NWD-RKA论文阅读
摘 要
在航空图像中检测微小目标(TOD)具有挑战性,因为一个微小目标仅包含少量像素。现有最先进的目标检测器在微小目标检测上表现不佳,主要由于缺乏辨别特征的监督。我们的关键发现是,交并比(IoU)度量及其扩展对微小目标的位置偏移非常敏感,这会在基于锚点的检测器中极大地恶化标签分配质量。为了解决这一问题,我们提出了一种新的评估指标——归一化瓦瑟斯坦距离(Normalized Wasserstein Distance, NWD)和一种新的基于排序的分配策略(RanKing-based Assigning, RKA)用于微小目标检测。所提出的 NWD-RKA 策略可以无缝嵌入各类基于锚点的检测器中,替换标准的基于IoU阈值的方法,显著改善标签分配并为网络训练提供充足的监督信息。在四个数据集上的测试结果表明,NWD-RKA 能持续大幅提升微小目标检测性能。此外,针对 AI-TOD 数据集中存在的明显噪声标签问题,我们精心重标注并发布了 AI-TOD-v2 及其对应基准。在 AI-TOD-v2 中,遗漏标注和位置误差问题得到显著缓解,从而促进了更可靠的训练和验证过程。在 DetectoRS 中嵌入 NWD-RKA 后,检测性能在 AI-TOD-v2 上较最先进方法提升了 4.3 AP 点。相关数据集、代码和更多可视化结果可见:https://chasel-tsui.github.io/AI-TOD-v2/。
引言
微小目标在航空图像中无处不在,其检测在车辆检测、交通监控和海上救援等场景中具有重要应用价值。尽管自深度神经网络发展以来(Ren 等,2015;Lin 等,2017b;Tian 等,2019),目标检测取得了显著进展,但大多数方法仅针对常规尺寸的目标进行设计。微小目标(在 AI-TOD 数据集中定义为小于 16×16 像素)通常仅包含极少的外观信息,这给学习辨别特征带来了巨大挑战,导致检测失败率高(Singh 等,2018;Wang 等,2021a;Yu 等,2020)。
近年来,微小目标检测(TOD)的研究主要集中在提升特征判别能力上(Lin 等,2017a;Zhao 等,2019;Qiao 等,2021;Li 等,2017;Bai 等,2018;Noh 等,2019)。一些研究通过规范化输入图像尺度来增强小目标分辨率及其特征(Singh 和 Davis,2018;Singh 等,2018);另一些则利用生成对抗网络(GAN)直接为小目标生成超分辨率表示(Li 等,2017;Bai 等,2018;Noh 等,2019)。此外,特征金字塔网络(FPN)被提出以学习多尺度特征,实现尺度不变检测(Lin 等,2017a;Zhao 等,2019;Qiao 等,2021)。尽管现有方法在一定程度上提升了 TOD 性能,但通常伴随着额外的计算开销。
除了学习判别特征外,训练样本选择质量对于基于锚点的微小目标检测器同样至关重要(Zhang 等,2020)。在此类检测器中,正负样本(pos/neg)标签的分配尤为关键。然而,对于微小目标,仅凭少量像素信息进行训练样本选择难度极大。如图 1 和图 2 所示,我们有以下两点关键观察。
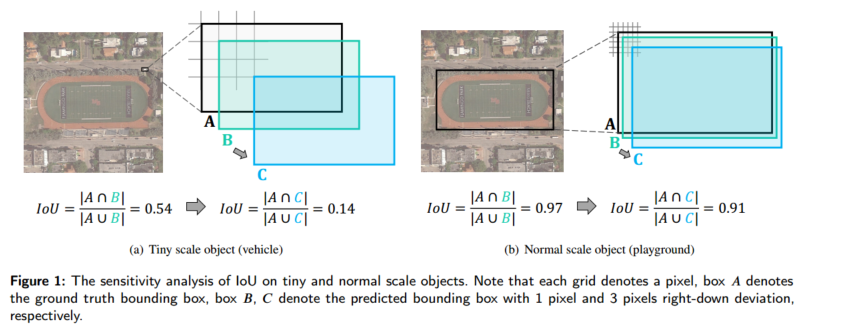
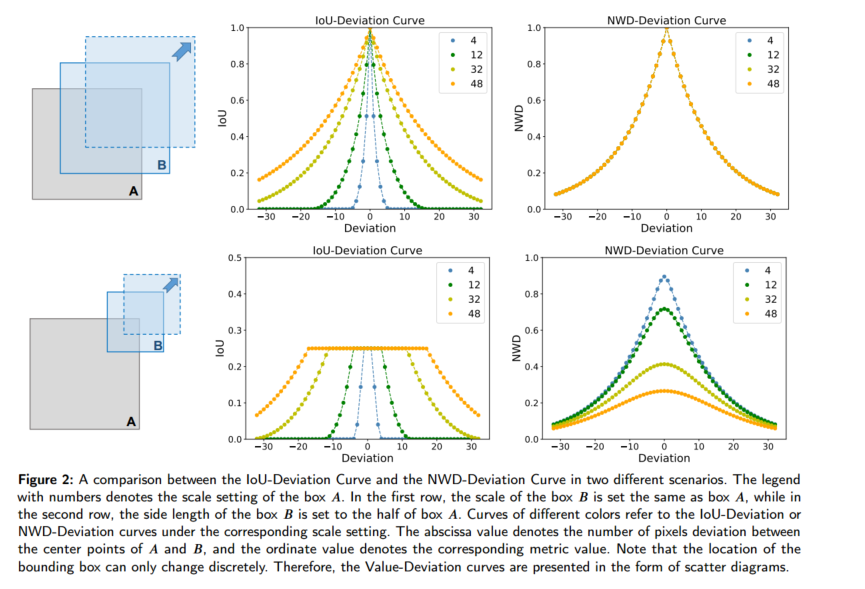
下图展示了 IoU-偏移 曲线(左)和 NWD-偏移 曲线(右)在两种不同场景下的对比。每条曲线对应于目标框 A 不同的尺度(用图例中的数字 4、12、32、48 表示长边像素数),横坐标是框 A 和框 B 中心点的像素偏移量,纵坐标是相应的相似度度量(IoU 或 NWD)。



观察一:IoU 对目标尺度的敏感性差异显著。 对于 5×8 像素的微小目标,轻微的位置偏移会导致 IoU 从 0.54 骤降至 0.14,造成标签分配错误。但对于 200×320 像素的常规目标,同样的偏移仅使 IoU 从 0.97 降至 0.91。此外,图 2 中不同尺度目标的 IoU-偏移曲线表明,目标越小,曲线下降越快。
观察二:IoU 在无重叠或完全包含时无法反映位置关系。 当两个框不重叠或一个框完全包含于另一个框内时,IoU 保持不变,但这在微小框中经常出现。
以上两点表明,IoU 不适于评估微小目标的位置关系,在标签分配中会带来三个缺陷:
正负样本不平衡。 由于 IoU 对微小目标的位置偏移极度敏感,大多数候选锚点变为负样本,导致正负样本严重不平衡。
尺度样本不平衡。 AI-TOD 数据集中,大尺度目标相较微小目标获得更多正样本,使网络偏向大尺度目标优化。
样本补偿失效。 当 IoU 为零时(两个框分离),无法对候选锚点进行合理排序,样本补偿策略失效。
虽然后续动态分配方法如 ATSS(Zhang 等,2020)可以自适应设置 IoU 阈值,但 IoU 的敏感性使得难以找到对微小目标高质量的正负样本。
另一方面,高质量数据对深度学习方法至关重要。目前针对航空图像微小目标的标注质量仍不理想。微小目标易被复杂背景误导,增加了标注难度和工作量(Wang 等,2021a)。至今,针对微小目标的基准仅有 TinyPerson(Yu 等,2020)和 AI-TOD(Wang 等,2021a),但 TinyPerson 仅覆盖单目标类别,而 AI-TOD 存在大量漏标和噪声(见图 3)。因此,亟需改进数据集标注质量,建立更可靠的航空图像微小目标检测基准。

为此,我们从方法和数据两个维度推动航空图像微小目标检测的发展。方法上,我们设计了一种统一策略,可嵌入现有基于锚点的检测器,提升微小目标检测性能。基于 IoU 在标签分配中的缺陷,本文先将边界框建模为二维高斯分布,再使用经典瓦瑟斯坦距离度量分布相似性,并通过指数非线性变换对距离进行归一化,得到归一化瓦瑟斯坦距离(NWD)。相比 IoU,NWD 在无重叠时仍能衡量分布相似性,对位置偏移更平滑且具有尺度平衡性(见图 2)。
接着,我们提出结合 NWD 的基于排序的训练样本分配(RKA)策略,不同于 Faster R-CNN(Ren 等,2015)的阈值分配,RKA 根据 NWD 分数对候选锚点排序,保证每个实例获得足够的正样本,从而有效缓解 IoU 方法的三大问题(正负不平衡、尺度不平衡、补偿失效),持续提升 TOD 性能。
数据方面,我们组织专家团队对 AI-TOD 进行了精细重标注,新增超过 5 万个微小目标实例,得到 AI-TOD-v2。该数据集包含 8 类共 28,036 张图像和 752,754 个实例,平均目标尺寸仅 12.7 像素,是目前目标检测数据集中最小的对象尺度。我们还在 AI-TOD-v2 上建立了更全面的基准,方便算法对比。
本文贡献归纳如下:
提出 NWD-RKA——一种适用于微小目标的训练样本分配策略,可同时缓解 IoU 阈值分配的三大缺陷。
精心重标注 AI-TOD,发布 AI-TOD-v2 数据集及对应基准,显著降低标签噪声并增加标注实例。
将 NWD-RKA 嵌入多种基于锚点的检测器,在 AI-TOD-v2 上实现 24.7 AP、57.2 AP0.5,相较最先进方法大幅领先,并在 AI-TOD、VisDrone2019 和 DOTA-v2.0 数据集上显著提升性能。
相关工作
2.1 航空图像目标检测数据集
在航空图像目标检测领域,为促进研究发展已提出多种公开数据集,例如 DIOR(Li 等,2020b)、DOTA(Xia 等,2018)、xView(Lam 等,2018)、VisDrone(Zhu 等,2018)、HRSC2016(Liu 等,2016b)、VEDAI(Razakarivony 和 Jurie,2016)、NWPU VHR-10(Cheng 等,2014)、UAVDT(Yu 等,2019)和 FAIR1M(Sun 等,2021b)。然而,这些数据集中对象的平均绝对尺寸通常远大于 32 像素,且大于 32 像素的目标占绝大多数,因此不适用于评估微小目标检测器的性能。尽管也存在专门针对微小目标检测的少量数据集(如 TinyPerson(Yu 等,2020)、R²-CNN(Pang 等,2019)),但 TinyPerson 仅包含单一类别的人物检测,R²-CNN 数据集并未公开。
相比之下,我们提出的 AI-TOD-v2 专注于航空图像中的微小目标检测。AI-TOD-v2 中目标的平均绝对尺寸仅 12.7 像素,约 86% 的实例小于 16 像素,远小于现有数据集。
2.2 微小目标检测策略
现有的小/微小目标检测策略大致可分为五类:多尺度特征学习、基于上下文的检测、数据增强、设计更优的训练策略以及标签分配策略。
多尺度特征学习:最简单直接的方式是对输入图像进行多尺度重采样,训练不同的检测器,各自针对特定尺度表现最佳,但会带来额外计算开销。为降低成本,许多研究(Liu 等,2016a;Cao 等,2018;Deng 等,2018;Lin 等,2017a;Zhang 等,2018;Yang 等,2018;Zheng 等,2020b)通过构建多尺度特征图来提升效果。例如,SSD(Liu 等,2016a)从不同分辨率的特征层检测目标,FPN(Lin 等,2017a)通过自上而下和横向连接融合多尺度特征。基于此,衍生出 FFSSD(Cao 等,2018)、MSCNN(Deng 等,2018)和 DFPN(Yang 等,2018)等网络。
基于上下文的检测:当目标极小且特征有限时,背景和上下文信息尤为重要。MRCNN(Gidaris 和 Komodakis,2015)通过提取 RoI 子区域特征并拼接实现局部上下文融合;ION(Bell 等,2016)利用 RoI 内外特征获得全局上下文;Relation Network(Hu 等,2018)建立外观与几何交互,强化对象间关联建模。
数据增强:通过扩充训练数据来提升检测器性能。常见做法包括图像翻转、上/下采样、旋转等。Kisantal 等(2019)指出,数据集中缺乏小目标实例会导致检测性能下降,他们通过对含小目标图片过采样及微小目标的拷贝粘贴实现增强。
更优训练策略设计:针对同时检测大/小目标的难题,SNIP(Singh 和 Davis,2018)与 SNIPER(Singh 等,2018)针对特定尺度范围的目标进行选择性训练;Kim 等(2018)提出 SAN,将不同空间中提取的特征映射到尺度不变子空间,提高对尺度变化的鲁棒性。
标签分配策略:微小目标的正负锚点分配极具挑战。一种简单方法是降低 IoU 阈值,虽然能匹配更多正样本,但整体样本质量下降。近期研究如 ATSS(Zhang 等,2020)、PAA(Kim 和 Lee,2020)、OTA(Ge 等,2021)均尝试自适应或全局视角优化标签分配,但仍依赖 IoU 度量,不适用于微小目标检测。
超分辨率方法:Shermeyer 和 Van Etten(2019)证明通过深度超分辨率框架提升图像分辨率可改善卫星图像目标检测。一些工作将 SR 模块集成到检测流程中,如边缘增强 SR GAN(Rabbi 等,2020)、在检测框架中添加辅助 GAN(Courtrai 等,2020)、结合循环 GAN 与残差特征聚合(Bashir 和 Wang,2021)等,均显著提升微小目标检测性能。
核心检测器改造:部分研究直接修改检测器以适应微小目标。例如 Mask-guided SSD(Sun 等,2021a)结合分割掩码抑制背景;YOLOFine(Pham 等,2020)改进 YOLO 以兼顾效率和精度;改良版 Faster R-CNN(Ren 等,2018)通过提高 FPN 分辨率和组合多种训练策略提升小目标检测。
相比上述方法,我们的方法主要聚焦于设计更优的相似度度量(NWD)及其定制化的标签分配策略,可替换现有 IoU 基础的分配方式,在微小目标检测任务中更具优势。
数据集
我们基于早期 AI-TOD(Wang 等,2021a)构建了 AI-TOD-v2 数据集。我们发现原 AI-TOD 存在大量漏标,主要因为它由多个公共航空图像数据集(Xia 等,2018;Lam 等,2018;Zhu 等,2018;Airbus,2018;Li 等,2020b)汇总而来,这些数据集并非针对微小目标检测设计,导致标签噪声严重,影响微小目标检测器的训练与验证。因此,我们对 AI-TOD 进行了精细重标注,并基于更多基线检测器建立了更全面的评测基准。注意,AI-TOD 和 AI-TOD-v2 共享图像集,但它们的注释不同。
3.1 数据集优化
原始 AI-TOD 包含 28,036 张图像和 8 类共 700,621 个 HBB(水平边界框)标注(Wang 等,2021a)。在 AI-TOD-v2 中,我们保留相同的图像和类别,也沿用 HBB 形式,因为微小目标仅有少量像素,大多数可近似为点状。我们请标注员对注释精细修正,流程如下:
结果可视化辅助定位漏标:首先,用我们在 AI-TOD 上性能最优的微小目标检测器训练并在 trainval、test 集分别测试,生成 TP、FN、FP 可视化结果(置信度阈值 0.3)。其中较多的 FP 通常对应真实存在但在原标签中漏标的目标,为重标注提供参考。
专家制订标注规范:基于可视化反馈,挑选典型图像,召集航空影像解译领域专家讨论并制定标注手册,培训武汉大学具有相关背景的志愿者进行大规模标注
双阶段重标注:
第一阶段,志愿者在高置信场景下修正明显的噪声标注,并标记不确定图像。
第二阶段,团队协作对标记图像进行位置精修与类别投票,决策不确定目标的准确标注
双盲质量审查:随机交换不同标注员的标注结果,互相检查低质量注释,并通过团队讨论和投票最终确定目标位置和类别。
部分重标前后示例见图 4,可见漏标和定位错误已被修复。

3.2 AI-TOD-v2 数据集特点
AI-TOD-v2 是当前地球观测领域目标尺度最小的数据集。我们从以下四方面对比 AI-TOD-v2 与前一版本及其他数据集的统计特征:
实例数量:AI-TOD-v2 共包含 28,036 张图像和 752,745 个标注实例,比原版增加 52,133 个实例。各类别及各数据切分(训练集、验证集、trainval、测试集)的实例数详见表 1。训练集和验证集的图像与标注已公开。
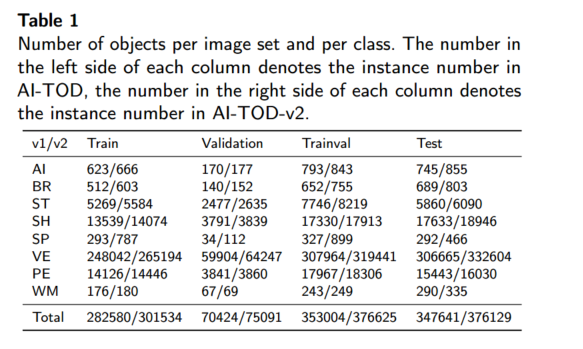
各类目标数目:与原版一致,AI-TOD-v2 包含 8 类常见微小目标:飞机(AI)、桥梁(BR)、油罐(ST)、船舶(SH)、游泳池(SP)、车辆(VE)、行人(PE)和风车(WM)。图 5(a) 为各类实例数量柱状图,可见类别不平衡(如车辆远超风车),符合实际场景,也增加算法设计挑战。
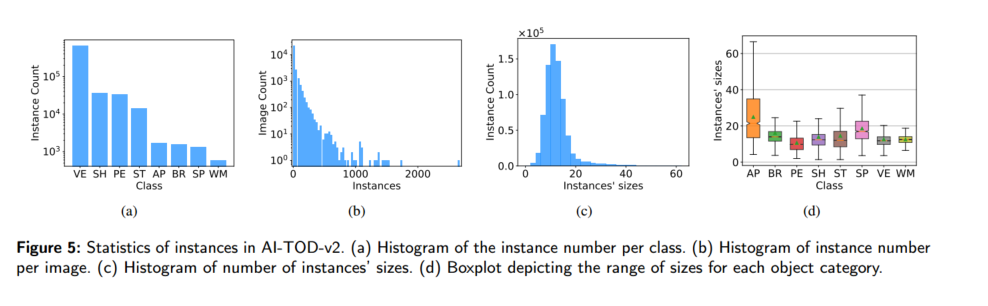
目标尺寸分布:图 5© 显示 AI-TOD-v2 中目标绝对尺寸主要集中在约 12 像素。表 2 对比了 AI-TOD-v2 与其他航空检测数据集的平均和标准差,AI-TOD-v2 平均仅 12.7 像素,略小于 AI-TOD,远小于其他数据集。
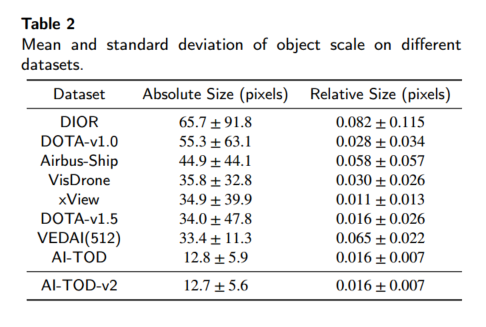
各类别尺寸范围:图 5(d) 展示了不同类别目标的尺寸分布。为更细致分析,我们将绝对尺寸分为 [2,8](极微小)、[8,16](微小)、[16,32](小)和 [32,64](中)四档。AI-TOD-v2 中极微小、微小、小、中目标所占比例分别为 12.4%、73.4%、12.4% 和 1.8%,大多数类别主要分布在极微小和微小区间。
3.3 AI-TOD-v2 注释评估
为客观评估 AI-TOD-v2 注释质量,我们进行了相似度检验和统计分析。相似度检验主要比较 NWD-RKA 预测框与 AI-TOD-v2 重标注框之间的 AP 指标。实验分两组:
组 1:在 AI-TOD 的 trainval 和 test 集上分别训练并验证 NWD-RKA(记原注释为 A1,NWD-RKA 预测为 NA1)。
组 2:将 AI-TOD-v2 注释(记为 A2)作为真值,用 NWD-RKA 在 AI-TOD 上的预测 NA1 与 A2 计算 AP。
结果见表 3。NA1 vs A2 的整体 AP 仅约 33.0,极微小尺度下低于 15.0,且 NA1 vs A2 的 AP 略低于 NA1 vs A1,说明重标注后的标注框与算法预测差异更大,而非算法预测适配标签。这表明 AI-TOD-v2 注释与 NWD-RKA 预测在本质上有所不同。
此外,我们还统计了 AI-TOD、NWD-RKA 预测与 AI-TOD-v2 注释的尺寸分布(见图 6)。三者在微小尺度实例数上差异明显:NWD-RKA 预测比原注释多约 16 万条假阳性,而 AI-TOD-v2 经过人工筛选,微小目标数最终为 550,933,比 AI-TOD 多约 4 万,比 NWDRKA 预测少约 12 万。这些差异进一步验证了三者的互异性,而 AI-TOD-v2 相较于算法预测的实例量收缩,体现了重标注流程的严格筛选。
4. 方法论
在本节中,我们首先介绍归一化高斯瓦瑟斯坦距离(Normalized Gaussian Wasserstein Distance,NWD)在微小边界框上的建模方法;随后详细描述基于排序的分配策略(RanKing-based Assignment,RKA)及其与 NWD 的结合。
4.1 归一化高斯瓦瑟斯坦距离

4.2 基于排序的标签分配(RKA)

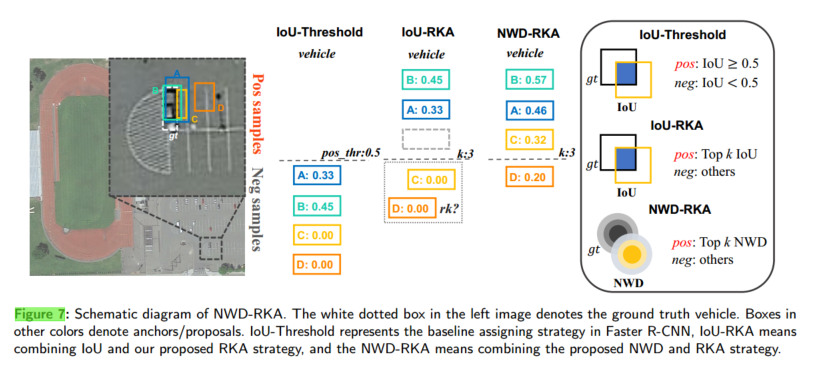
下图是 NWD‑RKA 策略的示意图,用来对比三种不同的标签分配方式(IoU‑Threshold、IoU‑RKA、NWD‑RKA)对四个候选锚点(A、B、C、D)赋正/负样本的结果。




分析
本节分为两部分:
第一部分对 IoU 和 NWD 两种度量进行特性分析;
第二部分总结 IoU 阈值分配策略的三大主要缺陷,并阐述 NWD-RKA 如何同时解决这些问题,从而提升微小目标检测性能。
5.1 度量指标分析
与 IoU 相比,NWD 在微小目标检测中具有以下优势:
对位置偏移的平滑性:如图 2 第一行所示,对少量像素当 B 沿着对角线偏移时,IoU 偏移极其敏感,表现为陡峭的下降;而 NWD 则给出平滑的衰减曲线,使同一阈值下可为微小目标补偿更多正样本。
尺度平衡性:图 2 中不同尺度的 NWD-偏移 曲线完全重合,说明 NWD 对各尺度目标响应一致,有助于在训练时为不同尺度实例分配均衡数量的正样本。
非重叠/包含场景下的相似度度量能力:如图 2 第二行所示,当 |A ∩ B|=0(无重叠)时,IoU 恒为 0,无法区分不同偏移;而 NWD 始终大于 0,可持续反映两框的位置关系。
5.2 NWD-RKA 分析
正负样本不平衡:AI-TOD-v2 中,微小目标正负样本比例在未经采样前远低于 MS COCO,IoU 的敏感性导致微小目标几乎无正样本。NWD-RKA 在一个 epoch 内将正样本数量增加至 709,060(相比基线多 490,240),极大缓解正样本缺乏,为分类和回归提供了更充足的监督(见表 4 的 AP/AR 提升)。
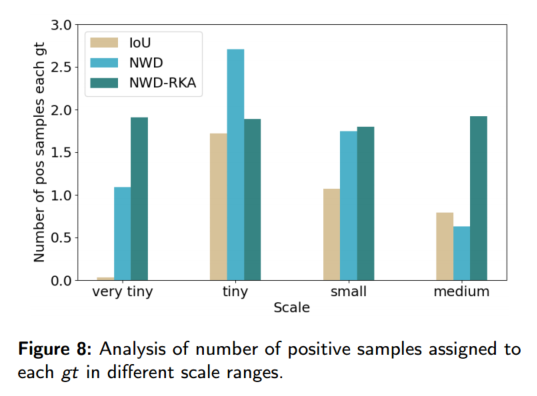
尺度样本不平衡:IoU 与离散锚点尺度匹配导致极微小尺度实例几乎无正样本(见图 8)。RKA 通过为每个 gt 分配 Top‑k NWD 得分最高锚点,实现各尺度实例正样本数量均衡分布,缓解了训练偏向问题。
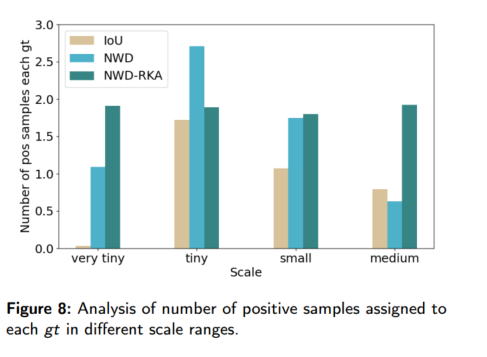
样本补偿失效:传统赋样策略在 IoU=0 时无法排序锚点,无论何种启发式都难保每个 gt 至少有正样本。NWD 在无重叠时仍可度量分布距离,保证所有锚点有正的 NWD 值,RKA 可对其排序并至少为每个 gt 选择一个正样本,彻底解决了样本补偿失效。
实验
本节首先介绍实验设置,包括使用的数据集、参数配置和评估指标;随后给出基于多种检测器的大规模基准测试;最后通过一系列对比实验证明提出方法的有效性,并进行消融分析。
6.1 实验设置
数据集:主要在 AI-TOD-v2 的 trainval 集上训练,并在 test 集上验证。为评估方法的泛化能力,还在其他包含大量微小目标的航空图像数据集上进行测试,包括原 AI-TOD、VisDrone2019 和 DOTA-v2.0。其中,对 VisDrone2019 和 DOTA-v2.0,使用其训练集训练,验证集测试。
参数配置:所有实验在单卡 NVIDIA RTX 3090 上,以 PyTorch 框架实现。默认使用 ImageNet 预训练的 ResNet-50+FPN 作为骨干;SGD 优化器训练 12 个 epoch,动量 0.9,权重衰减 1e-4,batch size=2;初始学习率 0.01,于第 8 和 11 个 epoch 衰减;RPN/两阶段检测器的采样数分别设置为 256/512,正负样本比例 1:3,RPN proposals 数量设为 3000。推理时置信度阈值设为 0.05,NMS IoU 阈值 0.5,保留前 3000 个框。以上配置为所有实验默认设置。
评估指标:采用 AP (Average Precision) 评价:AP0.5、AP0.75 表示以 IoU 0.5/0.75 为正例判定阈值的平均精度,AP 为从 0.5 到 0.95(步长 0.05)间的平均值;此外报告针对 very tiny、tiny、small、medium 四个尺度的 APvt、APt、APs、APm,以及最大检测数 1500 下的平均召回 AR1500。
6.2 大规模基准
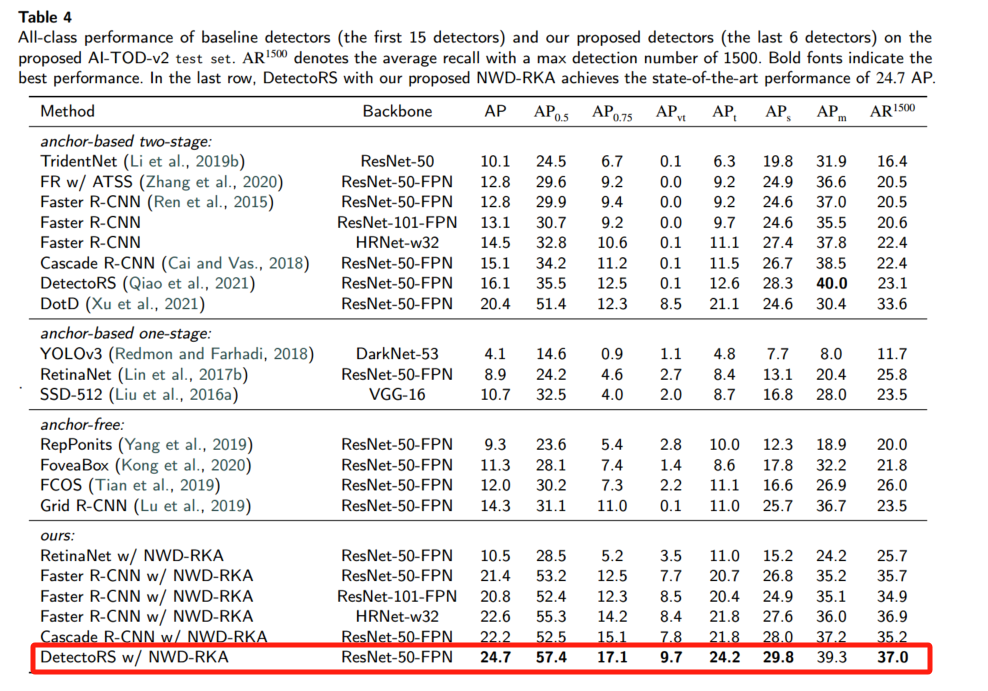
我们对超过 15 种典型检测器(包含一阶段/多阶段锚点方法和锚点自由方法)进行测试,并将图像的 proposals 数量和最大检测数从 100 增至 3000,以适应航空图像中更多目标。表 4/5 给出了全部类别和单类别的 AP。
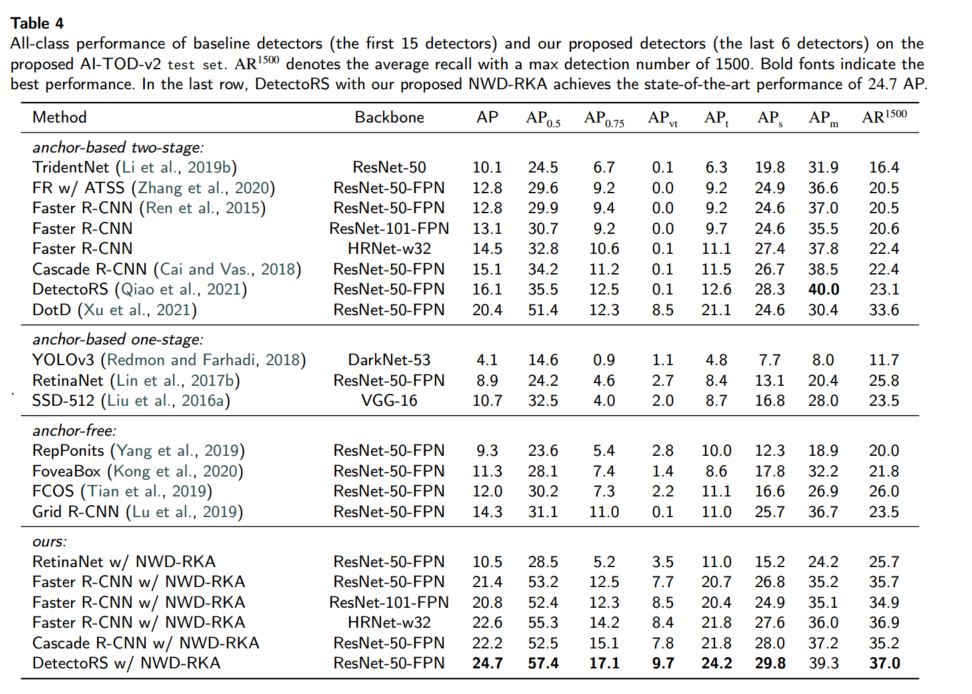
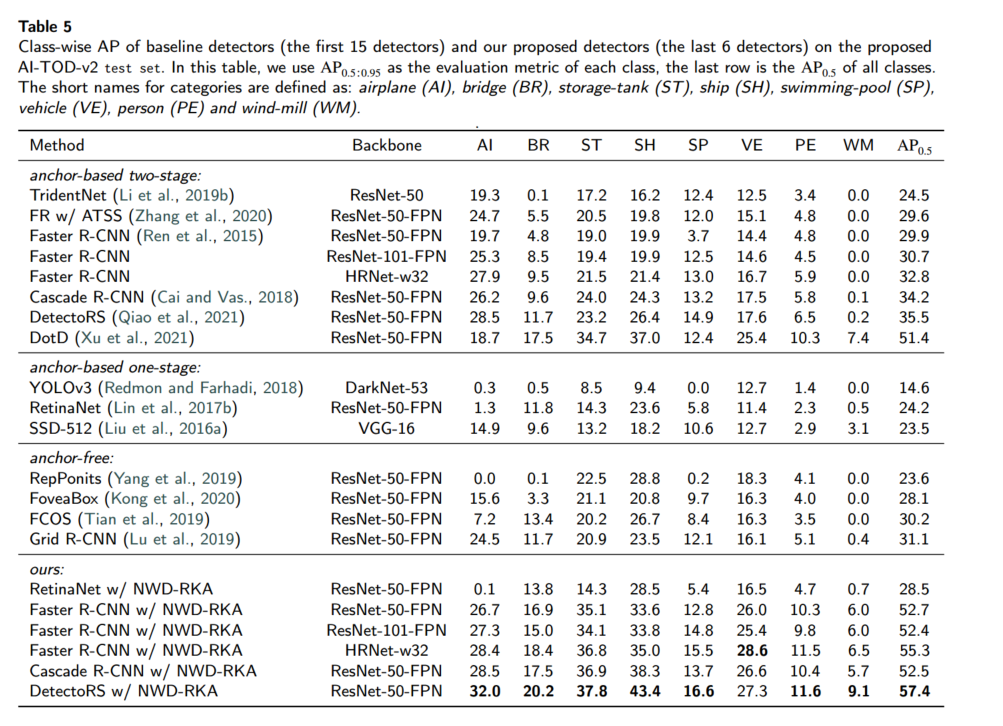
主要观察:
直接应用现有检测器到 AI-TOD-v2,性能远低于在 COCO、PASCAL VOC 上的表现,尤其是 APvt 接近零。微小目标在航空图像中外观信息有限且背景复杂,带来巨大挑战。
多阶段检测器(如 Faster R-CNN、Cascade R-CNN、DetectoRS)优于一阶段锚点(RetinaNet、SSD、YOLO)和锚点自由(FCOS、FoveaBox、CenterNet)方法,表明 TOD 任务中存在严重的前背景不平衡。
少数类性能明显低于常见类,源自训练样本不平衡。该问题在其他航空数据集中也普遍存在。
此外,AI-TOD-v2 与带噪音的 AI-TOD 构成天然的对比基准,可用于评估算法在标签噪声场景下的鲁棒性。
6.3 NWD-RKA 的实验结果
我们设置四类实验:
6.3.1 提升基线性能
:在 RetinaNet、Faster R-CNN、Cascade R-CNN 和 DetectoRS 上替换为 NWD-RKA,分别提升了 1.6、8.6、7.1 和 8.6 AP(表 4/5),对极微小目标的改进尤为显著。
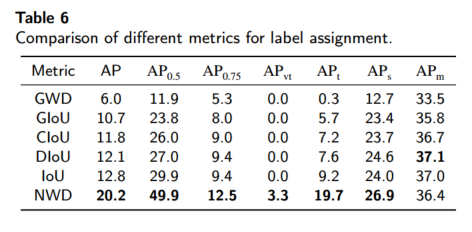
6.3.2 与其他度量比较:
将 GIoU、DIoU、CIoU 和 GWD 应用于同样的阈值分配,结果见表 6。NWD 达到最高 20.2 AP,表明 NWD 更适合微小目标的相似度衡量和标签分配。
6.3.3 消融研究:
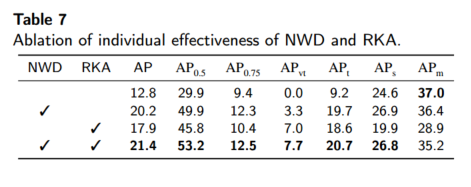
NWD 与 RKA 的单独效果(表 7):仅替换度量或仅替换分配策略时,AP 分别从 12.8 提升至 20.2 和 17.9,二者结合可达 21.4。
阈值微调对比(表 8):在微调 IoU 阈值后仍不及 NWD-RKA(21.4 AP)。

不同锚点尺度(表 9):NWD-RKA 在锚点尺度从 4 到 32 之间保持高性能,其中尺度 4 最佳(22.2 AP)。
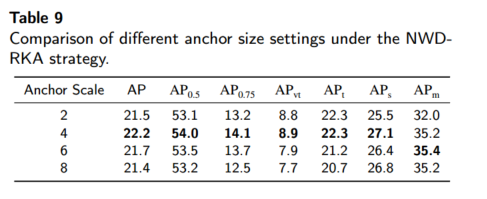
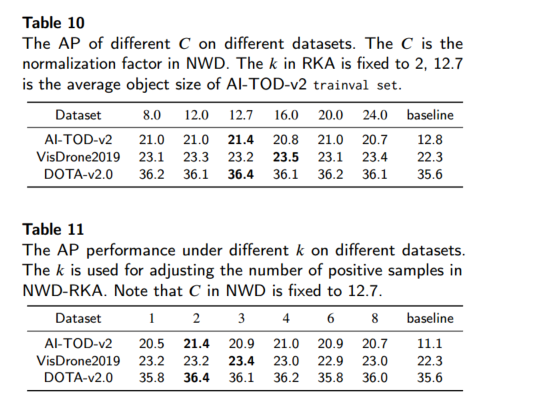
超参数鲁棒性(表 10/11):常数 C 在 8~24 范围内波动<1 AP,RKA 中的 k 在 1~8 之间变化<1 AP,说明参数选择在一定范围内均有效;建议统一设置 C≈12、k=2。
特征分辨率提升:用 HRNet 替换 ResNet-50,Faster R-CNN 性能提升 1.7 AP,而 HRNet + NWD-RKA 可达 22.6 AP,凸显 NWD-RKA 对不同骨干网络均有效。
6.3.4 在其他数据集上的实验:
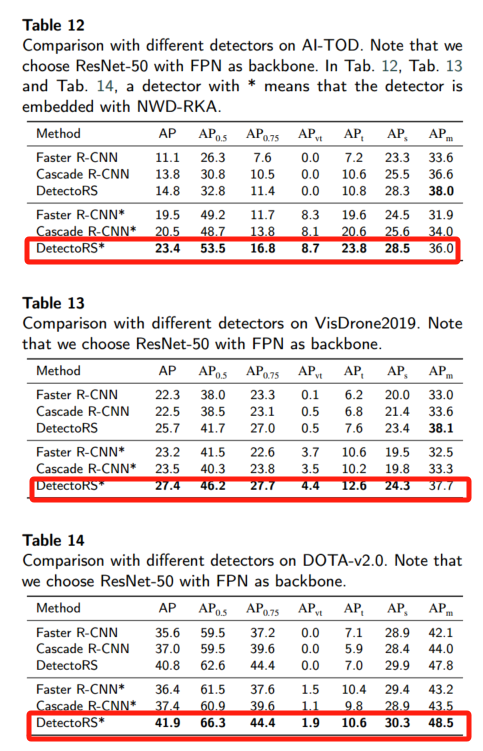
在原 AI-TOD、VisDrone2019、DOTA-v2.0 上,将 NWD-RKA 嵌入 Faster R-CNN、Cascade R-CNN 和 DetectoRS。表 12/13/14 显示均有显著提升,其中 DetectoRS 在三数据集分别提升 8.6、1.7、1.1 AP,tiny 尺度上的增益尤为突出。
6.4 可视化
图 9 展示了部分基线检测器和 NWD-RKA 检测器的可视化结果。与基线相比,DetectoRS + NWD-RKA 的检测结果有明显提升:

减少 FN:在微小目标检测中,基线检测器常出现漏检(FN),表明正样本监督不足;NWD-RKA 显著降低了 FN,说明其为微小目标提供了更充足的正样本监督。
降低 FP:RetinaNet 结果中可见大量误检(FP),表明其难以在众多候选框中正确分类;而 NWD-RKA 明显减少了 FP,说明其分配的正负样本更具区分度,提升了分类精度。
结论
本文提出了一种用于航空图像微小目标检测的 NWD-RKA 方法,并发布了精细优化的数据集 AI-TOD-v2 及其基准测试。主要贡献包括:
新颖标签分配策略:NWD-RKA 结合归一化瓦瑟斯坦距离和排序分配,无需设阈值,可为微小目标提供更多高质量正样本。
高质量数据集:AI-TOD-v2 为当前最小目标尺寸的航空图像数据集,显著降低了漏标和定位误差。
显著性能提升:在四个数据集和多种检测器上,NWD-RKA 均带来大幅性能提升,特别是在极微小尺度下实现了 SOTA。
我们希望开放数据集与优异性能能推动地球视觉与计算机视觉社区更多关注航空图像微小目标检测这一挑战性任务,并为定制化算法的公平对比与进步提供基准支持。
问题
1、论文基线模型
论文中所有消融实验均以 Faster R‑CNN 作为基线模型(默认使用 ImageNet 预训练的 ResNet‑50 + FPN 作为骨干网络),仅在此基础上分别替换 IoU 度量或阈值分配策略,或者同时替换为 NWD‑RKA,以验证各模块的独立与联合效果。
2、NWD‑RKA 和 RFLA这两个模型的最优结果有何差异
