2025.04.19【Spider】| 蜘蛛图绘制技巧精解
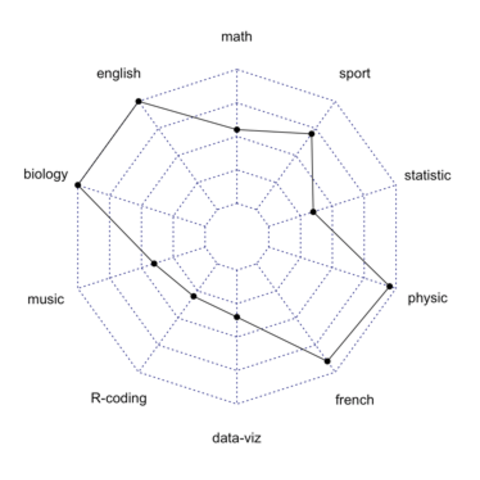
Basic multi-group radar chart
Start with a basic version, learn how to format your input
dataset
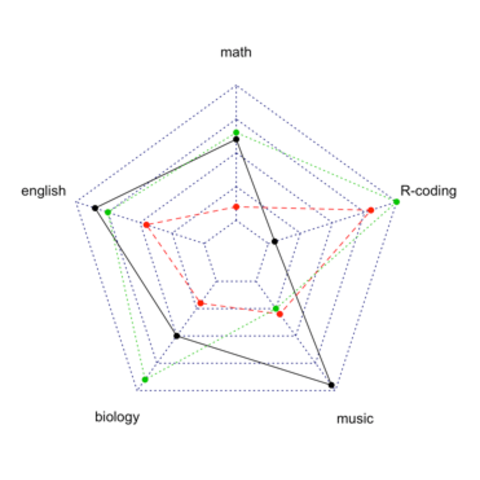
Radar chart with ggradar
A Spider chart made using the ggradar package
and a lot of customization.A work by Tuo Wang
文章目录
- Basic multi-group radar chart
- Radar chart with ggradar
- 引言
- Spider/Radar图表简介
- 为什么使用Spider/Radar图表
- 何时避免使用Spider/Radar图表
- R语言中的fmsb库
- 安装和加载fmsb库
- 创建基本的Spider/Radar图表
- 准备数据
- 创建图表
- 自定义Spider/Radar图表
- 添加轴标签
- 添加图例
- 自定义颜色和样式
- Spider/Radar图表在生物信息学中的应用
- 基因表达分析
- 蛋白质丰度比较
- 代谢物水平分析
- Spider/Radar图表的局限性
- 结论
引言
在生物信息学领域,数据可视化是理解复杂数据集的关键。Spider/Radar图表,也称为星形或雷达图表,是一种用于展示多个变量之间关系的二维图表。这种图表可以绘制一个或多个数据系列,并在多个定量变量上进行比较。尽管Spider/Radar图表在视觉上具有吸引力,但由于其可能误导数据解读,使用时应谨慎。在R语言中,fmsb库提供了构建Spider/Radar图表的最佳工具。通过这个库,我们可以轻松创建出既美观又信息丰富的图表,以直观展示生物信息数据的多维特征。然而,由于其设计上的一些缺点,比如难以比较不同数据点的大小,所以在选择使用Spider/Radar图表时,需要权衡其视觉效果与数据准确性。本文将详细介绍如何使用fmsb库来创建这些图表,并讨论它们在生物信息学中的应用及其局限性。
Spider/Radar图表简介
Spider/Radar图表是一种特殊的图表类型,它通过从中心点向外延伸的轴来展示多个变量的数据。每个轴代表一个变量,而数据点则沿着这些轴绘制。这种图表特别适合于展示一组变量的相对重要性或比较不同个体或组在多个维度上的表现。
为什么使用Spider/Radar图表
-
多变量比较:Spider/Radar图表可以同时展示多个变量的数据,使得比较变得更加直观。
-
视觉吸引力:这种图表以其独特的星形外观吸引观众的注意。
-
集中展示:所有数据点都集中在一个图表中,便于比较和分析。
何时避免使用Spider/Radar图表
-
数据点过多:当变量数量过多时,图表会变得拥挤且难以解读。
-
精确比较困难:由于轴之间的夹角和长度可能不同,精确比较不同数据点的大小变得困难。
-
误导性解读:如果轴的长度或角度设置不当,可能会导致误导性的解读。
R语言中的fmsb库
在R语言中,fmsb库是创建Spider/Radar图表的首选工具。这个库提供了一系列的函数来构建和自定义这些图表。
安装和加载fmsb库
首先,你需要安装并加载fmsb库。你可以使用以下命令来安装:
install.packages("fmsb")然后,使用library函数加载它:
library(fmsb)创建基本的Spider/Radar图表
接下来,我们将通过一个简单的例子来展示如何创建一个基本的Spider/Radar图表。
准备数据
首先,我们需要准备一些数据。这里我们使用一个包含三个变量的数据集:
data <- data.frame(Group = rep(c("A", "B"), each = 3),Var1 = c(1, 2, 3, 2, 3, 1),Var2 = c(3, 2, 1, 1, 2, 3),Var3 = c(2, 3, 1, 3, 1, 2)
)创建图表
使用radarchart函数来创建Spider/Radar图表:
radarchart(data[, -1], axistype = 1,pcol = rainbow(nrow(data)), pfcol = rainbow(nrow(data)), plwd = 4, plty = 1,vlcex = 0.8)这里的参数解释如下:
-
data[, -1]:选择除了第一列之外的所有列作为数据源。 -
axistype = 1:设置轴的类型为1,表示所有轴的长度相同。 -
pcol:设置线条的颜色。 -
pfcol:设置填充颜色。 -
plwd:设置线条的宽度。 -
plty:设置线条的类型。 -
vlcex:设置标签的字体大小。
自定义Spider/Radar图表
fmsb库允许你自定义Spider/Radar图表的许多方面,包括轴的标签、颜色、图例等。
添加轴标签
你可以使用axislabels参数来添加轴标签:
radarchart(data[, -1], axistype = 1,pcol = rainbow(nrow(data)), pfcol = rainbow(nrow(data)), plwd = 4, plty = 1,vlcex = 0.8,axislabels = c("Variable 1", "Variable 2", "Variable 3"))添加图例
使用legend.text参数来添加图例:
radarchart(data[, -1], axistype = 1,pcol = rainbow(nrow(data)), pfcol = rainbow(nrow(data)), plwd = 4, plty = 1,vlcex = 0.8,axislabels = c("Variable 1", "Variable 2", "Variable 3"),legend.text = data$Group)自定义颜色和样式
你可以通过修改pcol和pfcol参数来自定义线条和填充的颜色:
radarchart(data[, -1], axistype = 1,pcol = c("red", "blue"), pfcol = c("lightpink", "lightblue"), plwd = 4, plty = 1,vlcex = 0.8,axislabels = c("Variable 1", "Variable 2", "Variable 3"),legend.text = data$Group)Spider/Radar图表在生物信息学中的应用
Spider/Radar图表在生物信息学中有着广泛的应用,特别是在比较不同样本或个体在多个特征上的表现时。例如,它可以用于比较不同基因表达模式、蛋白质丰度或代谢物水平。
基因表达分析
在基因表达分析中,Spider/Radar图表可以用来展示不同样本中基因表达的变化。每个轴代表一个基因,而数据点则表示该基因在不同样本中的表达水平。
蛋白质丰度比较
在蛋白质组学研究中,Spider/Radar图表可以用来比较不同条件下蛋白质的丰度变化。这有助于识别在特定生物学过程中起关键作用的蛋白质。
代谢物水平分析
在代谢组学研究中,Spider/Radar图表可以用来展示不同样本中代谢物的水平。这有助于识别与特定疾病或条件相关的代谢物。
Spider/Radar图表的局限性
尽管Spider/Radar图表在视觉上具有吸引力,但它们也有一些局限性。以下是一些需要考虑的因素:
-
数据点过多:当变量数量过多时,图表会变得难以解读。
-
精确比较困难:由于轴之间的夹角和长度可能不同,精确比较不同数据点的大小变得困难。
-
误导性解读:如果轴的长度或角度设置不当,可能会导致误导性的解读。
因此,在决定使用Spider/Radar图表时,需要仔细考虑这些因素,并确保它们适合你的数据和分析目的。
结论
Spider/Radar图表是一种强大的工具,可以帮助我们在生物信息学领域中可视化和比较多变量数据。通过使用R语言中的fmsb库,我们可以轻松创建这些图表,并根据需要进行自定义。然而,我们也需要意识到它们的局限性,并在使用时保持谨慎。希望本文能帮助你更好地理解和应用Spider/Radar图表。
🌟 非常感谢您抽出宝贵的时间阅读我的文章。如果您觉得这篇文章对您有所帮助,或者激发了您对生物信息学的兴趣,我诚挚地邀请您:
👍 点赞这篇文章,让更多人看到我们共同的热爱和追求。
🔔 关注我的账号,不错过每一次知识的分享和探索的旅程。
📢 您的每一个点赞和关注都是对我最大的支持和鼓励,也是推动我继续创作优质内容的动力。
📚 我承诺,将持续为您带来深度与广度兼具的生物信息学内容,让我们一起在知识的海洋中遨游,发现更多未知的奇迹。
💌 如果您有任何问题或想要进一步交流,欢迎在评论区留言,我会尽快回复您。