【Machine Learning Q and AI 读书笔记】- 04 彩票假设
Machine Learning Q and AI 中文译名 大模型技术30讲,主要总结了大模型相关的技术要点,结合学术和工程化,对LLM从业者来说,是一份非常好的学习实践技术地图.
本文是Machine Learning Q and AI 读书笔记的第4篇,对应原书第四章 《彩票假设》.
TL;DR
本文记录彩票假设,以及相关的权重剪枝技术。
彩票假设
According to the lottery ticket hypothesis, a randomly initialized neural network can contain a subnetwork that, when trained on its own, can achieve the same accuracy on a test set as the original network after being trained for the same number of steps.
根据彩票假设理论,一个随机初始化的神经网络中可能包含一个子网络,当这个子网络单独进行训练时,可以在与原网络相同数量的训练步数后,在测试集上达到与原网络相同的准确率。
训练过程
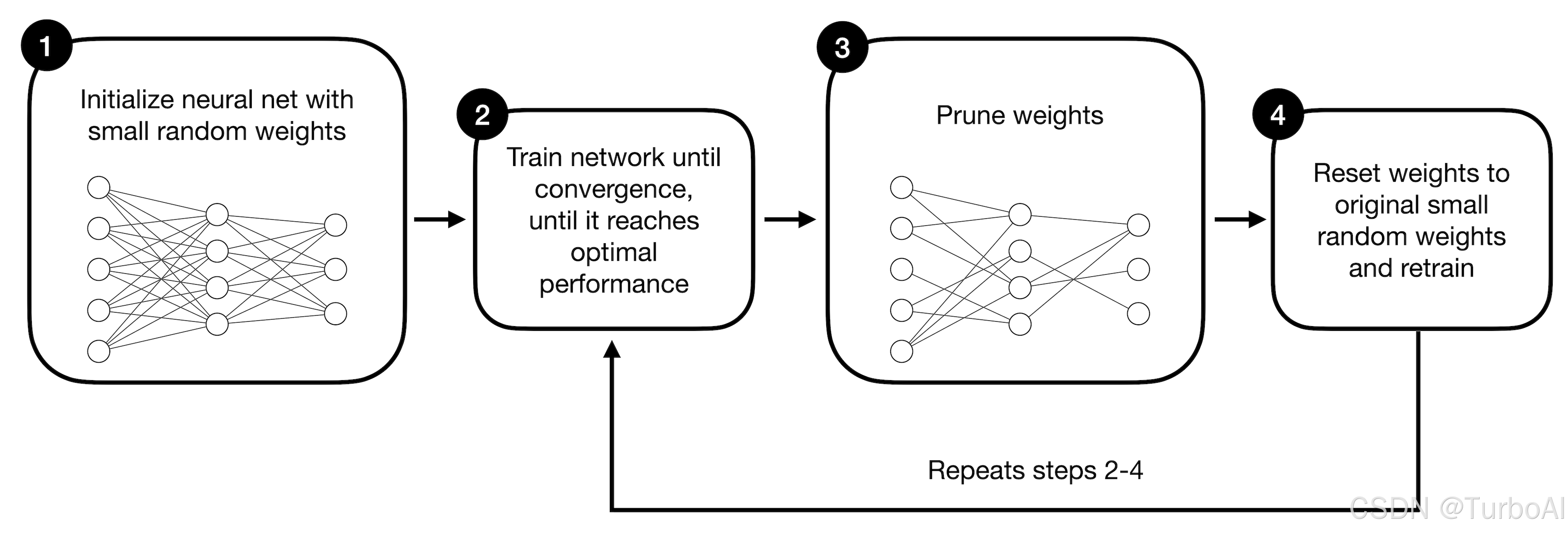
We start with a large neural network (1) that we train until convergence (2), which means that we put in our best efforts to make it perform as best as possible on a target dataset – for example, minimizing training loss and maximizing classification accuracy. This large neural network is initialized as usual using small random weights.
我们从一个大型神经网络(1)开始,将其训练到收敛(2),这意味着我们尽最大努力使其在目标数据集上表现得尽可能好——例如,最小化训练损失并最大化分类准确率。这个大型神经网络是按照常规方法使用小的随机权重进行初始化的。
Next, we prune the neural network’s weight parameters (3), removing them from the network. We can do this by setting the weights to zero to create sparse weight matrices. Which weights do we prune? The original lottery hypothesis approach follows a concept known as iterative magnitude pruning, where the weights with the lowest magnitudes are removed in an iterative fashion.
接下来,我们对神经网络的权重参数进行剪枝(3),将其从网络中移除。我们可以通过将权重设置为零来创建稀疏权重矩阵。那么,我们剪枝哪些权重呢?原始的彩票假设方法遵循一种称为迭代幅度剪枝的概念,即通过迭代方式移除幅度最小的权重。
意义和局限性
However, the good news is that winning tickets do exist, and even if it’s currently not possible to identify these without training their larger neural network counterparts, they can be used for more efficient inference after training.
然而,好消息是“中奖彩票”确实存在,即使目前无法在不训练其更大的神经网络对应物的情况下识别它们,但它们在训练后可以用于更高效的推理。
拓展阅读
笔者速读了彩票假设的原论文: The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks ,
摘要
Neural network pruning techniques can reduce the parameter counts of trained networks by over 90%, decreasing storage requirements and improving computational performance of inference without compromising accuracy. However, contemporary experience is that the sparse architectures produced by pruning are difficult to train from the start, which would similarly improve training performance.
We find that a standard pruning technique naturally uncovers subnetworks whose initializations made them capable of training effectively. Based on these results, we articulate the “lottery ticket hypothesis:” dense, randomly-initialized, feed-forward networks contain subnetworks (“winning tickets”) that - when trained in isolation - reach test accuracy comparable to the original network in a similar number of iterations. The winning tickets we find have won the initialization lottery: their connections have initial weights that make training particularly effective.
We present an algorithm to identify winning tickets and a series of experiments that support the lottery ticket hypothesis and the importance of these fortuitous initializations. We consistently find winning tickets that are less than 10-20% of the size of several fully-connected and convolutional feed-forward architectures for MNIST and CIFAR10. Above this size, the winning tickets that we find learn faster than the original network and reach higher test accuracy.
神经网络剪枝技术可以将训练后的网络参数数量减少超过90%,在不降低准确率的情况下,降低存储需求并提高推理的计算性能。然而,当下的经验表明,剪枝产生的稀疏架构从一开始就很难训练,而这本可以类似地提升训练性能。
我们发现,一种标准的剪枝技术自然地揭示了那些由于其初始权重而能够有效训练的子网络。基于这些结果,我们提出了“彩票假设”:密集的、随机初始化的、前馈网络中包含子网络(“中奖彩票”),这些子网络在单独训练时,能够在类似的迭代次数内达到与原始网络相当的测试准确率。我们发现的中奖彩票赢得了初始化的“彩票”:它们的连接具有初始权重,使得训练特别有效。
我们提出了一种识别中奖彩票的算法,并通过一系列实验来支持彩票假设以及这些幸运的初始化的重要性。我们始终能够找到小于10%-20%的全连接和卷积前馈架构(针对MNIST和CIFAR10)的中奖彩票。在超过这个比例的大小时,我们发现的中奖彩票比原始网络学习得更快,并且能够达到更高的测试准确率。
主要工作
-
中奖票据的发现:研究表明,通过剪枝(pruning)技术,可以发现那些在训练初期就具备良好学习能力的稀疏子网络,这些子网络在一定条件下能够达到与原始网络相当的测试准确率。
-
提高训练性能:这些中奖票据能够在较少的迭代次数内达到与原始网络相似的准确率,且在学习速度上超越原始网络。这一发现暗示通过较早的剪枝和训练策略,可以有效提升训练性能。
-
设计新网络:研究表明,中奖票据展示了一些稀疏架构和初始化的组合特性,这些特性有助于提高学习效果。这为新架构和初始化方案的设计提供了灵感,鼓励探索那些在不同任务上同样有效的策略。
总结
本笔记简要记录彩票假设和训练的方法,并附上原论文的主要工作。