req_text[req_text.find('"search_id"'):]phpsessid = req_text[req_text.find('=')+1:req_text.find('Time')]resp_userid = resp_text[resp_text.find('用户ID:'):resp_text.find('</li>')]final_search_id = search_id[search_id.find('= "')+3:-1]final_resp_userid = resp_userid[resp_userid.find(':')+1:]session_filename = './session/session_' + phpsessid.strip()with open(session_filename, 'r') as f:sessionid_text = f.read().strip()login_id = sessionid_text[sessionid_text.find('i:')+2:sessionid_text.find(';s:')]if '"is_admin";b:0;' in sessionid_text:if login_id != final_search_id:print(sessionid_text, search_id, resp_userid)print('----------------------------------------------------------------------------------')
精准提取出:请求包的PHPSESSIONID、请求包的search_id、响应包的userid。
根据请求包的PHPSESSIONID去打开session_id文件,读取其中的login_id作为查询用户的当前身份ID,如果在is_admin字段不为1的情况下,查询用户的当前身份ID与请求包的search_id不一致,视为越权。数据筛选结果如下:
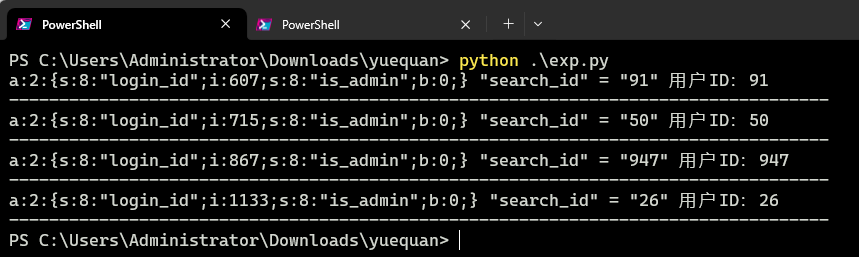
答案:607_715_867_1133
综合场景赛-数据识别与审计-2
题目给的用户权限表与adminer上导出的用户权限表,做对比(这里使用Diffinity工具)
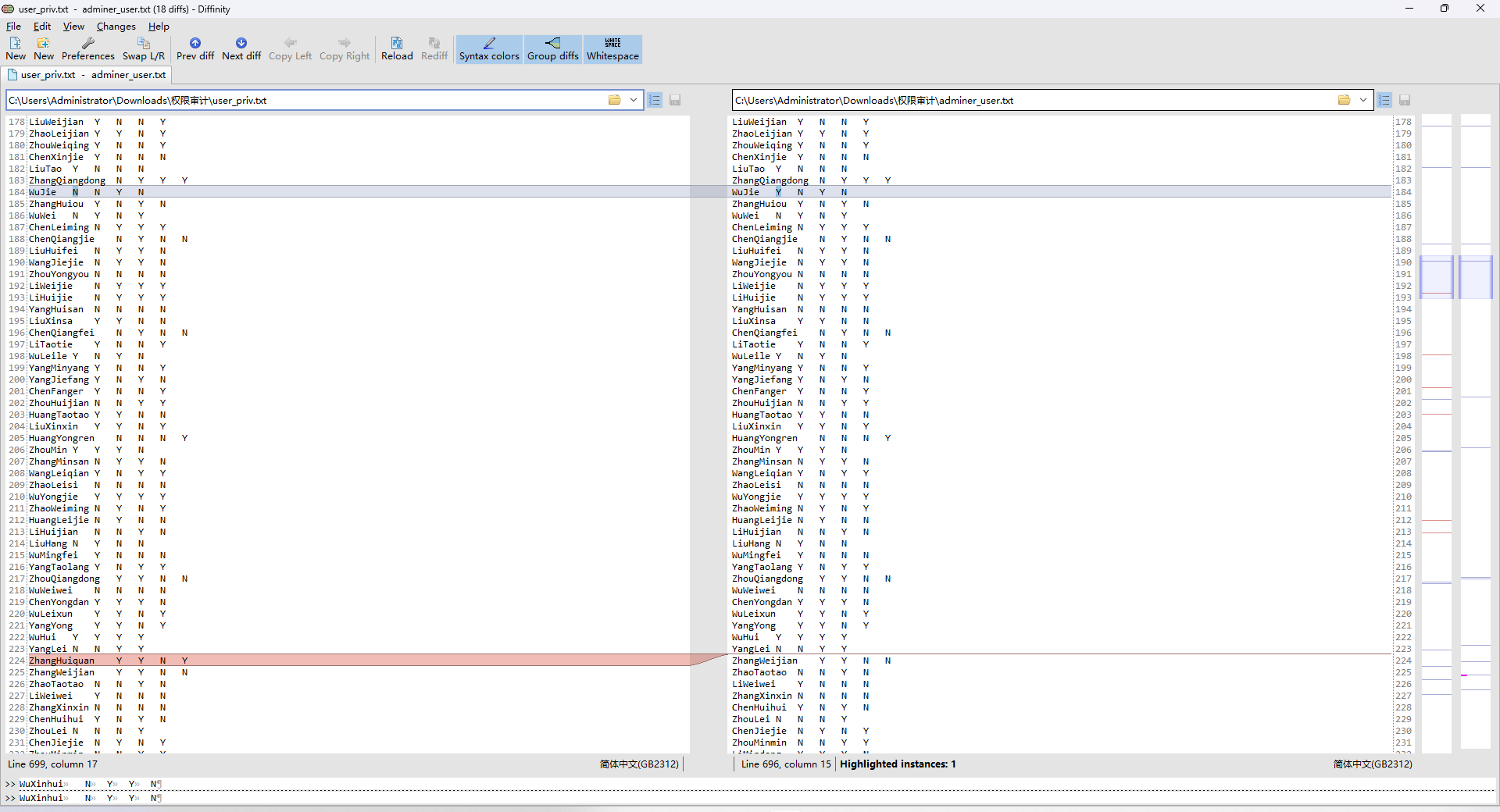
- Adminer上导出的用户权限表比题目给的表,少了6个用户。且另外有3个用户账号发生了变化。判断被删除用户有9个。
- 有三个用户账号发生了变化,即是删除也是增加,被添加的用户为3个。
- 权限项发生变化的用户有9个。
被删除的用户:9
被添加的用户:3
权限发生更改的用户:9
最终答案:9_3_9
综合场景赛-数据识别与审计-3
提取所有URL
import requests
from lxml import etree
import re
import tldextractextract_url = []
for page_num in range(1, 31):request_url = "http://192.168.60.133:80/?page={}".format(page_num)resp = requests.get(url=request_url)html = etree.HTML(resp.text)extract_url += html.xpath('//a[@class="text-decoration-none"]/@href')
for url in extract_url:print(url)
有url.txt和robots.txt,要求按照robots.txt中的规则,统计url.txt中Disallow的url数量,且Allow的规则优先于Disallow。
from urllib.parse import urlparse, unquote
import rewith open("url.txt", "r") as f:urls = [line.strip() for line in f.readlines()]with open("robots.txt", "r") as f:robots_lines = [line.strip() for line in f.readlines()]allow_patterns, disallow_patterns = [], []
for line in robots_lines:if line.startswith("Allow: "):rule = line[line.find('/'):].replace('.','\\.').replace('*','.*')allow_patterns.append(re.compile(rule))if line.startswith("Disallow: "):rule = line[line.find('/'):].replace('.','\\.').replace('*','.*')disallow_patterns.append(re.compile(rule))def is_allowed(path):for pattern in allow_patterns:if pattern.match(path):return Truereturn Falsedef is_disallowed(path):for pattern in disallow_patterns:if pattern.match(path):return Truereturn False# Allow优先级高于Disallow
disallowed_count = 0
for url in urls:path = unquote(url[url.find(urlparse(url).path):])if is_disallowed(path) and not is_allowed(path):disallowed_count += 1
print("[+]不允许爬虫爬取的URL数(Allow优先级高于Disallow): {}".format(disallowed_count))

最终答案:503