Nacos简介—2.Nacos的原理简介
大纲
1.Nacos集群模式的数据写入存储与读取问题
2.基于Distro协议在启动后的运行规则
3.基于Distro协议在处理服务实例注册时的写路由
4.由于写路由造成的数据分片以及随机读问题
5.写路由 + 数据分区 + 读路由的CP方案分析
6.基于Distro协议的定时同步机制
7.基于Distro协议的心跳校验下的数据同步补偿机制
8.基于Raft协议实现的弱CP模式
9.Nacos集群模式下的lookup寻址机制
1.Nacos集群模式的数据写入存储与读取问题
使用Nacos进行服务注册时,需要解决如下问题:
一.应该找集群里的哪个节点来发起服务注册?
二.服务实例数据应该存储在集群的哪个节点?
三.应该找集群里的哪个节点来发起服务发现?
2.基于Distro协议在启动后的运行规则
(1)Nacos集群启动后会按如下规则运行
(2)Distro协议 + 定时数据同步与AP + 心跳检验与网络分区
(1)Nacos集群启动后会按如下规则运行
一.Nacos集群的每个节点都可以处理写请求
Nacos集群节点收到写请求后:首先根据要注册的服务实例的IP:端口 + 路由算法,计算出所属集群节点。然后把服务实例注册请求转发到负责该服务实例数据的集群节点中。接着负责该服务实例数据的集群节点就会解析请求,把数据存储到内存里。同时会定期执行同步任务,把本节点负责的数据同步到其他节点。最终每个节点都会存储全量的服务实例数据。
二.新加入Nacos集群的节点会拉取全量数据
新加入Nacos集群的节点会轮询Nacos集群的所有节点,然后发送请求出去拉取各节点的数据,所以Nacos集群的每个节点上都会有所有已注册的服务实例的数据。
三.每个节点都会定期发送心跳给其他节点
Nacos集群的节点通过心跳请求进行数据校验,主要是交换数据的校验值。如果发现其他节点上的数据与自己的不一致,就会全量拉取数据进行补齐。
四.Nacos集群的每个节点都可以处理读请求
因为每个节点都有全量数据,所以每个节点都可以处理读请求。
(2)Distro协议 + 定时数据同步与AP + 心跳检验与网络分区
Distro协议兼顾了CAP中的AP。在这个协议下,所有节点通过定期数据同步 + 心跳校验实现数据最终一致。这个协议能让每个节点都有全量数据。
如果出现某节点宕机,不影响集群可用性。如果出现网络分区,同样不影响集群可用性。因为不同的网络分区只会读写分区中的Nacos节点,此时只是没办法同步数据而已。虽然数据会不一致,但一旦分区恢复后,心跳校验机制运作起来,数据会自动补齐。
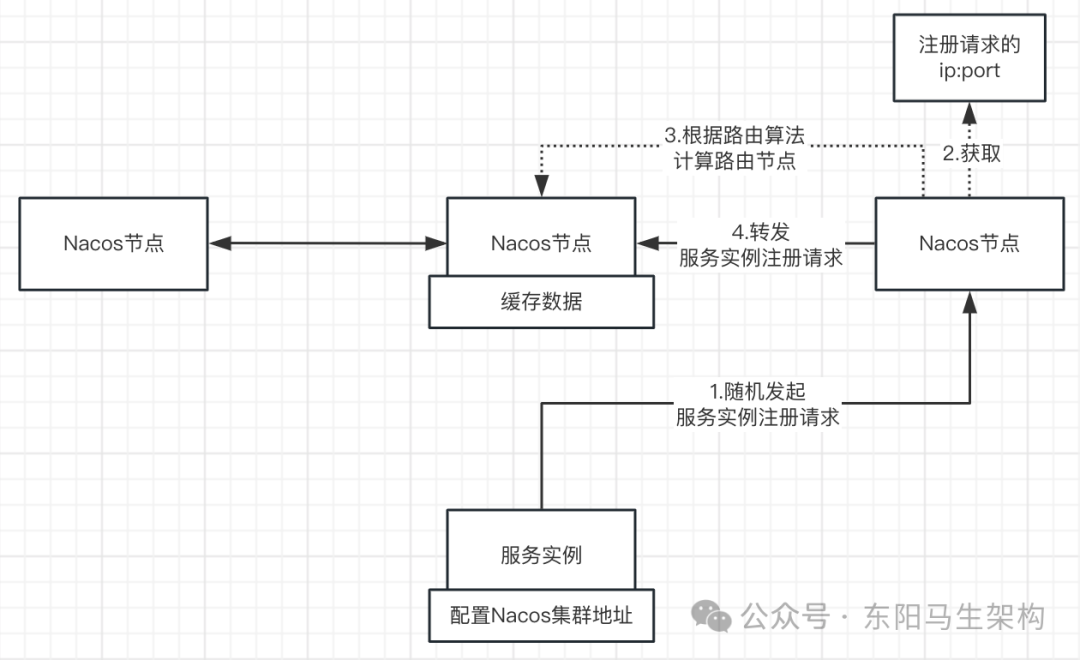
3.基于Distro协议在处理服务实例注册时的写路由
首先,服务实例会随机选择Nacos集群中的一个节点发起注册请求。
然后,Nacos集群节点收到写请求后:会根据要注册的服务实例的IP:端口 + 路由算法,计算出所属的集群节点。
接着,把服务实例注册请求转发到负责该服务实例数据的集群节点中。负责该服务实例数据的节点会解析请求,缓存服务实例数据到内存中。
4.由于写路由造成的数据分片以及随机读问题
由于Nacos集群节点收到写请求后:会根据要注册的服务实例的IP:端口 + 路由算法,计算出所属的集群节点。所以会导致数据分片,即每个节点仅负责管理一部分的服务实例数据。
服务实例进行服务发现时,只能随机选择一个Nacos节点来读取数据。对Nacos集群节点进行随机读的时候,由于每个节点只负责处理部分数据,所以可能出现读取不到刚向集群注册的数据的随机读问题。
5.写路由 + 数据分区 + 读路由的CP方案分析
在数据分区 + 随机读的情况下,此时为了读取到数据,有两种解决方案。
方案一:让随机选择的节点重新进行读路由
方案二:让随机选择的节点也拥有全部数据
如果采用方案一,也就是写路由 + 数据分片 + 读路由的架构设计。那么读写某个服务实例的数据,只能由Nacos集群中的其中一个节点处理。如果节点宕机,那么对应的该服务实例数据就不可用。虽然该节点的数据不可用,但也是对所有用户都不可用,视图是一致的。视图是一致的,说明要么都能读到数据,要么都读不到数据。所以这种方案会存在可用性的问题,但优点是数据是强一致的。也就是牺牲了CAP中的A,没有了可用性,但保证了CP。
Nacos的Distro协议则使用了方案二。某个节点宕机后,该节点的数据不会全部不可用,可能会丢失部分数据。也就是牺牲了CAP中的C,不能确保强一致性,但保证了AP。加上Distro协议的同步机制,可以让各节点的数据实现最终一致性。
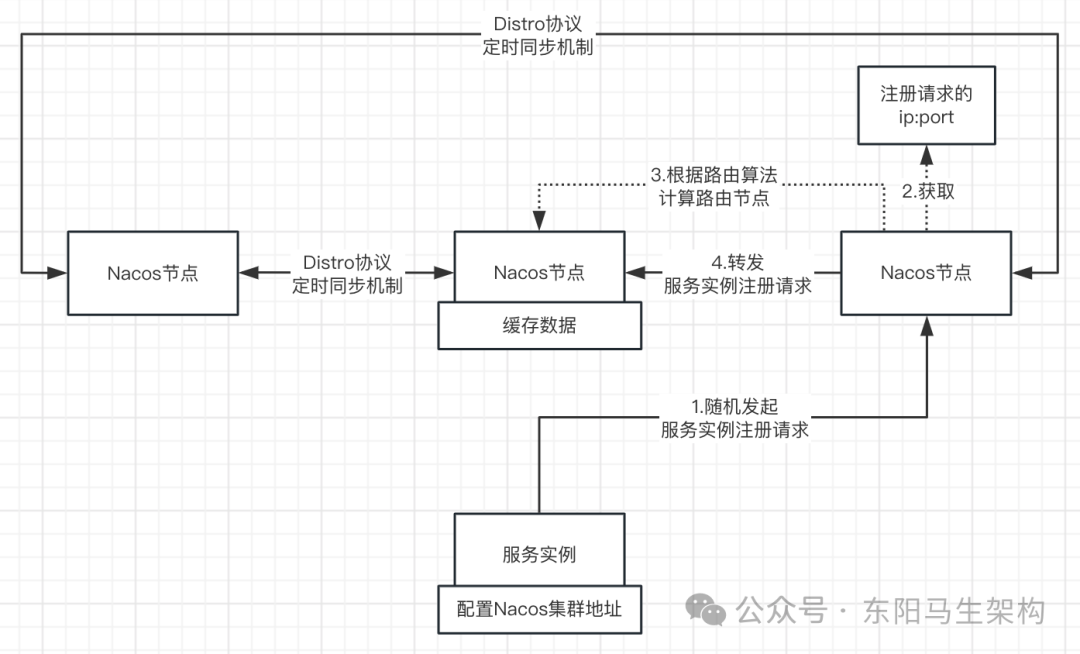
6.基于Distro协议的定时同步机制
Nacos集群中的每个节点,虽然通过写路由只写入由自己处理的数据,但同时也会定期执行同步任务,把本节点负责的数据同步到其他节点,最终每个节点都会存储全量的集群数据。
同步机制的存在保证了各节点的数据最终是一致的。
7.基于Distro协议的心跳校验下的数据同步补偿机制
Nacos集群的节点通过心跳请求进行数据校验,主要是交换数据的校验值。如果发现其他节点上的数据与自己的不一致,就会全量拉取数据进行补齐。
当出现网络分区时,两分区间的节点无法通信,此时自然就无法定时同步。但当分区恢复后,节点之间通过心跳校验机制,数据可以快速自动补齐。
8.基于Raft协议实现的弱CP模式
Nacos集群节点在启动时会选举出一个Leader节点,由Leader节点负责数据的写入,并将数据同步给其他节点。Leader节点成功写入数据的判断依据是,过半节点都成功同步数据了。
9.Nacos集群模式下的lookup寻址机制
(1)单机寻址
(2)文件寻址
(3)地址服务器寻址
寻址就是Nacos各节点启动时如何找到其他节点。
(1)单机寻址
Nacos通过"-m standalone"模式来启动时,会读取自己本机的IP:端口,然后构造对象放入到ServerMemberManager,它是专门负责管理所有节点信息的组件。
(2)文件寻址
cluster.conf里会写入各个节点地址,节点启动时会读取这个文件的内容。同时节点会针对这个文件施加监听器,如果发现文件有变动,会进行重新读取。但是需要手工维护每个节点的cluster.conf文件,比较适合常规的、三节点、小规模的生产集群部署。
(3)地址服务器寻址
如果Nacos需要进行大规模的集群部署,一般会采用这个方案。也就是使用一个Web服务器来维护一份cluster.conf,然后所有的Nacos都定时请求这个Web服务器获取最新的地址列表。