项目模拟实现消息队列第二天
消息应答的模式
1.自动应答:
消费者把这个消息取走了,就算是应答了(相当于没有应答)
2.手动应答:
basicAck方法属于手动应答(消费者需要主动调用这个api进行应答)
小结
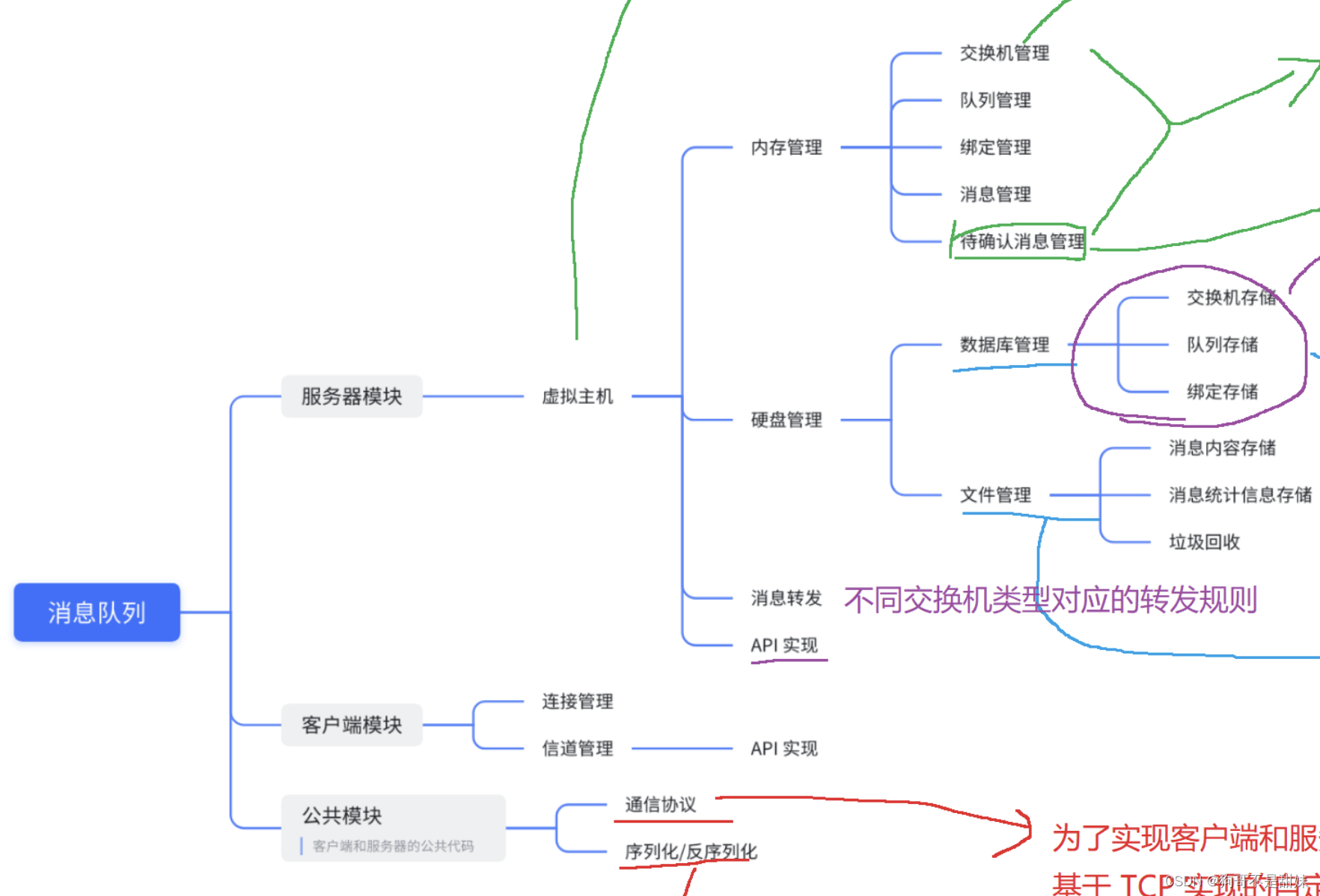
1.需要实现生产者,broker server,消费者这三个部分的
2.针对生产者和消费者来说,
主要编写的是 客户端和服务器的网络通信部分,给客户端提供一组api,让客户端的业务代码来调用,从而通过网络通信的方式远程调用broker server的方法
至于生产者的数据从哪里来,消费者取到数据之后干嘛,生产者和消费者的具体业务逻辑,我们不去关心
3.[重点]
实现broker server以及broker server内部的一些核心概念和核心api
核心概念:Virtual host,Exchange,Queue,Binding,Message
核心api:创建交换机,删除交换机,创建队列,删除队列,创建绑定,解除绑定,发送消息,订阅消息,应答消息
4.持久化
上述这些关键数据,在硬盘上怎么存储,什么格式存储,存储在数据库中,文件中?后续服务器重启了,如何读取当前数据,把内存中的内容恢复过来
上述要做的工作,最终目标就是实现一个"分布式系统"下这样的生产者消费者模型
消息队列中存在的核心概念
1.交换机 Exchange
2.队列. Queue
3.绑定 Binding
4.消息 Message
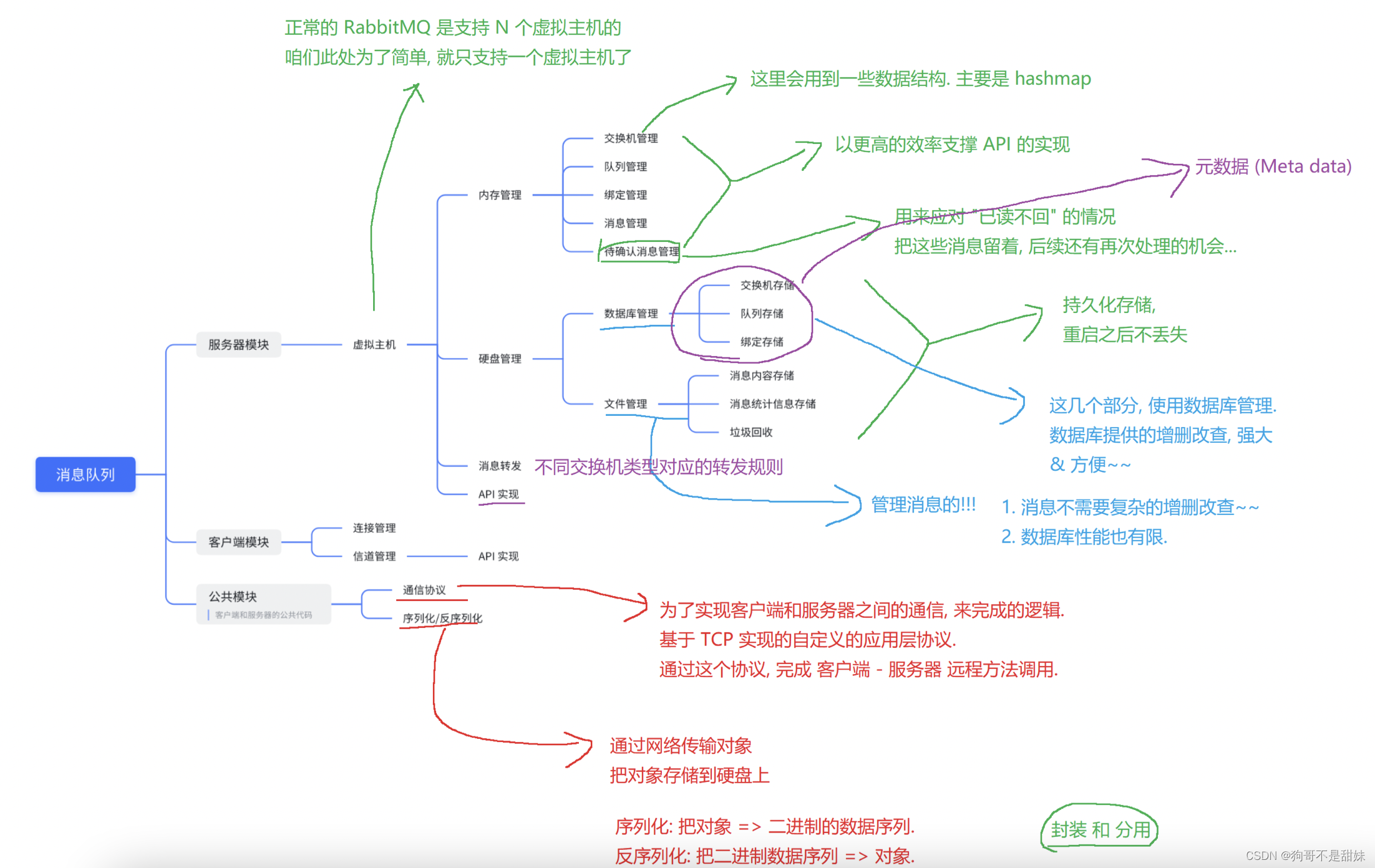
针对交换机,队列,绑定,消息---内存中也需要存储(执行效率高),硬盘上也需要存储(持久化),有些交换机,队列,绑定等,需要持久化存储,但是有些则不需要,用户使用的时候,可以通过开关(boolean值)来决定是否真正需要持久化

管理关键概念需要两个部分
1.内存
2.硬盘 ->数据库,文件
考虑使用MySQL本身比较重量,此处为了使用更方便,简化环境,采用更轻量的数据库,SQLite(一个完整的SQLite数据库,只有一个单独的可执行文件(不到1M),这个数据库相当于是直接操作本地的硬盘文件
SQLite应用非常广泛,在一些性能不高的设备上,使用数据库的首选,尤其是移动端和嵌入式设备Android系统,就是内置的SQLite(不用额外安装,直接使用maven,把SQLite的依赖引入进来即可,会自动加载jar和动态库文件
SQLite如何建库能
当把依赖和配置都搞好了,
难点1:
如何把
private Map<String,Object> arguments=new HashMap<>()转化成数据库中的字符串类型呢?关键要点是:MyBatis在玩成数据库操作的时候,会自动调用对象的getter和setter
1.比如MyBatis往数据库中写数据,就会调用对象的getter方法拿到属性的值,再往数据库中写,如果这个过程让,getArguments得到的结果是String类型的,此时就可以把数据写到数据库中了
2.比如MyBatis从数据库读数据的时候,就会调用对象的setter方法,把数据库智能鼓独到的结果设置到对象的属性中,比如这个过程,让setArguments,参数是一个String,并且在setArguments内部针对字符串解析,解析成一个Map对象。
使用Mybatis来创建数据表的时候,需要先创建出数据库来,创建meta.db这个文件,由于data目录不存在,所以创建meta.db文件的操作,也就失败了。
Message,如何在硬盘上存储
1.消息操作并不涉及到复杂的增删改查
2.消息数量可能非常多,数据库访问效率是不高的
直接把消息存储在文件中
一下设定了消息如何在文件中存储
消息是依附于队列的
因此存储的时候,就把消息按照队列的维度展开
此处已经有了个data目录,meta.db就在这个目录中
在data中创建一些子目录,每个队列有一个子目录,子目录的名字,就是队列名
data->
meta.db
testQueue1 这几个也是目录,用来存储对应的消息
testQueue2
testQueue3
每个队列的子目录喜爱,再分配两个文件,来存储信息
第一个文件:queue_data.txt这里保存消息的内容
第二个文件: queue_stat.txt这里保存消息的统计信息
queue_data这个文件是一个二进制格式的文件
做出以下约定~
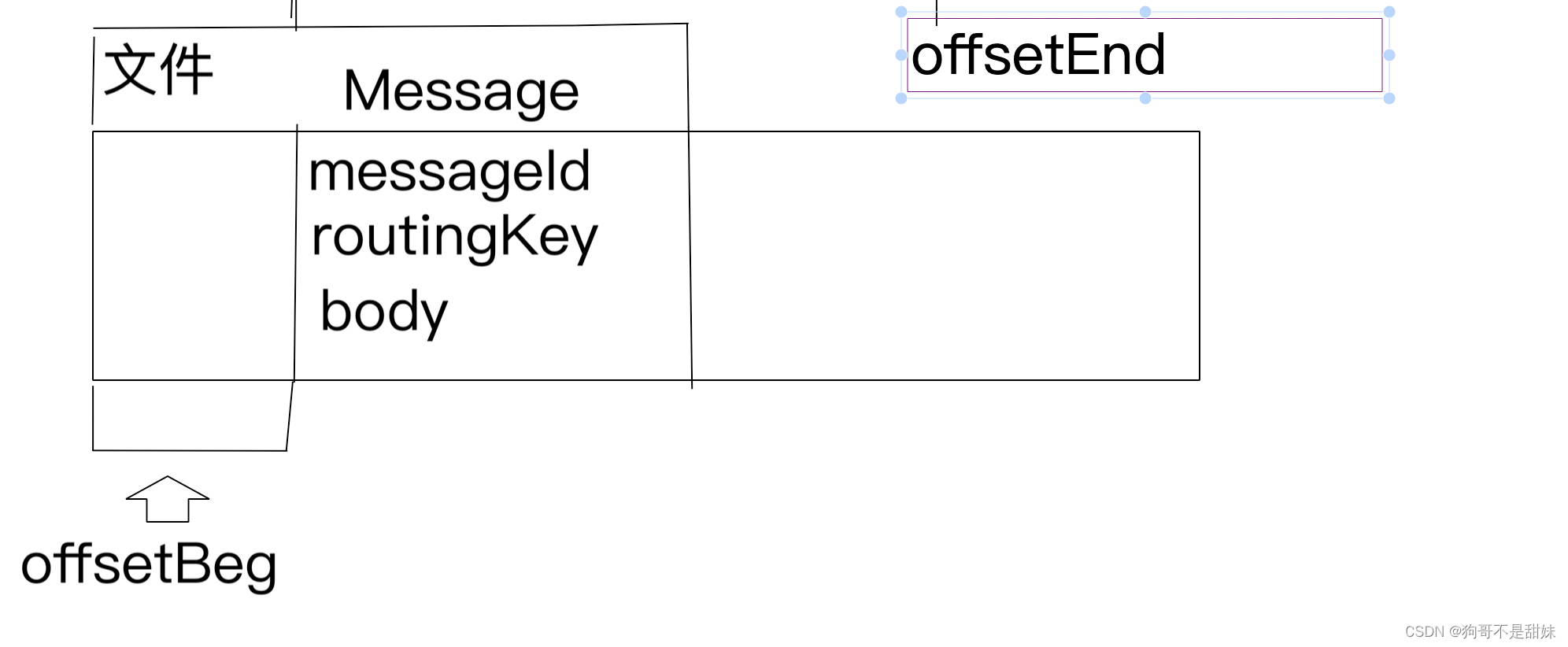
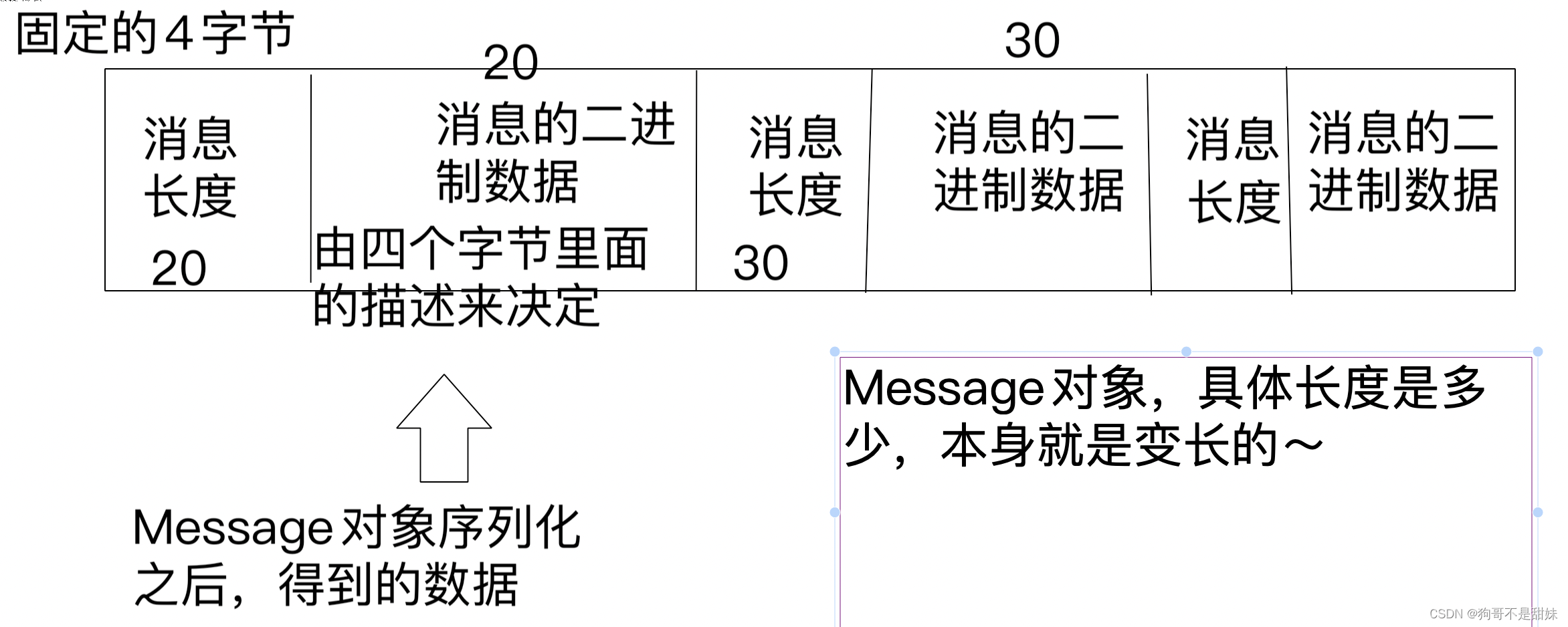
这个文件中包含若干个消息,每个消息都以二进制的方式存储
每个消息都由这几个部分构成
二进制的格式是java标准库序列化来实现的
Message对象,是在内存中记录一份,硬盘上也记录一份,内存中这一份,要记录offsetBeg和offsetEnd随时找到内存中的Message对象,就能找到对应的硬盘上的Message对象了。

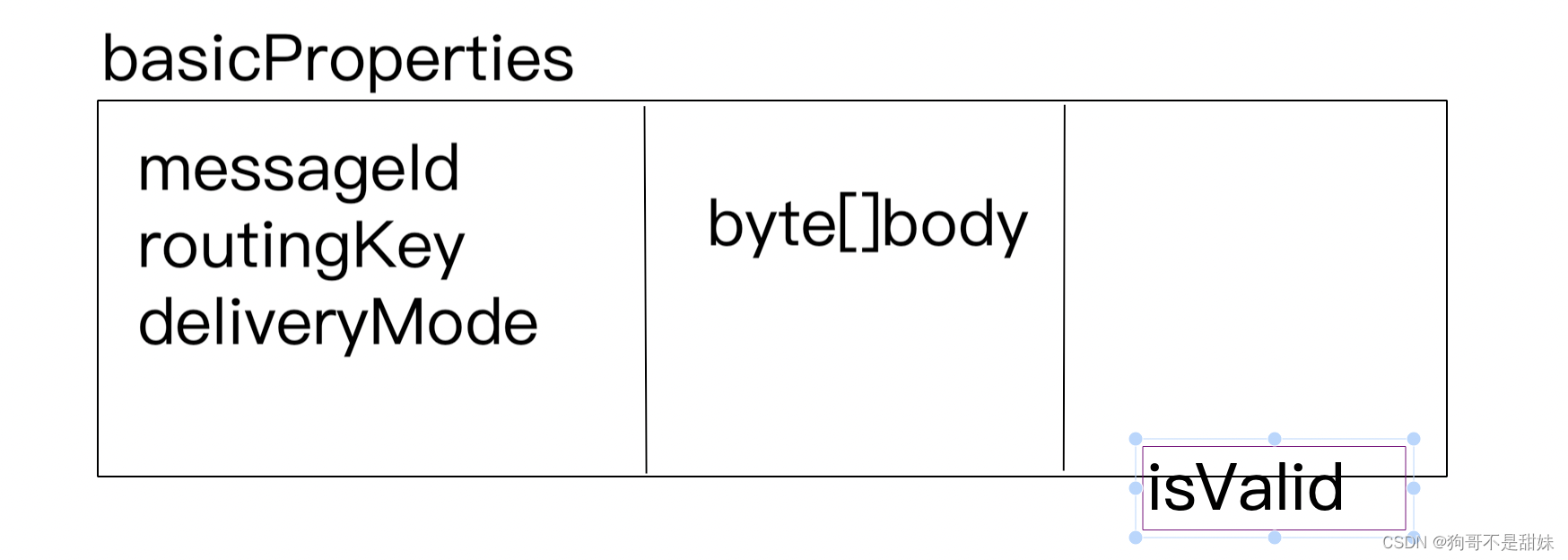
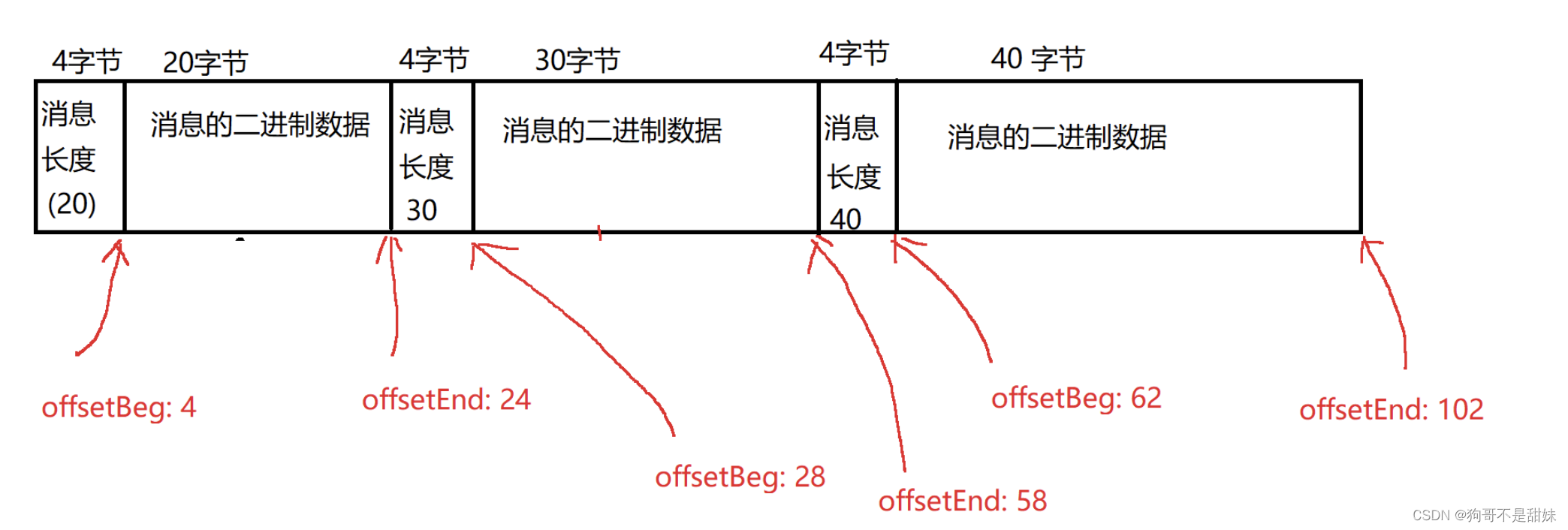
对于Broker Server来说,消息是需要新增,也是需要删除的,生产者生产一个消息过来,就得新增这个消息,消费者吧这个消息消费掉,这个消息就要删除
新增和删除,对于内存来说-好办(直接使用一些集合类)
但是在文件上就麻烦了,新增消息,可以直接把新的消息追加到文件末尾~删除消息不好处理,文件可以视为一个顺序表,这样的结构,如果此时直接删除中间元素,就需要涉及到类似于顺序表搬运这样的操作-效率非常低的是。
因此我们采用逻辑删除-isValid为1,有效消息,isValid为0-无效消息
随着时间的推移,这个消息文件可能会越来越大~并且,这里可能大部分都是无效的消息,针对这种情况,就需要考虑对当前消息数据文件,进行垃圾回收。
使用复制算法,针对消息数据文件中的垃圾,进行回收
如果某个队列中,消息特别多,而且都是有效消息,此时就会导致整个消息数据文件特别大,后续针对这个文件的各种操作,成本就会上升很多,假如这个文件大小是10G,此时如果出发一次GC,整体耗时就会非常高了


对于RabbitMQ来说,解决方案是把一个大的文件,拆成若干个小文件。
文件拆分:当单个文件长度到达一个阈值之后,就会拆分成两个文件(拆者拆着,就变成了很多文件)
文件合并:每个单独的文件都会进行GC,如果GC之后,发现文件变小了很多,就可能会和相邻的文件合并。
这样做,就可以在消息特别多的时候,也能保证性能上的及时响应
这一块逻辑比较复杂,因此此处不进行实现,咱们只考虑单个文件的情况
如果要实现这个机制,大概思路:需要专门的数据结构,来存储当前队列中有多少个数据文件,每个文件大小是多少,消息数目是多少,无效消息是多少
2.设计策略,什么时候出发文件的拆分,什么时候触发文件的合并
统计文件,读写比较简单
消息数据文件,比较复杂
消息序列化如何实现:
首先什么叫做序列化:把一个对象(结构化数据)转成一个字符串/字节数组->(降维打击了)
注意这样的序列化完成之后,对象的信息是不丢失的。这样后面才可以进行反序列化
序列化之后,方便存储和传输->(相当于干粮脱水)
一般是存储在文件中,文件只能存字符串/二进制数据,不能直接存对象
通过网络传输 JSON来完成序列化,反序列化
由于Message,里面存储的body是二进制数据,不太方便使用JSON进行序列化,JSON序列化得到的结果是文本数据,无法存储二进制。
我们准备直接使用二进制的序列化方式,针对Message对象进行序列化~
针对二进制序列化,也有很多种解决方案
1.JAVA标准库提高了序列化的方案,ObjectInputStream(用来序列化)和ObjectOutputStream(反序列化)
2.Hessian也是一个解决方案
3.protobuffer
4.thrift
咱们此处使用第一个方案,标准库自带的方案,好处:不必引入额外以来,学习成本低
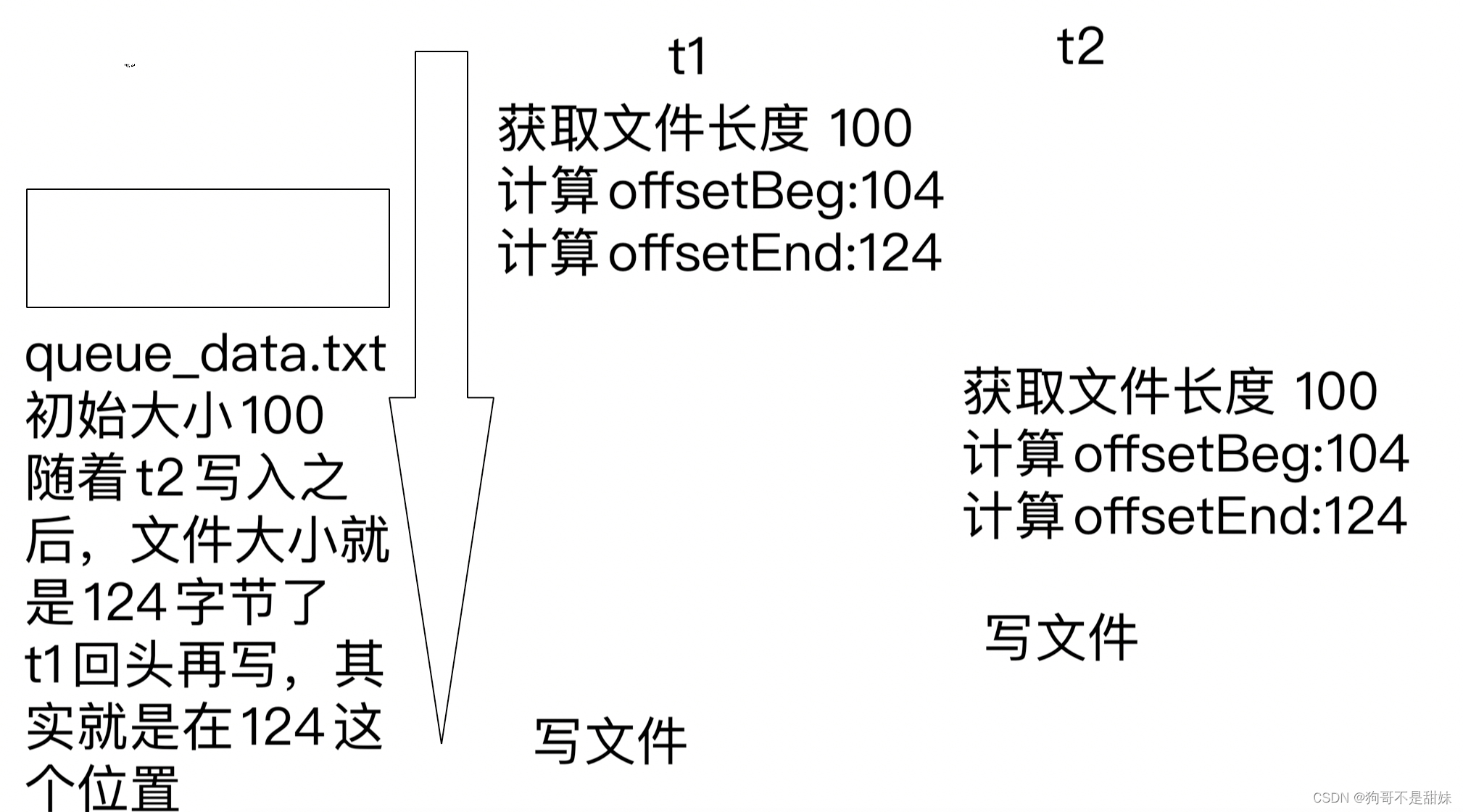
遇到的并发问题。,此时写入文件之后,真实消息所在的位置,就和刚才计算的offset不匹配了!
出路:加锁
如果两个线程,是往同一个队列中写消息,此时需要阻塞等待
如果两个线程,往不同队列中写消息,此时不需要阻塞队列。(不同队列,对应不同的文件,各自写各自的,就不会产生冲突了)
实现消息文件的垃圾回收
由于当前会不停的往消息文件中写入消息,并且删除消息只是逻辑删除,这就可能导致消息文件越来越大,并且里面又包含大量无效消息
此处的垃圾回收,使用复制算法
判定,当文件中信息总数超过2000,并且有效消息的数目不足50%,就要触发垃圾回收~,就把文件中所有有效消息取出来,单独的在写入到一个新的文件中,删除旧文件,使用新文件代替