【AI论文】WebThinker:赋予大型推理模型深度研究能力
摘要:大型推理模型(LRMs),如OpenAI-o1和DeepSeek-R1,展示了令人印象深刻的长期推理能力。 然而,他们对静态内部知识的依赖限制了他们在复杂的知识密集型任务上的表现,并阻碍了他们生成需要综合各种网络信息的综合研究报告的能力。 为了解决这个问题,我们提出了WebThinker,这是一个深度研究代理,它使LRM能够在推理过程中自主搜索网络、浏览网页和起草研究报告。 WebThinker集成了Deep Web Explorer模块,使LRM能够在遇到知识缺口时动态搜索、导航和提取网络信息。 它还采用了自主思考、搜索和起草策略,使模型能够实时无缝地交织推理、信息收集和报告撰写。 为了进一步提高研究工具的利用率,我们通过迭代在线直接偏好优化(DPO)引入了一种基于RL的训练策略。 在复杂推理基准(GPQA、GAIA、WebWalkerQA、HLE)和科学报告生成任务(Glaive)上的广泛实验表明,WebThinker的表现明显优于现有方法和强大的专有系统。 我们的方法增强了LRM在复杂场景中的可靠性和适用性,为更强大、更通用的深度研究系统铺平了道路。 代码可在https://github.com/RUC-NLPIR/WebThinker上找到。Huggingface链接:Paper page,论文链接:2504.21776
研究背景和目的
研究背景
随着人工智能技术的快速发展,大型推理模型(Large Reasoning Models, LRMs)在多个领域展现出了卓越的性能,尤其是在数学、代码编写和科学推理等方面。然而,这些模型在面对复杂的信息研究需求时,往往受限于其静态的内部知识,难以进行深入的网络信息检索,并生成全面且准确的科学研究报告。传统的检索增强生成(Retrieval-Augmented Generation, RAG)技术虽然在一定程度上缓解了这一问题,但其固定的检索和生成流程限制了LRMs与搜索引擎之间的深度交互,导致模型在探索更深层次的网络信息时显得力不从心。
当前,学术界和工业界迫切需要一种通用、灵活且开源的深度研究框架,以充分发挥LRMs在复杂现实世界问题解决中的潜力。特别是在知识密集型领域,如金融、科学和工程等,研究人员需要花费大量时间和精力进行信息收集,而一个能够自主进行深度网络探索和报告撰写的系统将极大提升研究效率。
研究目的
本研究旨在提出WebThinker,一个完全由推理模型驱动的开源深度研究框架。WebThinker旨在赋予LRMs自主搜索网络、浏览网页并在推理过程中起草研究报告的能力。通过集成深度网络探索模块(Deep Web Explorer)和自主思考-搜索-起草策略(Autonomous Think-Search-and-Draft Strategy),WebThinker使LRM能够在遇到知识缺口时动态地搜索、导航和提取网络信息,并将信息收集、推理和报告撰写无缝交织在一起。此外,本研究还通过基于强化学习(RL)的训练策略,进一步优化LRMs对研究工具的利用,提升其在复杂推理任务和科学研究报告生成任务中的表现。
研究方法
1. 框架设计
WebThinker框架包含两个主要模式:问题解决模式(Problem-Solving Mode)和报告生成模式(Report Generation Mode)。在问题解决模式下,LRM配备了一个深度网络探索模块,当遇到知识缺口时,可以自主发起网络搜索,并通过点击链接或按钮浏览网页,提取相关信息后再继续推理。在报告生成模式下,LRM除了具备深度网络探索能力外,还集成了起草、检查和编辑报告的工具,使其能够在思考和搜索的同时迭代地撰写全面的研究报告。
2. 深度网络探索模块
深度网络探索模块是WebThinker的核心组件之一,它使LRM能够动态地搜索、导航和提取网络信息。该模块由两个基本工具组成:搜索引擎和导航工具。搜索引擎用于根据生成的查询检索网页,而导航工具则用于与当前查看页面上的元素(如链接或按钮)进行交互。探索模块通过内部的推理链决定是进一步搜索还是深入导航,最终生成一个简洁的输出,以解决主推理链中的知识缺口。
3. 自主思考-搜索-起草策略
在报告生成模式下,WebThinker采用了自主思考-搜索-起草策略,使LRM能够在实时思考和搜索的同时撰写报告。LRM利用起草工具为特定章节撰写内容,利用检查工具查看当前报告状态,并利用编辑工具修改报告。这些工具由一个辅助的LLM实现,确保报告内容的全面性、连贯性和对新见解的适应性。
4. 强化学习训练策略
为了进一步提升LRMs对研究工具的利用能力,本研究采用了基于在线直接偏好优化(DPO)的强化学习训练策略。通过在大规模复杂推理和报告生成数据集上生成多样化的推理轨迹,并利用这些轨迹构建偏好对,训练LRM使其能够根据偏好对优化其推理和工具使用策略。
研究结果
1. 复杂推理任务表现
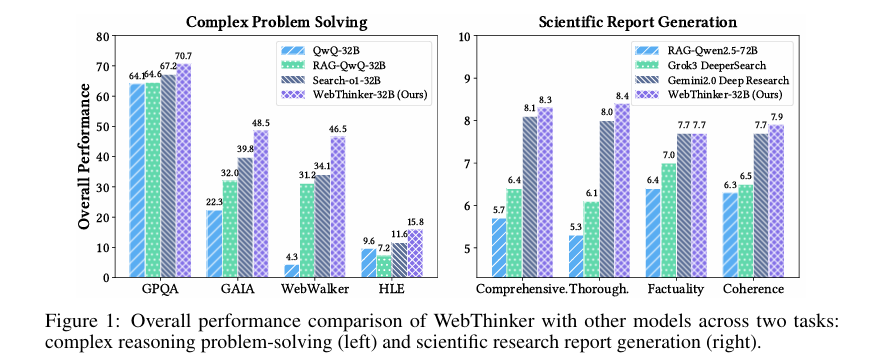
在复杂推理基准测试(如GPQA、GAIA、WebWalkerQA和HLE)上,WebThinker的表现显著优于现有的方法和强大的专有系统。特别是在GAIA和WebWalkerQA等需要深度网络信息检索的任务上,WebThinker通过其深度网络探索模块和自主思考-搜索-起草策略,展现了卓越的性能。与传统的RAG方法相比,WebThinker能够更有效地利用网络信息,生成更准确和全面的答案。
2. 科学研究报告生成表现
在科学研究报告生成任务(如Glaive)上,WebThinker同样表现出色。通过迭代地撰写、检查和编辑报告章节,WebThinker生成的报告在完整性、透彻性、事实性和连贯性方面均优于现有的RAG系统和非专有深度研究系统。特别是其自主思考-搜索-起草策略,使LRM能够在实时思考和搜索的同时撰写报告,确保了报告内容的时效性和准确性。
3. 不同LRM骨干的适应性
本研究还验证了WebThinker在不同LRM骨干上的适应性。通过在DeepSeek-R1系列模型(7B、14B和32B)上进行实验,结果表明WebThinker能够显著提升这些模型在复杂推理和报告生成任务上的表现。这证明了WebThinker框架的通用性和有效性。
研究局限
尽管WebThinker在复杂推理和科学研究报告生成任务上取得了显著成果,但本研究仍存在一些局限性:
-
计算资源需求:WebThinker的训练和推理过程需要较高的计算资源,尤其是在处理大规模数据集和复杂推理任务时。这可能限制了其在资源有限环境中的应用。
-
模型幻觉问题:在报告生成过程中,LRM有时会产生与原文不符的幻觉内容。尽管本研究通过Needleman-Wunsch算法等后处理方法进行了一定的纠正,但这一问题仍未完全解决。
-
数据稀缺性:高质量、公开可用的变音阿拉伯语语料库的稀缺性限制了Sadeed等模型在阿拉伯语变音符号标注任务上的进一步发展。类似地,对于WebThinker而言,特定领域的高质量数据集也可能成为其性能提升的瓶颈。
-
工具使用效率:尽管本研究通过强化学习训练策略提升了LRMs对研究工具的利用能力,但在某些复杂任务上,工具的使用效率仍有待提高。例如,在深度网络探索过程中,如何更有效地选择搜索查询和导航路径仍是一个挑战。
未来研究方向
针对WebThinker的局限性和当前研究的不足,未来的研究可以从以下几个方面展开:
-
优化计算资源利用:探索更高效的算法和模型架构,以减少WebThinker在训练和推理过程中的计算资源需求。例如,可以通过模型剪枝、量化或知识蒸馏等技术来减小模型大小,提高推理速度。
-
减少模型幻觉:研究更有效的后处理方法或训练策略,以减少LRM在报告生成过程中产生的幻觉内容。例如,可以引入更严格的验证机制或利用外部知识库来验证生成内容的准确性。
-
构建高质量数据集:针对特定领域构建高质量的数据集,以进一步提升WebThinker在复杂推理和报告生成任务上的性能。例如,可以与领域专家合作,收集和标注特定领域的高质量问答对和报告样本。
-
提升工具使用效率:研究更智能的工具选择和使用策略,以提高LRM在深度网络探索过程中的效率。例如,可以利用强化学习或元学习等技术来训练LRM,使其能够根据任务需求自动选择最合适的搜索查询和导航路径。
-
多模态推理能力:探索将WebThinker扩展到多模态领域,使其能够处理图像、视频等非文本信息。这将使WebThinker在更广泛的场景中发挥作用,如多媒体信息检索、视觉问答等。
-
用户交互与反馈:研究如何更好地将用户交互和反馈融入WebThinker的推理过程中。例如,可以通过用户反馈来不断优化LRM的推理策略和工具使用方式,提高系统的个性化和适应性。
综上所述,WebThinker作为一个完全由推理模型驱动的开源深度研究框架,在复杂推理和科学研究报告生成任务上展现出了卓越的性能。未来的研究将致力于进一步优化其性能、扩展其应用场景,并解决当前存在的局限性。