LangGraph实战指南:如何构建一个深度研究Agent


如何构建 Deep Research Agent
构建在实际中真正有效的LLM代理并非易事。
你需要考虑如何编排多步工作流、跟踪代理状态、实现必要的约束机制,并在决策过程发生时进行监控。
幸运的是,LangGraph恰好为你解决了这些痛点。
最近,谷歌通过开源一个基于LangGraph和Gemini构建的深度研究代理完整栈实现(采用Apache-2.0协议),完美展示了这一点。
这不是玩具级实现:该代理不仅能搜索,还能动态评估结果以决定是否需要通过进一步搜索获取更多信息。这种迭代工作流正是LangGraph真正发光的场景。
因此,如果你想了解LangGraph在实际中的工作方式,还有什么比从这样一个真实、可运行的代理开始更好的选择?
本文的学习计划:我们将采用“问题驱动”的学习方法。不会从冗长的抽象概念开始,而是直接深入代码,分析谷歌的实现。之后,我们会将每个部分与LangGraph的核心概念关联。
最终,你不仅会拥有一个可运行的研究代理,还将掌握足够的LangGraph知识来构建下一个项目。
本文讨论的所有代码均来自谷歌Gemini官方仓库,可在此处找到。我们的重点是定义研究代理的后端逻辑(backend/src/agent/目录)。
以下是本文的可视化路线图:
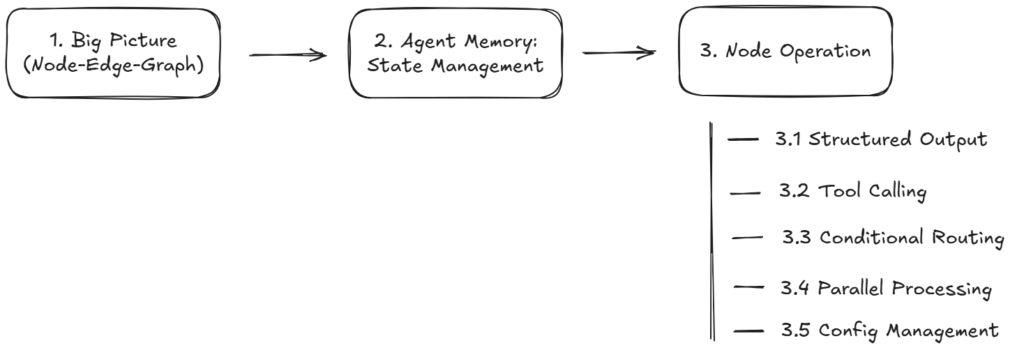
1. 整体概览——用图、节点和边建模工作流
🎯 问题
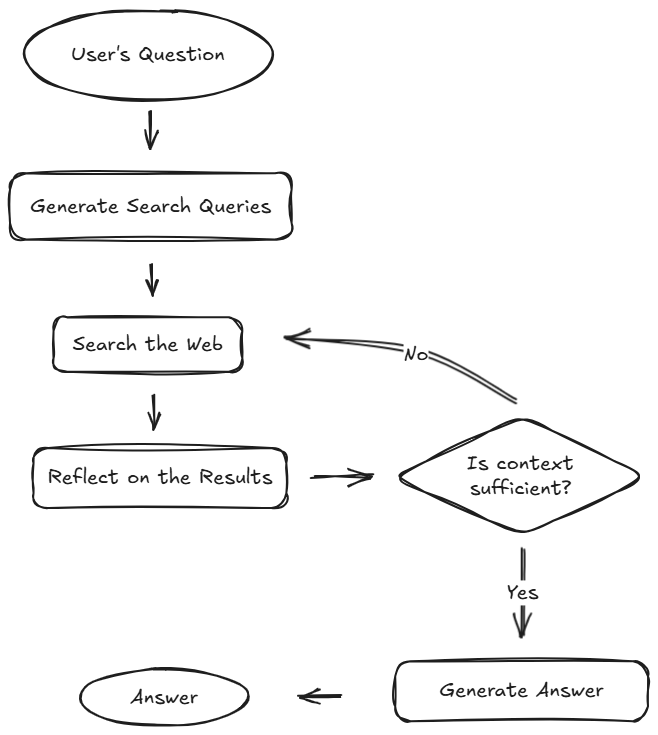
在本案例研究中,我们将构建一个激动人心的工具:基于LLM的研究增强代理,这是对ChatGPT、Gemini、Claude或Perplexity中“深度研究”功能的最小复刻。这就是我们的目标。
具体来说,我们的代理将按以下方式工作:
接收用户查询,自主搜索网络,检查获取的搜索结果,然后判断是否已找到足够信息。若足够,则生成带规范引用的精简报告;否则,循环返回进行更深入的搜索。
首先,我们需要勾勒一个高层流程图以明确构建目标:
💡 LangGraph的解决方案
现在,如何用LangGraph建模这个工作流?顾名思义,LangGraph使用图表示。但为什么用图?
简短的答案是:图非常适合建模复杂的有状态流程,正如我们要构建的应用。当存在分支决策、需要循环回溯,以及现实世界代理工作流中会遇到的各种复杂情况时,图提供了最自然的表示方式。
技术上,图由节点和边组成。在LangGraph中,节点是工作流中的单个处理步骤,边定义步骤间的转移,即控制和状态如何在系统中流动。
看代码!
在LangGraph中,从流程图到代码的转换非常直接。我们查看谷歌仓库中的agent/graph.py,看看如何实现。
第一步是创建图本身:
from langgraph.graph import StateGraph
from agent.state import (OverallState,QueryGenerationState,ReflectionState,WebSearchState,
)
from agent.configuration import Configuration# 创建代理图
builder = StateGraph(OverallState, config_schema=Configuration)
这里,StateGraph是LangGraph的状态感知图构建类。它接受定义节点间传递信息的OverallState类(这是我们下一节将讨论的代理内存部分),以及定义运行时可调参数的Configuration类(如各步骤调用的LLM、初始查询生成数量等)。后续章节将详细说明。
创建图容器后,我们可以添加节点:
# 定义循环节点
builder.add_node("generate_query", generate_query)
builder.add_node("web_research", web_research)
builder.add_node("reflection", reflection)
builder.add_node("finalize_answer", finalize_answer)
add_node()方法的第一个参数是节点名称,第二个参数是节点运行时执行的可调用对象。
通常,这个可调用对象可以是普通函数、异步函数、LangChain的Runnable,甚至是另一个编译后的StateGraph。
在我们的案例中:
generate_query基于用户问题生成搜索查询web_search使用原生谷歌搜索API工具执行网络研究reflection识别知识缺口并生成潜在后续查询finalize_answer完成研究总结
我们后续将详细分析这些函数的实现。
现在节点定义完成,下一步是添加边连接节点并定义执行顺序:
from langgraph.graph import START, END# 设置入口为`generate_query`
# 即该节点为第一个被调用的节点
builder.add_edge(START, "generate_query")# 添加条件边以在并行分支中继续搜索查询
builder.add_conditional_edges("generate_query", continue_to_web_research, ["web_research"]
)# 对网络研究进行反思
builder.add_edge("web_research", "reflection")# 评估研究结果
builder.add_conditional_edges("reflection", evaluate_research, ["web_research", "finalize_answer"]
)# 完成答案
builder.add_edge("finalize_answer", END)
需要注意几点:
- 之前定义的节点名称(如"generate_query"、"web_research"等)现在派上用场——我们可以在边定义中直接引用它们。
- 我们看到两种类型的边:静态边和条件边。
- 使用
builder.add_edge()时,会在两个节点间创建无条件直接连接。例如builder.add_edge("web_research", "reflection")表示网络研究完成后,流程将始终进入反思步骤。 - 使用
builder.add_conditional_edges()时,流程可能在运行时跳转到不同分支。创建条件边需要三个关键参数:源节点、路由函数和可能的目标节点列表。路由函数检查当前状态并返回下一个要访问的节点名称。例如evaluate_research()函数决定代理是否需要更多研究(此时进入"web_research"节点)或信息已足够可完成答案(进入"finalize_answer"节点)。
但为什么"generate_query"和"web_research"之间需要条件边?生成查询后难道不应该总是搜索吗?问得好!这实际与LangGraph如何支持并行化有关,我们后续将深入讨论。
- 我们还注意到两个特殊节点:
START和END。这是LangGraph内置的入口和出口点。每个图需要一个起始点(执行开始处),但可以有多个结束点(执行终止处)。
最后,将所有部分组合并将图编译为可执行代理:
graph = builder.compile(name="pro-search-agent")
完成!我们成功将流程图转换为LangGraph实现。
🎁 扩展阅读:图为何真正闪耀?
除了是非线性工作流的自然适配,LangGraph的节点/边/图表示带来了几个使真实世界代理构建和管理更简单的实用优势:
- 细粒度控制与可观测性:每个节点/边都有独立标识,可轻松检查进度并在异常时查看内部状态。这使调试和评估变得简单。
- 模块化与复用:可将单个步骤封装为可复用子图,如同乐高积木。这正是软件最佳实践的体现。
- 并行路径:当工作流部分独立时,图可轻松让它们并发运行。这显然有助于解决延迟问题并提高系统对故障的鲁棒性,这在复杂流水线中尤为关键。
- 易于可视化:无论是调试还是展示方案,能看到工作流逻辑总是很好的。图是可视化的自然选择。
📌 关键收获
回顾本节基础内容:
- LangGraph使用图描述代理工作流,因其能优雅处理分支、循环等非线性流程。
- LangGraph中,节点表示处理步骤,边定义步骤间的转移。
- LangGraph实现两种边:静态边和条件边。节点间固定转移用静态边;运行时动态决策的转移用条件边。
- 在LangGraph中构建图很简单:先创建StateGraph,添加节点(带其函数),用边连接,最后编译图。完成!
现在理解了基本结构,你可能想知道:信息如何在这些节点间流动?这引出了LangGraph最重要的概念之一:状态管理。
我们继续探索。
2. 代理的记忆——节点如何通过状态共享信息
🎯 问题
当代理遍历我们之前定义的图时,需要跟踪其生成/学习的信息。例如:
- 用户的原始问题
- 已生成的搜索查询列表
- 从网络获取的内容
- 关于收集信息是否充分的内部反思
- 最终打磨的答案
如何维护这些信息,使节点不孤立工作,而是协作并基于彼此工作?
💡 LangGraph的解决方案
LangGraph通过引入中心状态对象解决此问题,这是图中每个节点都能查看和写入的共享白板。
工作方式如下:
- 节点执行时接收图的当前状态
- 节点使用状态中的信息执行任务(如调用LLM、运行工具)
- 节点返回仅包含需要更新或添加状态部分的字典
- LangGraph将此输出自动合并到主状态对象,然后传递给下一个节点
由于状态传递和合并由LangGraph框架层处理,单个节点无需担心如何访问或更新共享数据。它们只需专注于特定任务逻辑。
此外,这种模式使代理工作流高度模块化。可轻松添加、删除或重新排列节点而不破坏状态流。
看代码!
记得上一节的这行代码吗?
# 创建代理图
builder = StateGraph(OverallState, config_schema=Configuration)
我们提到OverallState定义代理内存,但未展示具体实现。现在是时候打开黑箱了。
在仓库中,OverallState定义在agent/state.py:
from typing import TypedDict, Annotated, List
from langgraph.graph.message import add_messages
import operatorclass OverallState(TypedDict):messages: Annotated[list, add_messages]search_query: Annotated[list, operator.add]web_research_result: Annotated[list, operator.add]sources_gathered: Annotated[list, operator.add]initial_search_query_count: intmax_research_loops: intresearch_loop_count: intreasoning_model: str
本质上,所谓状态是作为契约的TypedDict。它定义工作流关心的每个字段,以及这些字段在多个节点写入时的合并方式。详细说明:
- 字段用途:
messages存储对话历史,search_query、web_search_result和sources_gathered跟踪代理的研究过程。其他字段通过设置限制和跟踪进度控制代理行为。 - Annotated模式:部分字段使用
Annotated[list, add_messages]或Annotated[list, operator.add]。这告诉LangGraph当多个节点修改同一字段时如何合并更新。具体来说,add_messages是LangGraph内置的智能合并对话消息的函数,operator.add在节点添加新项时拼接列表。 - 合并行为:如
research_loop_count: int等字段在更新时直接替换旧值。而Annotated字段是累积的,随着不同节点写入信息逐步构建。
虽然OverallState作为全局内存,但最好也定义更小的节点特定状态作为“API契约”,明确节点需要和产生的内容。毕竟,单个节点通常不需要整个OverallState的所有信息,也不会修改所有内容。
这正是LangGraph所做的。
在agent/state.py中,除了OverallState,还定义了三个其他状态:
class ReflectionState(TypedDict):is_sufficient: boolknowledge_gap: strfollow_up_queries: Annotated[list, operator.add]research_loop_count: intnumber_of_ran_queries: intclass QueryGenerationState(TypedDict):query_list: list[Query]class WebSearchState(TypedDict):search_query: strid: str
这些状态在agent/graph.py中按以下方式被节点使用:
from agent.state import (OverallState,QueryGenerationState,ReflectionState,WebSearchState,
)def generate_query(state: OverallState,config: RunnableConfig
) -> QueryGenerationState:# ...生成搜索查询的逻辑...return {"query_list": result.query}def continue_to_web_research(state: QueryGenerationState
):# ...发送多个搜索查询的逻辑...def web_research(state: WebSearchState,config: RunnableConfig
) -> OverallState:# ...执行网络研究的逻辑...return {"sources_gathered": sources_gathered,"search_query": [state["search_query"]],"web_research_result": [modified_text],}def reflection(state: OverallState,config: RunnableConfig
) -> ReflectionState:# ...反思结果的逻辑...return {"is_sufficient": result.is_sufficient,"knowledge_gap": result.knowledge_gap,"follow_up_queries": result.follow_up_queries,"research_loop_count": state["research_loop_count"],"number_of_ran_queries": len(state["search_query"]),}def evaluate_research(state: ReflectionState,config: RunnableConfig,
) -> OverallState:# ...确定研究流下一步的逻辑...def finalize_answer(state: OverallState,config: RunnableConfig) -> OverallState:# ...完成研究总结的逻辑...return {"messages": [AIMessage(content=result.content)],"sources_gathered": unique_sources,}
以reflection节点为例:它从OverallState读取,但返回符合ReflectionState契约的字典。之后,LangGraph会将其合并到主OverallState,供图中的下一个节点使用。
🎁 扩展阅读:状态去哪了?
使用LangGraph时常见的困惑是OverallState与这些小的节点特定状态如何交互。我们在此澄清。
关键心智模型是:运行时只有一个状态字典,即OverallState。
节点特定的TypedDict不是额外的运行时数据存储,而是对底层字典(OverallState)的类型化“视图”,临时聚焦节点应查看或产生的部分。它们的存在目的是让类型检查器和LangGraph运行时执行清晰的契约。

图5. 两种状态类型的快速对比。
节点运行前,LangGraph使用其类型提示创建仅包含节点所需输入的OverallState“切片”。
节点运行逻辑并返回其小而特定的输出字典(如ReflectionState字典)。
LangGraph获取返回的字典并执行OverallState.update(return_dict)。若有键定义了聚合器(如operator.add),则应用该逻辑。更新后的OverallState传递给下一个节点。
那么,为何LangGraph采用这种两级状态定义?除了为节点执行清晰契约并使节点操作自文档化,还有两个值得提及的好处:
- 即插即用复用:因为节点仅声明其需要和产生的状态小切片,它成为模块化、即插即用的组件。例如,仅需要状态中
{user_query}并输出{queries}的generate_query节点,可插入另一个完全不同的图,只要该图的OverallState能提供user_query。若节点编码针对整个全局状态(即输入输出均为OverallState类型),重命名任何不相关键时容易破坏工作流。这种模块化对构建复杂系统至关重要。 - 并行流效率:假设代理需要同时运行10次网络搜索。若使用节点特定状态作为小负载,只需将搜索查询发送到每个并行分支。这比将整个代理内存的副本(记住完整聊天历史也存储在
OverallState中!)发送到所有十个分支高效得多。这可显著减少内存和序列化开销。
这对我们的实际操作意味着什么?
- ✔ 在
OverallState中声明需要持久化或被多个不同节点可见的每个键。 - ✔ 使节点特定状态尽可能小。它们应仅包含节点负责产生的字段。
- ✔ 写入的每个键必须在某个状态模式中声明;否则,节点尝试写入时LangGraph会抛出
InvalidUpdateError。
📌 关键收获
回顾本节内容:
- LangGraph在两级维护状态:全局级有作为中心内存的
OverallState对象;节点级有基于TypedDict的小对象存储节点特定输入/输出。这使状态管理清晰有序。 - 每一步后,节点返回最小输出字典,然后合并回中心内存(
OverallState)。合并根据自定义规则(如列表的operator.add)执行。 - 节点自包含且模块化。可像积木一样轻松复用它们创建新工作流。
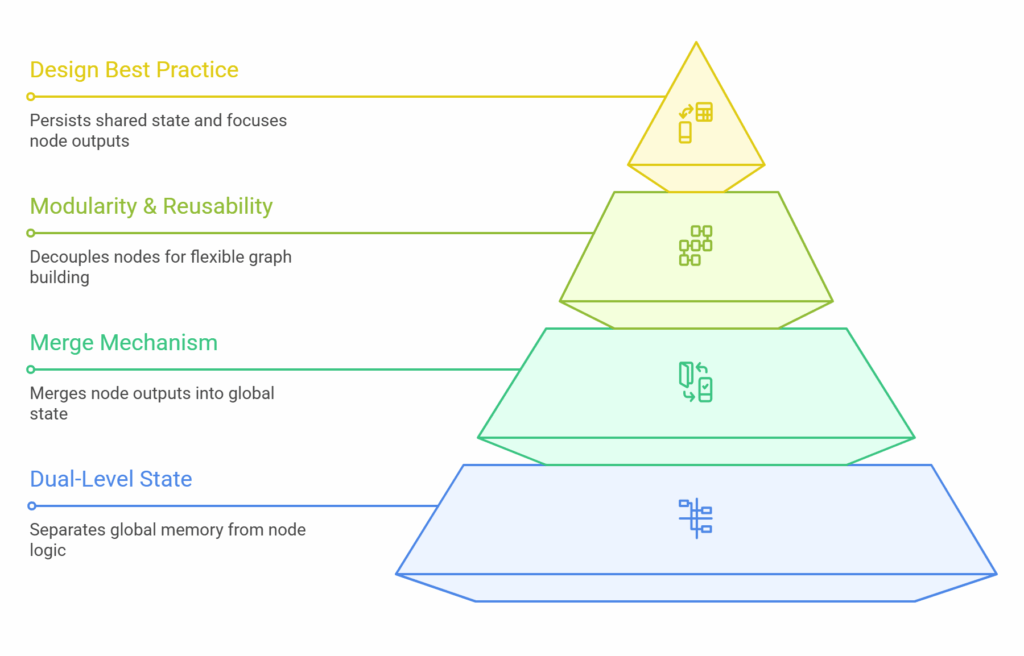
现在理解了图的结构和状态如何流动,节点内部发生了什么?我们转向节点操作。
3. 节点操作——真正的工作发生地
我们的图可以路由消息并保存状态,但每个节点内部仍需:
- 确保LLM输出正确格式
- 调用外部API
- 并行运行多个搜索
- 决定何时停止循环
幸运的是,LangGraph提供了几种可靠方法解决这些挑战。我们通过工作代码库的片段逐一了解。
3.1 结构化输出
🎯 问题
让LLM返回JSON对象很容易,但解析自由文本JSON在实际中不可靠。LLM一旦使用不同表述、添加意外格式或改变键顺序,工作流就可能脱轨。简言之,我们需要每一步处理都有可验证的输出结构。
💡 LangGraph的解决方案
我们约束LLM生成符合预定义模式的输出。这可通过使用llm.with_structured_output()将Pydantic模式附加到LLM调用实现,这是每个LangChain聊天模型包装器(如ChatGoogleGenerativeAI、ChatOpenAI等)提供的辅助方法。
看代码!
查看generate_query节点,其职责是创建搜索查询列表。由于我们需要该列表是干净的Python对象(而非杂乱字符串)供下一个节点解析,使用SearchQueryList(定义在agent/tools_and_schemas.py)强制输出模式是个好主意:
from typing import List
from pydantic import BaseModel, Fieldclass SearchQueryList(BaseModel):query: List[str] = Field(description="用于网络研究的搜索查询列表。")rationale: str = Field(description="简要说明这些查询与研究主题的相关性。")
以下是该模式在generate_query节点中的使用方式:
from langchain_google_genai import ChatGoogleGenerativeAI
from agent.prompts import (get_current_date,query_writer_instructions,
)def generate_query(state: OverallState,config: RunnableConfig
) -> QueryGenerationState:"""LangGraph节点,基于用户问题生成搜索查询。使用Gemini 2.0 Flash为网络研究生成优化的搜索查询。参数:state: 包含用户问题的当前图状态config: 运行配置,包括LLM提供方设置返回:包含状态更新的字典,包括含生成查询的search_query键"""configurable = Configuration.from_runnable_config(config)# 检查自定义初始搜索查询数量if state.get("initial_search_query_count") is None:state["initial_search_query_count"] = configurable.number_of_initial_queries# 初始化Gemini 2.0 Flashllm = ChatGoogleGenerativeAI(model=configurable.query_generator_model,temperature=1.0,max_retries=2,api_key=os.getenv("GEMINI_API_KEY"),)structured_llm = llm.with_structured_output(SearchQueryList)# 格式化提示current_date = get_current_date()formatted_prompt = query_writer_instructions.format(current_date=current_date,research_topic=get_research_topic(state["messages"]),number_queries=state["initial_search_query_count"],)# 生成搜索查询result = structured_llm.invoke(formatted_prompt)return {"query_list": result.query}
这里,llm.with_structured_output(SearchQueryList)用LangChain的结构化输出辅助包装Gemini模型。底层使用模型首选的结构化输出功能(Gemini 2.0 Flash的JSON模式)并自动将回复解析为SearchQueryList Pydantic实例,因此result是已验证的Python数据。
查看谷歌为此节点使用的系统提示也很有趣:
query_writer_instructions = """你的目标是生成复杂且多样的网络搜索查询。这些查询用于高级自动化网络研究工具,该工具能分析复杂结果、跟踪链接并综合信息。说明:
- 始终优先使用单个搜索查询,仅当原始问题请求多个方面或元素且一个查询不足时添加其他查询。
- 每个查询应专注于原始问题的一个特定方面。
- 不要生成超过{number_queries}个查询。
- 若主题广泛,查询应多样化。
- 不要生成多个相似查询,一个足够。
- 查询应确保收集最新信息。当前日期为{current_date}。格式:
- 将响应格式化为包含以下所有三个确切键的JSON对象:- "rationale": 简要说明这些查询为何相关- "query": 搜索查询列表示例:主题:去年苹果股票收入增长更多还是购买iPhone的人数增长更多
```json
{"rationale": "为准确回答此比较增长问题,我们需要苹果股票表现和iPhone销售指标的具体数据点。这些查询针对所需的精确财务信息:公司收入趋势、特定产品销售数量、同期股价变动以直接比较。","query": ["苹果2024财年总收入增长", "iPhone 2024财年销量增长", "苹果2024财年股价增长"],
}
```上下文:{research_topic}"""
我们看到了提示工程的最佳实践,如定义模型角色、指定约束、提供示例说明等。
3.2 工具调用
🎯 问题
研究代理要成功,需要从网络获取最新信息。为此,需要“工具”进行网络搜索。
💡 LangGraph的解决方案
节点可执行工具。这些可以是原生LLM工具调用功能(如Gemini中)或通过LangChain工具抽象集成。工具调用结果收集后,可放回代理状态。
</> 看代码!
关于工具调用使用模式,查看web_research节点。该节点使用Gemini的原生工具调用功能执行谷歌搜索。注意工具在模型配置中直接指定。
from langchain_google_genai import ChatGoogleGenerativeAI
from agent.prompts import (web_searcher_instructions,
)
from agent.utils import (get_citations,insert_citation_markers,resolve_urls,
)def web_research(state: WebSearchState,config: RunnableConfig
) -> OverallState:"""LangGraph节点,使用原生谷歌搜索API工具执行网络研究。结合Gemini 2.0 Flash使用原生谷歌搜索API工具执行网络搜索。参数:state: 包含搜索查询和研究循环计数的当前图状态config: 运行配置,包括搜索API设置返回:包含状态更新的字典,包括sources_gathered、research_loop_count和web_research_results"""# 配置configurable = Configuration.from_runnable_config(config)formatted_prompt = web_searcher_instructions.format(current_date=get_current_date(),research_topic=state["search_query"],)# 使用google genai客户端,因langchain客户端不返回依据元数据response = genai_client.models.generate_content(model=configurable.query_generator_model,contents=formatted_prompt,config={"tools": [{"google_search": {}}],"temperature": 0,},)# 将URL解析为短URL以节省token和时间resolved_urls = resolve_urls(response.candidates[0].grounding_metadata.grounding_chunks, state["id"])# 获取引用并添加到生成文本citations = get_citations(response, resolved_urls)modified_text = insert_citation_markers(response.text, citations)sources_gathered = [item for citation in citations for item in citation["segments"]]return {"sources_gathered": sources_gathered,"search_query": [state["search_query"]],"web_research_result": [modified_text],}
LLM看到Google Search工具并理解可用其完成提示。这种原生集成的关键优势是响应返回的grounding_metadata。该元数据包含依据块——本质上是答案片段与其对应的URL。这为我们免费提供了引用。
3.3 条件路由
🎯 问题
初始研究后,代理如何知道是停止还是继续?我们需要控制机制创建可自终止的研究循环。
💡 LangGraph的解决方案
条件路由由特殊类型的节点处理:该节点不返回状态,而是返回下一个要访问的节点名称。本质上,该节点实现路由函数,检查当前状态并决定图内的流量方向。
</> 看代码!
evaluate_research节点是代理的决策者。它检查reflection节点设置的is_sufficient标志,并将当前research_loop_count值与预配置的最大阈值比较。
def evaluate_research(state: ReflectionState,config: RunnableConfig,
) -> OverallState:"""LangGraph路由函数,确定研究流的下一步。通过决定是否继续收集信息或完成总结(基于配置的最大研究循环数)控制研究循环。参数:state: 包含研究循环计数的当前图状态config: 运行配置,包括max_research_loops设置返回:指示下一个要访问节点的字符串字面量("web_research"或"finalize_summary")"""configurable = Configuration.from_runnable_config(config)max_research_loops = (state.get("max_research_loops")if state.get("max_research_loops") is not Noneelse configurable.max_research_loops)if state["is_sufficient"] or state["research_loop_count"] >= max_research_loops:return "finalize_answer"else:return [Send("web_research",{"search_query": follow_up_query,"id": state["number_of_ran_queries"] + int(idx),},)for idx, follow_up_query in enumerate(state["follow_up_queries"])]
若满足停止条件,返回字符串"finalize_answer",LangGraph进入该节点。否则,返回包含follow_up_queries的Send对象列表,启动另一波并行网络研究,继续循环。
Send对象…它是什么?
这是LangGraph触发并行执行的方式。我们现在转向此。
3.4 并行处理
🎯 问题
为全面回答用户查询,generate_query节点需生成多个搜索查询。但我们不想逐个运行这些查询,因为太慢且低效。我们希望同时执行所有查询的网络搜索。
💡 LangGraph的解决方案
触发并行执行,节点可返回Send对象列表。Send是特殊指令,告诉LangGraph调度器将这些任务并发分派到指定节点(如"web_research"),每个任务有自己的状态片段。
</> 看代码!
为实现并行搜索,谷歌的实现引入continue_to_web_research节点作为分派器。它从状态获取query_list并为每个查询创建单独的Send任务。
from langgraph.types import Senddef continue_to_web_research(state: QueryGenerationState
):"""LangGraph节点,将搜索查询发送到web_research节点。用于生成n个web_research节点,每个对应一个搜索查询。"""return [Send("web_research", {"search_query": search_query, "id": int(idx)})for idx, search_query in enumerate(state["query_list"])]
这就是所需的所有代码。魔法发生在该节点返回后。
LangGraph收到此列表时,不会简单遍历它。实际上,它在底层触发复杂的扇出/扇入过程处理并发:
首先,每个Send对象仅携带你提供的小负载({"search_query": ..., "id": ...}),而非整个OverallState。目的是实现快速序列化。
然后,图调度器为列表中的每个项启动一个asyncio任务。此并发自动发生,工作流构建者无需编写async def或管理线程池。
最后,所有并行web_research分支完成后,它们各自返回的字典自动合并回主OverallState。记得我们最初讨论的Annotated[list, operator.add]吗?现在它变得关键:用此类归约器定义的字段(如sources_gathered),其结果将拼接为单个列表。
你可能想问:若某个并行搜索失败或超时会怎样?这正是我们为每个Send负载添加自定义id的原因。该ID直接流入跟踪日志,允许你定位并调试失败的具体分支。
若你记得之前的图定义行:
# 添加条件边以在并行分支中继续搜索查询
builder.add_conditional_edges("generate_query", continue_to_web_research, ["web_research"]
)
你可能疑惑:为何需要将continue_to_web_research节点声明为条件边的一部分?
关键是要认识到:continue_to_web_research不仅是管道中的另一步骤——它是路由函数。
generate_query节点可能返回零个查询(用户问题简单时)或二十个。静态边会强制工作流调用web_research恰好一次,即使无事可做。通过实现为条件边,continue_to_web_research在运行时决定是否分派——并通过Send决定生成多少并行分支。若continue_to_web_research返回空列表,LangGraph根本不会跟随该边。这节省了搜索API的往返。
最后,这再次体现了软件工程的最佳实践:generate_query专注于搜索什么,continue_to_web_research专注于是否及如何搜索,web_research专注于执行搜索,这是清晰的职责分离。
3.5 配置管理
🎯 问题
节点要正确工作,需要知道例如:
- 使用哪个LLM及参数设置(如temperature)?
- 应生成多少初始搜索查询?
- 总研究循环和每次运行的并发上限是多少?
- 等等…
简言之,我们需要一种干净、集中的方式管理这些设置,而不使核心逻辑混乱。
💡 LangGraph的解决方案
LangGraph通过向每个需要的节点传递单一、标准化的config解决此问题。该对象作为运行时特定设置的通用容器。
在节点内部,LangGraph使用自定义的类型化辅助类智能解析此config对象。该辅助类实现获取值的清晰层级:
- 首先查找当前运行
config对象中的覆盖值 - 若未找到,回退到检查环境变量
- 若仍未找到,使用辅助类中直接定义的默认值
</> 看代码!
查看reflection节点的实现以了解其工作方式。
def reflection(state: OverallState,config: RunnableConfig
) -> ReflectionState:"""LangGraph节点,识别知识缺口并生成潜在后续查询。分析当前总结以识别需要进一步研究的领域并生成潜在后续查询。使用结构化输出提取JSON格式的后续查询。参数:state: 包含运行中总结和研究主题的当前图状态config: 运行配置,包括LLM提供方设置返回:包含状态更新的字典,包括含生成后续查询的search_query键"""configurable = Configuration.from_runnable_config(config)# 增加研究循环计数并获取推理模型state["research_loop_count"] = state.get("research_loop_count", 0) + 1reasoning_model = state.get("reasoning_model") or configurable.reasoning_model# 格式化提示current_date = get_current_date()formatted_prompt = reflection_instructions.format(current_date=current_date,research_topic=get_research_topic(state["messages"]),summaries="\n\n---\n\n".join(state["web_research_result"]),)# 初始化推理模型llm = ChatGoogleGenerativeAI(model=reasoning_model,temperature=1.0,max_retries=2,api_key=os.getenv("GEMINI_API_KEY"),)result = llm.with_structured_output(Reflection).invoke(formatted_prompt)return {"is_sufficient": result.is_sufficient,"knowledge_gap": result.knowledge_gap,"follow_up_queries": result.follow_up_queries,"research_loop_count": state["research_loop_count"],"number_of_ran_queries": len(state["search_query"]),}
节点中仅需一行样板代码:
configurable = Configuration.from_runnable_config(config)
有很多“配置相关”术语。我们从Configuration开始逐一解析:
import os
from pydantic import BaseModel, Field
from typing import Any, Optionalfrom langchain_core.runnables import RunnableConfigclass Configuration(BaseModel):"""代理的配置。"""query_generator_model: str = Field(default="gemini-2.0-flash",metadata={"description": "用于代理查询生成的语言模型名称。"},)reflection_model: str = Field(default="gemini-2.5-flash-preview-04-17",metadata={"description": "用于代理反思的语言模型名称。"},)answer_model: str = Field(default="gemini-2.5-pro-preview-05-06",metadata={"description": "用于代理答案生成的语言模型名称。"},)number_of_initial_queries: int = Field(default=3,metadata={"description": "要生成的初始搜索查询数量。"},)max_research_loops: int = Field(default=2,metadata={"description": "要执行的最大研究循环数。"},)@classmethoddef from_runnable_config(cls, config: Optional[RunnableConfig] = None) -> "Configuration":"""从RunnableConfig创建Configuration实例。"""configurable = (config["configurable"] if config and "configurable" in config else {})# 从环境或配置获取原始值raw_values: dict[str, Any] = {name: os.environ.get(name.upper(), configurable.get(name))for name in cls.model_fields.keys()}# 过滤None值values = {k: v for k, v in raw_values.items() if v is not None}return cls(**values)
这是我们之前提到的自定义辅助类。可见Pydantic被大量用于定义代理的所有参数。需注意此类还定义了替代构造方法from_runnable_config()。该构造方法通过按我们在“💡 LangGraph的解决方案”中讨论的覆盖层级拉取值来创建Configuration实例。
config是from_runnable_config()方法的输入。技术上是RunnableConfig类型,但实际上是包含可选元数据的字典。在LangGraph中,它主要作为跨图传递上下文信息的结构化方式。例如,可携带标签、跟踪选项,以及——最重要的——"configurable"键下的嵌套覆盖字典。
最后,通过在每个节点调用:
configurable = Configuration.from_runnable_config(config)
我们通过组合三个来源的数据创建Configuration类实例:首先是config["configurable"],然后是环境变量,最后是类默认值。因此configurable是完全初始化、可直接使用的对象,使节点能访问所有相关设置,如configurable.reflection_model。
谷歌原始代码(反思节点和finalize_answer节点中)存在一个错误:
reasoning_model = state.get("reasoning_model") or configurable.reasoning_model
但
reasoning_model从未在configuration.py中定义。相反,应根据configuration.py定义使用reflect_model和answer_model。详情见PR #46。
总结:Configuration是定义,config是运行时输入,configurable是结果,即节点使用的已解析配置对象。
🎁 扩展阅读:我们未涵盖的内容
LangGraph提供的功能远多于本教程覆盖的内容。构建更复杂代理时,你可能会问:
- 如何让应用更响应?
LangGraph支持流式传输,可逐token输出结果以实现实时用户体验。
- API调用失败怎么办?
LangGraph实现重试和回退机制处理错误。
- 如何避免重新运行昂贵计算?
若某些节点需要执行昂贵处理,可使用LangGraph的缓存机制缓存节点输出。此外,LangGraph支持检查点,可保存图状态并从暂停处恢复。这对长时间运行的进程尤其重要。
- 能否实现人工介入工作流?
是的。LangGraph内置支持人工介入工作流,可暂停图并等待用户输入或批准后继续。
- 如何跟踪代理行为?
LangGraph与LangSmith原生集成,可通过最少配置提供代理行为的详细跟踪和可观测性。
- 代理如何自动发现和使用新工具?
LangGraph支持**MCP(模型上下文协议)**集成,允许自动发现和使用遵循此开放标准的工具。
更多详情请查看LangGraph官方文档。
📌 关键收获
回顾本节内容:
- 结构化输出:使用
.with_structured_output强制AI响应符合定义的特定结构,确保下游步骤可轻松解析的干净可靠数据。 - 工具调用:可在模型调用中嵌入工具,使代理能与外部世界交互。
- 条件路由:这是构建“自选冒险”逻辑的方式。节点通过返回下一个节点名称决定下一步,动态创建循环和决策点,使代理工作流更智能。
- 并行处理:LangGraph允许同时触发多个步骤运行。扇出任务和扇入收集结果的所有繁重工作由LangGraph自动处理。
- 配置管理:通过专用
Configuration类集中管理运行时设置、环境变量、默认值等,而非分散在代码中。
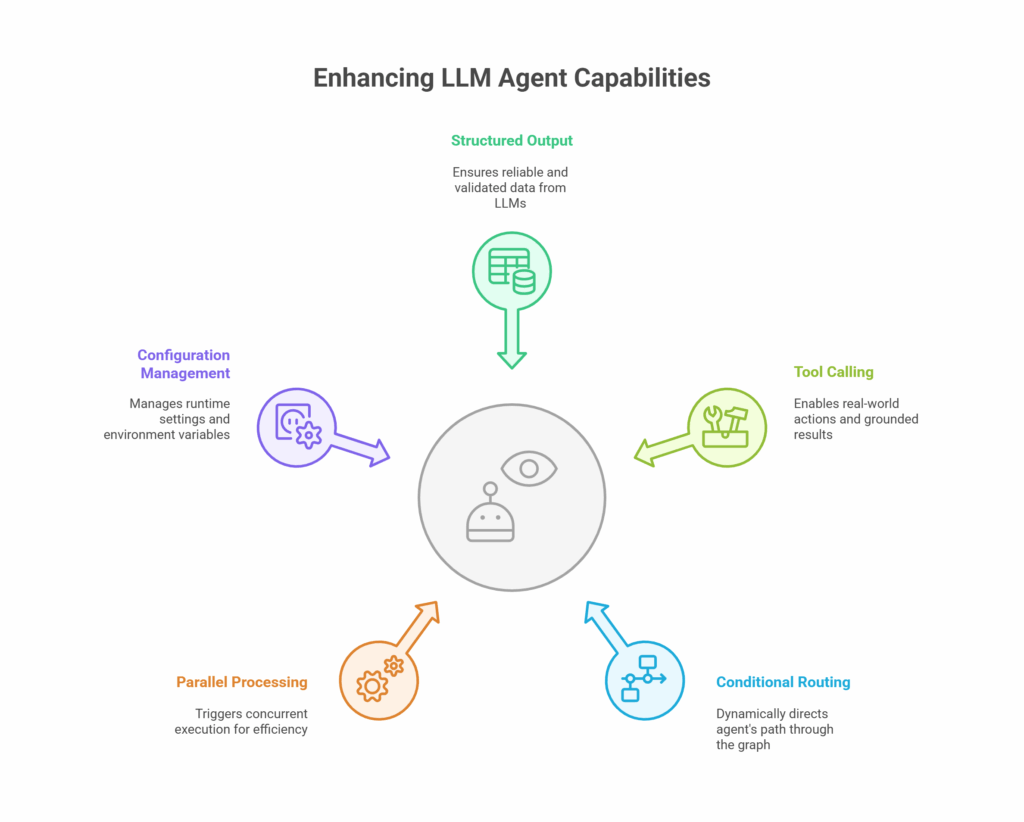
4. 总结
本文涵盖了大量内容!现在我们看到LangGraph的核心概念如何共同构建真实世界的研究代理,用几个关键收获总结我们的旅程:
- 图自然描述代理工作流。真实世界工作流涉及循环、分支和动态决策。LangGraph的图架构(节点、边、状态)提供了表示和管理此复杂性的清晰直观方式。
- 状态是代理的记忆。中心
OverallState对象是图中每个节点都能查看和写入的共享白板。结合节点特定状态模式,它们创建代理的记忆系统。 - 节点是可复用的模块化组件。在LangGraph中,应构建职责清晰的节点(如生成查询、调用工具、路由逻辑)。这使代理系统更易测试、维护和扩展。
- 控制在你手中。在LangGraph中,可通过条件边引导逻辑流,通过结构化输出强制数据可靠性,通过集中配置全局调整参数,或通过
Send实现任务并行执行。它们的组合使你能构建智能、高效、可靠的代理。
现在你已掌握LangGraph的所有知识,下一步想构建什么?