MySQL数据库——事务、索引和视图
目录
前言
一、事务:数据世界的“保险柜”
1、概述
2、ACID四大特性
3、隔离级别:解决并发冲突
①出现的问题
②解决的方式
二、索引:数据库的“目录”
1、概述
①索引优缺点:
②创建原则:
2、存储引擎
3、索引分类
单列索引
①普通索引
②主键索引
③唯一索引
组合索引(复合索引)
全文索引
三、视图:数据库的“定制窗口”
1、概述
2、优点
3、分类
①简单视图
②复杂视图
4、视图的管理与维护
①查看视图:知道数据库里有哪些视图
②重命名视图:改个更易懂的名字
③修改视图:更新视图的查询逻辑
④删除视图:不用的视图及时清理
5、视图的常用场景
①数据权限控制
②简化复杂查询
③分解复杂查询逻辑
四、数据库优化
1、事务使用建议
2、索引优化
3、查询优化
4、设计优化
前言
在数据库的江湖里
有“三剑客”默默守护着数据安全与查询效率
今天就让我们来看看他们三位怎么个事

一、事务:数据世界的“保险柜”
1、概述
事务就像人一样有“完美主义强迫症”
它不允许出现半吊子情况出现
要么全成功,要么全失败
所以它就是用来应对“操作一般出问题”的情况
事务(Transaction):
由一系列操作组成的一个执行逻辑单元
操作包括:对数据库表中数据进行访问与更新
一些简单注意事项:
- 只有DML语句才会产生事务,其他语句不会产生事务
- DML语句执行的时候,如果当前有事务,那么就使用这个事务。如果当前没有事务,则产生一个新事务
- commit、rollback、DDL语句都可以把当前事务给结束掉
commit和DDL语句:把这个事务给提交了,然后DML操作永久生效
rollback:把这个事务给回滚了,默认回滚到事务开始的状态
- mysql默认是开启事务,即 autocommit = 1,自动提交事务。即执行 insert、update、delete操作,立刻提交。
也就是说,每个SQL语句都被看做一个独立的事务
如果复杂业务需要显示控制事务
可以使用 BEGIN、COMMIT和ROLLBACK语句手动管理事务的生命周期
事务生命周期:
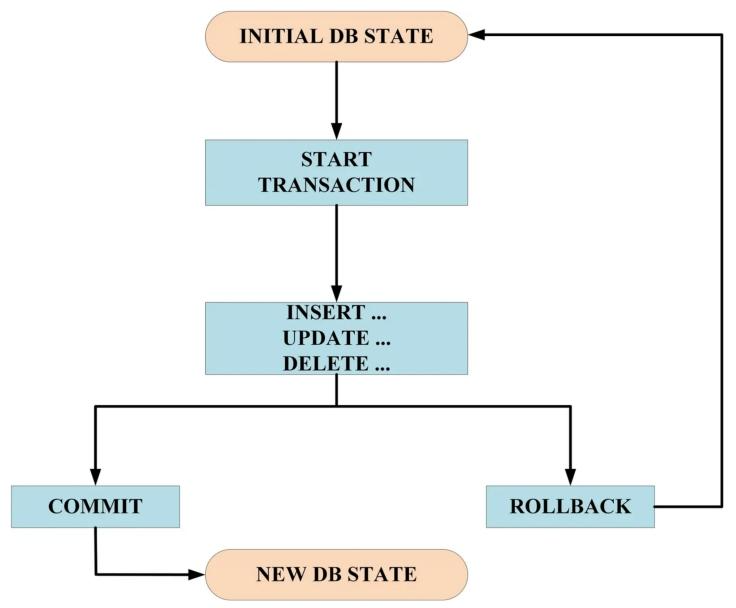
- 开始(BEGIN):事务的生命周期始于BEGIN语句的执行。在开始阶段, MySQL会为该事务分配一个唯一的事务ID,并开始记录事务日志
- 执行(执行SQL语句):在事务开始后,可以执行多个SQL语句,包括插入(INSERT)、更新(UPDATE)、删除(DELETE)等操作。这些操作会在事务日志中进行记录,但并不会立即影响数据库的实际数据
- 提交(COMMIT):当所有SQL语句执行完毕后,可以选择提交事务。提交操作会将事务中的所有修改永久保存到数据库中,并释放相关的锁资源
- 回滚(ROLLBACK):在事务执行过程中,如果发生错误或需要取消之前的修改,可以选择回滚事务。回滚操作会撤销事务中的所有修改,恢复到事务开始前的状态
- 结束(END):事务的生命周期在提交或回滚后结束。结束阶段会释放所有与该事务相关的资源,并关闭事务日志
示例:模拟转账
-- 开启事务
BEGIN; -- 方式1
START TRANSACTION; -- 方式2
SET AUTOCOMMIT=0; -- 方式3:关闭自动提交,后续操作需手动提交-- 执行转账操作
-- 张三扣100(假设张三id=1,李四id=2)
UPDATE t_account SET balance=balance-100 WHERE id=1;
-- 李四加100
UPDATE t_account SET balance=balance+100 WHERE id=2;-- 提交或回滚
-- 没问题就提交,锁死数据
COMMIT; -- 转账成功,数据永久生效
-- 出错就回滚
ROLLBACK; -- 比如李四id输错了,回滚后张三余额不变-- 进阶:设置回滚点
-- 如果事务中有很多操作,想回滚到某个步骤,用SAVEPOINT
BEGIN;
INSERT INTO t_user VALUES(1,'tom',1000); -- 操作1
SAVEPOINT A; -- 设回滚点A
INSERT INTO t_user VALUES(2,'zs',2000); -- 操作2
SAVEPOINT B; -- 设回滚点B
DELETE FROM t_user; -- 操作3(不小心删多了)
ROLLBACK TO A; -- 回滚到A,操作2和3失效,只剩操作1
COMMIT; -- 最终只保存了tom的数据注意事项:
rollback to 回滚点
此时事务并没有结束,可以继续回滚(rollback)或提交(commit)
2、ACID四大特性
事务有四个黄金法则, 根据英文首字母简称 ACID:
- 原子性(Atomicity):操作要么全成功,要么全失败,就像原子一样不可分割
- 一致性(Consistency):事务执行前后,数据库必须保持一致性状态
- 隔离性(Isolation):多个事务并发执行时,彼此之间互不干扰
- 持久性(Durability):一旦事务提交,对数据的改变就是永久的
简单解释一下:
A:比如转账,张三给李四转 100 元,要么张三扣 100、李四加 100,要么都不变(比如断电了),绝不会出现 “张三扣了钱,李四没收到” 的情况
C:转账前两人总余额是 2000,转账后还是 2000,不会多也不会少
I:张三转账时,李四查自己余额,要么看到转账前的数,要么看到转账后的数,绝不会看到 “正在转的中间数”
D:一旦转账成功,就算数据库崩溃,重启后数据还是对的,钱不会凭空消失
3、隔离级别:解决并发冲突
多人同时查改数据,就可能导致以下三大问题(并发冲突):
①出现的问题
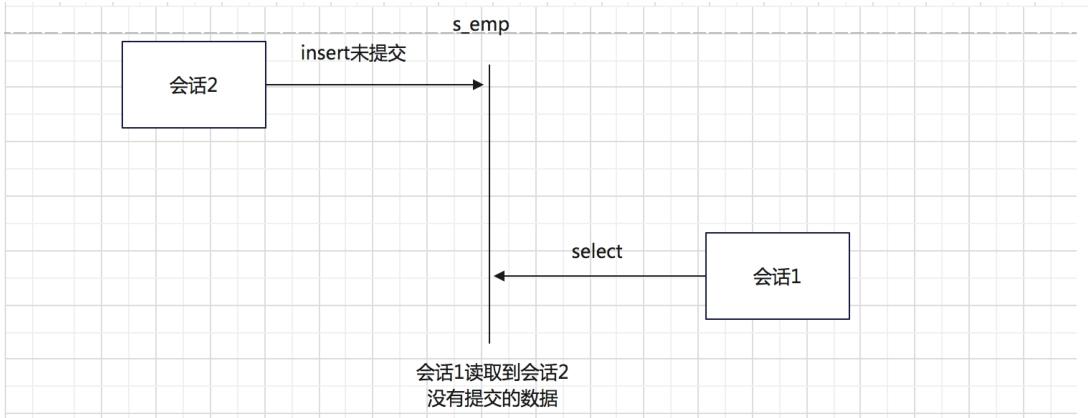
- 脏读
会话1 读到了 会话2 的数据
比如说抄作业
- 小明在写数学作业,写的答案是50(还没提交)
- 你瞟了一看正好看到了
- 结果小明发现写错了,擦掉改成45了
- 但是你知道的还是错误的50
读到了别人还没 COMMIT 的数据

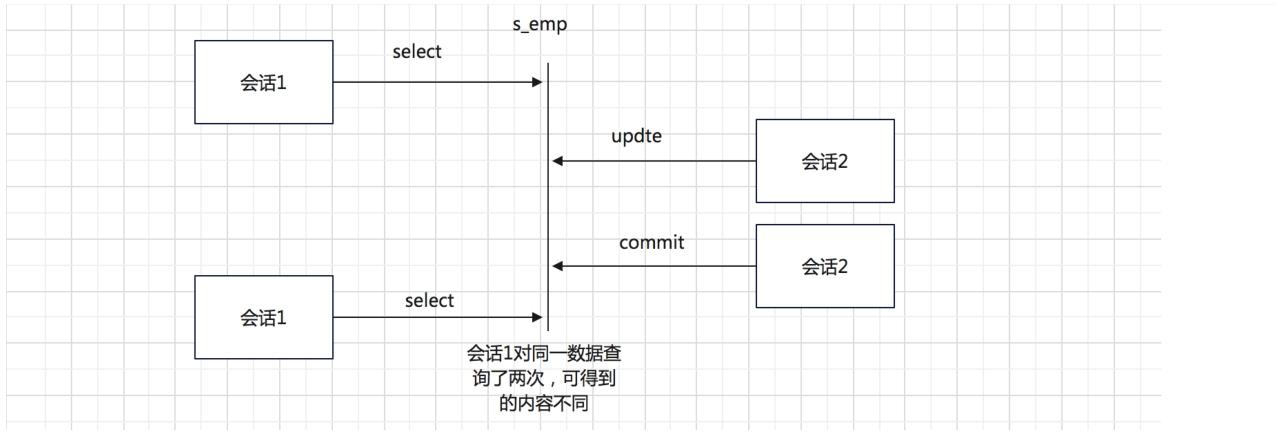
- 不可重复读
在同一事务中,两次读取同一数据,得到内容不同
比如看商品价格:
- 你看中一件衣服标价100元
- 你问售货员多少钱,他说“100元”
- 你觉得有点贵先去别的家看看
- 这时老板过来把价格改为80元
- 你转了一圈回来又问售货员,他说“80元”
- 同一件衣服,你两次问价得到了不同的结果
同一个数据,短时间内查询结果不一样

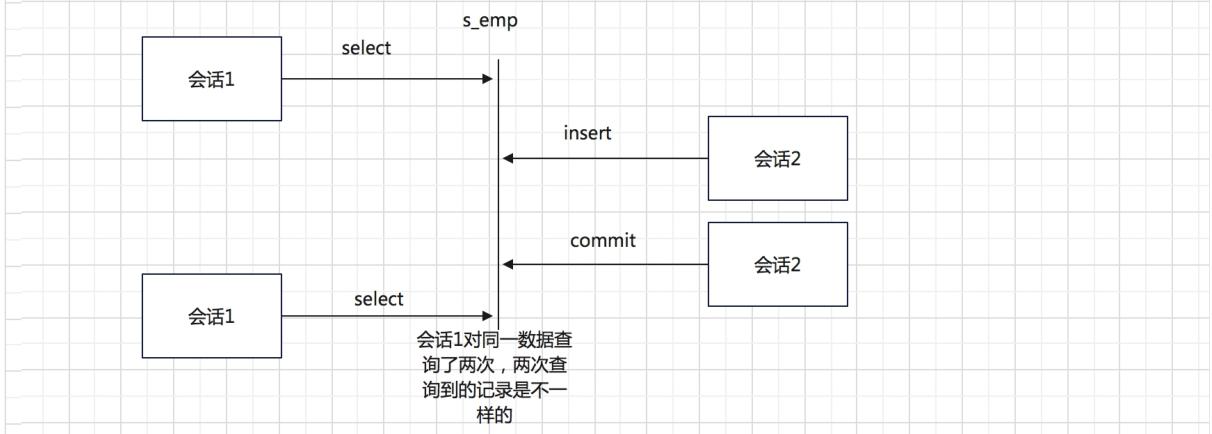
- 幻读
同一事务中,用同样的操作读取两次,得到的记录数不相同
比如大学查课
- 你是学生会查课的同学
- 拿出花名册开始点名
- 点完之后数了一遍来了82个人
- 正准备去汇报时迎面撞上一位拿着咖啡的老师
- 花名册被洒了的咖啡弄的不成样子只能再点一遍
- 但是你没有发现教室后面偷偷溜进来的三位同学
- 重新点完数了一遍变成85个人
- 你很疑惑:诶?我出现幻觉了吗
同样的查询条件,返回的记录数量变了

②解决的方式
MySQL定义了四种隔离级别用来应对上述三种情况:
| 隔离级别 | 脏读(读未提交) | 不可重复读(同一事务查两次结果不同) | 幻读(同一事务查两次记录数不同) |
|---|---|---|---|
| 读未提交(最低) | ✅ 允许 | ✅ 允许 | ✅ 允许 |
| 读已提交 | ❌ 禁止 | ✅ 允许 | ✅ 允许 |
| 可重复读(默认) | ❌ 禁止 | ❌ 禁止 | ✅ 允许 |
| 串行化(最高) | ❌ 禁止 | ❌ 禁止 | ❌ 禁止 |
不难发现
级别越高安全性越高,但是实时性能也越慢
示例:查看 / 修改隔离级别
-- 查看当前隔离级别
SHOW VARIABLES LIKE '%isolation%';-- 修改为“读已提交”(当前会话生效)
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;注意:
上述修改只在当前会话中生效
想要永久修改需要修改mysql配置文件
-- 恢复成默认隔离级别 set session transaction isolation level REPEATABLE READ;
二、索引:数据库的“目录”
1、概述
没有目录时,你得一页一页翻
有了目录可以快速锁定页码找到你要的内容
索引(Index):
是一种数据结构,用于提高数据库表的查询性能
索引可以加速数据的检索,减少查询所需的时间和资源消耗。
①索引优缺点:
- 优点:加快数据检索速度,提高查找效率
- 缺点:占用数据库物理存储空间,当对表中数据更新时,索引需要动态维护,降低数据写入效率
②创建原则:
- 对where 和 order by 涉及的列上尽量建立索引
-- 没有索引的情况(全表扫描) SELECT * FROM books WHERE title LIKE '%MySQL优化%' ORDER BY publish_year; -- 需要一页页翻阅所有书籍,找到符合条件的再排序-- 有索引的情况 CREATE INDEX idx_title_year ON books(title, publish_year); -- 直接查目录,快速定位到相关书籍并按顺序排列
- 更新频繁的列不应设置索引
-- 用户状态频繁变化的表 UPDATE users SET last_login = NOW() WHERE user_id = 1; -- 每次登录都更新 UPDATE users SET online_status = 1 WHERE user_id = 1; -- 频繁上下线-- 如果给这些字段建索引 CREATE INDEX idx_last_login ON users(last_login); CREATE INDEX idx_online_status ON users(online_status);每次UPDATE / INSERT/DELETE时,数据库需要:
- 修改数据本身 ✅(必须的)
- 更新相关索引 ❌(额外开销)
- 数据量小的表不要使用索引
索引占用额外存储空间,维护成本更高
- 重复数据多的字段不应设为索引(如性别,只有男和女),重复数据超 15%就不该建索引
也可以简单算一下看看适不适合:
选择性 = 不同值的数量 / 总记录数选择性 > 0.85:非常适合建索引
选择性 0.5-0.85:可以考虑建索引
选择性 < 0.15:不适合建索引示例:
-- 检查字段选择性
SELECT COUNT(DISTINCT gender) as distinct_values,COUNT(*) as total_records,COUNT(DISTINCT gender) / COUNT(*) as selectivity
FROM users;-- 结果示例:
-- distinct_values: 2
-- total_records: 10000
-- selectivity: 0.0002 -- 太低了,不适合建索引2、存储引擎
在 MySQL 中,存储引擎(Storage Engine)是负责处理数据的存储和检索的模块
MySQL 支持多种存储引擎
不同的存储引擎可以在不同的应用场景中提供不同的优势和特性
常见的有:
- InnoDB:MySQL 5.5 版本之后的默认存储引擎,适用于需要事务支持和高并发读写操作的应用场景
- MyISAM:MySQL 5.5 版本之前的默认存储引擎,它以其简单和高性能而闻名,适用于大量的读操作和只读数据
- Memory:或称为 Heap存储引擎,将数据存储在内存中,提供了非常快速的读写性能,但是,由于数据存储在内存中,重启服务器或断电会导致数据丢失,Memory 引擎适用于临时数据存储和高速缓存等场景
InnoDB用的底层数据结构是 B+树
为什么不用哈希、二叉树哪些呢?
- 哈希索引:像查字典的 “部首目录”,精确匹配快,但范围查询(比如 “薪水 > 5000”)直接歇菜,因为哈希值是无序的,无法进行大小比较。
- 二叉树:数据多了会变成 “歪脖子树”(像链表),查最后一个数据要遍历所有节点,慢得很。
- B + 树:多叉树,每个节点中可以存储多个数据,且每个节点中数据是有序的,树的高度值更小,查询效果更高。查范围(比如 “id 10-20”)直接扫叶子节点的双向链表,又快又稳,还能减少磁盘 IO
不过 B+树 也有弊端:
- 范围查找效率不高,比如查询 [20,39]
- 查询效率不稳定:离根节点近则查询快,远则慢
- 树高度还有下降空间(数据库优化方向,让树更矮胖,提高查询性能,但是会牺牲内存空间)
3、索引分类
按功能划分:
常用:单列索引(普通索引、主键索引、唯一索引)组合索引、全文索引
了解:空间索引、其他索引
-
单列索引
①普通索引
语法:
CREATE TABLE [IF NOT EXISTS] tb_name [(
字段1 数据类型 [约束条件] [默认值] [COMMENT '注解'],
字段2 数据类型 [约束条件] [默认值] [COMMENT '注解'],
字段3 数据类型 [约束条件] [默认值] [COMMENT '注解'],
[表约束条件]
index index_name(col_name...)
)][engine=innodb] [default charset=utf8];或
create index index_name on tb_name(col_name);或
alter table tb_name add index index_name(col_name);示例1:创建教师表,指定普通索引
create table tea(
id int primary key auto_increment,
name varchar(20),
age int,
index index_name(name)
);示例2:创建教师表之后构建索引
create table tea1(
id int primary key auto_increment,
name varchar(20),
age int
);
create index index_name on tea1(name);示例2:创建教师表之后构建索引
create table tea2(
id int primary key auto_increment,
name varchar(20),
age int
);
alter table tea2 add index index_name(name);查看xxx数据库中的全部索引
select *
from mysql.innodb_index_stats
where database_name='xxx';②主键索引
创建表时,MySQL会自动在主键列上建立一个索引
具有唯一性,不允许为NULL
示例:创建教师表,设置id为主键索引
create table tea4(
id int primary key auto_increment,
name varchar(20),
age int
);或
create table tea4(
id int,
name varchar(20),
age int
);
alter table tea4 add primary key(id);③唯一索引
和普通索引类似,不同点:
索引列的值必须唯一,但允许为NULL,如果是组合索引,列值的组合必须唯一
示例:
create table tea3(
id int primary key auto_increment,
name varchar(20),
age int,
unique index_name(name)
);或
create table tea3(
id int primary key auto_increment,
name varchar(20),
age int
create unique index index_name on tea3(name);或
create table tea3(
id int primary key auto_increment,
name varchar(20),
age int
);
alter table tea3 add unique index_name(name);-
组合索引(复合索引)
多个列一起建索引,遵循 “最左原则”
示例:创建教师表,设置id和名字为组合索引
create table tea5(
id int,
name varchar(20),
age int,
index index_name(id,name)
);或
create table tea5(
id int,
name varchar(20),
age int
);
create index index_name on tea5(id,name);或
create table tea5(
id int,
name varchar(20),
age int
);
alter table tea5 add index index_name(id,name);
注意:
以现在的索引是(id,name)这个顺序为例
- where id=1 可以使用索引,条件里面必须包含索引前面的字段才能够进行匹配
- where name='张三' 不可以使用索引(如果索引是(name,id)就可以)
- where name='张三' and id=12 可以使用索引,mysql本身就有一层sql优化,他会根据sql来识别出来该用哪个索引
- where id=12 and name='张三' 可以使用,顺序一致
-
全文索引
文本搜索专用,关键字 fulltext
要求:
- MySQL 5.6 以前的版本,只有 MyISAM 存储引擎支持全文索
- MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引
- 只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引
- 数据量较大时,先将数据放入一个没有全局索引的表中,然后再用create index创建fulltext索引,要比先建立一张表(包含fulltext索引),然后再将数据写入的速度快很多
为什么要全文索引?
- like + % 在文本比较少时是合适的,但是对于大量的文本数据检索,是不可想象的。
- 全文索引在大量的数据面前,能比 like + % 快 N 倍,速度不是一个数量级,但是全文索引可能存在精度问题。
示例(创建):创建表Poetry,收录诗歌
create table Poetry(
id int primary key auto_increment,
name varchar(20),
content text,
fulltext(content)
);-- 或
create table Poetry(
id int primary key auto_increment,
name varchar(20),
content text
);
create fulltext index index_content on Poetry(content);-- 或
create table Poetry(
id int primary key auto_increment,
name varchar(20),
content text
);
alter table Poetry add fulltext index_content(content);示例(搜索):基于全文检索查询含有And内容
MATCH(字段列表) AGAINST(搜索内容 [搜索模式])select *
from Poetry
where match(content) against('And');注意:
AGAINST必须与
MATCH()函数配合使用
三、视图:数据库的“定制窗口”
1、概述
视图是 “虚拟表”,不是真的存数据,而是保存一条查询语句
它是基于一个或多个表的查询结果构建而成的
视图提供了一种方便和灵活的方式来处理复杂查询、控制数据访问和重用查询逻辑
语法:
CREATE [OR REPLACE] VIEW view_name [(字段列表)]
AS
select语句
[WITH [CASCADED |LOCAL] CHECK OPTION]
- select语句
表示一个完整的查询语句,将查询记录映射到视图中
- [with [cascaded | local] check option]
可选项,表示更新视图时要保证在该视图的权限范围之内
2、优点
- 简化查询:复杂的多表联查,保存成视图后,下次直接
SELECT * FROM 视图名,不用再写长 SQL。 - 数据安全:不同角色看不同视图,销售看不到成本,实习生看不到核心客户。
- 减少冗余:多个地方用同一查询逻辑,只需要维护一个视图
-- 创建视图:只包含员工编号和姓名
CREATE VIEW v_emp_basic AS
SELECT id, name FROM emp;-- 销售人员查询时,只能看到视图中的数据,看不到薪水
SELECT * FROM v_emp_basic;3、分类
①简单视图
只关联一张表,查询逻辑简单(无聚合、无多表 join、无函数计算)
数据能 “双向同步”—— 修改视图会同步到原表,修改原表也会同步到视图
案例:单表视图的创建与更新
第一步:先建基础表emp和dept
-- 部门表
CREATE TABLE dept(id INT PRIMARY KEY,name VARCHAR(20) -- 部门名:java、bigdata、web
);
INSERT INTO dept VALUES(1,'java'),(2,'bigdata'),(3,'web');-- 员工表(含外键关联部门)
CREATE TABLE emp(id INT PRIMARY KEY,name VARCHAR(20),salary DOUBLE, -- 敏感字段:薪水dept_id INT,FOREIGN KEY(dept_id) REFERENCES dept(id)
);
INSERT INTO emp VALUES(1,'lisi',3000,1),(2,'wangwu',3200,1),(3,'zhansan',2800,1);第二步:创建简单视图(只查emp表的id和name)
创建简单视图(只查emp表的id和name)第三步:操作视图,观察与原表的同步
-- 1. 查视图:只能看到id和username,看不到salary
SELECT * FROM v_emp_simple;
-- 结果:
-- id | username
-- 1 | lisi
-- 2 | wangwu
-- 3 | zhansan-- 2. 插入视图:会同步到emp表
INSERT INTO v_emp_simple VALUES(4,'zhaoliu');
-- 查原表emp:新增了id=4、name=zhaoliu,salary和dept_id为NULL
SELECT * FROM emp;-- 3. 更新视图:同步到emp表
UPDATE v_emp_simple SET username='zhaosi' WHERE id=4;
-- 查原表emp:id=4的name变成zhaosi-- 4. 删除视图数据:同步删除emp表数据
DELETE FROM v_emp_simple WHERE id=4;
-- 查原表emp:id=4的记录被删除②复杂视图
基于多表 join、聚合函数(
SUM/COUNT)、子查询等复杂逻辑构建的视图不支持更新(因为数据来自多个表,无法确定该修改哪个原表),只能用于查询
案例:多表关联的复杂视图
需求:创建视图,显示员工姓名、所属部门名、薪水(关联emp和dept表)
第一步:创建复杂视图
CREATE VIEW v_emp_dept AS
SELECT CONCAT(e.name, '(', d.name, ')') AS username, -- 拼接员工名+部门名(如lisi(java))e.salary,e.dept_id,d.name AS dept_name
FROM emp e
JOIN dept d ON e.dept_id = d.id; -- 多表join第二步:查询视图(正常使用)
SELECT * FROM v_emp_dept;
第三步:尝试更新视图(报错)
-- 试图修改拼接后的username,报错
UPDATE v_emp_dept SET username='jack(java)' WHERE dept_id=1;
-- 错误信息:ERROR 1348 (HY000): Column 'username' is not updatable为什么不能更新?
因为
username是e.name和d.name拼接的结果数据库不知道该修改
emp表的name,还是dept表的name而且视图来自多表 join,更新逻辑不明确,所以 MySQL 直接禁止
文档明确的 “不可更新视图” 场景
只要视图包含以下任意一种结构,就不能更新:
- 聚合函数(
SUM/COUNT/AVG/MAX/MIN);DISTINCT(去重);UNION/UNION ALL(合并结果集);- 多表
JOIN;GROUP BY/HAVING(分组统计);- 选择列表中的子查询;
- 数学表达式(如
salary*12);- 常量视图(如
CREATE VIEW v_const AS SELECT 'briup' AS company;)
4、视图的管理与维护
①查看视图:知道数据库里有哪些视图
-- 方法1:查看当前数据库所有表和视图(视图会和表一起显示)
SHOW TABLES;
-- 结果中,视图名(如v_emp_simple)和表名(如emp)并列,可通过后续命令区分-- 方法2:查看视图的定义(最实用,知道视图是怎么建的)
SHOW CREATE VIEW v_emp_dept;
-- 会显示创建视图的完整SQL语句,方便排查问题-- 方法3:从系统表查询,明确区分视图和表
SELECT TABLE_NAME, TABLE_TYPE
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = '你的数据库名' -- 替换成你的库名,比如briupAND TABLE_TYPE = 'VIEW'; -- 只查视图②重命名视图:改个更易懂的名字
-- 语法:RENAME TABLE 旧视图名 TO 新视图名
RENAME TABLE v_emp_simple TO v_emp_basic_info;
-- 重命名后,用新名字调用
SELECT * FROM v_emp_basic_info;③修改视图:更新视图的查询逻辑
如果业务需求变了(比如视图要加个dept_id列),不用删了重建,直接修改:
-- 语法:ALTER VIEW 视图名 AS 新的SELECT语句
ALTER VIEW v_emp_basic_info AS
SELECT id, name, dept_id FROM emp; -- 新增dept_id列-- 查修改后的视图:多了dept_id列
SELECT * FROM v_emp_basic_info;④删除视图:不用的视图及时清理
-- 语法:DROP VIEW [IF EXISTS] 视图名
DROP VIEW IF EXISTS v_emp_dept; -- IF EXISTS:避免视图不存在时报错5、视图的常用场景
①数据权限控制
- 销售人员:只能看员工的
id、name、dept_id,看不到salary;- 部门经理:能看本部门员工的
id、name、salary;- 高管:能看所有员工的完整数据
解决方案:给不同角色建不同视图
,不用修改代码,只需控制视图权限:
-- 给销售人员的视图(无salary)
CREATE VIEW v_sales_emp AS SELECT id, name, dept_id FROM emp;-- 给部门经理的视图(只看本部门,假设经理是java部门,dept_id=1)
CREATE VIEW v_manager_emp AS
SELECT id, name, salary FROM emp WHERE dept_id=1;-- 给高管的视图(完整数据)
CREATE VIEW v_admin_emp AS SELECT * FROM emp;②简化复杂查询
如果经常需要查 “员工 + 部门 + 薪水等级”(关联
emp、dept、salgrade三张表)每次写长 SQL 很麻烦
,用视图封装:
-- 创建复杂视图:关联三张表
CREATE VIEW v_emp_full_info AS
SELECT e.id,e.name,d.name AS dept_name,s.name AS sal_grade -- 薪水等级(来自salgrade表)
FROM emp e
JOIN dept d ON e.dept_id = d.id
JOIN salgrade s ON e.salary BETWEEN s.minsal AND s.maxsal;-- 下次查询只需一行
SELECT * FROM v_emp_full_info;③分解复杂查询逻辑
如果有一个超复杂的查询(比如多表 join + 子查询 + 聚合)
可以拆成多个简单视图
逐步组合
,降低难度。
比如 “查各部门平均薪水及等级”,可以拆两步:
- 先建 “部门平均薪水” 视图;
- 再关联 “薪水等级表” 建最终视图
-- 步骤1:部门平均薪水视图
CREATE VIEW v_dept_avg_sal AS
SELECT dept_id, AVG(salary) AS avg_sal
FROM emp GROUP BY dept_id;-- 步骤2:关联薪水等级,得到最终视图
CREATE VIEW v_dept_sal_grade AS
SELECT d.name AS dept_name,v.avg_sal,s.name AS sal_grade
FROM v_dept_avg_sal v
JOIN dept d ON v.dept_id = d.id
JOIN salgrade s ON v.avg_sal BETWEEN s.minsal AND s.maxsal;四、数据库优化
1、事务使用建议
- 事务不宜过长,尽快提交以释放锁资源
- 合理设置隔离级别,平衡一致性和性能
- 对于只读操作,考虑使用较低的隔离级别
2、索引优化
- 给
WHERE/ORDER BY涉及的列建索引 - 用组合索引代替多个单列索引(比如
(dept_id, salary)比单独建两个索引好)
3、查询优化
- 尽量不使用 NULL
通常索引字段不存在NULL
IS NULL或者IS NOT NULL 会导致索引无法使用,进而导致查询性能低下
- 别用
SELECT *,只查需要的列 - 避免
LIKE '%关键词%'(用全文索引代替) - 用
EXISTS代替IN(子查询更快) - 减少子查询
执行子查询时,会创建临时表,查询完毕后再删除它,所以子查询的速度会受到影响
- 避免排序
有些时候,数据库会暗中排序,比如这些:
- group by 子句
- order by 子句
- 聚合函数(sum、count、avg、max、min)
- distinct
- 集合运算符(union、intersect、except)
- 窗口函数(rank、row_number等)
所以:
- 能写在 WHERE 子句里的条件不要写在 HAVING 子句里。
- 如果需要对两张表的连接结果进行去重,可以考虑使用exists代替distinct,以避免排序
4、设计优化
- 字段默认值别设为 NULL(NULL 不进索引)
- 表字段尽量小(比如用
INT不用BIGINT,CHAR(6)存邮编够了) - 大表分表(数据超 100 万行,考虑水平拆分或垂直拆分)
事务、索引、视图并不是孤立存在的
它们经常协同工作
事不宜迟,赶快尝试一下吧!
