Hystrix与Sentinel-熔断限流
Hystrix与Sentinel-熔断限流
Hystrix(Netflix开源,目前处于维护模式)和 Sentinel(阿里巴巴开源,活跃开发)都是微服务架构中处理服务容错和系统保护的核心组件,旨在提高系统的弹性(Resilience)。
虽然目标相似(熔断、降级、限流),但它们在设计理念、实现机制、实时性、资源模型等方面存在显著差异。下面详细对比它们的区别和原理:
一、核心区别总结表
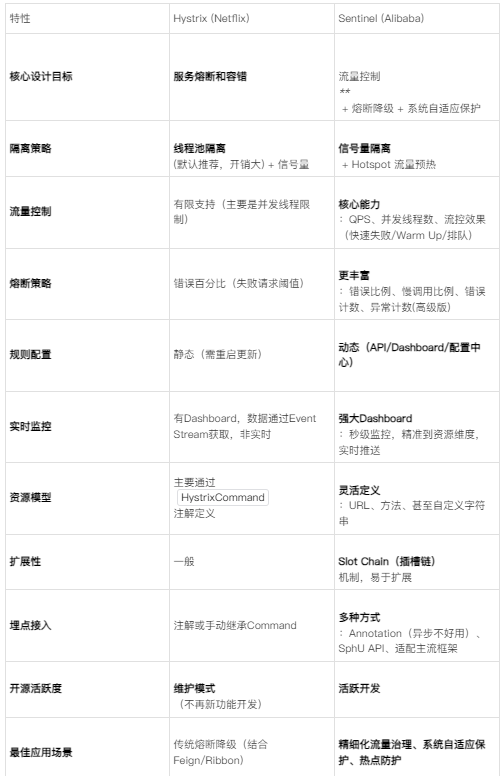
二、核心原理详解
- Hystrix 原理
Hystrix 的核心是 “避免级联故障”,通过隔离、熔断、降级和监控来实现。
-
隔离 (Isolation):
-
线程池隔离 (Thread Pool Isolation - 默认): 对依赖服务的调用分配到独立的线程池执行。即使某个依赖服务线程池耗尽或超时,也不会影响到调用该依赖服务的上游线程(通常是Tomcat线程)。
-
优点: 隔离彻底,支持超时控制(依赖线程中断)。
-
缺点: 线程上下文切换开销大,资源消耗高(每个依赖需要单独线程池)。
-
信号量隔离 (Semaphore Isolation): 使用信号量控制对依赖服务的并发调用数量。在调用线程(如Tomcat线程)上直接执行依赖调用,通过信号量计数器限制最大并发数。
-
优点: 轻量级,开销极小。
-
缺点: 不支持超时控制(因为调用发生在Tomcat线程内,无法中断阻塞的IO操作),不隔离超时问题。
-
熔断 (Circuit Breaking):
-
基于滑动时间窗口统计指标(默认10秒窗口,分成10个桶,每秒滚动)。
-
主要监控错误率(errorPercentageThreshold)或失败请求次数。
-
当满足熔断条件(如10秒内错误率超过50%或请求量达到阈值且失败超半数)时,熔断器开启(Open)。
-
Open状态下,所有请求快速失败,执行降级逻辑(Fallback)。
-
经过一定熔断时间(sleepWindowInMilliseconds)后,熔断器进入半开(Half-Open)状态,允许少量试探请求通过。若这些请求成功,熔断器关闭(Closed);若失败,重新回到Open状态。
-
降级 (Fallback):
-
当命令执行失败(超时、异常、熔断开启、线程池/信号量拒绝)时,执行预先定义的降级逻辑(如返回缓存值、静态值、友好提示),避免调用者长时间等待或资源耗尽。
-
监控 (Metrics and Monitoring):
-
收集命令执行的关键指标(成功率、熔断状态、线程池状态、请求延迟等)。
-
通过hystrix.stream暴露度量数据(SSE)。Hystrix Dashboard单独部署,消费这些流数据进行可视化展示。
-
缺点: 非实时,数据获取有一定延迟,监控粒度和灵活性不如Sentinel。
- Sentinel 原理
Sentinel的核心是面向流量,围绕资源的实时状态,制定动态规则进行流量控制和熔断降级,目标是保障服务稳定性。
-
资源与统计 (Resource & Statistics):
-
资源 (Resource): Sentinel保护的目标对象。它可以是一个URL、一个方法、一个服务调用,甚至是一段代码块(用@SentinelResource注解或SphU.entry() API定义)。
-
Slot Chain (插槽链): Sentinel功能的核心实现机制。 对资源的每次访问 (entry) 都会经过一个由多个ProcessorSlot组成的责任链处理。这些Slot按顺序执行不同的处理逻辑:
-
NodeSelectorSlot: 负责资源维度的调用路径统计树(ClusterNodeBuilder)。
-
ClusterBuilderSlot: 创建资源对应的ClusterNode,存储聚合统计信息(RT、QPS、Thread count等)。
-
StatisticSlot: 核心统计Slot,统计实时的调用数据(QPS, RT, 线程数,错误数等),为后续规则判断提供基础。
-
AuthoritySlot: 校验来源(origin)的授权规则(黑白名单)。
-
SystemSlot: 检查系统保护规则(CPU、负载、全局QPS等)。
-
ParamFlowSlot: 热点参数限流(控制单个值如特定用户ID的流量)。
-
FlowSlot: 验证流量控制规则。
-
DegradeSlot: 验证熔断降级规则。
-
LogSlot: 发生限流/降级事件时记录日志。
-
(SentinelResourceAspect处理@SentinelResource的fallback和blockHandler通常不在此链中)
-
流量控制 (Flow Control):
-
Sentinel的核心强项之一。基于实时统计数据(QPS/并发线程数),针对不同流量控制场景提供了丰富的策略:
-
阈值类型: QPS 或 并发线程数。
-
流控模式:
-
直接: 针对当前资源本身限制。
-
关联: 当关联资源达到阈值,限流当前资源(用于处理应用层争抢)。
-
链路: 只统计指定调用入口(EntryPoint)到这个资源的流量并限流。
-
流控效果:
-
快速失败: 直接抛FlowException。
-
Warm Up (预热/冷启动): 让流量缓慢增加到阈值,避免冷系统瞬间被压垮。
-
排队等待 (Rate Limiter): 将请求排队,以恒定速率通过(类似令牌桶)。
-
熔断降级 (Circuit Breaking & Degradation):
-
Sentinel的另一个核心能力,提供比Hystrix更精细的熔断策略:
-
慢调用比例 (SLOW_REQUEST_RATIO): 请求响应时间(RT)大于设定慢调用阈值的比例超过阈值时熔断。
-
异常比例 (ERROR_RATIO): 单位统计窗口内,异常调用的比例超过阈值时熔断(类似Hystrix)。
-
异常数 (ERROR_COUNT): 单位统计窗口内,异常调用的数量超过阈值时熔断。
-
高级规则 (如Ahas, 商业版SAE): 支持基于特定异常类型的熔断(如NullPointerException)。
-
提供多种降级方式(手动配置blockHandler/fallback或在规则中指定跳转URL)。
-
系统自适应保护 (System Rule):
-
Sentinel独有的全局维度保护。根据系统的实时指标(如全局QPS、平均RT、系统负载Load、CPU使用率、并发线程数)动态调整入口流量,防止雪崩,保障整体稳定性。系统繁忙时自动削峰填谷。
-
热点参数限流 (Parameter Flow Control):
-
对包含热点参数(例如商品ID、用户ID) 的调用进行细粒度限流(如限制特定商品ID每秒钟的查询次数)。普通的流量控制无法实现这种维度的控制。
-
实时监控与控制台 (Real-time Monitoring & Dashboard):
-
Sentinel 最强大的优势之一。
-
控制台 (Dashboard): 提供秒级实时监控,清晰展示每个资源的流量、QPS、RT、线程数、异常比例、熔断状态、调用链路(支持链路流控模式调试)等关键信息。
-
动态规则推送: 控制台修改的规则通过(需要配置规则源如Nacos, Apollo, Zookeeper, File)实时推送到所有接入Sentinel的应用程序,无需重启应用。
-
调用链查询: 查看资源调用的详细路径,辅助定位问题和配置链路流控。
三、如何选择? -
选择 Hystrix 如果:
-
项目已经广泛使用且运行稳定,暂时没有更换的迫切需求。
-
核心需求是基本的服务熔断和降级,特别是配合Spring Cloud Feign/Ribbon使用时。
-
不介意它的局限性(资源消耗高、监控非实时、动态配置难、缺少精细流量控制)。
-
对引入新开源库(Sentinel)的成本有顾虑(但Sentinel接入其实也很方便)。
-
强烈建议选择 Sentinel 如果:
-
需要精细化的流量控制能力(特别是QPS控制、预热、排队)。
-
需要热点参数限流(如电商促销场景)。
-
需要强大的系统自适应保护能力(防止系统整体雪崩)。
-
对实时监控和告警有高要求(秒级监控看板是巨大优势)。
-
需要动态更新规则,不用重启应用。
-
追求更轻量级、高性能的隔离策略。
-
系统对资源消耗敏感。
-
希望使用一个功能更全面、生态活跃的现代化流量治理组件。
-
对阿里系中间件生态较熟悉。
总结
Hystrix 是服务熔断降级领域的先驱,为微服务稳定性奠定了基础。而 Sentinel 是更强大的继任者,它不仅涵盖了 Hystrix 的核心功能(熔断降级),更是在流量控制、系统保护、实时监控、动态规则等方面进行了革命性的增强,提供了更全面的服务稳定性保障方案。 考虑到 Hystrix 已进入维护模式,Sentinel 的活跃开发和社区支持,对于新项目或需要进行深度流量治理的项目,Sentinel 是当前(2024年)更优的选择。Sentinel 的理念代表着服务治理从单一的服务保护向更全面的“面向流量”治理演进的方向。
能否给出实际使用 Sentinel的案例?
好的,下面提供几个实际使用 Sentinel 的典型业务场景案例,涵盖其核心功能(流量控制、熔断降级、热点参数限流、系统保护),并给出关键配置/代码思路:
案例一:电商秒杀 - 热点商品防护 & 总流量控制
- 场景: 电商平台进行热门商品(如 iPhone)的限时秒杀活动。瞬时超大流量涌入,极易导致:
a.该商品的查询、下单接口被瞬间打垮。
b.数据库或缓存被压垮。
c.整个应用服务器资源耗尽(CPU/线程),影响其他正常业务。
- Sentinel 解决方案:
a.热点参数限流 (ParamFlowRule):
-
资源: 商品查询接口 (如 /api/product/detail/{productId}) 和 下单接口 (如 /api/order/create)。
-
规则:
-
ParamFlowRule(资源名)
-
paramIdx = 0 (假设商品ID productId 是方法的第一个参数)
-
grade = RuleConstant.FLOW_GRADE_QPS (基于QPS控制)
-
paramKey = 热点参数值 (如 “iphone_15_pro_max”)
-
count = 1000 (限制这个 特定商品 的查询/下单总QPS为1000)
-
behavior = RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER (排队等待) + maxQueueingTimeMs = 500 (最多排队500毫秒) OR behavior = RuleConstant.CONTROL_BEHAVIOR_DEFAULT (快速失败)。
-
效果: 防止少数几个超热商品(如新品首发)占用所有资源,确保其他商品和系统整体稳定。
b.接口总QPS限流 (FlowRule): -
资源: /api/product/detail/{productId} (查询), /api/order/create (创建订单)。
-
规则:
-
FlowRule(资源名)
-
grade = RuleConstant.FLOW_GRADE_QPS
-
count = 5000 (限制该接口 所有商品 的总QPS为5000)
-
controlBehavior = RuleConstant.CONTROL_BEHAVIOR_WARM_UP (预热) + warmUpPeriodSec = 10 (10秒预热到5000 QPS) OR RuleConstant.CONTROL_BEHAVIOR_DEFAULT (快速失败)。
-
效果: 控制整个接口的总流量,避免超出系统处理能力。
c.降级策略 (DegradeRule - 可选备用): -
资源: /api/product/detail/{productId}
-
规则 (慢调用熔断):
-
DegradeRule(资源名)
-
grade = RuleConstant.DEGRADE_GRADE_RT (基于慢调用比例)
-
count = 100 (慢调用阈值RT=100ms)
-
timeWindow = 10 (统计窗口10秒)
-
slowRatioThreshold = 0.5 (慢调用比例超过50%)
-
minRequestAmount = 20 (最小请求数20)
-
statIntervalMs = 1000 (秒级统计)
-
效果: 当商品详情查询因为下游服务(如缓存、库存服务)变慢,导致响应时间普遍超过100ms时,Sentinel自动熔断对该接口的访问一段时间,直接返回静态信息或降级页面(如“系统繁忙,请稍后查看”),避免线程堆积拖垮整个服务器。
d.系统自适应保护 (SystemRule): -
规则:
-
SystemRule(整个应用)
-
highestSystemLoad = 8 (当系统Load > 8 时触发保护)
-
qps = 1500 (或者 maxThread = 1000) OR avgRt = 500 (RT > 500ms)
-
highestCpuUsage = 0.9 (CPU > 90%)
-
效果: 当系统负载(Load)、整体QPS、平均RT或CPU达到危险阈值时,Sentinel自动拒绝部分外部新请求(blocked by Sentinel (system limit)),优先保障系统不崩溃,保护内部已有服务的处理能力。
案例二:支付核心链路保障 - 熔断降级 & 链路流控 -
场景: 支付服务 pay-service 依赖于风控服务 risk-service。风险控制至关重要,但偶尔可能因为网络抖动或风控自身过载导致高延迟或失败。
-
目标:必须确保支付主流程(/api/pay/create)的绝对稳定。
-
需求:即使风控服务偶尔不稳定或变慢,也不能导致大量支付请求堆积在支付服务上造成级联故障。
-
Sentinel 解决方案:
a.链路流控 (FlowRule - 链路模式):
-
入口资源: ApiPayment.createOrder() (支付核心入口)
-
调用关系: ApiPayment.createOrder() -> RiskService.check() (调用风控)
-
规则:
-
FlowRule(资源名 = “RiskService.check()”)
-
grade = RuleConstant.FLOW_GRADE_THREAD OR FLOW_GRADE_QPS
-
count = 50 (限制从 支付主入口 发起的对 RiskService.check() 的最大并发线程数或QPS)
-
strategy = RuleConstant.STRATEGY_CHAIN (链路模式)
-
refResource = “ApiPayment.createOrder()” (关联到调用入口资源)
-
效果: 限定 仅由支付核心链路 使用的风控资源配额。即使其他非关键路径也调用风控服务,也不会影响支付主链路的配额,保证了支付核心的可用性。同时避免了大量支付请求因等待风控结果而耗尽支付服务线程。
b.熔断降级 (DegradeRule): -
资源: RiskService.check() (依赖的资源)
-
规则 (异常比例熔断):
-
DegradeRule(资源名)
-
grade = RuleConstant.DEGRADE_GRADE_EXCEPTION_RATIO
-
count = 0.6 (异常比例阈值60%)
-
timeWindow = 5 (5秒熔断窗口)
-
minRequestAmount = 10 (最小请求数10)
-
降级处理:
-
在支付服务调用风控的代码处,使用 @SentinelResource:
@SentinelResource(value = “RiskService.check()”,
blockHandler = “handleBlock”, // FlowSlot限流处理
fallback = “handleFallback”) // DegradeSlot熔断/异常处理
public RiskResult checkPaymentRisk(PaymentRequest req) {
// 调用远程risk-service
}
public RiskResult handleBlock(PaymentRequest req, BlockException ex) {
// 流控触发:可记录日志,返回一个“快速风控通过”标识或特定错误码
log.warn(“风控限流触发,降级处理”, ex);
return RiskResult.PASS_TEMPORARY; // 假设临时标记为通过
}
public RiskResult handleFallback(PaymentRequest req, Throwable t) {
// 熔断触发或业务异常:记录日志,返回降级结果
log.error(“风控调用异常或熔断,降级处理”, t);
return RiskResult.PASS_TEMPORARY;
}
-
效果:
-
当风控服务不稳定,错误率达到60%时,Sentinel熔断对它的调用(进入handleFallback)。
-
在降级逻辑中,我们可以策略性地放行支付请求(例如,针对小额或低风险业务继续支付,对大额或高风险支付则提示稍后再试),牺牲一部分风控准确性,换取支付核心链路的整体可用性。熔断器恢复后,恢复正常风控调用。
-
流控逻辑(handleBlock)也能在调用量过大时提供一层保障。
案例三:三方接口依赖保护 - 限流 & 线程隔离 -
场景: 内容服务 content-service 需要调用一个外部供应商的短信发送接口 /external/sms/send。
-
问题:该外部接口QPS配额有限(如200 QPS),且稳定性无法保证。
-
风险:如果内容服务突发大量短信发送请求,可能导致:
i.超过外部配额被拒绝。
ii.外部接口响应变慢甚至不可用。
iii.内容服务调用线程被大量阻塞等待外部响应,进而影响内容服务的其他核心功能(如文章发布、审核)。
- Sentinel 解决方案:
a.精确QPS限流 (FlowRule):
-
资源: /external/sms/send (定义的资源名)
-
规则:
-
FlowRule(资源名)
-
grade = RuleConstant.FLOW_GRADE_QPS
-
count = 200 (严格限制200 QPS,不超配额)
-
controlBehavior = RuleConstant.CONTROL_BEHAVIOR_DEFAULT (快速失败)
-
效果: 硬性限制调用频率,防止超过配额。
b.信号量隔离 (Sentinel默认): -
Sentinel 默认通过信号量控制资源并发。我们无需特殊配置隔离策略(不像Hystrix线程池)。
-
资源: /external/sms/send
-
隐含规则: 每次调用都向Sentinel申请信号量许可,许可数由Sentinel内部管理(与流控规则结合)。如果并发请求数超过阈值,后续请求快速失败(Block)。
-
效果: 外部慢调用只会占用请求线程一小段时间(直到获取信号量失败或请求发出),并不会阻塞业务线程池中处理其他内容的线程,保护自身服务免受下游拖累。如果配置了QPS限流,天然具备并发控制能力。
c.熔断降级 (DegradeRule): -
资源: /external/sms/send
-
规则 (慢调用熔断):
-
grade = RuleConstant.DEGRADE_GRADE_RT
-
count = 3000 (RT 3秒)
-
timeWindow = 60 (熔断60秒)
-
slowRatioThreshold = 0.8 (80%请求 > 3s)
-
效果: 当外部接口普遍响应极慢时(可能是其自身故障),Sentinel主动熔断,让短信发送降级(如记录日志,稍后异步重试或提示用户重试),避免大量无用等待。
关键实施步骤总结 (简化版):
1.引入依赖: 在项目的pom.xml中添加Sentinel Core、Spring Cloud Alibaba Sentinel等依赖。
2.定义资源: -
关键方法使用 @SentinelResource(value = “resourceName”, blockHandler/functions) 注解。
-
或通过 SphU.entry(“resourceName”) / try (Entry entry = SphU.entry(“resourceName”)) { … } API方式。
3.配置规则: -
动态 (推荐): 集成Nacos/ZK/Apollo作为规则数据源。在Sentinel Dashboard 上配置规则,规则自动推送到所有应用实例。
-
静态: 在应用启动时通过代码加载 (FlowRuleManager.loadRules(List), DegradeRuleManager.loadRules(…))。可用于初始化默认规则或做兜底,但不够灵活。
4.实现降级逻辑: 在 blockHandler / fallback 方法或 Sentinel ExceptionHandler 中编写限流/熔断/异常时返回的友好结果(缓存值、默认值、错误提示)。
5.部署 & 接入 Dashboard: -
部署 Sentinel Dashboard。
-
配置应用连接Dashboard (sentinel.transport.port/dashboard)。
6.监控与调整: 在Dashboard实时查看各资源流量、规则状态、系统指标。根据线上实际情况调整规则阈值。配置告警规则(对接钉钉、邮件等)。
Sentinel Dashboard 价值凸显:
在这些案例中,Dashboard 提供了 秒级实时监控,让你可以清晰看到: -
/api/product/detail/{X} 资源的总QPS、不同热点参数的详细统计、是否触发限流。
-
RiskService.check() 的调用来源分布、RT、异常率、是否熔断。
-
/external/sms/send 的并发数、成功率、规则状态。
-
整个应用的CPU、Load、线程数、全局QPS,是否触发系统保护。
-
方便地进行规则动态调整和链路查看。
总结:
Sentinel 的核心价值在于其 面向流量 的治理能力和 实时动态 的规则引擎。这些案例展示了它如何用于: -
保障核心业务链路:通过链路流控、熔断降级。
-
防护突发流量:通过QPS限流、预热、排队。
-
应对热点访问:通过热点参数限流。
-
保护系统整体稳定:通过系统规则防护。
-
隔离故障依赖:通过信号量隔离和熔断。
相较于 Hystrix,Sentinel 提供了更精细、更灵活、更实时、更轻量级的解决方案,是现代微服务和云原生应用中系统高可用的关键基础设施之一。其 Dashboard 极大地提升了治理效率和问题排查速度。
Sentinel 在开发中实际可能遇到的问题?
在开发和生产环境中使用 Sentinel 时,虽然其功能强大灵活,但也可能遇到一些特定的挑战和问题。以下是一些 实际开发中可能遇到的痛点、坑点及应对方案:
一、规则管理问题
1.规则配置错误导致失效/过度拦截:
- 问题描述: 在 Dashboard 动态修改规则时,参数理解错误(如将 QPS 阈值误设为并发线程数)、流控模式/效果选择错误、资源名拼写错误,导致规则无效或流量被过度限制。
- 应对:
- 严格代码评审: 规则上线前 Review。
- 预发环境测试: 在预发环境模拟流量验证规则效果。
- 灰度发布规则: 通过配置中心灰度推送规则到少量实例。
- 监控告警: 配置核心接口 QPS、BlockQPS、异常率告警,快速发现异常。
2.规则来源切换不稳定: - 问题描述: 应用从 文件规则源 切换(重启生效)迁移到 Nacos/ZK(动态生效)时,可能会短暂出现规则加载竞争,导致规则丢失或冲突。
- 应对:
- 做好过渡: 先通过 Dashboard 将规则同步到配置中心,再修改应用配置指向配置中心。避免手动维护两套规则。
- 兜底本地文件: 配置中心故障时自动回退到本地规则 (file:
)。
3.集群限流配置管理复杂: - 问题描述: 集群限流 (Token Server模式) 需要独立部署 Token Server 节点,并处理其高可用、配置同步和扩容问题。
- 应对:
- 大型稳定业务才使用集群限流。中小业务优先用单机限流。
- 使用 Nacos/Etcd 作为 Token Server 的注册中心, 解决节点发现。
- Token Server 高可用: 至少部署2个节点。
二、资源定义问题
1.资源名冲突或不规范:
- 问题描述:
- 团队中不同开发者对同一资源使用不同命名 (如 GET:/api/user, UserService.getUserById, com.xxx.UserController#getUser), 造成规则无法统一管理。
- 资源名包含动态参数 (如 DELETE:/user/{id}), 误对单个资源限流 (此时需热点规则)。
- 应对:
- 定义明确规范: 强制统一资源名格式 (如 HTTP_METHOD:FullPath, ClassName#methodName)。
- 使用 AOP 切面统一包装资源名: 避免开发随意命名。
- 对含路径参数的资源,默认按统一资源名创建限流规则,明确区分普通流控规则与热点规则。
三、依赖与集成问题
1.Spring Cloud Gateway/WebFlux 支持细节坑:
- 问题描述:
- 响应式异步场景限流不准: WebFlux中线程模型不同,传统 ThreadLocal 变量丢失,需依赖 reactor context 传递。
- Gateway 路由级别的限流: 默认 Sentinel Starter 可能只识别 “Fallback” Route ID,需定制代码才能按路由ID限流。
- 应对:
- Gateway集成务必用 spring-cloud-alibaba-sentinel-gateway 组件。
- 手动传递 Context: 在 WebFlux 中通过 SentinelReactorTransformer 传递资源名。
2.Feign 熔断降级冲突: - 问题描述:
- 同时启用 Sentinel + Hystrix (通过 feign.circuitbreaker.enabled=true), Sentinel的流控异常可能被 Hystrix 包裹,导致 @SentinelResource 的 fallback 不触发。
- 应对:
- 不要混用! 使用 Sentinel 时彻底关闭 Hystrix (feign.circuitbreaker.enabled=false)。
3.与 Spring Boot Actuator 冲突: - 问题描述:
- Sentinel 可能拦截 /actuator/** 端点,导致健康检查失败。
- 应对:
- 配置 SentinelWebAutoConfiguration 排除对 Actuator 端点的保护:
spring:
cloud:
sentinel:
filter:
# 排除 Actuator 端点
url-patterns: /api/,/auth/,/your-public-urls/**
# 或加特定排除规则
excluded-urls: /actuator/**
四、流量计算与准确性
1.预热(Warm Up)时间计算不准:
- 问题描述:
- 若 warmUpPeriodSec 设置时间过长,系统可能长时间低负载运行;设置过短,预热效果不足。
- 突发流量场景下效果不佳: 限流曲线过于平滑,无法应对小高峰。
- 应对:
- 结合压测数据设置预热时间和初始阈值。
- 流量陡增场景下,改用排队等待(CONTROL_BEHAVIOR_RATE_LIMITER)模式。
2.热点限流参数提取失败: - 问题描述:
- @SentinelResource 的 args 参数识别依赖 编译时保留参数名 (-parameters 编译选项)。
- 对象参数 (如 User user) 中需指定成员变量 (ParamFlowRule.paramKey 指定为 user.id) —— 可能无法识别。
- 应对:
- 确保编译参数带 -parameters (Spring Boot 默认支持)。
- 封装参数提取逻辑: 使用 SphU.entryWithArgs(resource, args) API + 自定义 ParamFlowSlot 处理嵌套对象。
五、异常处理和上下文丢失
1.业务异常统计不准确:
- 问题描述:
- Sentinel 默认仅统计 Throwable 异常。若业务自定义异常被 try-catch 未抛出至 Sentinel, 不会触发熔断统计。
- 应对:
- 手动 **Tracer.trace(ex)** 记录异常。
- 使用 ContextUtil.runOnContext 确保 Exit Hook 执行。
2.异步调用链上下文丢失: - 问题描述:
- 异步任务中,无法关联父线程的 Sentinel Context,导致子任务限流失效。
- 应对:
- 使用 AsyncEntry:java try (AsyncEntry entry = SphU.asyncEntry(resourceName)) { // 异步任务逻辑 entry.onError(e); //手动通知异常 }
- 跨线程传递 Context: 通过 Runnable/Callable 包装任务。
六、监控与排查困难
1.Dashboard 数据不够实时/有延迟:
- 问题描述:
- 生产实例数多、指标量大时,Dashboard 聚合显示可能存在 3-10s 延迟。对突发限流无法立即查看到。
- 应对:
- 结合业务日志: 日志输出 Block 记录 (BlockException 记录资源名)。
- 暴露 Metrics 端点: 接入 Prometheus + Grafana,实现秒级监控。
2.原始日志文件过大: - 问题描述:
- 如果开启了 csp.sentinel.log.output.file 输出详细日志,日志文件会急剧增大。
- 应对:
- 限制日志级别: 生产环境用 warn 级别。
- 使用 Logback/Log4j2 按日切割日志 + 自动清理。
3.限流熔断根因定位难: - 问题描述: 当接口响应慢或被拒绝时,难以区分是 下游熔断、限流触发 还是 系统规则保护 导致。
- 应对:
- 清晰的响应码设计: HTTP 429 (限流) vs HTTP 503 (熔断) vs HTTP 509 (系统保护)。
- ErrorMsg 信息: 在 blockHandler 中返回详细信息 (“被流量控制规则拦截”,“下游服务熔断”)。
七、其它高级坑点
1.Agent 方式接入导致 ClassLoader 冲突:
- 问题描述: 通过 Java Agent (如 -javaagent:/sentinel-agent.jar) 接入 Sentinel 可能引起多应用部署时 ClassLoader 冲突 (如 Tomcat)。
- 应对:
- 优先选择 Starter Jar 依赖方式。
- 使用独立容器部署应用 (Docker)。
2.动态规则更新引发短暂抖动: - 问题描述: 大规模推送规则更新时 (1000+规则),服务端短暂增加CPU负载,极端情况出现请求延迟。
- 应对:
- 避免一次推送海量规则。
- 分批次灰度推送。
关键总结:避坑最佳实践
问题类型关键解决策略规则配置错误代码评审 + 预发测试 + 监控告警 + 灰度发布资源名混乱团队规范统一 + AOP 切面强制包装依赖集成冲突避免混用框架(Hystrix) + 排除健康检查端点流量计算不准压测校准参数 + 根据业务选择模式(WarmUp/RateLimiter)异常处理失效手动Tracer.trace(ex) + AsyncEntry保证上下文监控定位困难清晰状态码 + 结合日志链路追踪 + Prometheus集成动态规则抖动小批量灰度推送 + Token Server集群化部署热点参数提取失败开启编译参数-parameters + 自定义slot扩展解析
💡 核心建议:
undefined.重视理解原理:深刻理解 FlowSlot / DegradeSlot / StatisticSlot 工作原理;
undefined.强化监控告警:实时监控 BlockQPS 和熔断状态;
undefined.预生产环境验证:所有规则在生产生效前需模拟流量;
undefined.建立团队规范:统一资源命名、规则模板、降级策略;
undefined.逐步灰度应用:先在小流量服务试点,稳定后逐步推广。
尽管有潜在问题,通过合理设计和规范操作,Sentinel 仍是当前微服务流量治理的最佳工具之一。提前了解这些“坑”能极大提升应用稳定性!